Utilizzare Archiviazione Premium di Azure con SQL Server in macchine virtuali
Panoramica
Le unità SSD Premium di Azure costituiscono la risorsa di archiviazione di nuova generazione che fornisce bassa latenza e I/O ad alta velocità. Funziona al meglio per i carichi di lavoro con numerose operazioni di I/O, ad esempio SQL Server in macchine virtualiIaaS.
Importante
Azure offre due modelli di distribuzione diversi per creare e usare le risorse: Resource Manager e distribuzione classica. Questo articolo illustra l'uso del modello di distribuzione classica. Microsoft consiglia di usare il modello di Gestione risorse per le distribuzioni più recenti.
In questo articolo sono fornite indicazioni per la migrazione di una macchina virtuale che esegue SQL Server per l’uso di Archiviazione Premium. Sono inclusi i passaggi relativi all'infrastruttura di Azure (rete, archiviazione) e alle macchine virtuali guest di Windows. Nell'esempio incluso nell' Appendice viene mostrata una migrazione end-to-end completa in cui le VM più grandi vengono spostate per sfruttare i vantaggi dell'archiviazione SSD locale migliorata con PowerShell.
È importante comprendere il processo end-to-end di utilizzo di Archiviazione Premium di Azure con SQL Server in macchine virtuali IAAS. ad esempio:
- Identificazione dei prerequisiti per l'utilizzo di Archiviazione Premium.
- Esempi di distribuzione di SQL Server su IaaS in Archiviazione Premium per nuove distribuzioni
- Esempi di migrazione delle distribuzioni esistenti, sia di server autonomi che distribuzioni tramite gruppi di disponibilità di SQL AlwaysOn.
- Approcci di migrazione possibili.
- Esempio end-to-end completo che mostra i passaggi di Azure, Windows e SQL Server per la migrazione di un'implementazione di AlwaysOn esistente.
Per ottenere le informazioni più esaustive sull'uso di SQL Server in Macchine virtuali di Azure, vedere SQL Server in Macchine virtuali di Azure.
Autore: Daniel Sol Revisori tecnici: Luis Carlos Vargas Herring, Sanjay Mishra, Pravin Mital, Juergen Thomas, Gonzalo Ruiz.
Prerequisiti per Archiviazione Premium
Esistono diversi prerequisiti per l'utilizzo di Archiviazione Premium.
Dimensioni della macchina
Per usare Archiviazione Premium occorre usare macchine virtuali (VM) serie DS. Se in precedenza non sono state utilizzate macchine serie DS nel servizio cloud, è necessario eliminare la macchina virtuale esistente, mantenere i dischi collegati e creare quindi un nuovo servizio cloud prima di ricreare la macchina virtuale con dimensioni del ruolo DS*. Per ulteriori informazioni sulle dimensioni della macchine virtuali, vedere Dimensioni delle macchine virtuali e dei servizi cloud per Azure.
Servizi cloud
È possibile utilizzare le macchine virtuali DS* con Archiviazione Premium solo quando vengono create in un nuovo servizio cloud. Se si usa SQL Server AlwaysOn in Azure, il listener AlwaysOn fa riferimento all'indirizzo IP del servizio di bilanciamento del carico interno o esterno di Azure associato a un servizio cloud. In questo articolo viene illustrato come eseguire la migrazione mantenendo la disponibilità in questo scenario.
Nota
Una macchina virtuale serie DS* deve essere la prima macchina virtuale distribuita nel nuovo servizio cloud.
Reti virtuali regionali
Per le macchine virtuali DS* è necessario configurare la rete virtuale (VNET) che ospita le macchine virtuali regionali. In tal modo si "amplia" la rete virtuale per consentire il provisioning delle macchine virtuali più grandi in altri cluster e permettere la comunicazione. Nella schermata seguente, la posizione evidenziata mostra le VNET regionali, mentre il primo risultato mostra una rete virtuale limitata.

È possibile generare un ticket di supporto Microsoft per eseguire la migrazione a una rete virtuale regionale. Microsoft quindi effettua una modifica. Per completare la migrazione alle reti virtuali regionali, modificare la proprietà AffinityGroup nella configurazione della rete. Esportare innanzitutto la configurazione di rete in PowerShell, quindi sostituire la proprietà AffinityGroup nell’elemento VirtualNetworkSite con una proprietà Location. Specificare Location = XXXX dove XXXX è un'area di Azure. Importare quindi la nuova configurazione.
Ad esempio, prendere in considerazione la seguente configurazione di rete virtuale:
<VirtualNetworkSite name="danAzureSQLnet" AffinityGroup="AzureSQLNetwork">
<AddressSpace>
<AddressPrefix>10.0.0.0/8</AddressPrefix>
<AddressPrefix>172.16.0.0/12</AddressPrefix>
</AddressSpace>
<Subnets>
...
</VirtualNetworkSite>
Per spostarla in una rete virtuale regionale in Europa occidentale, modificare la configurazione come segue:
<VirtualNetworkSite name="danAzureSQLnet" Location="West Europe">
<AddressSpace>
<AddressPrefix>10.0.0.0/8</AddressPrefix>
<AddressPrefix>172.16.0.0/12</AddressPrefix>
</AddressSpace>
<Subnets>
...
</VirtualNetworkSite>
Account di archiviazione
Occorre creare un nuovo account di archiviazione configurato per Archiviazione Premium. Si noti che l'utilizzo di Archiviazione Premium è impostato sull’account di archiviazione, non sui singoli dischi rigidi virtuali. Tuttavia, quando si utilizza una macchina virtuale serie DS* è possibile collegare i dischi rigidi virtuali dagli account di archiviazione Standard e Premium. Se non si desidera collocare il disco rigido virtuale del sistema operativo sull'account di Archiviazione Premium, è possibile valutare questa possibilità.
Il seguente comando New-AzureStorageAccountPowerShell con Type "Premium_LRS" consente di creare un account di Archiviazione Premium:
$newstorageaccountname = "danpremstor"
New-AzureStorageAccount -StorageAccountName $newstorageaccountname -Location "West Europe" -Type "Premium_LRS"
Impostazioni della cache di dischi rigidi virtuali
La differenza principale con la creazione di dischi che fanno parte di un account di Archiviazione Premium è l'impostazione della cache su disco. Per i dischi del volume di dati di SQL Server, è consigliabile usare "Read Caching". Per i volumi del log delle transazioni, l'impostazione della cache su disco deve essere "None". Questa impostazione differisce da quelle consigliate per gli account di archiviazione Standard.
Dopo aver collegato i dischi rigidi virtuali, l'impostazione della cache non può essere modificata. È necessario scollegare e ricollegare il disco rigido virtuale con un'impostazione di cache aggiornata.
Spazi di archiviazione di Windows
È possibile usare Spazi di archiviazione Windows come con la precedente Archiviazione Standard; questo consentirà di eseguire la migrazione di una VM che già usa Spazi di archiviazione. Nell'esempio riportato in Appendice (passaggio 9 e successivi) viene illustrato il codice di Powershell per estrarre e importare una macchina virtuale con più dischi rigidi virtuali collegati.
Sono stati utilizzati pool di archiviazione con account di archiviazione Azure Standard per migliorare la velocità effettiva e ridurre la latenza. Può essere utile testare i pool di archiviazione con Archiviazione Premium per le nuove distribuzioni, ma l’impostazione dell’archiviazione aggiunge ulteriore complessità.
Come individuare quali dischi virtuali di Azure sono mappati ai pool di archiviazione
Poiché esistono diverse indicazioni di impostazione della cache per i dischi rigidi virtuali collegati, è possibile copiare i dischi rigidi virtuali in un account di Archiviazione Premium. Tuttavia, quando vengono ricollegati alla nuova macchina virtuale serie DS, è necessario modificare le impostazioni della cache. È più semplice applicare le impostazioni della cache di Archiviazione Premium consigliate quando si dispone di dischi rigidi virtuali separati per i file di dati SQL e file di log (anziché di un singolo disco rigido virtuale che contiene entrambi).
Nota
Se si dispone di file di log e dati di SQL Server nello stesso volume, l'opzione di memorizzazione nella cache da scegliere dipende dai modelli di accesso I/O per i carichi di lavoro del database. Solo i test possono dimostrare quale opzione di memorizzazione nella cache è più adatta a questo scenario.
Se tuttavia si usano spazi di archiviazione di Windows costituiti da più dischi rigidi virtuali, è necessario esaminare gli script originali per identificare quali VHD collegati si trovano in un pool specifico in modo da poter impostare adeguatamente la cache per ogni disco.
Se non è disponibile lo script originale che mostra quali dischi rigidi virtuali sono mappati al pool di archiviazione, è possibile utilizzare la procedura seguente per determinare il mapping tra disco e pool di archiviazione.
Per ogni disco, attenersi alla procedura seguente:
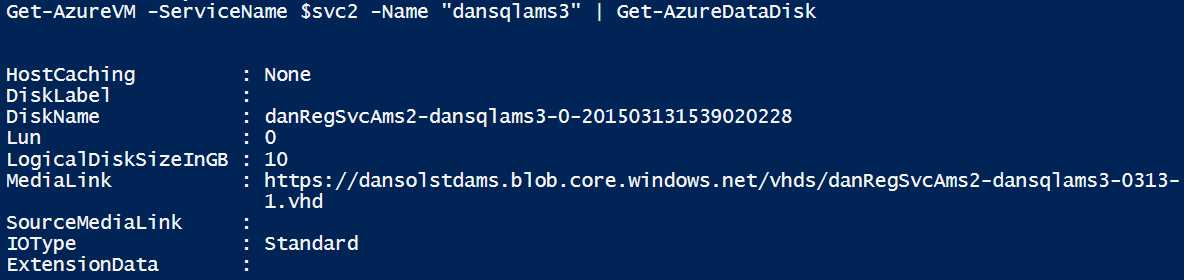
- Ottenere l’elenco di dischi collegati alla macchina virtuale con il comando Get-AzureVM :
Get-AzureVM -ServiceName <servicename> -Name <vmname> | Get-AzureDataDisk
Prendere nota del nome del disco e del LUN.
Desktop remoto nella macchina virtuale. Passare quindi a Gestione computer | Gestione dispositivi | Unità disco. Esaminare le proprietà di ciascun "Disco virtuale Microsoft"
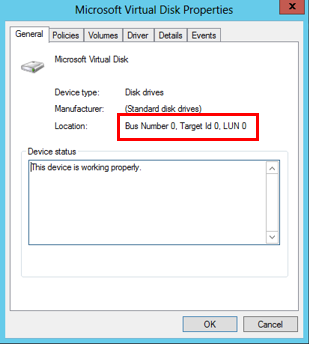
Il numero LUN è un riferimento al numero LUN specificato al momento del collegamento del disco rigido virtuale alla macchina virtuale.
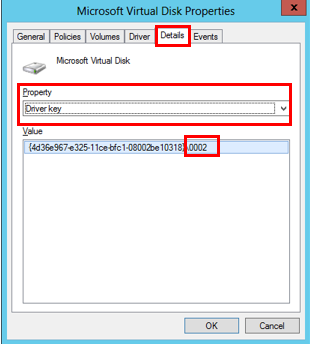
Per il "Disco virtuale Microsoft" andare alla scheda Dettagli, quindi nell’elenco Proprietà andare a Chiave driver. In Valore, notare l'Offset, ovvero 0002 nella schermata seguente. Il valore 0002 denota PhysicalDisk2 a cui fa riferimento il pool di archiviazione.
