Serializzazione del modello di dati da e verso archivi diversi (anteprima)
Affinché il modello di dati venga archiviato in un database, è necessario convertirlo in un formato comprensibile per il database. Database diversi richiedono schemi e formati di archiviazione diversi. Alcuni hanno uno schema rigoroso che deve essere rispettato, mentre altri consentono di definire lo schema dall'utente.
Opzioni di mapping
I connettori dell'archivio vettoriale forniti dal Kernel Semantico offrono diversi modi per ottenere questa mappatura.
Mappatori integrati
I connettori dell'archivio vettoriale forniti dal Kernel Semantico hanno mapper integrati che eseguiranno il mapping del modello di dati ai e dagli schemi del database. Consultare la pagina per ogni connettore per ulteriori informazioni su come i mapper integrati mappano i dati per ciascun database.
Mapper personalizzati
I connettori dell'archivio vettoriale forniti dal Kernel Semantico supportano l'uso di mapper personalizzati in combinazione con un VectorStoreRecordDefinition. In questo caso, il VectorStoreRecordDefinition può essere diverso dal modello di dati fornito.
Il VectorStoreRecordDefinition viene usato per definire lo schema del database, mentre il modello di dati viene usato dallo sviluppatore per interagire con l'archivio vettoriale.
In questo caso è necessario un mapper personalizzato per mappare dal modello di dati allo schema del database personalizzato definito dal VectorStoreRecordDefinition.
Consiglio
Consulta Come creare un mapper personalizzato per un connettore Vector Store per un esempio su come farlo.
Affinché il modello di dati sia definito come classe o definizione da archiviare in un database, deve essere serializzato in un formato comprensibile per il database.
È possibile eseguire due modi, usando la serializzazione predefinita fornita dal kernel semantico o fornendo la logica di serializzazione personalizzata.
I due diagrammi seguenti mostrano i flussi per la serializzazione e la deserializzazione dei modelli di dati da e verso un modello di archivio.
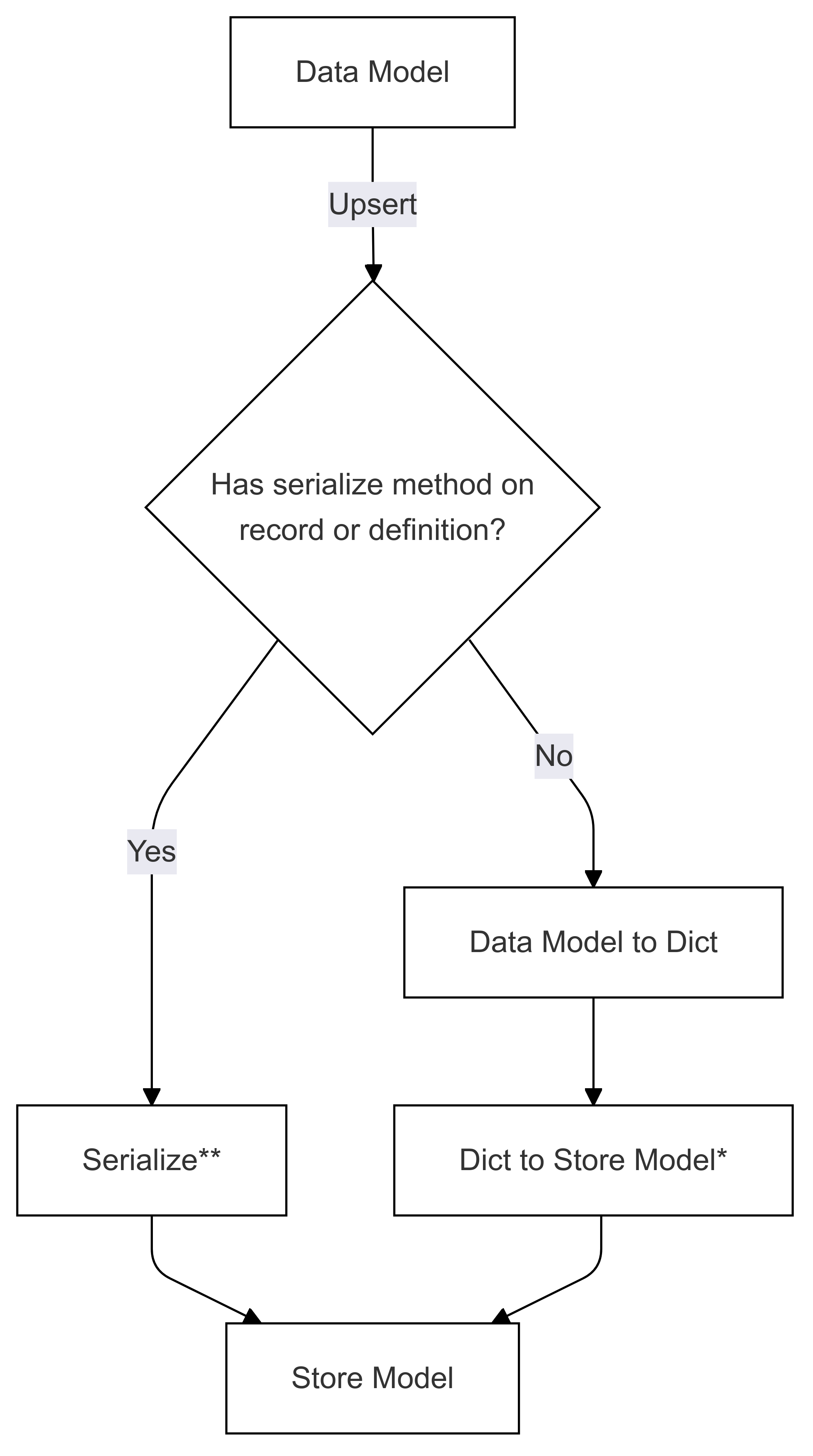
Flusso di serializzazione (usato in Upsert)
Flusso di deserializzazione (usato in Get and Search)
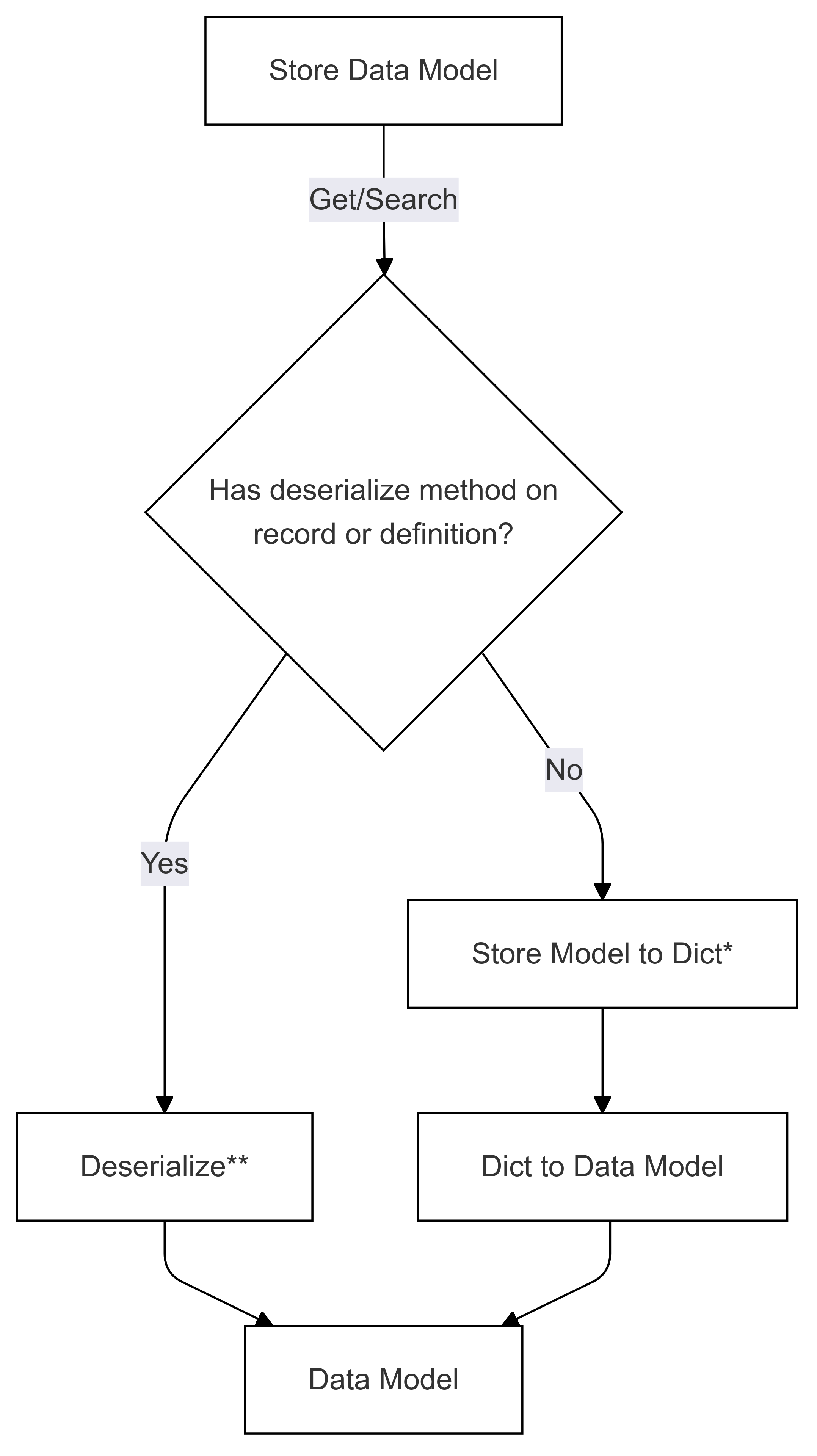
I passaggi contrassegnati con * (in entrambi i diagrammi) vengono implementati dallo sviluppatore di un connettore specifico e sono diversi per ogni negozio. I passaggi contrassegnati con ** (in entrambi i diagrammi) vengono forniti come un metodo in un record o come parte della definizione di record, che sono sempre forniti dall'utente. Per altre informazioni, vedere Serializzazione Diretta.
(De)Approcci di serializzazione
Serializzazione diretta (modello di dati al modello di archivio)
La serializzazione diretta è il modo migliore per garantire il controllo completo sul modo in cui i modelli vengono serializzati e per ottimizzare le prestazioni. Lo svantaggio è che è specifico per un archivio dati, quindi quando lo si utilizza non è semplice passare da un archivio all'altro con lo stesso modello di dati.
È possibile usarlo implementando un metodo che segue il protocollo SerializeMethodProtocol nel modello di dati o aggiungendo funzioni che seguono la SerializeFunctionProtocol alla definizione del record, entrambe sono disponibili in semantic_kernel/data/vector_store_model_protocols.py.
Quando una di queste funzioni è presente, verrà usata per serializzare direttamente il modello di dati nel modello di archiviazione.
È possibile implementare solo uno dei due e utilizzare la deserializzazione/serializzazione predefinita per l'altra direzione. Questo potrebbe, ad esempio, essere utile quando si gestisce una raccolta creata al di fuori del tuo controllo e hai bisogno di personalizzare il modo in cui viene deserializzata. Inoltre, non è comunque possibile eseguire un 'upsert'.
Serializzazione integrata (da modello di dati a dict e da dict a modello di archiviazione e viceversa)
La serializzazione predefinita viene eseguita convertendo prima il modello di dati in un dizionario e quindi serializzandolo nel modello che archivia riconosce, per ogni archivio diverso e definito come parte del connettore predefinito. La deserializzazione viene eseguita nell'ordine inverso.
Passaggio di serializzazione 1: Modello di dati da definire
A seconda del tipo di modello di dati disponibile, i passaggi vengono eseguiti in modi diversi. Esistono quattro modi per provare a serializzare il modello di dati in un dizionario:
-
to_dictmetodo nella definizione (allineato all'attributo to_dict del modello di dati, seguendo ilToDictFunctionProtocol) - verificare se il record è un
ToDictMethodProtocole utilizzare il metodoto_dict - Verificare se il record è un modello Pydantic e utilizzare la
model_dumpdel modello; consultare la nota seguente per ulteriori informazioni. - scorrere i campi nella definizione e creare il dizionario
Passaggio di serializzazione 2: Dict to Store Model
Un metodo deve essere fornito dal connettore per convertire il dizionario nel modello di archivio. Questa operazione viene eseguita dallo sviluppatore del connettore ed è diversa per ogni negozio.
Passaggio di deserializzazione 1: Archiviare il modello in dict
Un metodo deve essere fornito dal connettore per convertire il modello di archivio in un dizionario. Questa operazione viene eseguita dallo sviluppatore del connettore ed è diversa per ogni negozio.
Passaggio 2 della deserializzazione: dict in un modello di dati
La deserializzazione viene eseguita nell'ordine inverso e tenta queste opzioni:
-
from_dictmetodo per la definizione (che si allinea all'attributo from_dict del modello di dati, seguendo ilFromDictFunctionProtocol) - verificare se il record è un
FromDictMethodProtocole usare il metodofrom_dict - verificare se il record è un modello Pydantic e utilizzare il
model_validatedel modello, si veda la nota seguente per ulteriori informazioni. - scorrere i campi nella definizione e impostare i valori, quindi questo dict viene passato al costruttore del modello di dati come argomenti denominati (a meno che il modello di dati non sia un dict stesso, in tal caso viene restituito così come è)
Nota
Uso di Pydantic con serializzazione predefinita
Quando si definisce il modello usando un oggetto BaseModel pydantic, verranno usati i model_dump metodi e model_validate per serializzare e deserializzare il modello di dati da e verso un dict. Questo viene fatto utilizzando il metodo model_dump senza alcun parametro; se si desidera controllare tale azione, considerare di implementare il ToDictMethodProtocol nel proprio modello di dati, poiché è la prima opzione che viene presa in considerazione.
Serializzazione dei vettori
Quando si dispone di un vettore nel modello di dati, deve essere un elenco di valori float o un elenco di int, poiché ciò è ciò che la maggior parte degli archivi richiede, se si vuole che la classe archivi il vettore in un formato diverso, è possibile usare serialize_function e deserialize_function definito nell'annotazione VectorStoreRecordVectorField . Ad esempio, per una matrice numpy è possibile usare l'annotazione seguente:
import numpy as np
vector: Annotated[
np.ndarray | None,
VectorStoreRecordVectorField(
dimensions=1536,
serialize_function=np.ndarray.tolist,
deserialize_function=np.array,
),
] = None
Se si utilizza un archivio vettoriale in grado di gestire matrici numpy native e non si desidera convertirle avanti e indietro, è necessario configurare i metodi di serializzazione e deserializzazione diretta per il modello e quell'archivio.
Nota
Questa operazione viene usata solo quando si usa la serializzazione predefinita, quando si usa la serializzazione diretta, è possibile gestire il vettore in qualsiasi modo desiderato.
Presto disponibile
Altre informazioni saranno presto disponibili.