Connettersi e gestire Azure Databricks in Microsoft Purview
Questo articolo descrive come registrare Azure Databricks e come autenticare e interagire con Azure Databricks in Microsoft Purview. Per altre informazioni su Microsoft Purview, vedere l'articolo introduttivo.
Funzionalità supportate
| Estrazione dei metadati | Analisi completa | Analisi incrementale | Analisi con ambito | Classificazione | Applicazione di etichette | Criteri di accesso | Derivazione | Condivisione dati | Visualizzazione in diretta |
|---|---|---|---|---|---|---|---|---|---|
| Sì | Sì | No | Sì | No | No | No | Sì | No | No |
Nota
Questo connettore porta i metadati dal metastore Hive con ambito area di lavoro di Azure Databricks. Per analizzare i metadati nel catalogo Unity di Azure Databricks, fare riferimento al connettore Azure Databricks Unity Catalog.
Durante l'analisi del metastore Hive di Azure Databricks, Microsoft Purview supporta:
Estrazione di metadati tecnici, tra cui:
- Area di lavoro di Azure Databricks
- Server Hive
- Database
- Tabelle che includono colonne, chiavi esterne, vincoli univoci e descrizione dell'archiviazione
- Viste che includono le colonne e la descrizione dell'archiviazione
Recupero della relazione tra tabelle esterne e asset BLOB di Azure Data Lake Storage Gen2/Azure (percorsi esterni).
Recupero della derivazione statica tra tabelle e viste in base alla definizione della vista.
Quando si configura l'analisi, è possibile scegliere di analizzare l'intero metastore Hive o di definire l'ambito dell'analisi in un subset di schemi.
Confronto tra l'analisi tramite il connettore Hive Metastore generico nel caso in cui venga usato per analizzare Azure Databricks in precedenza:
- È possibile configurare direttamente l'analisi per le aree di lavoro di Azure Databricks senza l'accesso diretto a HMS. Usa il token di accesso personale di Databricks per l'autenticazione e si connette a un cluster per eseguire l'analisi.
- Le informazioni sull'area di lavoro di Databricks vengono acquisite.
- Viene acquisita la relazione tra tabelle e asset di archiviazione.
Limitazioni note
Quando l'oggetto viene eliminato dall'origine dati, attualmente l'analisi successiva non rimuove automaticamente l'asset corrispondente in Microsoft Purview.
Prerequisiti
È necessario avere un account Azure con una sottoscrizione attiva. Creare un account gratuitamente.
È necessario disporre di un account Microsoft Purview attivo.
È necessaria una Key Vault di Azure e per concedere a Microsoft Purview le autorizzazioni per accedere ai segreti.
Sono necessarie le autorizzazioni Amministratore origine dati e Lettore dati per registrare un'origine e gestirla nel portale di governance di Microsoft Purview. Per altre informazioni sulle autorizzazioni, vedere Controllo di accesso in Microsoft Purview.
Configurare il runtime di integrazione self-hosted più recente. Per altre informazioni, vedere Creare e configurare un runtime di integrazione self-hosted. La versione minima di Integration Runtime self-hosted supportata è 5.20.8227.2.
Assicurarsi che JDK 11 sia installato nel computer in cui è installato il runtime di integrazione self-hosted. Riavviare il computer dopo aver installato il JDK per renderlo effettivo.
Assicurarsi che Visual C++ Redistributable (versione Visual Studio 2012 Update 4 o versione successiva) sia installata nel computer in cui è in esecuzione il runtime di integrazione self-hosted. Se l'aggiornamento non è installato, scaricarlo ora.
Nell'area di lavoro di Azure Databricks:
Generare un token di accesso personale e archiviarlo come segreto in Azure Key Vault.
Creare un cluster. Annotare l'ID cluster: è possibile trovarlo nell'area di lavoro di Azure Databricks - Calcolo -> cluster -> Tag -> Tag aggiunti automaticamente ->
ClusterId.>Assicurarsi che l'utente disponga delle autorizzazioni seguenti per connettersi al cluster Azure Databricks:
- Può connettersi all'autorizzazione per connettersi al cluster in esecuzione.
- È possibile riavviare l'autorizzazione per attivare automaticamente l'avvio del cluster se il relativo stato viene terminato durante la connessione.
Registrazione
Questa sezione descrive come registrare un'area di lavoro di Azure Databricks in Microsoft Purview usando il portale di governance di Microsoft Purview.
Passare all'account Microsoft Purview.
Selezionare Mappa dati nel riquadro sinistro.
Selezionare Registra.
In Registra origini selezionare Azure Databricks>Continue.
Nella schermata Registra origini (Azure Databricks) eseguire le operazioni seguenti:
In Nome immettere un nome che verrà visualizzato da Microsoft Purview come origine dati.
Per la sottoscrizione di Azure e il nome dell'area di lavoro databricks selezionare la sottoscrizione e l'area di lavoro da analizzare dall'elenco a discesa. L'URL dell'area di lavoro di Databricks viene popolato automaticamente.
Selezionare una raccolta dall'elenco.
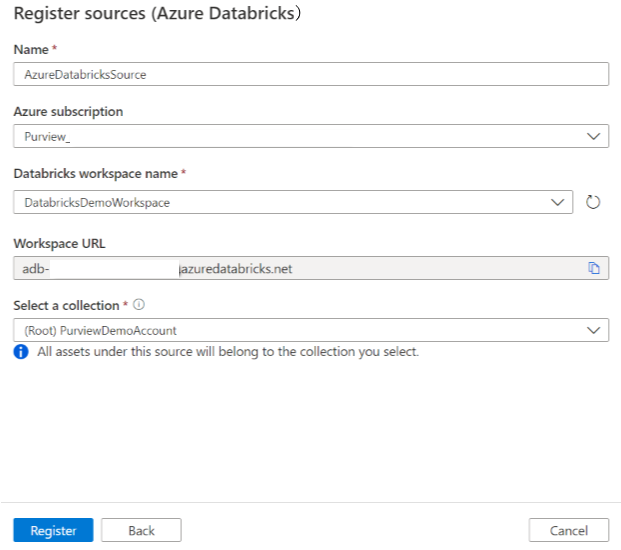
Seleziona Fine.
Analisi
Consiglio
Per risolvere eventuali problemi relativi all'analisi:
- Verificare di aver seguito tutti i prerequisiti.
- Esaminare la documentazione sulla risoluzione dei problemi di analisi.
Usare la procedura seguente per analizzare Azure Databricks per identificare automaticamente gli asset. Per altre informazioni sull'analisi in generale, vedere Analisi e inserimento in Microsoft Purview.
Nel Centro gestione selezionare Runtime di integrazione. Assicurarsi che sia configurato un runtime di integrazione self-hosted. Se non è configurato, usare la procedura descritta in Creare e gestire un runtime di integrazione self-hosted.
Passare a Origini.
Selezionare Azure Databricks registrato.
Selezionare + Nuova analisi.
Quando richiesto, specificare i dettagli seguenti:
Nome: immettere un nome per l'analisi.
Metodo di estrazione: Indicare di estrarre i metadati dal metastore Hive o dal catalogo Unity. Selezionare Metastore Hive.
Connettersi tramite il runtime di integrazione: selezionare il runtime di integrazione self-hosted configurato.
Credenziali: selezionare le credenziali per connettersi all'origine dati. Assicurarsi di:
- Selezionare Autenticazione token di accesso durante la creazione di credenziali.
- Specificare il nome del segreto del token di accesso personale creato in Prerequisiti nella casella appropriata.
Per altre informazioni, vedere Credenziali per l'autenticazione di origine in Microsoft Purview.
ID cluster: specificare l'ID cluster a cui Microsoft Purview si connette e a cui viene eseguita l'analisi. È possibile trovarlo nell'area di lavoro di Azure Databricks - Calcolo -> Cluster -> Tag -> Tag aggiunti automaticamente ->
ClusterId.>Punti di montaggio: specificare il punto di montaggio e la stringa di posizione di origine di Archiviazione di Azure quando l'archiviazione esterna è montata manualmente in Databricks. Usare il formato
/mnt/<path>=abfss://<container>@<adls_gen2_storage_account>.dfs.core.windows.net/;/mnt/<path>=wasbs://<container>@<blob_storage_account>.blob.core.windows.net. Viene usato per acquisire la relazione tra le tabelle e gli asset di archiviazione corrispondenti in Microsoft Purview. Questa impostazione è facoltativa, se non è specificata, tale relazione non viene recuperata.È possibile ottenere l'elenco dei punti di montaggio nell'area di lavoro di Databricks eseguendo il comando Python seguente in un notebook:
dbutils.fs.mounts()Stampa tutti i punti di montaggio come indicato di seguito:
[MountInfo(mountPoint='/databricks-datasets', source='databricks-datasets', encryptionType=''), MountInfo(mountPoint='/mnt/ADLS2', source='abfss://samplelocation1@azurestorage1.dfs.core.windows.net/', encryptionType=''), MountInfo(mountPoint='/databricks/mlflow-tracking', source='databricks/mlflow-tracking', encryptionType=''), MountInfo(mountPoint='/mnt/Blob', source='wasbs://samplelocation2@azurestorage2.blob.core.windows.net', encryptionType=''), MountInfo(mountPoint='/databricks-results', source='databricks-results', encryptionType=''), MountInfo(mountPoint='/databricks/mlflow-registry', source='databricks/mlflow-registry', encryptionType=''), MountInfo(mountPoint='/', source='DatabricksRoot', encryptionType='')]In questo esempio specificare quanto segue come punti di montaggio:
/mnt/ADLS2=abfss://samplelocation1@azurestorage1.dfs.core.windows.net/;/mnt/Blob=wasbs://samplelocation2@azurestorage2.blob.core.windows.netSchema: subset di schemi da importare espressi come elenco di schemi separati da punto e virgola. Ad esempio,
schema1;schema2. Tutti gli schemi utente vengono importati se l'elenco è vuoto. Tutti gli schemi e gli oggetti di sistema vengono ignorati per impostazione predefinita.I modelli di nomi di schema accettabili possono essere nomi statici o contenere caratteri jolly . Ad esempio:
A%;%B;%C%;D- Iniziare con A o
- Terminare con B o
- Contengono C o
- Uguale a D
L'utilizzo di NOT e caratteri speciali non è accettabile.
Nota
Questo filtro dello schema è supportato in Integration Runtime self-hosted versione 5.32.8597.1 e successive.
Memoria massima disponibile: memoria massima (in gigabyte) disponibile nel computer del cliente per i processi di analisi da usare. Questo valore dipende dalle dimensioni di Azure Databricks da analizzare.
Nota
Come regola generale, specificare 1 GB di memoria per ogni 1000 tabelle.
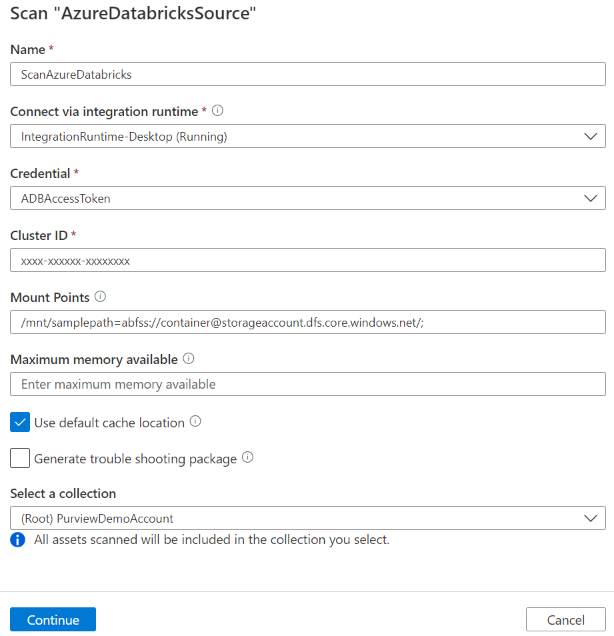
Selezionare Continua.
Per Esegui analisi, scegliere se configurare una pianificazione o eseguire l'analisi una sola volta.
Esaminare l'analisi e selezionare Salva ed esegui.
Al termine dell'analisi, vedere come esplorare e cercare gli asset di Azure Databricks.
Visualizzare le analisi e le esecuzioni di analisi
Per visualizzare le analisi esistenti:
- Passare al portale di Microsoft Purview. Nel riquadro sinistro selezionare Mappa dati.
- Selezionare l'origine dati. È possibile visualizzare un elenco di analisi esistenti nell'origine dati in Analisi recenti oppure è possibile visualizzare tutte le analisi nella scheda Analisi .
- Selezionare l'analisi con i risultati che si desidera visualizzare. Il riquadro mostra tutte le esecuzioni di analisi precedenti, insieme allo stato e alle metriche per ogni esecuzione dell'analisi.
- Selezionare l'ID di esecuzione per controllare i dettagli dell'esecuzione dell'analisi.
Gestire le analisi
Per modificare, annullare o eliminare un'analisi:
Passare al portale di Microsoft Purview. Nel riquadro sinistro selezionare Mappa dati.
Selezionare l'origine dati. È possibile visualizzare un elenco di analisi esistenti nell'origine dati in Analisi recenti oppure è possibile visualizzare tutte le analisi nella scheda Analisi .
Selezionare l'analisi da gestire. È quindi possibile eseguire automaticamente le seguenti azioni:
- Modificare l'analisi selezionando Modifica analisi.
- Annullare un'analisi in corso selezionando Annulla esecuzione analisi.
- Eliminare l'analisi selezionando Elimina analisi.
Nota
- L'eliminazione dell'analisi non elimina gli asset del catalogo creati dalle analisi precedenti.
Esplorare e cercare gli asset
Dopo aver eseguito l'analisi di Azure Databricks, è possibile esplorare Unified Catalog o cercare Unified Catalog per visualizzare i dettagli dell'asset.
Dall'asset dell'area di lavoro databricks è possibile trovare anche il metastore Hive associato e le tabelle/viste invertite.
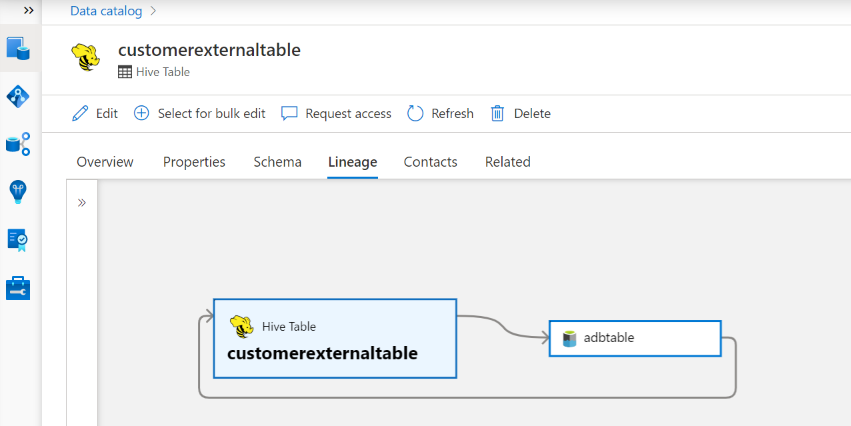
Derivazione
Vedere la sezione relativa alle funzionalità supportate negli scenari di Azure Databricks supportati. Per altre informazioni sulla derivazione in generale, vedere la guida dell'utente alla derivazione e alla derivazione dei dati.
Passare alla scheda Hive table/view asset -> derivazione. Se applicabile, è possibile visualizzare la relazione tra asset. Per la relazione tra gli asset di archiviazione esterni e di tabella, è possibile notare che l'asset di tabella Hive e l'asset di archiviazione sono connessi direttamente in modo bidirezionale, in quanto influiscono reciprocamente l'uno sull'altro. Se si usa il punto di montaggio nell'istruzione create table, è necessario fornire le informazioni sul punto di montaggio nelle impostazioni di analisi per estrarre tale relazione.
Passaggi successivi
Dopo aver registrato l'origine, usare le guide seguenti per altre informazioni su Microsoft Purview e sui dati: