Eseguire il training di un modello di codifica predittiva (anteprima)
Importante
Questo articolo si applica solo all'esperienza classica di eDiscovery. L'esperienza classica di eDiscovery verrà ritirata nell'agosto 2025 e non sarà disponibile come opzione di esperienza nel portale di Microsoft Purview dopo il ritiro.
È consigliabile iniziare a pianificare questa transizione in anticipo e iniziare a usare la nuova esperienza di eDiscovery nel portale di Microsoft Purview. Per altre informazioni sull'uso delle funzionalità e delle funzionalità di eDiscovery più recenti, vedere Informazioni su eDiscovery.
Importante
La codifica predittiva è stata ritirata a partire dal 31 marzo 2024 e non è disponibile nei nuovi casi di eDiscovery. Per i casi esistenti con modelli di codifica predittiva sottoposti a training, è possibile continuare ad applicare filtri di punteggio esistenti per esaminare i set. Tuttavia, non è possibile creare o eseguire il training di nuovi modelli.
Dopo aver creato un modello di codifica predittiva in Microsoft Purview eDiscovery (Premium), il passaggio successivo consiste nell'eseguire il primo round di training per eseguire il training del modello sui contenuti rilevanti e non rilevanti nel set di revisioni. Dopo aver completato il primo ciclo di training, è possibile eseguire cicli di training successivi per migliorare la capacità del modello di stimare il contenuto pertinente e non pertinente.
Per esaminare il flusso di lavoro di codifica predittiva, vedere Informazioni sulla codifica predittiva in eDiscovery (Premium)
Consiglio
Se non si è cliente E5, usa la versione di valutazione delle soluzioni Microsoft Purview di 90 giorni per esplorare in che modo funzionalità aggiuntive di Purview possono aiutare l'organizzazione a gestire le esigenze di sicurezza e conformità dei dati. Iniziare ora dall'hub delle versioni di valutazione di Microsoft Purview. Informazioni dettagliate sui termini di registrazione e prova.
Prima di eseguire il training di un modello
- Durante un round di training, etichettare gli elementi come Rilevanti o Non rilevanti in base alla pertinenza del contenuto nel documento. Non basare la decisione sui valori nei campi dei metadati. Ad esempio, per i messaggi di posta elettronica o le conversazioni di Teams, non basare la decisione di etichettatura sui partecipanti al messaggio.
Eseguire il training di un modello per la prima volta
Nota
Per un periodo di tempo limitato, l'esperienza classica di eDiscovery è disponibile nel nuovo portale di Microsoft Purview. Abilitare l'esperienza eDiscovery classica del portale Purview nelle impostazioni dell'esperienza eDiscovery per visualizzare l'esperienza classica nel nuovo portale di Microsoft Purview.
Nel portale di Microsoft Purview aprire un caso di eDiscovery (Premium) e quindi selezionare la scheda Set di revisione .
Aprire un set di revisione e quindi selezionareAnalytics Manage predictive coding (anteprima).Open a review set and then select Analytics> Manage predictive coding (preview).
Nella pagina Modelli di codifica predittiva (anteprima) selezionare il modello di cui si vuole eseguire il training.
Nella scheda Panoramica , in Round 1, selezionare Start next training round (Avvia prossimo turno di training).
Viene visualizzata la scheda Training che contiene 50 elementi da etichettare.
Esaminare ogni documento e quindi selezionare Pertinente o Non pertinente nella parte inferiore del riquadro di lettura per etichettarlo.
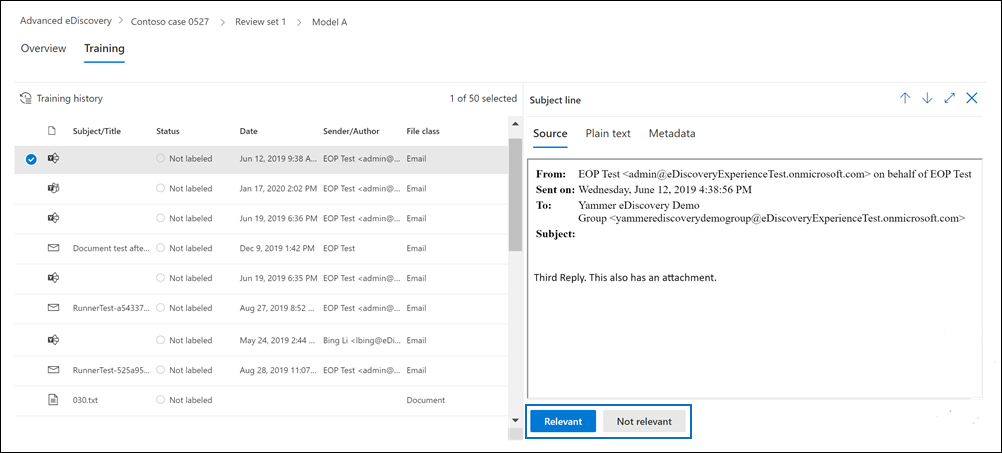
Dopo aver etichettato tutti i 50 elementi, selezionare Fine.
Il sistema "apprende" dall'etichettatura e aggiornerà il modello richiederà un paio di minuti. Al termine di questo processo, nella pagina Modelli di codifica predittiva (anteprima) viene visualizzato lo stato Pronto per il modello.
Eseguire cicli di training aggiuntivi
Dopo aver eseguito il primo turno di training, è possibile eseguire cicli di training successivi seguendo i passaggi descritti nella sezione precedente. L'unica differenza è che il numero del round di training verrà aggiornato nella scheda Panoramica del modello. Ad esempio, dopo aver eseguito il primo round di training, è possibile selezionare Avvia turno di training successivo per avviare il secondo turno di training. E così via.
Ogni ciclo di training (sia quelli in corso che quelli completati) viene visualizzato nella scheda Training per il modello. Quando si seleziona un round di training, viene visualizzata una pagina a comparsa con informazioni e metriche per il round.
Cosa accade dopo aver eseguito un round di training
Dopo aver eseguito il primo round di training, viene avviato un processo che esegue le operazioni seguenti:
In base a come sono stati etichettati i 40 elementi nel set di training, il modello apprende dall'etichettatura e si aggiorna per diventare più accurato.
Il modello elabora quindi ogni elemento nell'intero set di revisione e assegna un punteggio di stima compreso tra 0 (non pertinente) e 1 (pertinente).
Il modello assegna un punteggio di stima ai 10 elementi nel set di controlli etichettati durante il round di training. Il modello confronta il punteggio di stima di questi 10 elementi con l'etichetta effettiva assegnata all'elemento durante il round di training. In base a questo confronto, il modello identifica la classificazione seguente (denominata matrice di confusione set di controlli) per valutare le prestazioni di stima del modello:
| Etichetta | L'elemento di stima del modello è rilevante | L'elemento di stima del modello non è rilevante |
|---|---|---|
| L'elemento del revisore etichetta l'elemento come pertinente | Vero positivo | Falso positivo |
| Il revisore etichetta l'elemento come non pertinente | Falso negativo | Vero negativo |
In base a questi confronti, il modello deriva i valori per le metriche F-score, precision e recall e il margine di errore per ognuno di essi. I punteggi per queste metriche delle prestazioni del modello vengono visualizzati in una pagina a comparsa per il round di training. Per una descrizione di queste metriche, vedere Informazioni di riferimento sulla codifica predittiva.
- Infine, il modello determina i successivi 50 elementi che verranno usati per il prossimo round di training. Questa volta, il modello potrebbe selezionare 20 elementi dal set di controlli e 30 nuovi elementi dal set di revisione e designarli come set di training per il round successivo. Il campionamento per il turno di training successivo non viene campionato in modo uniforme. Il modello ottimizza la selezione del campionamento degli elementi del set di revisione per selezionare gli elementi in cui la stima è ambigua, ovvero il punteggio di stima è compreso nell'intervallo 0,5. Questo processo è noto come selezione distorta.
Cosa accade dopo aver eseguito i turni di training successivi
Dopo aver eseguito i turni di training successivi (dopo il primo round di training), il modello esegue le operazioni seguenti:
- Il modello viene aggiornato in base alle etichette applicate al set di training in tale ciclo di training.
- Il sistema valuta il punteggio di stima del modello sugli elementi nel set di controlli e controlla se il punteggio è allineato al modo in cui sono stati etichettati gli elementi nel set di controlli. La valutazione viene eseguita su tutti gli elementi etichettati del set di controlli per tutti i turni di training. I risultati di questa valutazione vengono incorporati nel dashboard nella scheda Panoramica del modello.
- Il modello aggiornato rielabora ogni elemento nel set di revisione e assegna a ogni elemento un punteggio di stima aggiornato.
Passaggi successivi
Dopo aver eseguito il primo round di training, è possibile eseguire più turni di training o applicare il filtro del punteggio di stima del modello al set di revisione per visualizzare gli elementi stimati dal modello come pertinenti o non pertinenti. Per altre informazioni, vedere Applicare un filtro del punteggio di stima a un set di revisione.