Per ogni del pool di archiviazione eseguire il dump dei dischi associati:
Get-StoragePool -FriendlyName AMS1pooldata | Get-PhysicalDisk

Ora è possibile utilizzare queste informazioni per collegare i dischi rigidi virtuali collegati ai dischi fisici nei pool di archiviazione.
Una volta eseguito il mapping dei dischi rigidi virtuali ai dischi fisici nei pool di archiviazione è possibile scollegarli e copiarli su un account di Archiviazione Premium e quindi collegarli con l'impostazione corretta della cache. Vedere l'esempio fornito in Appendice, passaggi da 8 a 12. Questi passaggi illustrano come estrarre una configurazione di disco rigido virtuale collegato alla macchina virtuale in un file CSV, copiare i dischi rigidi virtuali, modificare le impostazioni della cache di configurazione disco e infine ridistribuire la macchina virtuale come macchina virtuale serie DS con tutti i dischi collegati.
Larghezza di banda di archiviazione della VM e velocità effettiva di archiviazione del VHD
Le prestazioni dell’archiviazione dipendono dalle dimensioni della macchina virtuale DS* specificate e della dimensioni del disco rigido virtuale. Le VM hanno quote diverse per il numero di dischi rigidi virtuali che possono essere collegati e la larghezza di banda massima che supportano (MB/s). Per i numeri di larghezza di banda specifici, vedere Dimensioni delle macchine virtuali e dei servizi cloud per Azure.
Input/output al secondo maggiori si ottengono con dimensioni del disco maggiori. Tenere conto di questa considerazione quando si decide il percorso di migrazione. Per i dettagliate vedere la tabella per i tipi di disco e input/output al secondo.
Infine, tenere presente che le VM supportano larghezze di banda massime diverse per tutti i dischi collegati. Con un carico elevato si potrebbe saturare la larghezza di banda su disco massima disponibile per le dimensioni del ruolo di macchina virtuale. Ad esempio, Standard_DS14 supporta fino a 512 MB/s. Pertanto, con tre dischi P30 si potrebbe saturare la larghezza di banda del disco della VM. In questo esempio, tuttavia, il limite di velocità effettiva potrebbe essere superato a seconda della combinazione di I/O di lettura e scrittura.
Nuove distribuzioni
Nelle due sezioni successive viene illustrato come distribuire le macchine virtuali di SQL Server in Archiviazione Premium. Come affermato in precedenza, non occorre necessariamente collocare il disco del sistema operativo su Archiviazione Premium. È possibile eseguire questa operazione se si intende posizionare i carichi di lavoro con numerose operazioni di I/O sul disco rigido virtuale del sistema operativo.
Nel primo esempio viene illustrato l'utilizzo di immagini della raccolta Azure esistente. Nel secondo esempio viene illustrato come utilizzare un'immagine di macchina virtuale personalizzata disponibile in un account di archiviazione Standard esistente.
Nota
Questi esempi presuppongono che sia già stata creata una rete virtuale regionale.
Creare una nuova macchina virtuale con Archiviazione Premium con immagine della raccolta
Nell'esempio seguente viene illustrato come collocare il disco rigido virtuale di sistema operativo su Archiviazione Premium e collegare dischi rigidi virtuali di Archiviazione Premium. Tuttavia, è anche possibile collocare il disco del sistema operativo in un account di archiviazione Standard e quindi collegare dischi rigidi virtuali che risiedono in un account di Archiviazione Premium. Vengono illustrati entrambi gli scenari.
$mysubscription = "DansSubscription"
$location = "West Europe"
#Set up subscription
Set-AzureSubscription -SubscriptionName $mysubscription
Select-AzureSubscription -SubscriptionName $mysubscription -Current
Passaggio 1: creare un account di Archiviazione Premium
#Create Premium Storage account, note Type
$newxiostorageaccountname = "danspremsams"
New-AzureStorageAccount -StorageAccountName $newxiostorageaccountname -Location $location -Type "Premium_LRS"
Passaggio 2: creare un nuovo servizio cloud
$destcloudsvc = "danNewSvcAms"
New-AzureService $destcloudsvc -Location $location
Passaggio 3: riservare un indirizzo VIP di servizio cloud (facoltativo)
#check exisitng reserved VIP
Get-AzureReservedIP
$reservedVIPName = "sqlcloudVIP"
New-AzureReservedIP –ReservedIPName $reservedVIPName –Label $reservedVIPName –Location $location
Passaggio 4: creare un contenitore di macchine virtuali
#Generate storage keys for later
$xiostorage = Get-AzureStorageKey -StorageAccountName $newxiostorageaccountname
##Generate storage acc contexts
$xioContext = New-AzureStorageContext –StorageAccountName $newxiostorageaccountname -StorageAccountKey $xiostorage.Primary
#Create container
$containerName = 'vhds'
New-AzureStorageContainer -Name $containerName -Context $xioContext
Passaggio 5: collocare il disco rigido virtuale del sistema operativo su Archiviazione Standard o Premium
#NOTE: Set up subscription and default storage account which is used to place the OS VHD in
#If you want to place the OS VHD Premium Storage Account
Set-AzureSubscription -SubscriptionName $mysubscription -CurrentStorageAccount $newxiostorageaccountname
#If you wanted to place the OS VHD Standard Storage Account but attach Premium Storage VHDs then you would run this instead:
$standardstorageaccountname = "danstdams"
Set-AzureSubscription -SubscriptionName $mysubscription -CurrentStorageAccount $standardstorageaccountname
Passaggio 6: Creare una macchina virtuale
#Get list of available SQL Server Images from the Azure Image Gallery.
$galleryImage = Get-AzureVMImage | where-object {$_.ImageName -like "*SQL*2014*Enterprise*"}
$image = $galleryImage.ImageName
#Set up Machine Specific Information
$vmName = "dsDan1"
$vnet = "dansvnetwesteur"
$subnet = "SQL"
$ipaddr = "192.168.0.8"
#Remember to change to DS series VM
$newInstanceSize = "Standard_DS1"
#create new Availability Set
$availabilitySet = "cloudmigAVAMS"
#Machine User Credentials
$userName = "myadmin"
$pass = "mycomplexpwd4*"
#Create VM Config
$vmConfigsl = New-AzureVMConfig -Name $vmName -InstanceSize $newInstanceSize -ImageName $image -AvailabilitySetName $availabilitySet ` | Add-AzureProvisioningConfig -Windows ` -AdminUserName $userName -Password $pass | Set-AzureSubnet -SubnetNames $subnet | Set-AzureStaticVNetIP -IPAddress $ipaddr
#Add Data and Log Disks to VM Config
#Note the size specified '-DiskSizeInGB 1023', this attaches 2 x P30 Premium Storage Disk Type
#Utilising the Premium Storage enabled Storage account
$vmConfigsl | Add-AzureDataDisk -CreateNew -DiskSizeInGB 1023 -LUN 0 -HostCaching "ReadOnly" -DiskLabel "DataDisk1" -MediaLocation "https://$newxiostorageaccountname.blob.core.windows.net/vhds/$vmName-data1.vhd"
$vmConfigsl | Add-AzureDataDisk -CreateNew -DiskSizeInGB 1023 -LUN 1 -HostCaching "None" -DiskLabel "logDisk1" -MediaLocation "https://$newxiostorageaccountname.blob.core.windows.net/vhds/$vmName-log1.vhd"
#Create VM
$vmConfigsl | New-AzureVM –ServiceName $destcloudsvc -VNetName $vnet ## Optional (-ReservedIPName $reservedVIPName)
#Add RDP Endpoint
$EndpointNameRDPInt = "3389"
Get-AzureVM -ServiceName $destcloudsvc -Name $vmName | Add-AzureEndpoint -Name "EndpointNameRDP" -Protocol "TCP" -PublicPort "53385" -LocalPort $EndpointNameRDPInt | Update-AzureVM
#Check VHD storage account, these should be in $newxiostorageaccountname
Get-AzureVM -ServiceName $destcloudsvc -Name $vmName | Get-AzureDataDisk
Get-AzureVM -ServiceName $destcloudsvc -Name $vmName |Get-AzureOSDisk
Creare una nuova VM per usare Archiviazione Premium con un'immagine personalizzata
Questo scenario mostra la posizione delle immagini personalizzate esistenti che risiedono in un account di Archiviazione Standard. Come accennato, se si intende collocare il disco rigido virtuale del sistema operativo su Archiviazione Premium, è necessario copiare l'immagine esistente nell'account di Archiviazione Standard e trasferirlo a una Archiviazione Premium prima che possa essere usato. Se si dispone di un'immagine locale, è possibile usare questo metodo per copiarla direttamente nell'account di archiviazione Premium.
Passaggio 1: Creare un account di archiviazione
$mysubscription = "DansSubscription"
$location = "West Europe"
#Create Premium Storage account
$newxiostorageaccountname = "danspremsams"
New-AzureStorageAccount -StorageAccountName $newxiostorageaccountname -Location $location -Type "Premium_LRS"
#Standard Storage account
$origstorageaccountname = "danstdams"
Passaggio 2: Creare il servizio cloud
$destcloudsvc = "danNewSvcAms"
New-AzureService $destcloudsvc -Location $location
Passaggio 3: usare l'immagine esistente
È possibile utilizzare un'immagine esistente. In alternativa è possibile acquisire un'immagine di una macchina esistente. Si noti che la macchina non deve essere DS*. Dopo aver creato l'immagine, la procedura seguente illustra come copiarla nell'account di archiviazione Premium con il cmdlet Start-AzureStorageBlobCopy di PowerShell.
#Get storage account keys:
#Standard Storage account
$originalstorage = Get-AzureStorageKey -StorageAccountName $origstorageaccountname
#Premium Storage account
$xiostorage = Get-AzureStorageKey -StorageAccountName $newxiostorageaccountname
#Set up contexts for the storage accounts:
$origContext = New-AzureStorageContext –StorageAccountName $origstorageaccountname -StorageAccountKey $originalstorage.Primary
$destContext = New-AzureStorageContext –StorageAccountName $newxiostorageaccountname -StorageAccountKey $xiostorage.Primary
Passaggio 4: copiare BLOB tra account di archiviazione
#Get Image VHD
$myImageVHD = "dansoldonorsql2k14-os-2015-04-15.vhd"
$containerName = 'vhds'
#Copy Blob between accounts
$blob = Start-AzureStorageBlobCopy -SrcBlob $myImageVHD -SrcContainer $containerName `
-DestContainer vhds -Destblob "prem-$myImageVHD" `
-Context $origContext -DestContext $destContext
Passaggio 5: verificare regolarmente lo stato della copia:
$blob | Get-AzureStorageBlobCopyState
Passaggio 6: aggiungere il disco di immagine al repository dischi di Azure in Sottoscrizione
$imageMediaLocation = $destContext.BlobEndPoint+"/"+$myImageVHD
$newimageName = "prem"+"dansoldonorsql2k14"
Add-AzureVMImage -ImageName $newimageName -MediaLocation $imageMediaLocation
Nota
È possibile che si verifichino errori di lease del disco anche se i report di stato indicano un esisto positivo. In questo caso, attendere circa 10 minuti.
Passaggio 7: Compilare la macchina virtuale
Si compila la macchina virtuale da un'immagine e si collegano due dischi rigidi virtuali di Archiviazione Premium:
$newimageName = "prem"+"dansoldonorsql2k14"
#Set up Machine Specific Information
$vmName = "dansolchild"
$vnet = "westeur"
$subnet = "Clients"
$ipaddr = "192.168.0.41"
#This needs to be a new cloud service
$destcloudsvc = "danregsvcamsxio2"
#Use to DS Series VM
$newInstanceSize = "Standard_DS1"
#create new Availability Set
$availabilitySet = "cloudmigAVAMS3"
#Machine User Credentials
$userName = "myadmin"
$pass = "theM)stC0mplexP@ssw0rd!"
#Create VM Config
$vmConfigsl2 = New-AzureVMConfig -Name $vmName -InstanceSize $newInstanceSize -ImageName $newimageName -AvailabilitySetName $availabilitySet ` | Add-AzureProvisioningConfig -Windows ` -AdminUserName $userName -Password $pass | Set-AzureSubnet -SubnetNames $subnet | Set-AzureStaticVNetIP -IPAddress $ipaddr
$vmConfigsl2 | Add-AzureDataDisk -CreateNew -DiskSizeInGB 1023 -LUN 0 -HostCaching "ReadOnly" -DiskLabel "DataDisk1" -MediaLocation "https://$newxiostorageaccountname.blob.core.windows.net/vhds/$vmName-Datadisk-1.vhd"
$vmConfigsl2 | Add-AzureDataDisk -CreateNew -DiskSizeInGB 1023 -LUN 1 -HostCaching "None" -DiskLabel "LogDisk1" -MediaLocation "https://$newxiostorageaccountname.blob.core.windows.net/vhds/$vmName-logdisk-1.vhd"
$vmConfigsl2 | New-AzureVM –ServiceName $destcloudsvc -VNetName $vnet
Distribuzioni esistenti che non usano i gruppi di disponibilità AlwaysOn
Nota
Per le distribuzioni esistenti, vedere prima la sezione Prerequisiti di questo articolo.
Esistono diverse considerazioni per le distribuzioni di SQL Server che non usano i gruppi di disponibilità AlwaysOn e per quelle che li usano. Se non si usa AlwaysOn ed è disponibile un SQL Server autonomo esistente, si può eseguire l'aggiornamento ad Archiviazione Premium con un nuovo servizio cloud e un account di archiviazione. Valutare le opzioni seguenti:
- Creare una nuova macchina virtuale di SQL Server. È possibile creare una nuova macchina virtuale di SQL Server che utilizza un account di Archiviazione Premium, come documentato in Nuove distribuzioni. Eseguire il backup e il ripristino della configurazione di SQL Server e dei database utente. L'applicazione deve essere aggiornata per fare riferimento al nuovo SQL Server se si accede internamente o esternamente. È necessario copiare tutti gli oggetti esterni al db, come se si eseguisse una migrazione di SQL Server SxS (Side by Side). Sono inclusi oggetti come account di accesso, certificati e server collegati.
- Eseguire la migrazione di una macchina virtuale di Server SQL esistente. È necessario disconnettere la VM di SQL Server e trasferirla in un nuovo servizio cloud, operazione che implica la copia di tutti i relativi dischi rigidi virtuali collegati all'account di Archiviazione Premium. Quando la VM torna online, l'applicazione fa riferimento al nome host del server come prima. Tenere presente che le dimensioni del disco esistente influiscono sulle prestazioni. Ad esempio, un disco di 400 GB viene arrotondato per eccesso a un P20. Se si sa che tali prestazioni del disco non sono necessarie, è possibile ricreare la macchina virtuale come macchina virtuale serie DS e collegare dischi rigidi di archiviazione virtuale di Archiviazione Premium con le prestazioni/dimensioni desiderate. È quindi possibile scollegare e ricollegare i file di database SQL.
Nota
Quando si copiano i dischi rigidi virtuali, è necessario fare attenzione alle dimensioni, in quanto indicano in quale tipo di disco di Archiviazione Premium rientrano, determinando la specifica delle prestazioni del disco. Azure arrotonda alla dimensione del disco più vicina, per cui un disco di 400 GB viene arrotondato a un P20. A seconda dei requisiti di I/O esistenti del disco rigido virtuale del sistema operativo, potrebbe essere necessario eseguirne la migrazione a un account di Archiviazione Premium.
Se si accede esternamente a SQL Server, viene modificato l'indirizzo VIP del servizio cloud. È anche necessario aggiornare le impostazioni di endpoint, ACL e DNS.
Distribuzioni esistenti che usano i gruppi di disponibilità AlwaysOn
Nota
Per le distribuzioni esistenti, vedere prima la sezione Prerequisiti di questo articolo.
In questa sezione viene analizzato prima di tutto in che modo AlwaysOn interagisce con una rete di Azure. Verranno poi descritte le migrazioni in due scenari: migrazioni in cui viene considerato tollerabile un certo tempo di inattività e migrazioni in cui è necessario che i tempi di inattività siano minimi.
I gruppi di disponibilità di SQL Server AlwaysOn locali usano un listener locale che registra un nome DNS virtuale con un indirizzo IP condiviso tra uno o più server SQL. Quando si connettono i client vengono indirizzati attraverso l’IP del listener a SQL Server primario. Si tratta del server a cui appartiene la risorsa IP AlwaysOn in quel momento.
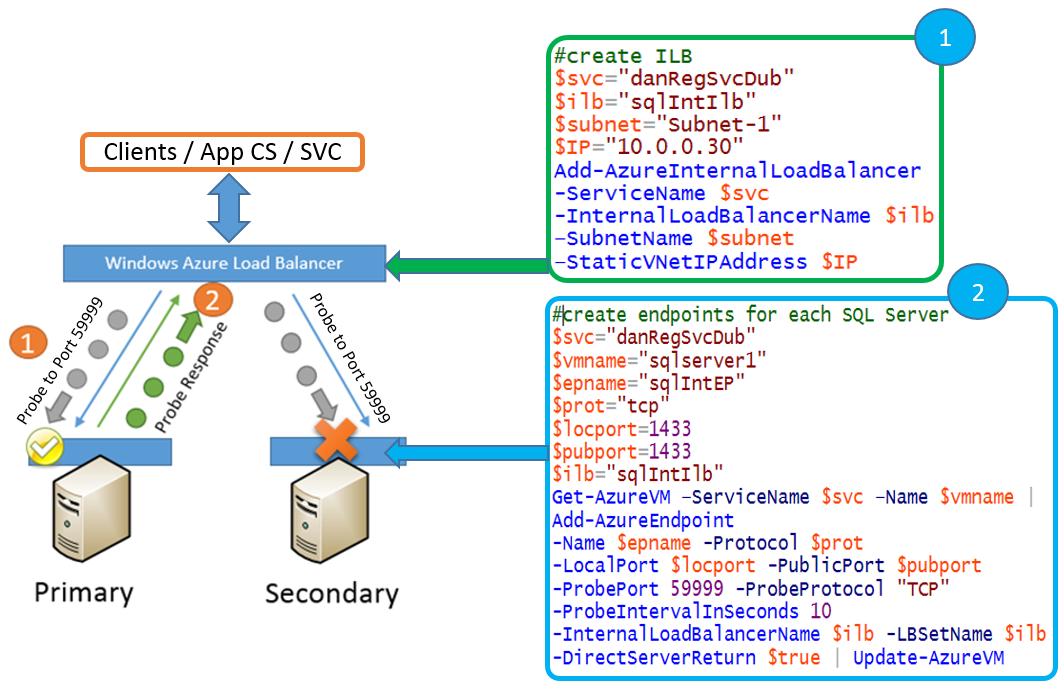
In Microsoft Azure è consentito un solo indirizzo IP assegnato a una scheda di rete nella macchina virtuale, pertanto per conseguire lo stesso livello di astrazione possibile in locale, Azure utilizza l'indirizzo IP assegnato ai servizi di bilanciamento del carico interno ed esterno (ILB/ELB). La risorsa IP condivisa tra i server viene impostata sullo stesso IP del servizio ILB/ELB, che viene pubblicato nel DNS, e il traffico del client viene passato attraverso il servizio ILB/ELB alla replica di SQL Server primario. Il servizio ILB/ELB riconosce l'istanza di SQL Server primaria, perché usa i probe per verificare la presenza della risorsa IP AlwaysOn. Nell'esempio precedente, verifica ogni nodo che dispone di un endpoint a cui fa riferimento il servizio ELB/ILB. Quello che risponde è il Server SQL primario.
Nota
Il servizio ILB e il servizio ELB vengono assegnati a un servizio cloud di Azure specifico, pertanto qualsiasi migrazione cloud in Azure comporta probabilmente la modifica dell'IP del servizio di bilanciamento del carico.
Migrazione delle distribuzioni di AlwaysOn che tollerano tempi di inattività
Sono disponibili due strategie per eseguire la migrazione delle distribuzioni di AlwaysOn che consentono periodi di inattività:
- Aggiungere più repliche secondarie a un cluster AlwaysOn esistente
- Eseguire la migrazione a un nuovo cluster AlwaysOn
1. Aggiungere più repliche secondarie a un cluster AlwaysOn esistente
Una strategia consiste nell'aggiungere più repliche secondarie al gruppo di disponibilità AlwaysOn. È necessario aggiungere questi elementi in un nuovo servizio cloud e aggiornare il listener con il nuovo IP del servizio di bilanciamento carico.
Punti dei tempi di inattività:
- Convalida del cluster.
- Test di failover AlwaysOn per nuovi database secondari.
Se si usano pool di archiviazione di Windows nella VM per una velocità effettiva I/O superiore, questi vengono portati offline durante una convalida completa del cluster. Il test di convalida è necessario quando si aggiungono nodi al cluster. Il tempo necessario per eseguire il test può variare, pertanto verificarlo nell'ambiente di test rappresentativo per ottenere una stima approssimativa della durata.
È necessario prevedere tempo per eseguire il failover manuale e test CHAOS sui nodi appena aggiunti per assicurarsi che la disponibilità elevata AlwaysOn funzioni come previsto.
Nota
Prima che venga eseguita la convalida è necessario arrestare tutte le istanze di SQL Server in cui vengono usati i pool di archiviazione.
Procedure generali
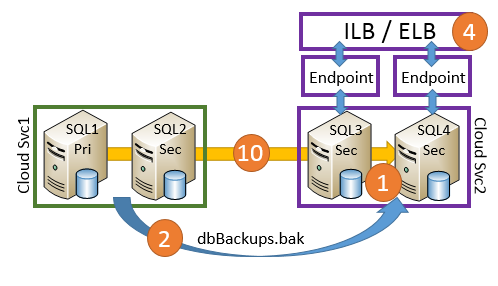
Creare due nuovi server SQL Server nel nuovo servizio cloud con Archiviazione Premium collegata.
Copiare i backup completi e ripristinare con NORECOVERY.
Copiare gli oggetti dipendenti esterni al database utente, ad esempio nomi di accesso e così via.
Crea un nuovo servizio di carico bilanciamento interno (ILB) oppure utilizzare un servizio di bilanciamento del carico esterno (ELB) e quindi impostare gli endpoint con bilanciamento del carico in entrambi i nodi nuovi.
Nota
Prima di continuare, verificare che tutti i nodi abbiano la configurazione dell'endpoint corretta
Impedire all'utente/applicazione l’accesso a SQL Server (se si utilizzano pool di archiviazione).
Arrestare i servizi motore di SQL Server in tutti i nodi (se si utilizzano il pool di archiviazione).
Aggiungere nuovi nodi al cluster ed eseguire la convalida completa.
Quando la convalida ha esito positivo, avviare tutti i servizi di SQL Server.
Eseguire il backup dei log delle transazioni e ripristinare i database utente.
Aggiungere nuovi nodi nel gruppo di disponibilità AlwaysOn e impostare la replica come sincrona.
Aggiungere la risorsa indirizzo IP del nuovo ILB/ELB del servizio cloud tramite PowerShell per AlwaysOn in base all'esempio multisito riportato nell' Appendice. Nel clustering di Windows impostare i Proprietari possibili della risorsa Indirizzo IP sui nuovi nodi. Vedere la sezione "Aggiunta della risorsa indirizzo IP nella stessa subnet" in Appendice.
Failover su uno dei nuovi nodi.
Impostare i nuovi nodi come Partner di failover automatico e testare i failover.
Rimuovere i nodi originali dal gruppo di disponibilità.
Vantaggi
- Nuovi SQL Server possono essere testati (SQL Server e applicazione) prima di essere aggiunti a AlwaysOn.
- È possibile modificare le dimensioni della macchina virtuale e personalizzare la risorsa di archiviazione per i requisiti specifici. Tuttavia, sarebbe opportuno mantenere tutti i percorsi di file SQL inalterati.
- È possibile controllare quando viene avviato il trasferimento dei backup del database alle repliche secondarie. Questo comportamento è diverso dal quello del commandlet di Azure Start-AzureStorageBlobCopy per copiare i dischi rigidi virtuali perché in quest’ultimo caso la copia è asincrona.
Svantaggi
- Quando si utilizzano pool di archiviazione di Windows, durante la convalida del cluster completo si verifica un tempo di inattività del cluster per i nuovi nodi aggiuntivi.
- A seconda della versione di SQL Server e del numero di repliche secondarie esistenti, potrebbe non essere possibile aggiungere ulteriori repliche secondarie senza rimuovere i le repliche secondarie esistenti.
- Il tempo di trasferimento dei dati SQL potrebbe essere molto lungo durante la configurazione di repliche secondarie.
- Esiste un costo aggiuntivo durante la migrazione mentre le nuove macchine vengono eseguite in parallelo.
2. Eseguire la migrazione a un nuovo cluster AlwaysOn
Un'altra strategia consiste nel creare un nuovo cluster AlwaysOn con nuovi nodi nel nuovo servizio cloud e quindi reindirizzare i client in modo che lo usino.
Punti dei tempi di inattività
Quando si trasferiscono utenti e applicazioni al nuovo listener AlwaysOn, si verifica un tempo di inattività. Il tempo di inattività dipende da:
- Il tempo necessario per ripristinare i backup dei log delle transazioni finali nei database in nuovi server.
- Il tempo impiegato per aggiornare le applicazioni client in modo che usino il nuovo listener AlwaysOn.
Vantaggi
- È possibile testare l'ambiente di produzione reale, SQL Server e le modifiche del build del sistema operativo.
- È possibile personalizzare l'archiviazione e ridurre le dimensioni della macchina virtuale. Ciò potrebbe causare determinare una riduzione dei costi.
- Durante questo processo, è possibile aggiornare il build o la versione di SQL Server. È inoltre possibile aggiornare il sistema operativo.
- Il cluster AlwaysOn precedente può fungere da destinazione di rollback.
Svantaggi
- È necessario modificare il nome DNS del listener, se si vuole che entrambi i cluster AlwaysOn vengano eseguiti contemporaneamente. Ciò comporta un sovraccarico di amministrazione durante la migrazione perché le stringhe dell’applicazione client devono riflettere il nuovo nome del listener.
- È necessario implementare un meccanismo di sincronizzazione tra i due ambienti per mantenerli quanto più vicini è possibile al fine di ridurre al minimo i requisiti di sincronizzazione finale prima della migrazione.
- Esiste un costo aggiunto durante la migrazione mentre il nuovo ambiente è in esecuzione.
Migrazione delle distribuzioni AlwaysOn per un tempo di inattività minimo
Sono disponibili due strategie per la migrazione delle distribuzioni di AlwaysOn per un tempo di inattività minimo:
- Usare una replica secondaria esistente: sito singolo
- Usare una o più repliche secondarie esistenti: multisito
1. Usare una replica secondaria esistente: sito singolo
Una strategia per il tempo di inattività minimo consiste nel rimuovere una replica secondaria del cloud esistente dal servizio cloud corrente. Successivamente si copiano i dischi rigidi virtuali nel nuovo account di Archiviazione Premium e si crea la macchina virtuale nel nuovo servizio cloud. A questo punto, si aggiorna il listener in clustering e failover.
Punti dei tempi di inattività
- Quando si aggiorna il nodo finale con l'endpoint di bilanciamento del carico, si verifica un tempo di inattività.
- La riconnessione del client potrebbe essere rimandata a seconda della configurazione client/DNS.
- Un tempo di inattività aggiuntivo si verifica se si sceglie di portare offline il gruppo di cluster AlwaysOn per sostituire gli indirizzi IP. È possibile evitare questa situazione usando una dipendenza OR e possibili proprietari per la risorsa indirizzo IP aggiunto. Vedere la sezione "Aggiunta della risorsa indirizzo IP nella stessa subnet" in Appendice.
Nota
Quando si vuole che il nodo aggiunto partecipi come partner di failover AlwaysOn, è necessario aggiungere un endpoint di Azure con un riferimento al set con carico bilanciato. Quando si esegue il comando Add-AzureEndpoint per questa operazione, le connessioni correnti restano aperte, ma non sarà possibile stabilire nuove connessioni fino a quando non verrà aggiornato il bilanciamento del carico. Nel test questo processo è durato 90-120 secondi; è opportuno verificare questa durata.
Vantaggi
- Nessun costo aggiuntivo durante la migrazione.
- Una migrazione uno a uno.
- Minore complessità.
- Consente un maggiore IOPS dalle SKU di Archiviazione Premium. Quando i dischi sono disconnessi dalla macchina virtuale e copiati nel nuovo servizio cloud, è possibile utilizzare uno strumento di terze parti per aumentare le dimensioni del disco rigido virtuale, fornendo una maggiore velocità effettiva. Per aumentare le dimensioni del disco rigido virtuale, vedere questo forum di discussione.
Svantaggi
- Perdita temporanea di disponibilità elevata e ripristino di emergenza durante la migrazione.
- Poiché si tratta di una migrazione 1:1, è necessario usare una dimensione minima di VM che supporti il numero di dischi rigidi virtuali presenti, pertanto potrebbe non essere possibile ridurre le dimensioni delle VM.
- Questo scenario prevede l’uso del commandlet Start-AzureStorageBlobCopy di Azure, che è asincrono. Non esiste alcun contratto di servizio al completamento della copia. Il tempo delle copie varia perché dipende dal tempo di attesa in coda e dalla quantità di dati da trasferire. Il tempo di copia aumenta se la destinazione del trasferimento è un altro centro dati di Azure che supporta Archiviazione Premium in un'altra area. Se si dispone solo di due nodi, valutare la possibilità di un’attenuazione per l’eventualità che la copia richieda più tempo durante i test. Valutare, ad esempio, le possibilità seguenti.
- Aggiungere un terzo nodo di SQL Server temporaneo per la disponibilità elevata prima della migrazione con tempi di inattività concordati.
- Eseguire la migrazione all'esterno della manutenzione pianificata di Azure.
- Assicurarsi di che avere configurato correttamente il quorum del cluster.
Procedure generali
In questo documento non viene illustrato un esempio end-to-end completo. Nella sezione Appendice, tuttavia, sono forniti dettagli che possono essere usati per eseguire questo tipo di migrazione.

- Raccogliere la configurazione del disco e rimuovere il nodo (non eliminare i dischi rigidi virtuali collegati).
- Creare un account di Archiviazione Premium e copiare i dischi rigidi virtuali dall'account di Archiviazione Standard
- Creare il nuovo servizio cloud e ridistribuire la macchina virtuale SQL2 in tale servizio cloud. Creare la macchina virtuale utilizzando la copia del disco rigido virtuale del sistema operativo originale e collegare i dischi rigidi virtuali copiati.
- Configurare ILB/ELB e aggiungere gli endpoint.
- Aggiornare il listener in uno dei modi seguenti:
- Portare offline il gruppo AlwaysOn e aggiornare il listener di AlwaysOn con il nuovo indirizzo IP ILB/ELB.
- Aggiungere la risorsa indirizzo IP del servizio ILB/ELB del nuovo servizio cloud tramite PowerShell nel clustering di Windows. Quindi impostare i possibili proprietari della risorsa indirizzo IP sul nodo migrato, SQL2, e impostare tale nodo come dipendenza OR nel nome di rete. Vedere la sezione "Aggiunta della risorsa indirizzo IP nella stessa subnet" in Appendice.
- Controllare la configurazione DNS/propagazione ai client.
- Eseguire la migrazione della macchina virtuale SQL1 ed effettuare i passaggi da 2 a 4.
- Se si utilizzano i passaggi 5ii, aggiungere SQL1 come possibile proprietario per la risorsa indirizzo IP aggiunto
- Testare i failover.
2. Usare una o più repliche secondarie esistenti: Multisito
Se sono disponibili nodi in più data center di Azure o se è disponibile un ambiente ibrido, si può usare una configurazione AlwaysOn in questo ambiente per ridurre al minimo i tempi di inattività.
L'approccio consiste nel cambiare in sincrona la sincronizzazione di AlwaysOn per il data center di Azure locale o secondario e quindi eseguire il failover in tale SQL Server. Copiare quindi i dischi rigidi virtuali in un account di Archiviazione Premium e ridistribuire la macchina in un nuovo servizio cloud. Aggiornare il listener ed eseguire il failback.
Punti dei tempi di inattività
Il tempo di inattività corrisponde al tempo necessario per il failover al centro dati alternativo e ritorno. Dipende anche dalla configurazione del client/DNS e potrebbe determinare un ritardo della riconnessione del client. Si consideri l'esempio seguente di una configurazione di AlwaysOn ibrida:

Vantaggi
- È possibile utilizzare l'infrastruttura esistente.
- È possibile pre-aggiornare Archiviazione di Azure nel centro dati di Azure di ripristino di emergenza.
- È possibile riconfigurare l'archiviazione del centro dati di Azure di ripristino di emergenza.
- Esiste un minimo di due failover durante la migrazione, esclusi i failover di test.
- Non è necessario spostare i dati di SQL Server con backup e ripristino.
Svantaggi
- A seconda dell’accesso client a SQL Server, potrebbe esserci un aumento della latenza durante l'esecuzione di SQL Server in un centro dati alternativo per l'applicazione.
- Il tempo di copia dei dischi rigidi virtuali in Archiviazione Premium potrebbe essere lungo. Ciò potrebbe influire sulla decisione relativa al mantenimento del nodo nel gruppo di disponibilità. Considerare questo aspetto quando carichi di lavoro a uso intensivo di log vengono eseguiti durante le migrazioni richieste, dal momento che il nodo primario deve mantenere le transazioni non replicate nel proprio log delle transazioni, aumentando così in modo significativo.
- Questo scenario prevede l’uso del commandlet Start-AzureStorageBlobCopy di Azure, che è asincrono. Non esiste alcun contratto di servizio al completamento. Il tempo delle copie varia, perché dipende dal tempo di attesa in coda e dalla quantità di dati da trasferire. Di conseguenza, dal momento che si dispone di un solo nodo nel secondo centro dati, è opportuno prevedere operazioni di attenuazione per l’eventualità che la copia richieda più tempo durante i test. Questi passaggi di mitigazione includono i concetti seguenti:
- Aggiungere un secondo nodo di SQL Server temporaneo per la disponibilità elevata prima della migrazione con tempi di inattività concordati.
- Eseguire la migrazione all'esterno della manutenzione pianificata di Azure.
- Assicurarsi di che avere configurato correttamente il quorum del cluster.
Questo scenario presuppone di aver documentato l'installazione e che si sappia come viene eseguito il mapping dell’archiviazione in modo da poter apportare le modifiche necessarie a definire impostazioni della cache su disco ottimali.
Procedure generali

- Rendere il centro dati di Azure locale/alternativo l'SQL Server primario e l’altro partner di failover automatico.
- Raccogliere la configurazione del disco da SQL2 e rimuovere il nodo (non eliminare i dischi rigidi virtuali collegati).
- Creare un account di Archiviazione Premium e copiare i dischi rigidi virtuali dall'account di Archiviazione Standard.
- Creare un nuovo servizio cloud e la macchina virtuale SQL2 con relativi dischi di archiviazione Premium collegati.
- Configurare ILB/ELB e aggiungere gli endpoint.
- Aggiornare il listener di AlwaysOn con nuovo il indirizzo IP ILB/ELB e testare il failover.
- Controllare la configurazione DNS.
- Modificare l'AFP in SQL2, quindi eseguire la migrazione di SQL1 ed eseguire i passaggi da 2 a 5.
- Testare i failover.
- Riportare l'AFP a SQL1 e SQL2
Appendice: migrazione di un cluster AlwaysOn multisito ad Archiviazione Premium
La parte restante di questo articolo fornisce un esempio dettagliato della conversione di un cluster AlwaysOn multisito all'Archiviazione Premium. Il listener, inoltre, viene passato dall’uso di un servizio di bilanciamento del carico esterno (ELB) all’uso di un servizio di bilanciamento del carico interno (ILB).
Environment
- Windows 2K12 /SQL 2K12
- 1 File DB su SP
- 2 pool di archiviazione per ogni nodo

VM:
In questo esempio viene illustrato lo spostamento da un ELB a un ILB. ELB era disponibile prima di ILB, pertanto viene illustrato come eseguire il passaggio a ILB durante la migrazione.

Passaggi precedenti: connettersi a Sottoscrizione
Add-AzureAccount
#Set up subscription
Get-AzureSubscription
Passaggio 1: creare un nuovo account di archiviazione e un nuovo servizio cloud
$mysubscription = "DansSubscription"
$location = "West Europe"
#Storage accounts
#current storage account where the vm to migrate resides
$origstorageaccountname = "danstdams"
#Create Premium Storage account
$newxiostorageaccountname = "danspremsams"
New-AzureStorageAccount -StorageAccountName $newxiostorageaccountname -Location $location -Type "Premium_LRS"
#Generate storage keys for later
$originalstorage = Get-AzureStorageKey -StorageAccountName $origstorageaccountname
$xiostorage = Get-AzureStorageKey -StorageAccountName $newxiostorageaccountname
#Generate storage acc contexts
$origContext = New-AzureStorageContext –StorageAccountName $origstorageaccountname -StorageAccountKey $originalstorage.Primary
$xioContext = New-AzureStorageContext –StorageAccountName $newxiostorageaccountname -StorageAccountKey $xiostorage.Primary
#Set up subscription and default storage account
Set-AzureSubscription -SubscriptionName $mysubscription -CurrentStorageAccount $origstorageaccountname
Select-AzureSubscription -SubscriptionName $mysubscription -Current
#CREATE NEW CLOUD SVC
$vnet = "dansvnetwesteur"
##Existing cloud service
$sourceSvc="dansolSrcAms"
##Create new cloud service
$destcloudsvc = "danNewSvcAms"
New-AzureService $destcloudsvc -Location $location
Passaggio 2: Aumentare gli errori consentiti nelle risorse <Facoltativo>
In alcune risorse che appartengono al gruppo di disponibilità AlwaysOn sono previsti limiti al numero di errori che possono verificarsi in un intervallo di tempo durante il quale il servizio cluster prova a riavviare il gruppo di risorse. Si consiglia di aumentare questo numero durante l’esecuzione di questa procedura poiché se non si esegue il failover manuale e non si attivano i failover arrestando le macchine si potrebbe raggiungere il limite.
Sarebbe prudente raddoppiare la quantità di errori consentita. A questo scopo, in Gestione cluster di failover passare alle proprietà del gruppo di risorse AlwaysOn:
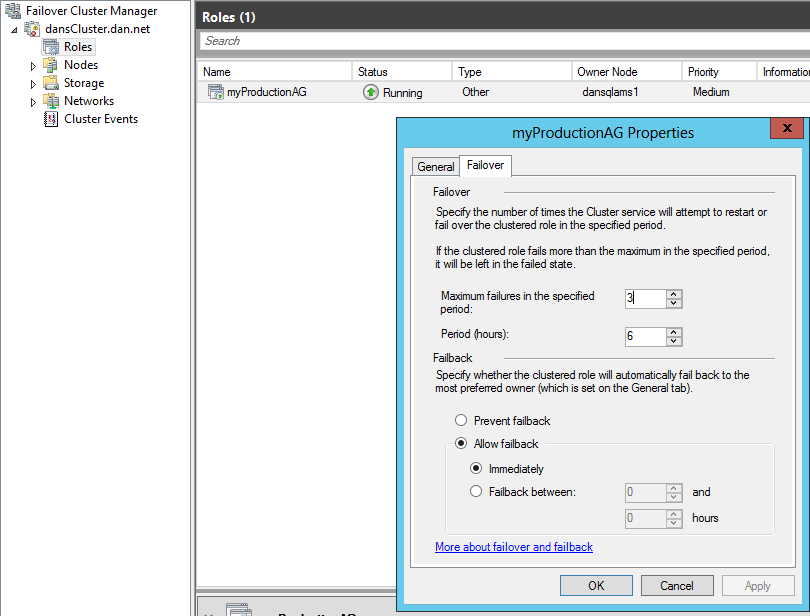
Modificare il numero massimo di errori in 6.
Passaggio 3: Aggiunta della risorsa indirizzo IP per il gruppo di <cluster facoltativo>
Con un solo indirizzo IP per il gruppo cluster, se viene allineato alla subnet cloud, tenere presente che se si portano accidentalmente offline tutti i nodi del cluster nel cloud nella rete, la risorsa IP del cluster e il nome di rete del cluster non potranno essere portati online. In questo caso vengono impediti gli aggiornamenti ad altre risorse cluster.
Passaggio 4: Configurazione del DNS
L'implementazione di una transizione senza intoppi dipende dalla modalità di uso e aggiornamento del DNS. Quando viene installato AlwaysOn, crea un gruppo di risorse cluster di Windows. Se si apre Gestione cluster di failover, si nota la presenza di almeno tre risorse. Le due a cui fa riferimento il documento sono:
- Nome di rete virtuale: nome DNS a cui si connette il client quando si sceglie di stabilire la connessione a SQL Server tramite AlwaysOn.
- Risorsa indirizzo IP: indirizzo IP associato al nome di rete virtuale; possono essere più di uno e in una configurazione multisito è presente un indirizzo IP per sito/subnet.
Quando ci si connette a SQL Server, il driver del client SQL Server recupera i record DNS associati al listener e prova a connettersi a ogni indirizzo IP associato a AlwaysOn. Di seguito sono illustrati alcuni fattori che possono influenzare questa situazione.
Il numero di record DNS simultanei associati al nome del listener dipende non solo dal numero di indirizzi IP associati, ma anche dall'impostazione "RegisterAllIpProviders" in Clustering di failover per la risorsa nome di rete virtuale di AlwaysOn.
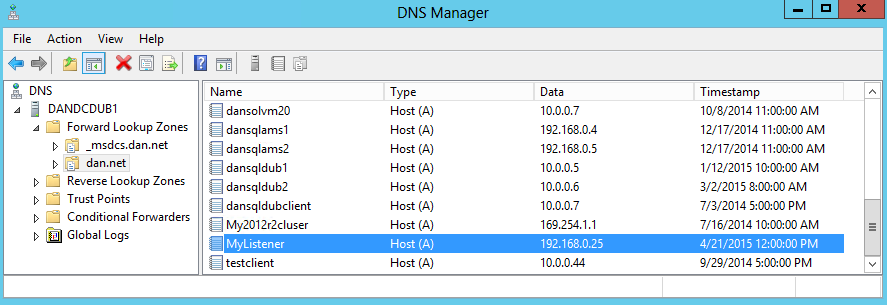
Quando si distribuisce AlwaysOn in Azure, sono disponibili diversi passaggi per creare il listener e gli indirizzi IP. È necessario configurare manualmente su 1 l'impostazione "RegisterAllIpProviders", diversamente dalla distribuzione di AlwaysOn locale, dove è già impostata su 1.
Se "RegisterAllIpProviders" è 0, viene visualizzato solo un record DNS nel DNS associato al listener:
Se "RegisterAllIpProviders" è 1:
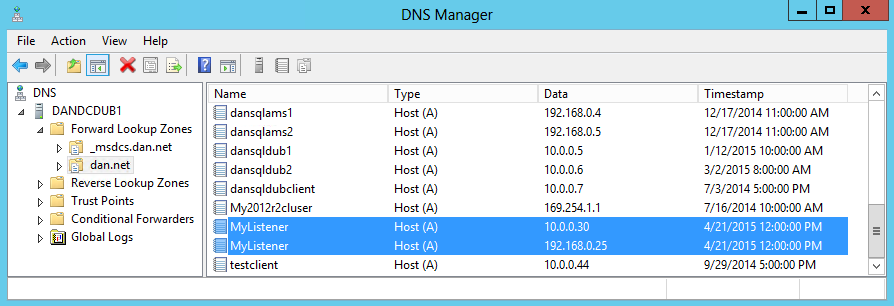
Il codice seguente rimuove le impostazioni del nome di rete virtuale e lo configura automaticamente. Per rendere effettiva la modifica, è necessario disconnettere il nome di rete virtuale e riportarlo online. Il listener viene disconnesso, determinando un'interruzione della connettività client.
##Always On Listener Name
$ListenerName = "Mylistener"
##Get AlwaysOn Network Name Settings
Get-ClusterResource $ListenerName| Get-ClusterParameter
##Set RegisterAllProvidersIP
Get-ClusterResource $ListenerName| Set-ClusterParameter RegisterAllProvidersIP 1
In un passaggio di migrazione successivo si dovrà aggiornare il listener AlwaysOn con un indirizzo IP più recente che fa riferimento a un bilanciamento del carico. Ciò comporta la rimozione e l'aggiunta di una risorsa indirizzo IP. Dopo l’aggiornamento IP, è necessario assicurarsi che il nuovo indirizzo IP sia stato aggiornato nella zona DNS e che i client aggiornino la relativa cache DNS locale.
Se i client si trovano in segmenti di rete diversi e fanno riferimento a un server DNS diverso, è necessario considerare ciò che accade sul trasferimento di zona DNS durante la migrazione, dal momento che il tempo di riconnessione dell'applicazione è limitato almeno del tempo di trasferimento di zona di ogni nuovo indirizzo IP per il listener. In caso di vincolo di tempo, è necessario discutere e verificare imponendo un trasferimento di zona incrementale con i team di Windows e, inoltre, impostare il record host DNS su una durata (TTL) inferiore, così i client si aggiornano. Per ulteriori informazioni, vedere Trasferimenti di zona incrementali e Start-DnsServerZoneTransfer.
Per impostazione predefinita, il valore TTL per il Record DNS associato al Listener in AlwaysOn in Azure è 1200 secondi. È possibile ridurre questo valore in caso di vincolo di tempo durante la migrazione per assicurarsi che i client aggiornino il proprio DNS con l'indirizzo IP aggiornato per il listener. È possibile visualizzare e modificare la configurazione eseguendo il dump della configurazione del nome di rete virtuale:
$AGName = "myProductionAG"
$ListenerName = "Mylistener"
#Look at HostRecordTTL
Get-ClusterResource $ListenerName| Get-ClusterParameter
#Set HostRecordTTL Examples
Get-ClusterResource $ListenerName| Set-ClusterParameter -Name "HostRecordTTL" 120
Nota
Più basso è "HostRecordTTL", più alto sarà il traffico DNS.
Impostazioni applicazione client
Se l'applicazione client SQL supporta .NET 4.5 SQLClient, è possibile usare la parola chiave "MULTISUBNETFAILOVER=TRUE". È consigliabile applicare questa parola chiave, poiché consente una connessione più veloce al gruppo di disponibilità SQL AlwaysOn durante il failover. Enumera tutti gli indirizzi IP associati al listener AlwaysOn in parallelo e consente una velocità di tentativi di connessione TCP maggiore durante un failover.
Per altre informazioni riguardanti le impostazioni precedenti, vedere Parola chiave MultiSubnetFailover e funzionalità associate. Vedere anche Supporto SqlClient per disponibilità elevata, ripristino di emergenza.
Passaggio 5: impostare il quorum del cluster
Poiché sarà portato offline almeno un SQL Server alla volta, è necessario modificare l'impostazione del quorum del cluster, se si usa FSW (File Share Witness) con due nodi. Il quorum deve essere impostato in modo da consentire la maggioranza del nodo e usare la votazione dinamica al fine di permettere a un singolo nodo di rimanere permanente.
Set-ClusterQuorum -NodeMajority
Per altre informazioni sulla gestione e sulla configurazione del quorum del cluster, vedere Configurare e gestire il quorum in un cluster di failover di Windows Server 2012.
Passaggio 6: estrarre endpoint e ACL esistenti
#GET Endpoint info
Get-AzureVM -ServiceName $destcloudsvc -Name $vmNameToMigrate | Get-AzureEndpoint
#GET ACL Rules for Each EP, this example is for the Always On Endpoint
Get-AzureVM -ServiceName $destcloudsvc -Name $vmNameToMigrate | Get-AzureAclConfig -EndpointName "myAOEndPoint-LB"
Salvare il testo in un file.
Passaggio 7: modificare i partner di failover e le modalità di replica
In presenza di più di 2 SQL Server, è necessario impostare su "Sincrono" il failover di un'altra replica secondaria in un altro data center o in locale e renderlo Partner di failover automatico (AFP), in modo da mantenere la disponibilità elevata mentre si apportano modifiche. A tale scopo, è possibile utilizzare TSQL o SSMS:
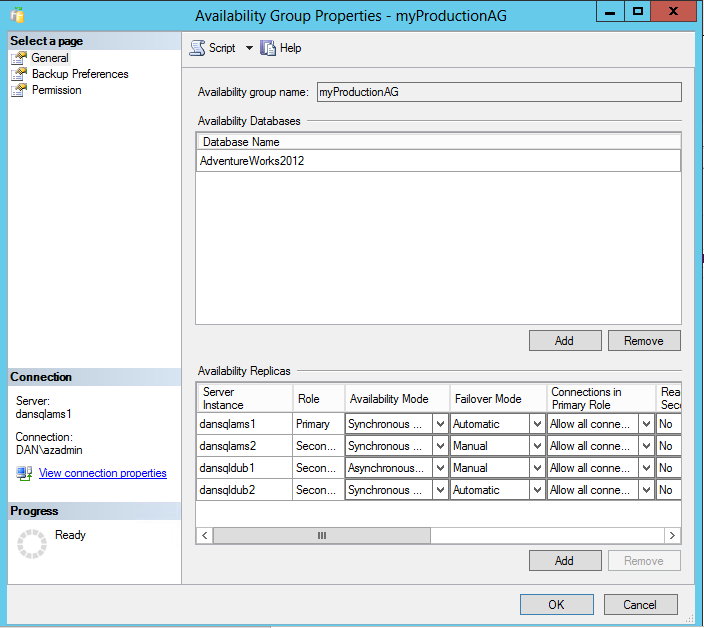
Passaggio 8: rimuovere la macchina virtuale secondaria dal servizio cloud
È consigliabile pianificare prima la migrazione di un nodo secondario del cloud. Se il nodo è attualmente primario, è consigliabile avviare un failover manuale.
$vmNameToMigrate="dansqlams2"
#Check machine status
Get-AzureVM -ServiceName $sourceSvc -Name $vmNameToMigrate
#Shutdown secondary VM
Get-AzureVM -ServiceName $sourceSvc -Name $vmNameToMigrate | stop-AzureVM
#Extract disk configuration
##Building Existing Data Disk Configuration
$file = "C:\Azure Storage Testing\mydiskconfig_$vmNameToMigrate.csv"
$datadisks = @(Get-AzureVM -ServiceName $sourceSvc -Name $vmNameToMigrate | Get-AzureDataDisk )
Add-Content $file "lun, vhdname, hostcaching, disklabel, diskName"
foreach ($disk in $datadisks)
{
$vhdname = $disk.MediaLink.AbsolutePath -creplace "/vhds/"
$disk.Lun, , $disk.HostCaching, $vhdname, $disk.DiskLabel,$disks.DiskName
# Write-Host "copying disk $disk"
$adddisk = "{0},{1},{2},{3},{4}" -f $disk.Lun,$vhdname, $disk.HostCaching, $disk.DiskLabel, $disk.DiskName
$adddisk | add-content -path $file
}
#Get OS Disk
$osdisks = Get-AzureVM -ServiceName $sourceSvc -Name $vmNameToMigrate | Get-AzureOSDisk ## | select -ExpandProperty MediaLink
$osvhdname = $osdisks.MediaLink.AbsolutePath -creplace "/vhds/"
$osdisks.OS, $osdisks.HostCaching, $osvhdname, $osdisks.DiskLabel, $osdisks.DiskName
$addosdisk = "{0},{1},{2},{3},{4}" -f $osdisks.OS,$osvhdname, $osdisks.HostCaching, $osdisks.Disklabel , $osdisks.DiskName
$addosdisk | add-content -path $file
#Import disk config
$diskobjects = Import-CSV $file
#Check disk config, make sure below returns the disks associated with the VM
$diskobjects
#Identify OS Disk
$osdiskimport = $diskobjects | where {$_.lun -eq "Windows"}
$osdiskforbuild = $osdiskimport.diskName
#Check machibe is off
Get-AzureVM -ServiceName $sourceSvc -Name $vmNameToMigrate
#Drop machine and rebuild to new cls
Remove-AzureVM -ServiceName $sourceSvc -Name $vmNameToMigrate
Passaggio 9: modificare le impostazioni di memorizzazione nella cache del disco nel file CSV e salvare
Per i volumi di dati, devono essere impostate su READONLY.
Per i volumi di TLOG, devono essere impostate su NONE.
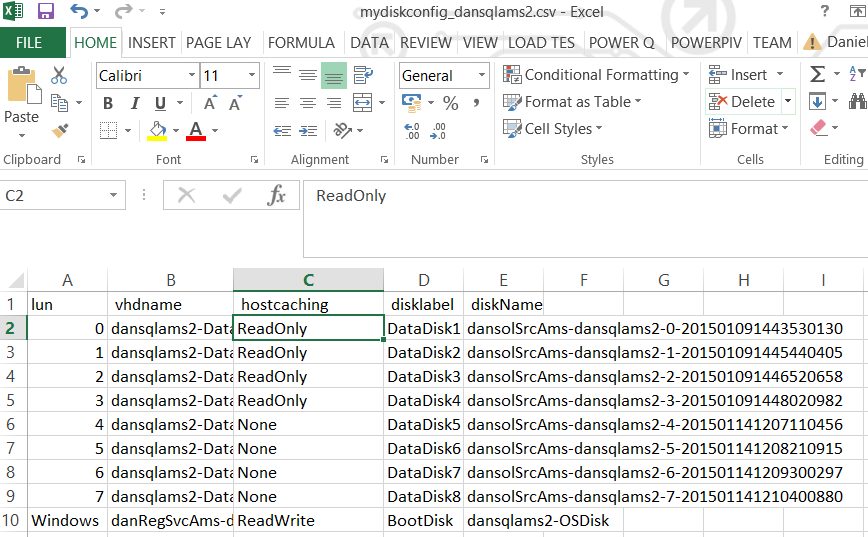
Passaggio 10: copiare i dischi rigidi virtuali
#Ensure you have created the container for these:
$containerName = 'vhds'
#Create container
New-AzureStorageContainer -Name $containerName -Context $xioContext
####DISK COPYING####
#Get disks from csv, get settings for each VHDs and copy to Premium Storage accoun
ForEach ($disk in $diskobjects)
{
$lun = $disk.Lun
$vhdname = $disk.vhdname
$cacheoption = $disk.HostCaching
$disklabel = $disk.DiskLabel
$diskName = $disk.DiskName
Write-Host "Copying Disk Lun $lun, Label : $disklabel, VHD : $vhdname has cache setting : $cacheoption"
#Start async copy
Start-AzureStorageBlobCopy -srcUri "https://$origstorageaccountname.blob.core.windows.net/vhds/$vhdname" `
-SrcContext $origContext `
-DestContainer $containerName `
-DestBlob $vhdname `
-DestContext $xioContext
}
È possibile controllare lo stato della copia dei dischi rigidi virtuali per l'account di Archiviazione Premium:
ForEach ($disk in $diskobjects)
{
$lun = $disk.Lun
$vhdname = $disk.vhdname
$cacheoption = $disk.HostCaching
$disklabel = $disk.DiskLabel
$diskName = $disk.DiskName
$copystate = Get-AzureStorageBlobCopyState -Blob $vhdname -Container $containerName -Context $xioContext
Write-Host "Copying Disk Lun $lun, Label : $disklabel, VHD : $vhdname, STATUS = " $copystate.Status
}

Attendere che tutto venga registrato come esito positivo.
Per informazioni per i singoli BLOB:
Get-AzureStorageBlobCopyState -Blob "blobname.vhd" -Container $containerName -Context $xioContext
Passaggio 11: registrare un disco del sistema operativo
#Change storage account
Set-AzureSubscription -SubscriptionName $mysubscription -CurrentStorageAccount $newxiostorageaccountname
Select-AzureSubscription -SubscriptionName $mysubscription -Current
#Register OS disk
$osdiskimport = $diskobjects | where {$_.lun -eq "Windows"}
$osvhd = $osdiskimport.vhdname
$osdiskforbuild = $osdiskimport.diskName
#Registering OS disk, but as XIO disk
$xioDiskName = $osdiskforbuild + "xio"
Add-AzureDisk -DiskName $xioDiskName -MediaLocation "https://$newxiostorageaccountname.blob.core.windows.net/vhds/$osvhd" -Label "BootDisk" -OS "Windows"
Passaggio 12: importare la replica secondaria nel nuovo servizio cloud
Il codice riportato di seguito utilizza anche l'opzione aggiunta qui, è possibile importare la macchina e utilizzare l'indirizzo VIP da conservare.
#Build VM Config
$ipaddr = "192.168.0.5"
#Remember to change to XIO
$newInstanceSize = "Standard_DS13"
$subnet = "SQL"
#Create new Availability Set
$availabilitySet = "cloudmigAVAMS"
#build machine config into object
$vmConfig = New-AzureVMConfig -Name $vmNameToMigrate -InstanceSize $newInstanceSize -DiskName $xioDiskName -AvailabilitySetName $availabilitySet ` | Add-AzureProvisioningConfig -Windows ` | Set-AzureSubnet -SubnetNames $subnet | Set-AzureStaticVNetIP -IPAddress $ipaddr
#Reload disk config
$diskobjects = Import-CSV $file
$datadiskimport = $diskobjects | where {$_.lun -ne "Windows"}
ForEach ( $attachdatadisk in $datadiskimport)
{
$label = $attachdatadisk.disklabel
$lunNo = $attachdatadisk.lun
$hostcach = $attachdatadisk.hostcaching
$datadiskforbuild = $attachdatadisk.diskName
$vhdname = $attachdatadisk.vhdname
###Attaching disks to a VM during a deploy to a new cloud service and new storage account is different from just attaching VHDs to just a redeploy in a new cloud service
$vmConfig | Add-AzureDataDisk -ImportFrom -MediaLocation "https://$newxiostorageaccountname.blob.core.windows.net/vhds/$vhdname" -LUN $lunNo -HostCaching $hostcach -DiskLabel $label
}
#Create VM
$vmConfig | New-AzureVM –ServiceName $destcloudsvc –Location $location -VNetName $vnet ## Optional (-ReservedIPName $reservedVIPName)
Passaggio 13: creare il servizio ILB sul nuovo Svc cloud, aggiungere endpoint a carico bilanciato e ACL
#Check for existing ILB
GET-AzureInternalLoadBalancer -ServiceName $destcloudsvc
$ilb="sqlIntIlbDest"
$subnet = "SQL"
$IP="192.168.0.25"
Add-AzureInternalLoadBalancer -ServiceName $destcloudsvc -InternalLoadBalancerName $ilb –SubnetName $subnet –StaticVNetIPAddress $IP
#Endpoints
$epname="sqlIntEP"
$prot="tcp"
$locport=1433
$pubport=1433
Get-AzureVM –ServiceName $destcloudsvc –Name $vmNameToMigrate | Add-AzureEndpoint -Name $epname -Protocol $prot -LocalPort $locport -PublicPort $pubport -ProbePort 59999 -ProbeIntervalInSeconds 5 -ProbeTimeoutInSeconds 11 -ProbeProtocol "TCP" -InternalLoadBalancerName $ilb -LBSetName $ilb -DirectServerReturn $true | Update-AzureVM
#SET Azure ACLs or Network Security Groups & Windows FWs
#https://msdn.microsoft.com/library/azure/dn495192.aspx
####WAIT FOR FULL AlwaysOn RESYNCRONISATION!!!!!!!!!#####
Passaggio 14: aggiornare AlwaysOn
#Code to be executed on a Cluster Node
$ClusterNetworkNameAmsterdam = "Cluster Network 2" # the azure cluster subnet network name
$newCloudServiceIPAmsterdam = "192.168.0.25" # IP address of your cloud service
$AGName = "myProductionAG"
$ListenerName = "Mylistener"
Add-ClusterResource "IP Address $newCloudServiceIPAmsterdam" -ResourceType "IP Address" -Group $AGName -ErrorAction Stop | Set-ClusterParameter -Multiple @{"Address"="$newCloudServiceIPAmsterdam";"ProbePort"="59999";SubnetMask="255.255.255.255";"Network"=$ClusterNetworkNameAmsterdam;"OverrideAddressMatch"=1;"EnableDhcp"=0} -ErrorAction Stop
#set dependency and NETBIOS, then remove old IP address
#set NETBIOS, then remove old IP address
Get-ClusterGroup $AGName | Get-ClusterResource -Name "IP Address $newCloudServiceIPAmsterdam" | Set-ClusterParameter -Name EnableNetBIOS -Value 0
#set dependency to Listener (OR Dependency) and delete previous IP Address resource that references:
#Make sure no static records in DNS
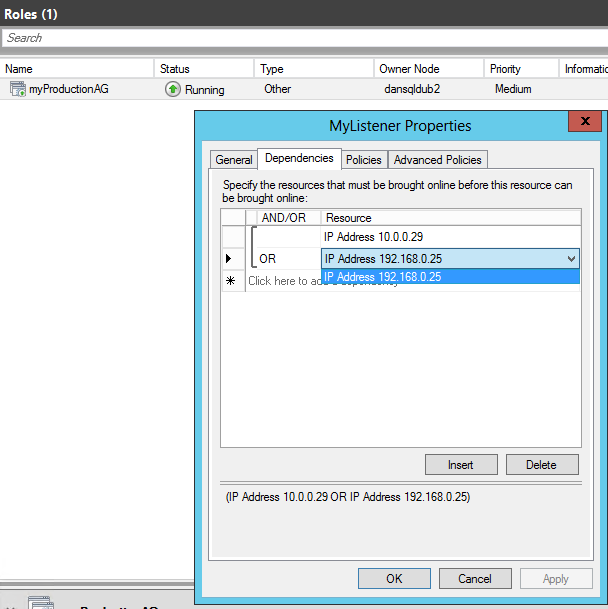
Ora, rimuovere l’indirizzo IP del servizio cloud precedente.
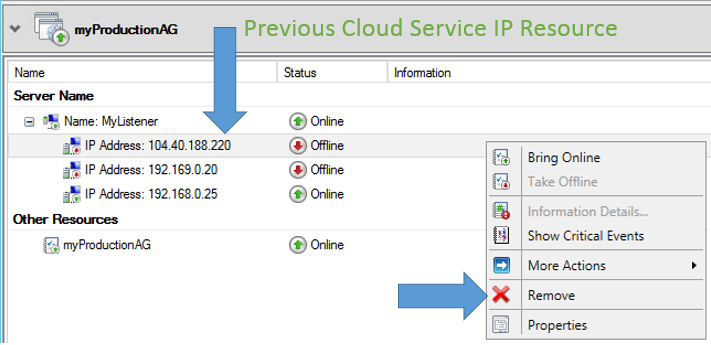
Passaggio 15: eseguire il controllo dell'aggiornamento DNS
È ora necessario controllare i server DNS nelle reti client SQL Server e assicurarsi che il servizio cluster abbia aggiunto il record host aggiuntivo per l'indirizzo IP aggiunto. Se tali server DNS non sono stati aggiornati, forzare un trasferimento di zona DNS e assicurarsi che i client presenti nella subnet riescano a risolversi in entrambi gli indirizzi IP di AlwaysOn, in modo che non sia necessario attendere la replica DNS automatica.
Passaggio 16: riconfigurare Always On
A questo punto è necessario attendere che il database secondario su cui è stato migrato il nodo venga risincronizzato completamente e passare al nodo di replica sincrona e renderlo AFP.
Passaggio 17: eseguire la migrazione del secondo nodo
$vmNameToMigrate="dansqlams1"
Get-AzureVM -ServiceName $sourceSvc -Name $vmNameToMigrate
#Get endpoint information
$endpoint = Get-AzureVM -ServiceName $sourceSvc -Name $vmNameToMigrate | Get-AzureEndpoint
#Shutdown VM
Get-AzureVM -ServiceName $sourceSvc -Name $vmNameToMigrate | stop-AzureVM
#Get disk config
#Building Existing Data Disk Configuration
$file = "C:\Azure Storage Testing\mydiskconfig_$vmNameToMigrate.csv"
$datadisks = @(Get-AzureVM -ServiceName $sourceSvc -Name $vmNameToMigrate | Get-AzureDataDisk )
Add-Content $file "lun, vhdname, hostcaching, disklabel, diskName"
foreach ($disk in $datadisks)
{
$vhdname = $disk.MediaLink.AbsolutePath -creplace "/vhds/"
$disk.Lun, , $disk.HostCaching, $vhdname, $disk.DiskLabel,$disks.DiskName
# Write-Host "copying disk $disk"
$adddisk = "{0},{1},{2},{3},{4}" -f $disk.Lun,$vhdname, $disk.HostCaching, $disk.DiskLabel, $disk.DiskName
$adddisk | add-content -path $file
}
#Get OS Disk
$osdisks = Get-AzureVM -ServiceName $sourceSvc -Name $vmNameToMigrate | Get-AzureOSDisk ## | select -ExpandProperty MediaLink
$osvhdname = $osdisks.MediaLink.AbsolutePath -creplace "/vhds/"
$osdisks.OS, $osdisks.HostCaching, $osvhdname, $osdisks.DiskLabel, $osdisks.DiskName
$addosdisk = "{0},{1},{2},{3},{4}" -f $osdisks.OS,$osvhdname, $osdisks.HostCaching, $osdisks.Disklabel , $osdisks.DiskName
$addosdisk | add-content -path $file
#Import disk config
$diskobjects = Import-CSV $file
#Check disk configuration
$diskobjects
#Identify OS Disk
$osdiskimport = $diskobjects | where {$_.lun -eq "Windows"}
$osdiskforbuild = $osdiskimport.diskName
#Check machine is off
Get-AzureVM -ServiceName $sourceSvc -Name $vmNameToMigrate
#Drop machine and rebuild to new cls
Remove-AzureVM -ServiceName $sourceSvc -Name $vmNameToMigrate
Passaggio 18: modificare le impostazioni di memorizzazione nella cache del disco nel file CSV e salvare
Per i volumi di dati, le impostazioni della cache devono essere impostate su READONLY.
Per i volumi di TLOG, le impostazioni della cache devono essere impostate su NONE.
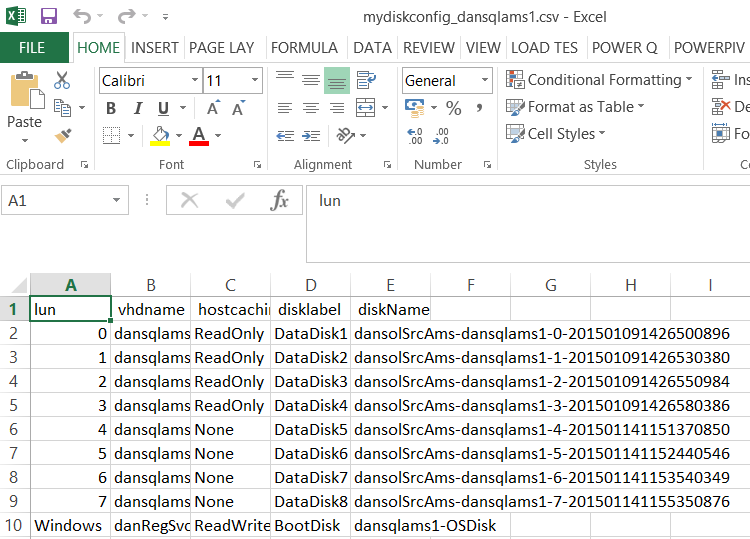
Passaggio 19: creare un nuovo account di archiviazione indipendente per il nodo secondario
$newxiostorageaccountnamenode2 = "danspremsams2"
New-AzureStorageAccount -StorageAccountName $newxiostorageaccountnamenode2 -Location $location -Type "Premium_LRS"
#Reset the storage account src if node 1 in a different storage account
$origstorageaccountname2nd = "danstdams2"
#Generate storage keys for later
$xiostoragenode2 = Get-AzureStorageKey -StorageAccountName $newxiostorageaccountnamenode2
#Generate storage acc contexts
$xioContextnode2 = New-AzureStorageContext –StorageAccountName $newxiostorageaccountnamenode2 -StorageAccountKey $xiostoragenode2.Primary
#Set up subscription and default storage account
Set-AzureSubscription -SubscriptionName $mysubscription -CurrentStorageAccount $newxiostorageaccountnamenode2
Select-AzureSubscription -SubscriptionName $mysubscription -Current
Passaggio 20: copiare i dischi rigidi virtuali
#Ensure you have created the container for these:
$containerName = 'vhds'
#Create container
New-AzureStorageContainer -Name $containerName -Context $xioContextnode2
####DISK COPYING####
##get disks from csv, get settings for each VHDs and copy to Premium Storage accoun
ForEach ($disk in $diskobjects)
{
$lun = $disk.Lun
$vhdname = $disk.vhdname
$cacheoption = $disk.HostCaching
$disklabel = $disk.DiskLabel
$diskName = $disk.DiskName
Write-Host "Copying Disk Lun $lun, Label : $disklabel, VHD : $vhdname has cache setting : $cacheoption"
#Start async copy
Start-AzureStorageBlobCopy -srcUri "https://$origstorageaccountname2nd.blob.core.windows.net/vhds/$vhdname" `
-SrcContext $origContext `
-DestContainer $containerName `
-DestBlob $vhdname `
-DestContext $xioContextnode2
}
#Check for copy progress
#check individual blob status
Get-AzureStorageBlobCopyState -Blob "danRegSvcAms-dansqlams1-2014-07-03.vhd" -Container $containerName -Context $xioContext
È possibile controllare lo stato della copia per tutti i dischi rigidi virtuali:
ForEach ($disk in $diskobjects)
{
$lun = $disk.Lun
$vhdname = $disk.vhdname
$cacheoption = $disk.HostCaching
$disklabel = $disk.DiskLabel
$diskName = $disk.DiskName
$copystate = Get-AzureStorageBlobCopyState -Blob $vhdname -Container $containerName -Context $xioContextnode2
Write-Host "Copying Disk Lun $lun, Label : $disklabel, VHD : $vhdname, STATUS = " $copystate.Status
}

Attendere che tutto venga registrato come esito positivo.
Per informazioni per i singoli BLOB:
#Check individual blob status
Get-AzureStorageBlobCopyState -Blob "danRegSvcAms-dansqlams1-2014-07-03.vhd" -Container $containerName -Context $xioContextnode2
Passaggio 21: registrare un disco del sistema operativo
#change storage account to the new XIO storage account
Set-AzureSubscription -SubscriptionName $mysubscription -CurrentStorageAccount $newxiostorageaccountnamenode2
Select-AzureSubscription -SubscriptionName $mysubscription -Current
#Register OS disk
$osdiskimport = $diskobjects | where {$_.lun -eq "Windows"}
$osvhd = $osdiskimport.vhdname
$osdiskforbuild = $osdiskimport.diskName
#Registering OS disk, but as XIO disk
$xioDiskName = $osdiskforbuild + "xio"
Add-AzureDisk -DiskName $xioDiskName -MediaLocation "https://$newxiostorageaccountnamenode2.blob.core.windows.net/vhds/$osvhd" -Label "BootDisk" -OS "Windows"
#Build VM Config
$ipaddr = "192.168.0.4"
$newInstanceSize = "Standard_DS13"
#Join to existing Availability Set
#Build machine config into object
$vmConfig = New-AzureVMConfig -Name $vmNameToMigrate -InstanceSize $newInstanceSize -DiskName $xioDiskName -AvailabilitySetName $availabilitySet ` | Add-AzureProvisioningConfig -Windows ` | Set-AzureSubnet -SubnetNames $subnet | Set-AzureStaticVNetIP -IPAddress $ipaddr
#Reload disk config
$diskobjects = Import-CSV $file
$datadiskimport = $diskobjects | where {$_.lun -ne "Windows"}
ForEach ( $attachdatadisk in $datadiskimport)
{
$label = $attachdatadisk.disklabel
$lunNo = $attachdatadisk.lun
$hostcach = $attachdatadisk.hostcaching
$datadiskforbuild = $attachdatadisk.diskName
$vhdname = $attachdatadisk.vhdname
###This is different to just a straight cloud service change
#note if you do not have a disk label the command below will fail, populate as required.
$vmConfig | Add-AzureDataDisk -ImportFrom -MediaLocation "https://$newxiostorageaccountnamenode2.blob.core.windows.net/vhds/$vhdname" -LUN $lunNo -HostCaching $hostcach -DiskLabel $label
}
#Create VM
$vmConfig | New-AzureVM –ServiceName $destcloudsvc –Location $location -VNetName $vnet -Verbose
Passaggio 22: aggiungere endpoint con carico bilanciato e ACL
#Endpoints
$epname="sqlIntEP"
$prot="tcp"
$locport=1433
$pubport=1433
Get-AzureVM –ServiceName $destcloudsvc –Name $vmNameToMigrate | Add-AzureEndpoint -Name $epname -Protocol $prot -LocalPort $locport -PublicPort $pubport -ProbePort 59999 -ProbeIntervalInSeconds 5 -ProbeTimeoutInSeconds 11 -ProbeProtocol "TCP" -InternalLoadBalancerName $ilb -LBSetName $ilb -DirectServerReturn $true | Update-AzureVM
#STOP!!! CHECK in the Azure portal or Machine Endpoints through PowerShell that these Endpoints are created!
#SET ACLs or Azure Network Security Groups & Windows FWs
#https://msdn.microsoft.com/library/azure/dn495192.aspx
Passaggio 23: Failover di test
Attendere la sincronizzazione del nodo sottoposto a migrazione con il nodo AlwaysOn locale. Posizionarlo in modalità di replica sincrona e attendere il completamento della sincronizzazione. Quindi eseguire il failover da locale sul primo nodo migrato, ossia AFP. Successivamente, modificare l’ultimo nodo migrato in AFP.
È consigliabile testare i failover tra tutti i nodi ed eseguire i caos test per assicurarsi che i failover funzionino nel modo previsto e nei tempi indicati.
Passaggio 24: ripristinare le impostazioni quorum del cluster/TTL DNS/Failover Pntrs/Impostazioni di sincronizzazione
Aggiunta della risorsa indirizzo IP nella stessa Subnet
Se sono presenti solo due server SQL e si vuole eseguirne la migrazione a un nuovo servizio cloud ma mantenerli nella stessa subnet, è possibile evitare di portare offline il listener per eliminare l'indirizzo IP di AlwaysOn originale e aggiungere il nuovo indirizzo IP. Se si esegue la migrazione delle VM a un'altra subnet, non è necessario eseguire questa operazione, perché una rete di cluster aggiuntiva fa riferimento a tale subnet.
Dopo aver attivato la replica secondaria migrata e aggiunto la nuova risorsa indirizzo IP per il nuovo servizio cloud prima del failover della replica primaria esistente, è necessario eseguire questi passaggi in Gestione failover cluster:
Per aggiungere l'indirizzo IP, vedere l'Appendice, passaggio 14.
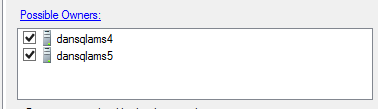
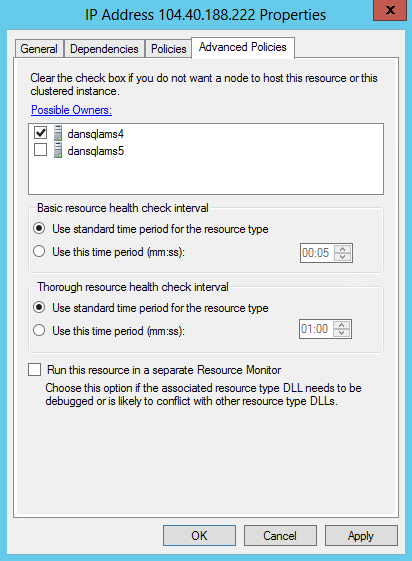
Per la risorsa indirizzo IP corrente, modificare il proprietario possibile in "SQL Server primario esistente", nell'esempio "dansqlams4":
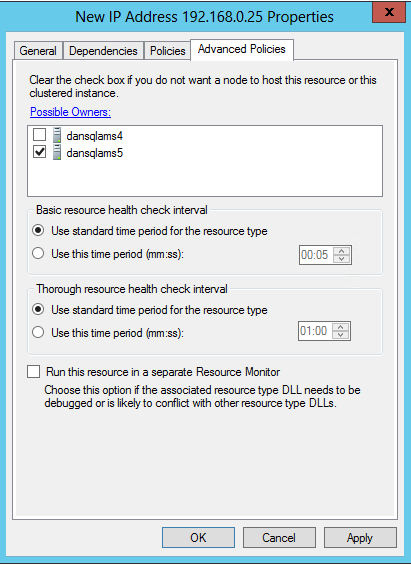
Per la nuova risorsa indirizzo IP, modificare il proprietario possibile in "SQL Server secondario migrato", nell'esempio "dansqlams5":
Dopo queste impostazioni, è possibile eseguire il failover e quando l'ultimo viene migrato, i possibili proprietari devono essere modificati in modo che tale nodo venga aggiunto come possibile proprietario: