connettori Power Query (anteprima - ritirata)
Importante
Power Query supporto del connettore è stato introdotto come anteprima pubblica controllata in Condizioni supplementari per l'uso per le anteprime di Microsoft Azure, ma è ora sospeso. Se si dispone di una soluzione di ricerca che usa un connettore Power Query, eseguire la migrazione a una soluzione alternativa.
Eseguire la migrazione entro il 28 novembre 2022
L'anteprima del connettore Power Query è stata annunciata a maggio 2021 e non verrà spostata verso la disponibilità generale. Le indicazioni sulla migrazione seguenti sono disponibili per Snowflake e PostgreSQL. Se si usa un connettore diverso e sono necessarie istruzioni di migrazione, usare le informazioni di contatto tramite posta elettronica fornite nell'iscrizione di anteprima per richiedere assistenza o aprire un ticket con il supporto di Azure.
Prerequisiti
- Un account dell'Archiviazione di Azure. Se non ne hai uno, crea un account di archiviazione.
- Un Azure Data Factory. Se non ne hai uno, crea una Data Factory. Vedere Prezzi delle pipeline di Data Factory prima dell'implementazione per comprendere i costi associati. Controllare anche i prezzi di Data Factory tramite esempi.
Eseguire la migrazione di una pipeline di dati Snowflake
Questa sezione illustra come copiare i dati da un database Snowflake a un indice Ricerca cognitiva di Azure. Non esiste alcun processo per l'indicizzazione diretta da Snowflake a Ricerca cognitiva di Azure, quindi questa sezione include una fase di staging che copia il contenuto del database in un contenitore BLOB di Archiviazione di Azure. Verrà quindi indicizzato da tale contenitore di staging usando una pipeline di Data Factory.
Passaggio 1: Recuperare le informazioni del database Snowflake
Passare a Snowflake e accedere all'account Snowflake. Un account Snowflake è simile a https://< account_name.snowflakecomputing.com>.
Dopo aver eseguito l'accesso, raccogliere le informazioni seguenti dal riquadro sinistro. Queste informazioni verranno usate nel passaggio successivo:
- In Dati selezionare Database e copiare il nome dell'origine del database.
- In Amministrazione selezionare Utenti & Ruoli e copiare il nome dell'utente. Assicurarsi che l'utente disponga delle autorizzazioni di lettura.
- In Amministrazione selezionare Account e copiare il valore LOCALIZZATO dell'account.
- Dall'URL Snowflake, simile a
https://app.snowflake.com/<region_name>/xy12345/organization). copiare il nome dell'area. Ad esempio, inhttps://app.snowflake.com/south-central-us.azure/xy12345/organization, il nome dell'area èsouth-central-us.azure. - In Amministrazione selezionare Warehouses (Warehouse) e copiare il nome del magazzino associato al database usato come origine.
Passaggio 2: Configurare il servizio collegato Snowflake
Accedere a Azure Data Factory Studio con l'account Azure.
Selezionare la data factory e quindi continuare.
Dal menu a sinistra selezionare l'icona Gestisci .
In Servizi collegati selezionare Nuovo.
Nel riquadro destro, nella ricerca dell'archivio dati immettere "snowflake". Selezionare il riquadro Snowflake e selezionare Continua.
Compilare il modulo Nuovo servizio collegato con i dati raccolti nel passaggio precedente. Il nome dell'account include un valore LOCALIZZATO e l'area ( ad esempio:
xy56789south-central-us.azure).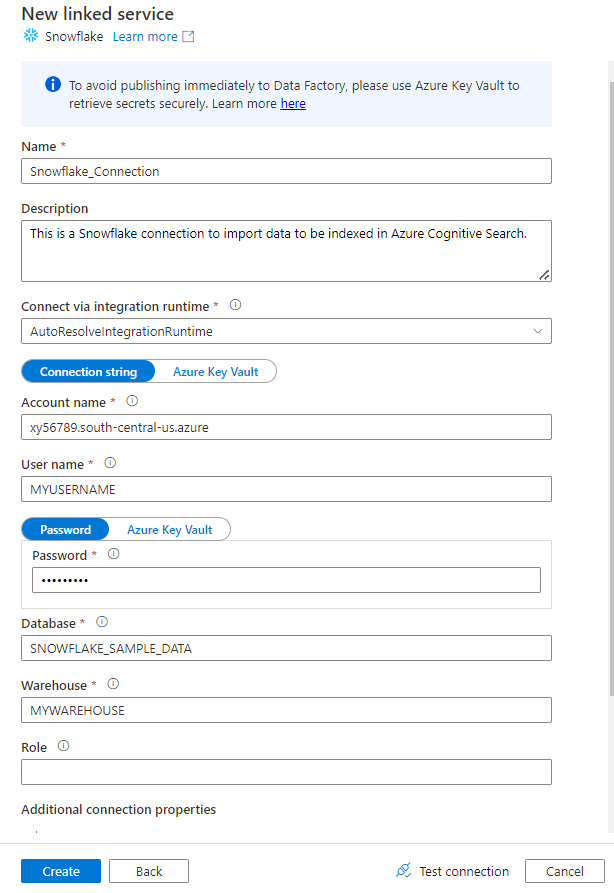
Al termine del modulo, selezionare Test connessione.
Se il test ha esito positivo, selezionare Crea.
Passaggio 3: Configurare il set di dati Snowflake
Dal menu a sinistra selezionare l'icona Autore .
Selezionare Set di dati e quindi selezionare il menu Puntini di sospensione Azioni set di dati (
...).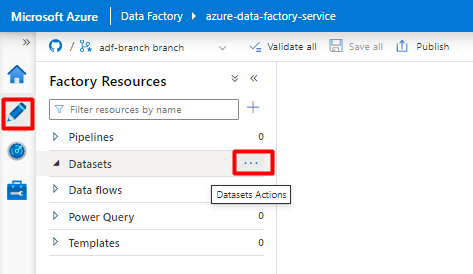
Selezionare Nuovo set di dati.
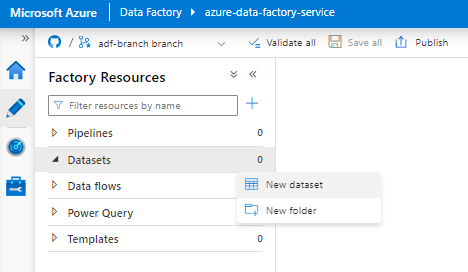
Nel riquadro destro, nella ricerca dell'archivio dati immettere "snowflake". Selezionare il riquadro Snowflake e selezionare Continua.
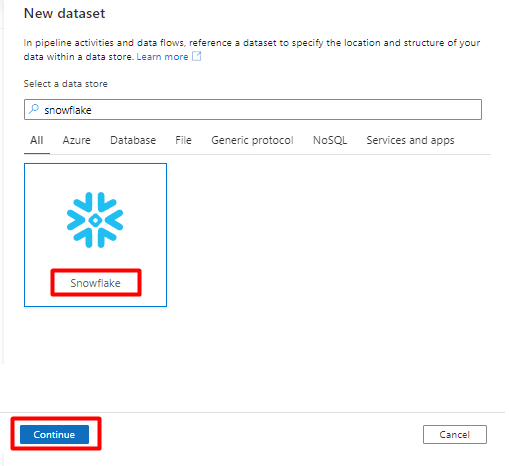
In Imposta proprietà:
- Selezionare il servizio collegato creato nel passaggio 2.
- Selezionare la tabella da importare e quindi selezionare OK.
Selezionare Salva.
Passaggio 4: Creare un nuovo indice in Ricerca cognitiva di Azure
Creare un nuovo indice nel servizio Ricerca cognitiva di Azure con lo stesso schema di quello attualmente configurato per i dati Snowflake.
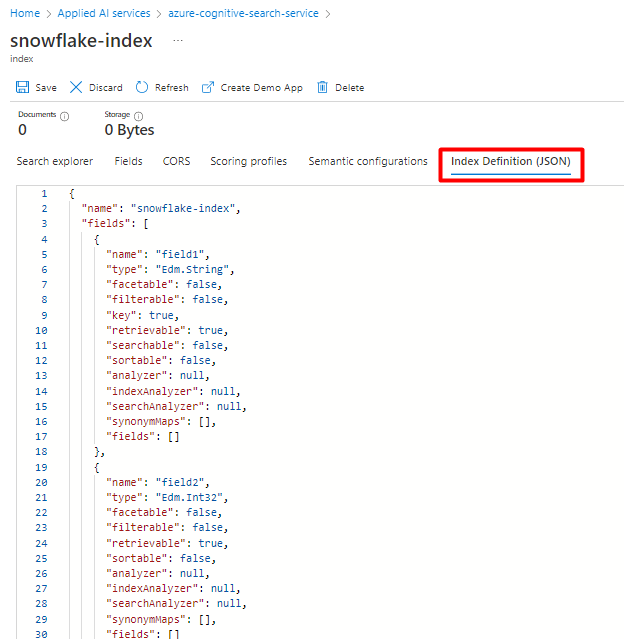
È possibile riutilizzare l'indice attualmente usato per Snowflake Power Connector. Nella portale di Azure trovare l'indice e quindi selezionare Definizione di indice (JSON). Selezionare la definizione e copiarla nel corpo della nuova richiesta di indice.
Passaggio 5: Configurare Ricerca cognitiva di Azure servizio collegato
Dal menu a sinistra selezionare Gestisci icona.
In Servizi collegati selezionare Nuovo.
Nel riquadro destro, nella ricerca dell'archivio dati immettere "search". Selezionare il riquadro Ricerca di Azure e selezionare Continua.
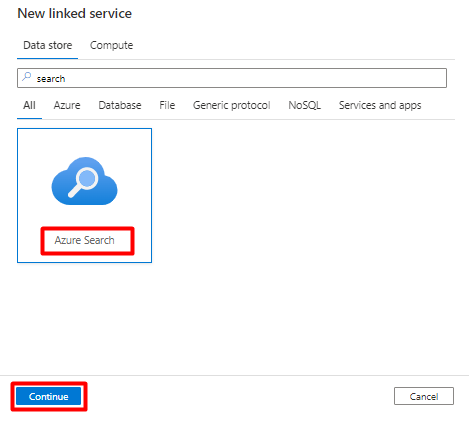
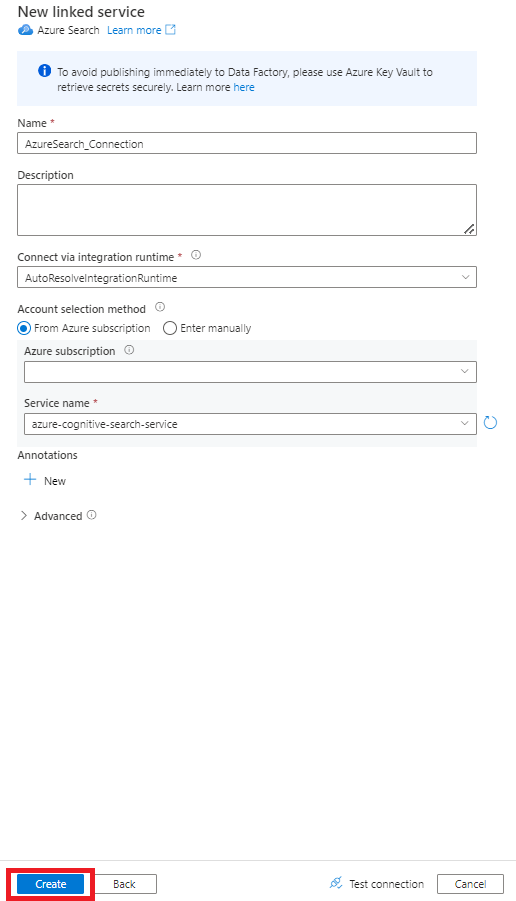
Compilare i valori del nuovo servizio collegato :
- Scegliere la sottoscrizione di Azure in cui risiede il servizio Ricerca cognitiva di Azure.
- Scegliere il servizio Ricerca cognitiva di Azure con l'indicizzatore del connettore Power Query.
- Selezionare Crea.
Passaggio 6: Configurare Ricerca cognitiva di Azure set di dati
Dal menu a sinistra selezionare Icona Autore .
Selezionare Set di dati e quindi selezionare il menu Puntini di sospensione Azioni set di dati (
...).
Selezionare Nuovo set di dati.
Nel riquadro destro, nella ricerca dell'archivio dati immettere "search". Selezionare il riquadro Ricerca di Azure e selezionare Continua.
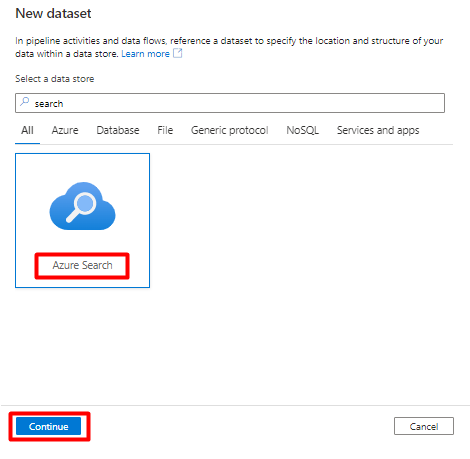
In Imposta proprietà:
Selezionare il servizio collegato creato di recente nel passaggio 5.
Scegliere l'indice di ricerca creato nel passaggio 4.
Selezionare OK.
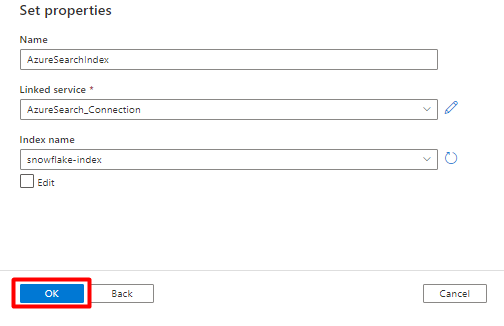
Selezionare Salva.
Passaggio 7: Configurare Archiviazione BLOB di Azure servizio collegato
Dal menu a sinistra selezionare Gestisci icona.
In Servizi collegati selezionare Nuovo.
Nel riquadro destro, nella ricerca dell'archivio dati immettere "storage". Selezionare il riquadro Archiviazione BLOB di Azure e selezionare Continua.
Compilare i valori del nuovo servizio collegato :
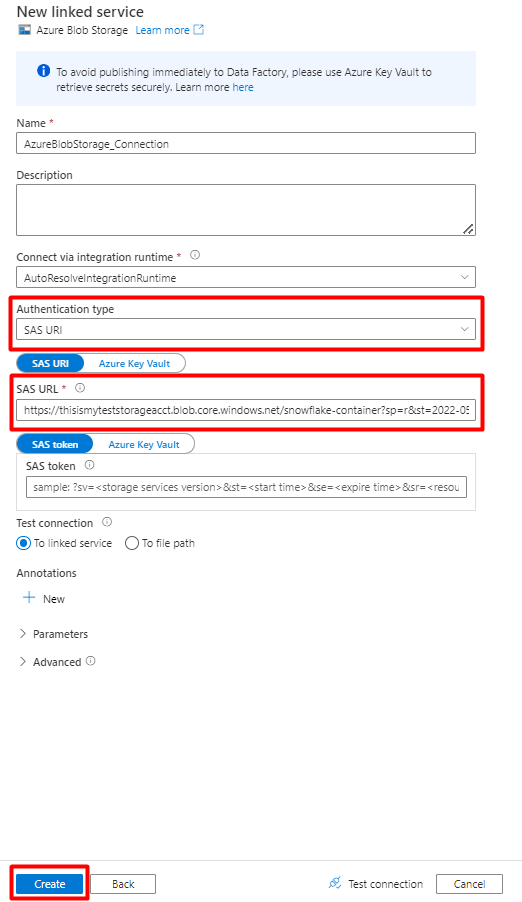
Scegliere il tipo di autenticazione: URI di firma di accesso condiviso. Solo questo tipo di autenticazione può essere usato per importare dati da Snowflake in Archiviazione BLOB di Azure.
Generare un URL di firma di accesso condiviso per l'account di archiviazione che verrà usato per la gestione temporanea. Incollare l'URL di firma di accesso condiviso DEL BLOB nel campo URL di firma di accesso condiviso.
Selezionare Crea.
Passaggio 8: Configurare il set di dati di archiviazione
Nel menu a sinistra selezionare l'icona Autore .
Selezionare Set di dati e quindi selezionare i puntini di sospensione Azioni set di dati (
...).
Selezionare Nuovo set di dati.
Nel riquadro destro, nella ricerca dell'archivio dati immettere "storage". Selezionare il riquadro Archiviazione BLOB di Azure e selezionare Continua.
Selezionare DelimitedText format (Formato delimitato) e selezionare Continue (Continua).
In Imposta proprietà:
In Servizio collegato selezionare il servizio collegato creato nel passaggio 7.
In Percorso file scegliere il contenitore che sarà il sink per il processo di gestione temporanea e selezionare OK.
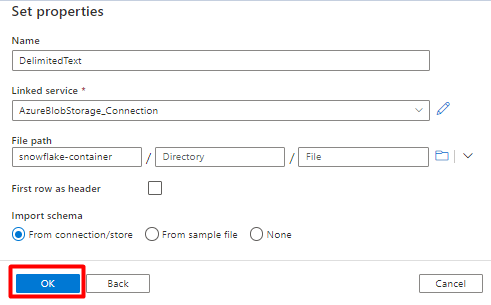
In Delimitatore di riga selezionare Avanzamento riga (\n).
Selezionare Prima riga come casella di intestazione .
Selezionare Salva.
Passaggio 9: Configurare la pipeline
Nel menu a sinistra selezionare l'icona Autore .
Selezionare Pipeline e quindi selezionare i puntini di sospensione Pipelines Actions (
...Azioni pipeline).
Selezionare New pipeline (Nuova pipeline).
Creare e configurare le attività di Data Factory copiate da Snowflake al contenitore di Archiviazione di Azure:
Espandere Sposta & sezione transform (Sposta & trasformazione ) e trascinare l'attività Copy Data (Copia dati ) nell'area di disegno dell'editor della pipeline vuota.
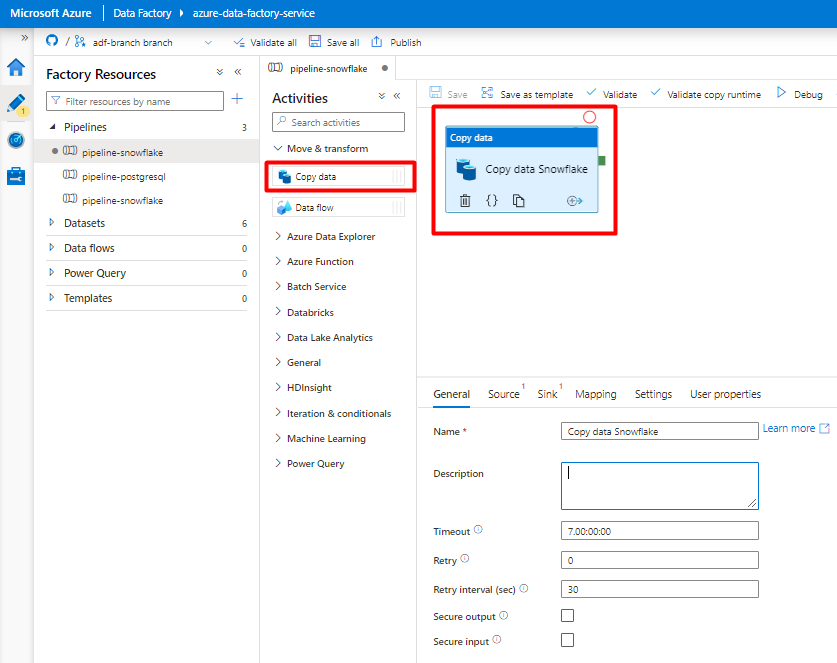
Aprire la scheda Generale . Accettare i valori predefiniti a meno che non sia necessario personalizzare l'esecuzione.
Nella scheda Origine selezionare la tabella Snowflake. Lasciare le opzioni rimanenti con i valori predefiniti.
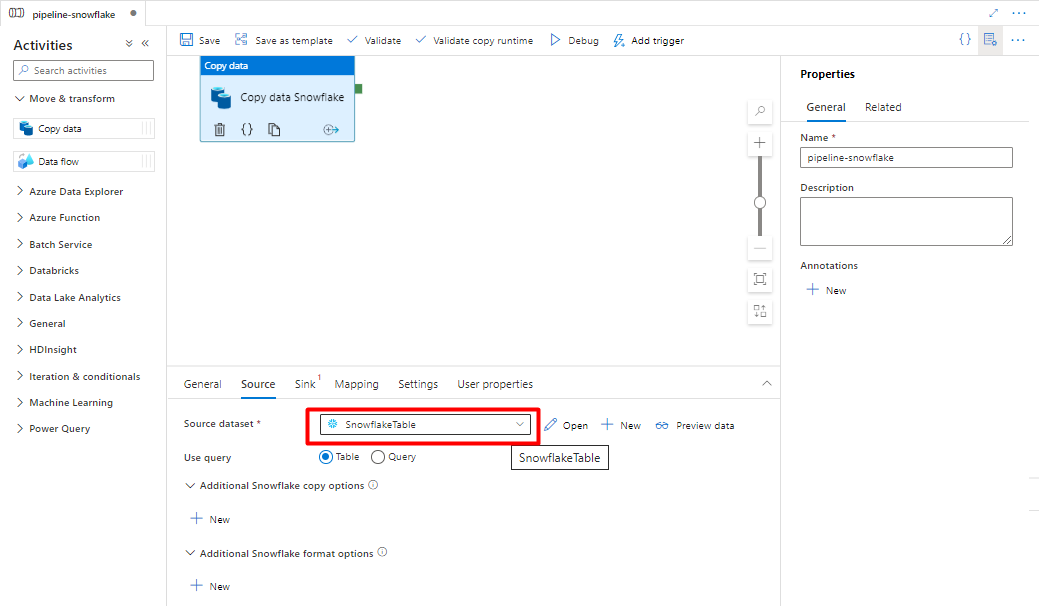
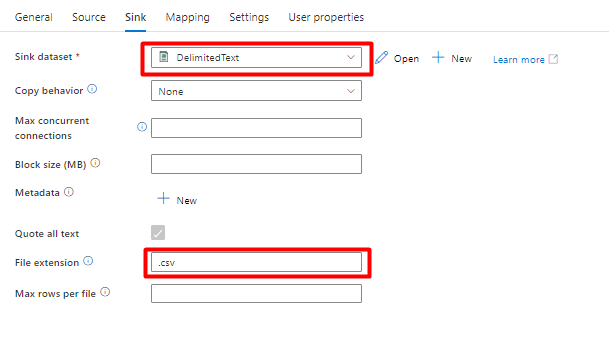
Nella scheda Sink :
Selezionare Storage DelimitedText dataset created in Step 8 (Set di dati DelimitedText di archiviazione creato nel passaggio 8).
In Estensione file aggiungere .csv.
Lasciare le opzioni rimanenti con i valori predefiniti.
Selezionare Salva.
Configurare le attività copiate dal BLOB di Archiviazione di Azure in un indice di ricerca:
Espandere Sposta & sezione transform (Sposta & trasformazione ) e trascinare l'attività Copy Data (Copia dati ) nell'area di disegno dell'editor della pipeline vuota.
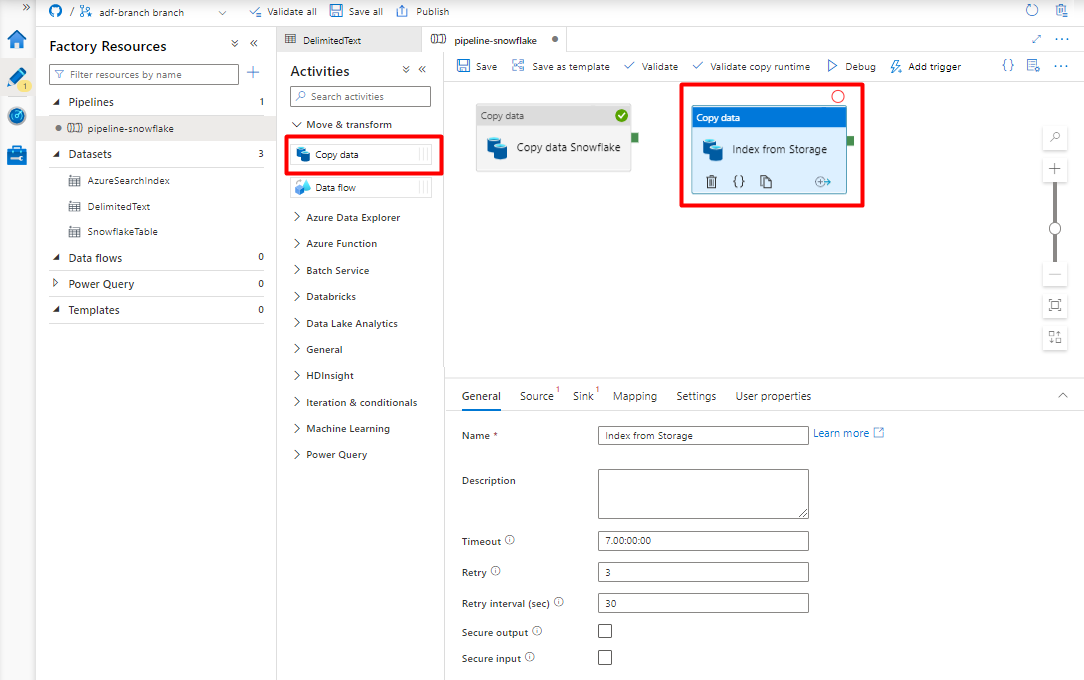
Nella scheda Generale accettare i valori predefiniti, a meno che non sia necessario personalizzare l'esecuzione.
Nella scheda Origine :
- Selezionare Storage DelimitedText dataset created in Step 8 (Set di dati DelimitedText di archiviazione creato nel passaggio 8).
- Nel tipo Percorso file selezionare Percorso file con caratteri jolly.
- Lasciare tutti i campi rimanenti con i valori predefiniti.
Nella scheda Sink selezionare l'indice Ricerca cognitiva di Azure. Lasciare le opzioni rimanenti con i valori predefiniti.
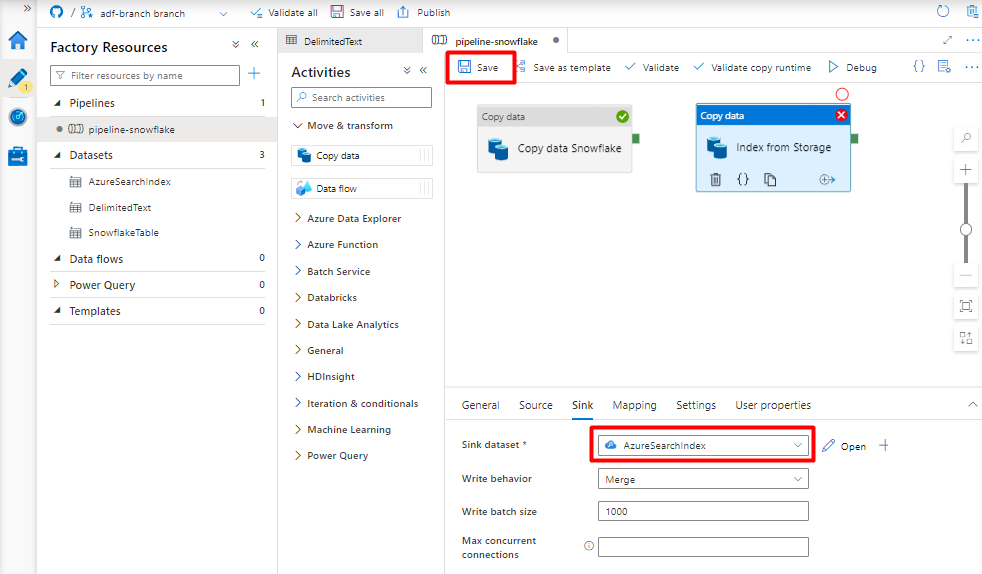
Selezionare Salva.
Passaggio 10: Configurare l'ordine delle attività
Nell'editor dell'area di disegno pipeline selezionare il piccolo quadrato verde sul bordo del riquadro attività della pipeline. Trascinarlo nell'attività "Indici dall'account di archiviazione a Ricerca cognitiva di Azure" per impostare l'ordine di esecuzione.
Selezionare Salva.
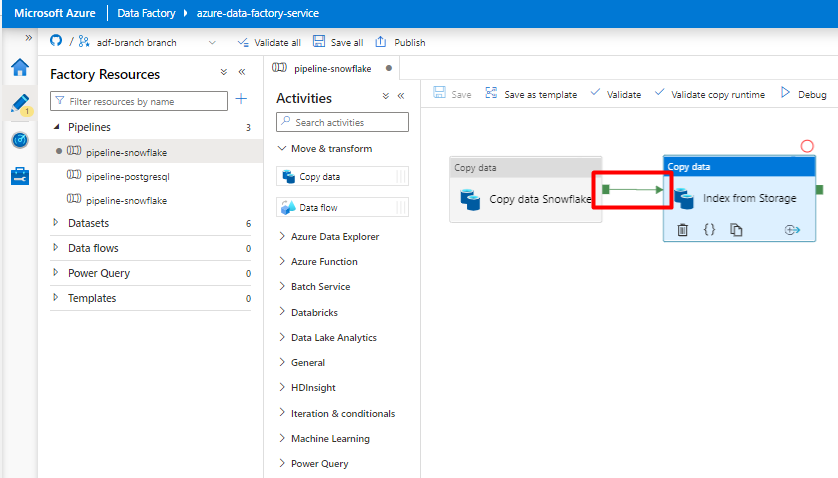
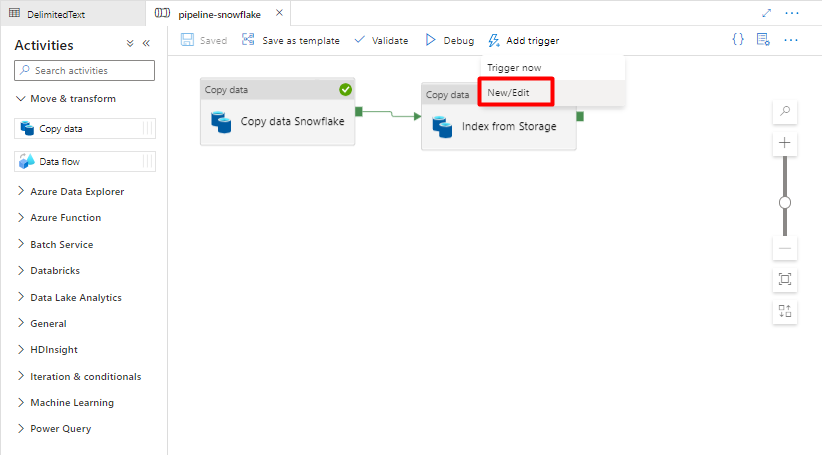
Passaggio 11: Aggiungere un trigger della pipeline
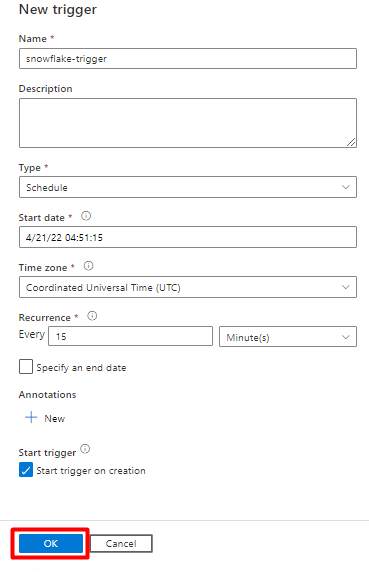
Selezionare Aggiungi trigger per pianificare l'esecuzione della pipeline e selezionare Nuovo/Modifica.
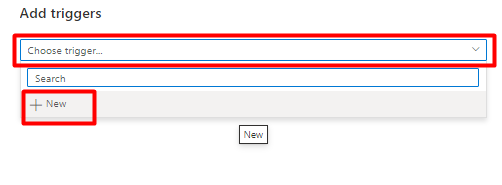
Nell'elenco a discesa Scegli trigger selezionare Nuovo.
Esaminare le opzioni del trigger per eseguire la pipeline e selezionare OK.
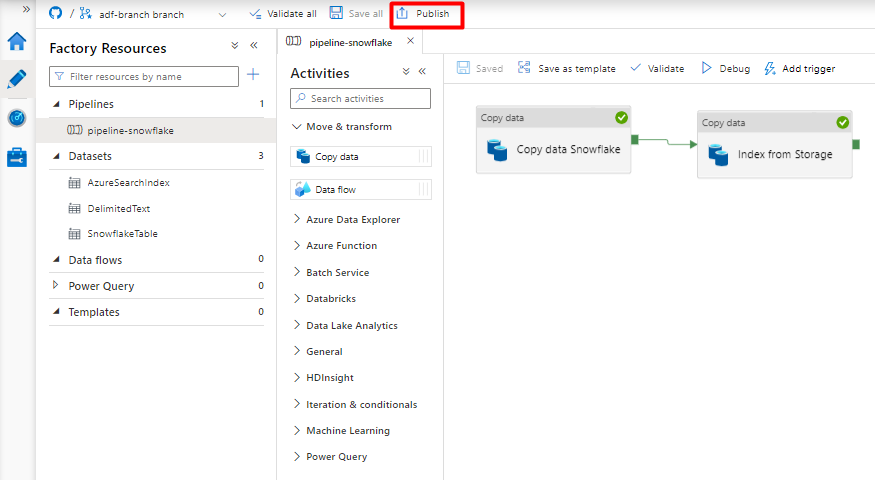
Selezionare Salva.
Selezionare Pubblica.
Eseguire la migrazione di una pipeline di dati PostgreSQL
Questa sezione illustra come copiare dati da un database PostgreSQL a un indice Ricerca cognitiva di Azure. Non esiste alcun processo per l'indicizzazione diretta da PostgreSQL a Ricerca cognitiva di Azure, quindi questa sezione include una fase di gestione temporanea che copia il contenuto del database in un contenitore BLOB di Archiviazione di Azure. Si eseguirà quindi l'indicizzazione da tale contenitore di staging usando una pipeline di Data Factory.
Passaggio 1: Configurare il servizio collegato PostgreSQL
Accedere a Azure Data Factory Studio con l'account Azure.
Scegliere Data Factory e selezionare Continua.
Nel menu a sinistra selezionare l'icona Gestisci .
In Servizi collegati selezionare Nuovo.
Nel riquadro destro, nella ricerca nell'archivio dati immettere "postgresql". Selezionare il riquadro PostgreSQL che rappresenta la posizione del database PostgreSQL (Azure o altro) e selezionare Continua. In questo esempio il database PostgreSQL si trova in Azure.

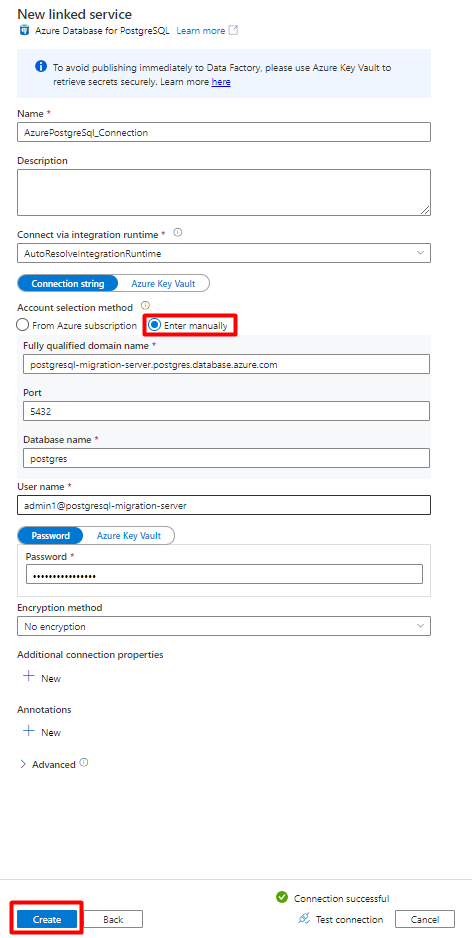
Compilare i valori del nuovo servizio collegato :
In Metodo di selezione account selezionare Invio manualmente.
Nella pagina panoramica Database di Azure per PostgreSQL nella portale di Azure incollare i valori seguenti nel rispettivo campo:
- Aggiungere il nome del server al nome di dominio completo.
- Aggiungere Amministrazione nome utente a Nome utente.
- Aggiungere database al nome del database.
- Immettere la Amministrazione password del nome utente in Password nome utente.
- Selezionare Crea.
Passaggio 2: Configurare il set di dati PostgreSQL
Dal menu a sinistra selezionare Icona Autore .
Selezionare Set di dati e quindi selezionare il menu Puntini di sospensione Azioni set di dati (
...).
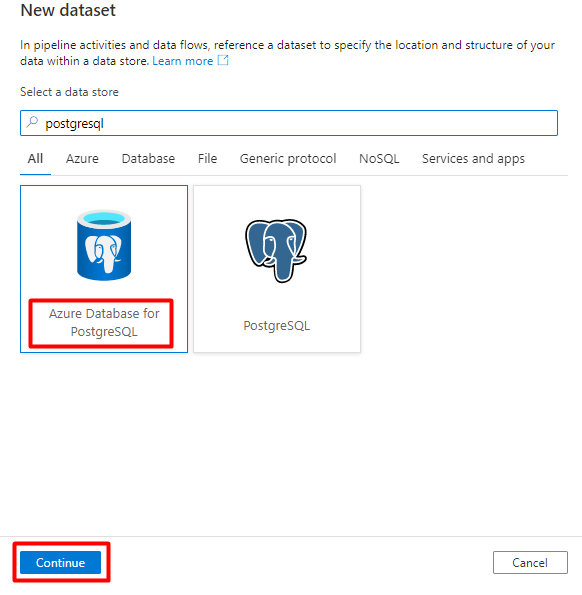
Selezionare Nuovo set di dati.
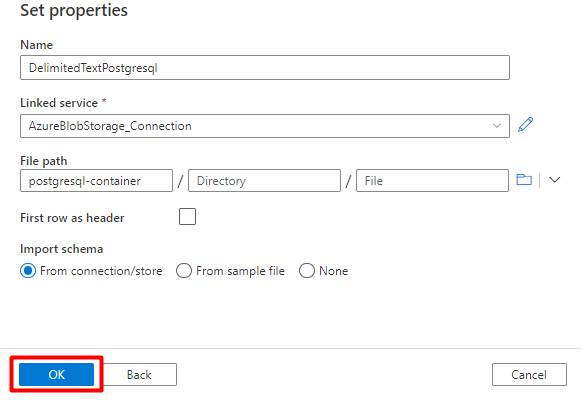
Nel riquadro destro, nella ricerca dell'archivio dati immettere "postgresql". Selezionare il riquadro di Azure PostgreSQL . Selezionare Continua.
Compilare i valori Imposta proprietà :
Scegliere il servizio collegato PostgreSQL creato nel passaggio 1.
Selezionare la tabella da importare/indicizzare.
Selezionare OK.
Selezionare Salva.
Passaggio 3: Creare un nuovo indice in Ricerca cognitiva di Azure
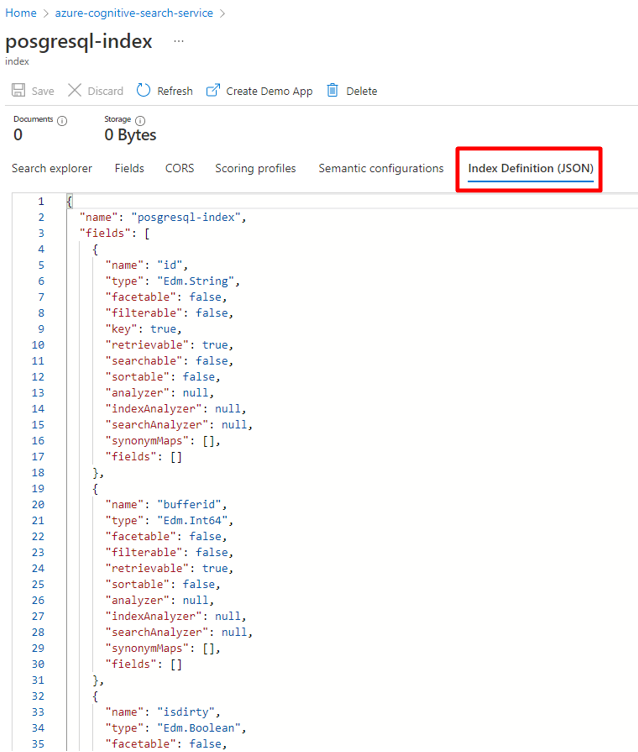
Creare un nuovo indice nel servizio Ricerca cognitiva di Azure con lo stesso schema usato per i dati PostgreSQL.
È possibile riutilizzare l'indice attualmente usato per PostgreSQL Power Connector. Nella portale di Azure trovare l'indice e quindi selezionare Definizione di indice (JSON). Selezionare la definizione e copiarla nel corpo della nuova richiesta di indice.
Passaggio 4: Configurare Ricerca cognitiva di Azure servizio collegato
Dal menu a sinistra selezionare l'icona Gestisci .
In Servizi collegati selezionare Nuovo.
Nel riquadro destro, nella ricerca dell'archivio dati immettere "search". Selezionare Riquadro Ricerca di Azure e selezionare Continua.
Compilare i valori del nuovo servizio collegato :
- Scegliere la sottoscrizione di Azure in cui risiede il servizio Ricerca cognitiva di Azure.
- Scegliere il servizio Ricerca cognitiva di Azure con l'indicizzatore del connettore Power Query.
- Selezionare Crea.
Passaggio 5: Configurare Ricerca cognitiva di Azure Set di dati
Dal menu a sinistra selezionare Icona Autore .
Selezionare Set di dati e quindi selezionare il menu Puntini di sospensione Azioni set di dati (
...).
Selezionare Nuovo set di dati.
Nel riquadro destro, nella ricerca dell'archivio dati immettere "search". Selezionare il riquadro Ricerca di Azure e selezionare Continua.
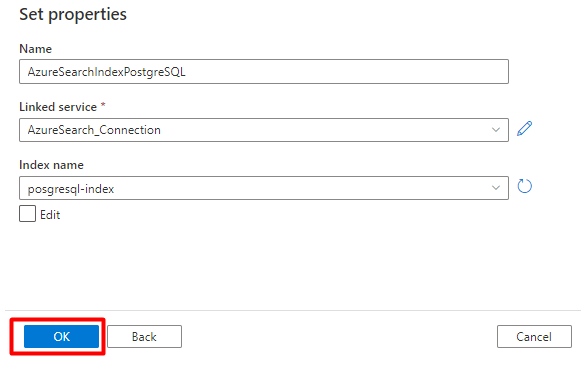
In Imposta proprietà:
Selezionare il servizio collegato creato per Ricerca cognitiva di Azure nel passaggio 4.
Scegliere l'indice creato come parte del passaggio 3.
Selezionare OK.
Selezionare Salva.
Passaggio 6: Configurare Archiviazione BLOB di Azure servizio collegato
Dal menu a sinistra selezionare Gestisci icona.
In Servizi collegati selezionare Nuovo.
Nel riquadro destro, nella ricerca dell'archivio dati immettere "archiviazione". Selezionare il riquadro Archiviazione BLOB di Azure e selezionare Continua.
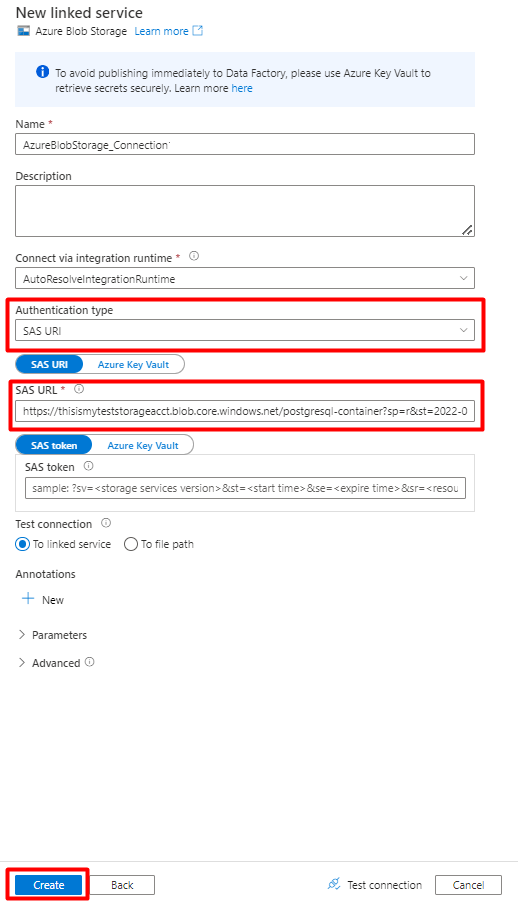
Compilare i valori del nuovo servizio collegato :
Scegliere il tipo di autenticazione: URI di firma di accesso condiviso. Solo questo metodo può essere usato per importare dati da PostgreSQL in Archiviazione BLOB di Azure.
Generare un URL di firma di accesso condiviso per l'account di archiviazione usato per la gestione temporanea e copiare l'URL della firma di accesso condiviso BLOB nel campo URL di firma di accesso condiviso.
Selezionare Crea.
Passaggio 7: Configurare il set di dati di archiviazione
Dal menu a sinistra selezionare Icona Autore .
Selezionare Set di dati e quindi selezionare il menu Puntini di sospensione Azioni set di dati (
...).
Selezionare Nuovo set di dati.
Nel riquadro destro, nella ricerca dell'archivio dati immettere "archiviazione". Selezionare il riquadro Archiviazione BLOB di Azure e selezionare Continua.
Selezionare DelimitedText format (DelimitedText format) e selezionare Continua.
In Delimitatore riga selezionare Feed riga (\n).
Selezionare Prima riga come casella di intestazione .
Selezionare Salva.
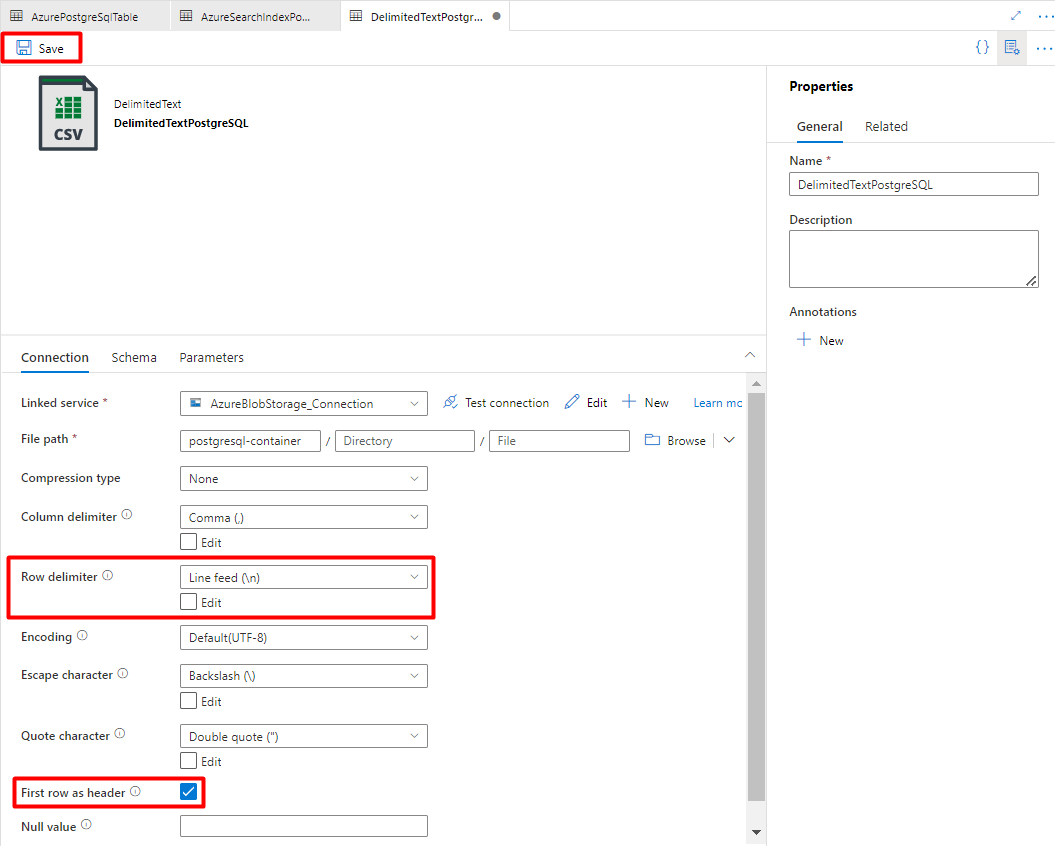
Passaggio 8: Configurare la pipeline
Dal menu a sinistra selezionare Icona Autore .
Selezionare Pipeline e quindi selezionare il menu Puntini di sospensione delle azioni pipeline (
...).
Selezionare New pipeline (Nuova pipeline).
Creare e configurare le attività di Data Factory copiate da PostgreSQL al contenitore di archiviazione di Azure.
Espandere Sposta & sezione trasformazione e trascinare e rilasciare l'attività Copia dati nell'area di disegno dell'editor della pipeline vuota.
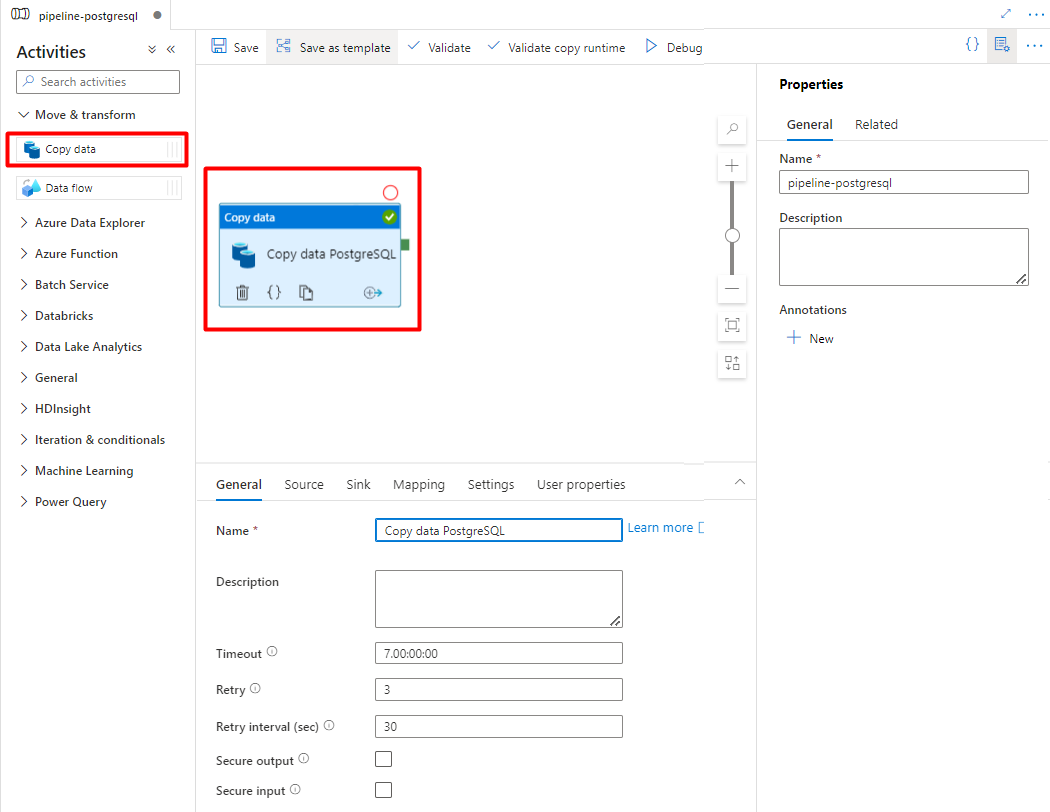
Aprire la scheda Generale , accettare i valori predefiniti, a meno che non sia necessario personalizzare l'esecuzione.
Nella scheda Origine selezionare la tabella PostgreSQL. Lasciare le opzioni rimanenti con i valori predefiniti.
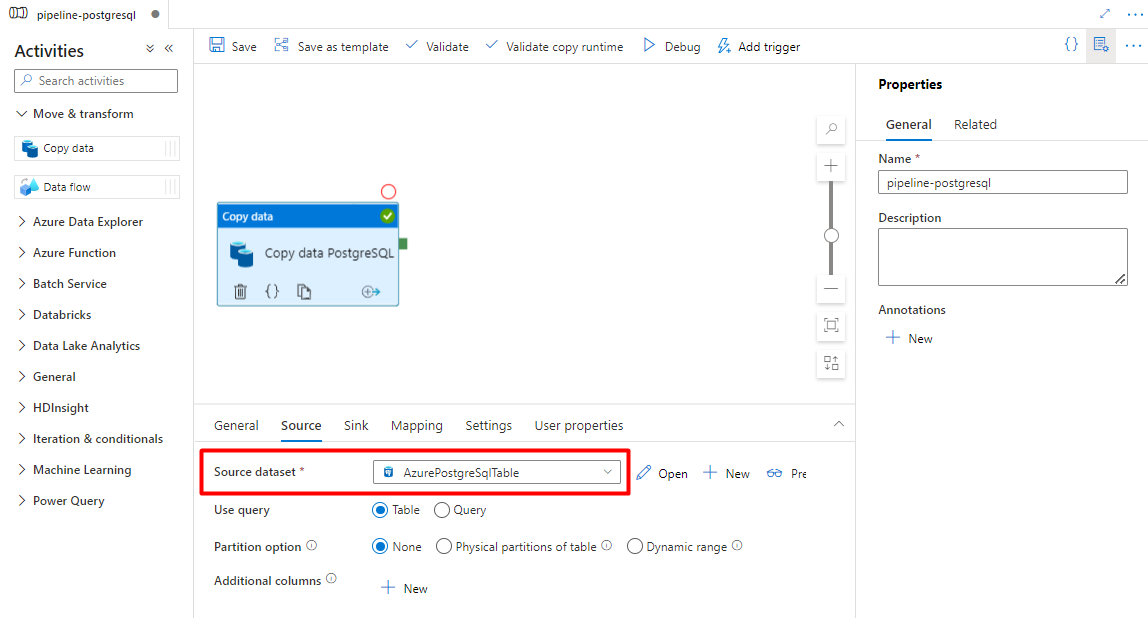
Nella scheda Sink :
Selezionare il set di dati PostgreSQL delimitato dall'archiviazione configurato nel passaggio 7.
In Estensione file aggiungere .csv
Lasciare le opzioni rimanenti con i valori predefiniti.
Selezionare Salva.
Configurare le attività copiate da Archiviazione di Azure a un indice di ricerca:
Espandere Sposta & sezione trasformazione e trascinare e rilasciare l'attività Copia dati nell'area di disegno dell'editor della pipeline vuota.
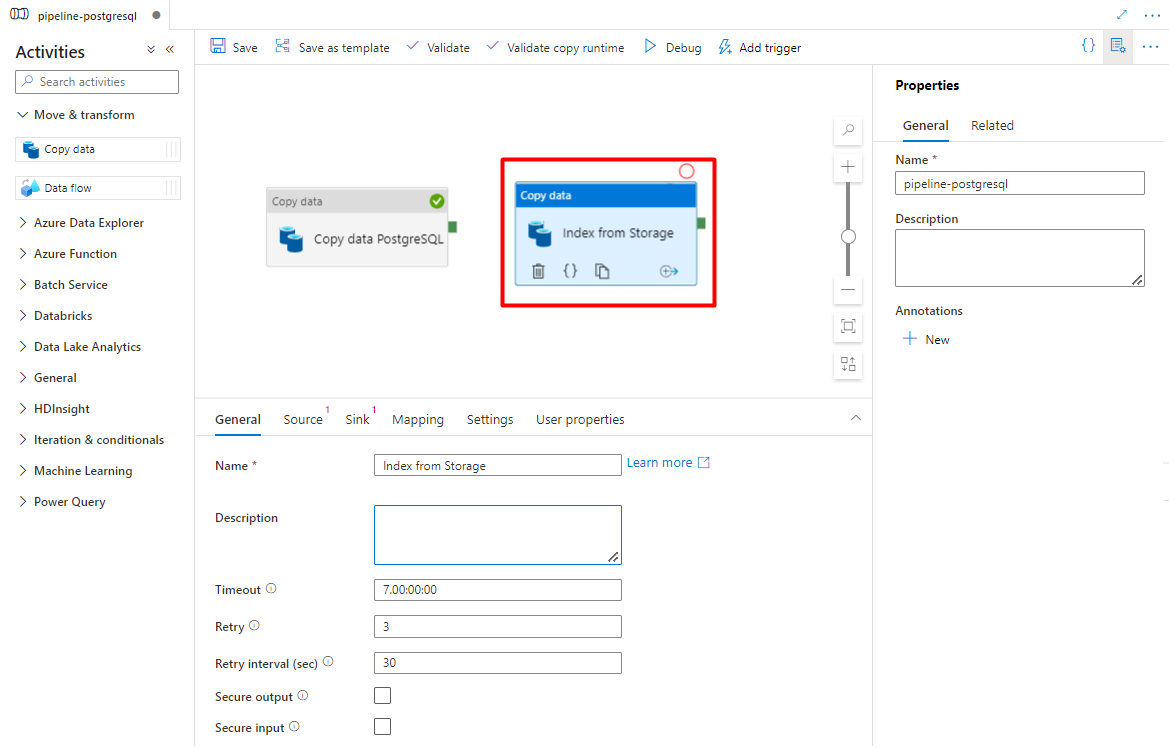
Nella scheda Generale lasciare i valori predefiniti, a meno che non sia necessario personalizzare l'esecuzione.
Nella scheda Origine :
- Selezionare il set di dati di origine di archiviazione configurato nel passaggio 7.
- Nel campo Tipo di percorso file selezionare Percorso jolly.
- Lasciare tutti i campi rimanenti con valori predefiniti.
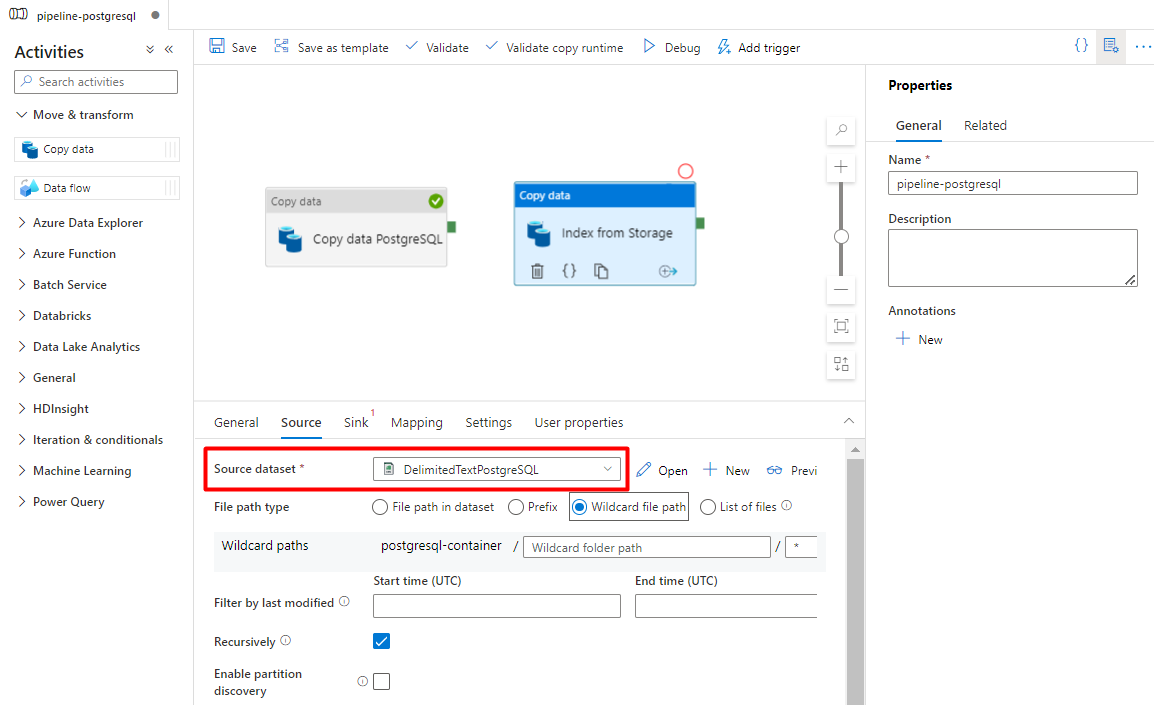
Nella scheda Sink selezionare l'indice Ricerca cognitiva di Azure. Lasciare le opzioni rimanenti con i valori predefiniti.
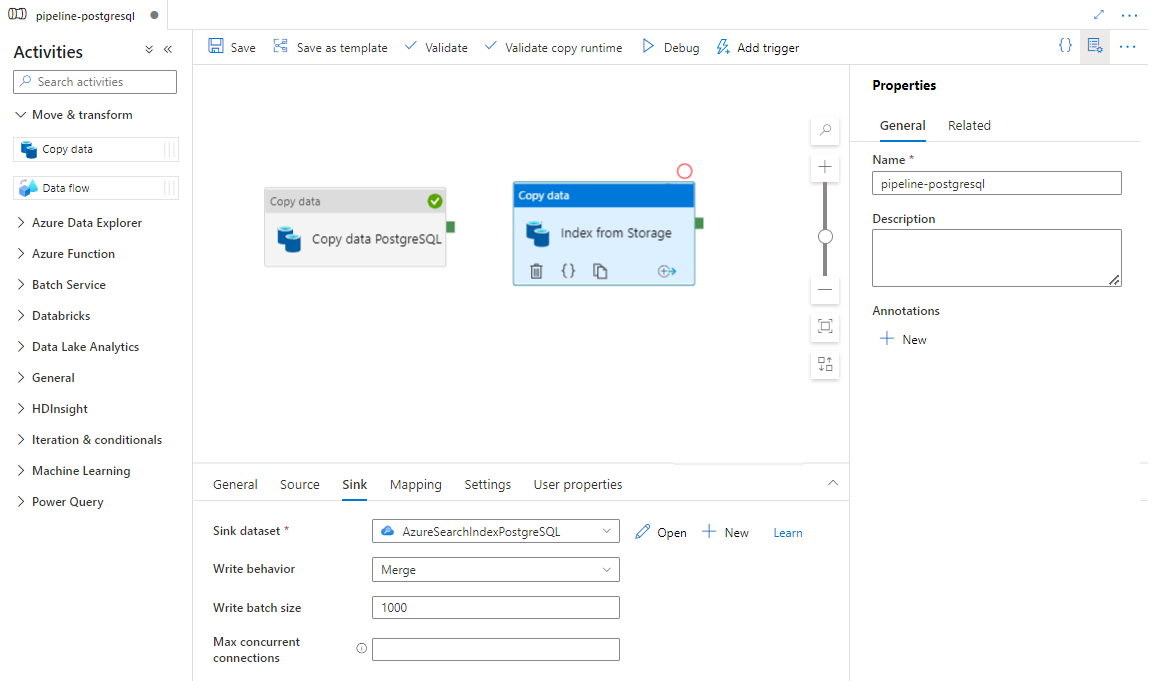
Selezionare Salva.
Passaggio 9: Configurare l'ordine di attività
Nell'editor canvas pipeline selezionare il quadrato verde al bordo dell'attività della pipeline. Trascinarla nell'attività "Indici dall'account di archiviazione a Ricerca cognitiva di Azure" per impostare l'ordine di esecuzione.
Selezionare Salva.
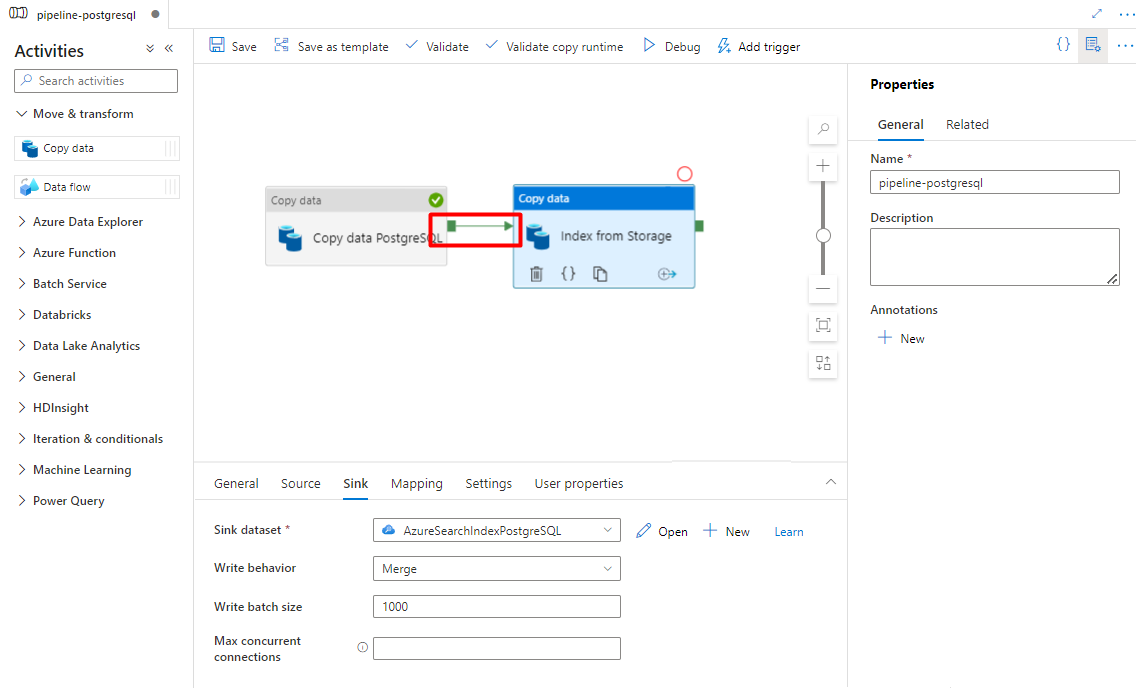
Passaggio 10: Aggiungere un trigger della pipeline
Selezionare Aggiungi trigger per pianificare l'esecuzione della pipeline e selezionare Nuovo/Modifica.
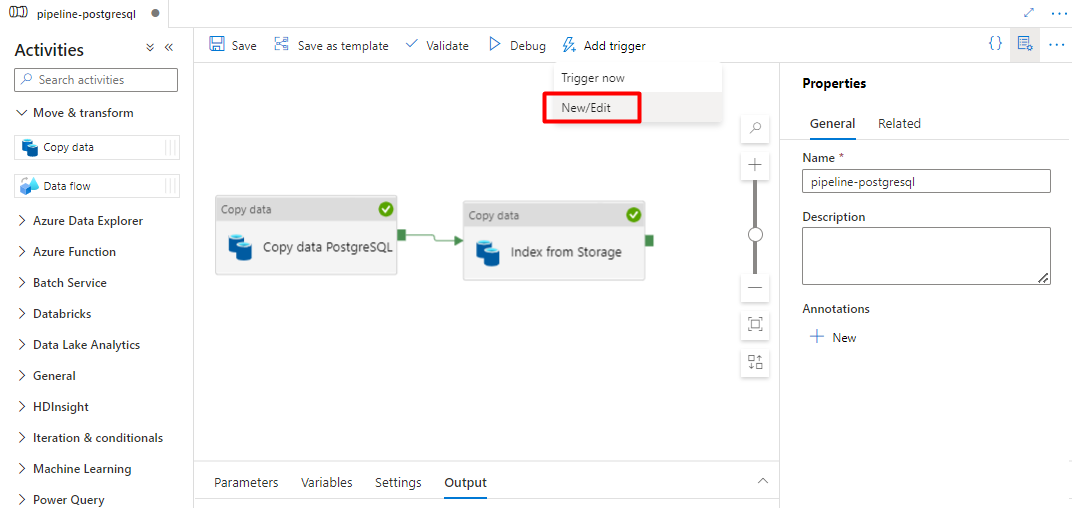
Nell'elenco a discesa Scegli trigger selezionare Nuovo.
Esaminare le opzioni del trigger per eseguire la pipeline e selezionare OK.
Selezionare Salva.
Selezionare Pubblica.
Contenuto legacy per l'anteprima del connettore Power Query
Un connettore Power Query viene usato con un indicizzatore di ricerca per automatizzare l'inserimento dei dati da varie origini dati, incluse quelle in altri provider cloud. Usa Power Query per recuperare i dati.
Le origini dati supportate nell'anteprima includono:
- Amazon Redshift
- Elasticsearch
- PostgreSQL
- Oggetti Salesforce
- Report di Salesforce
- Smartsheet
- Snowflake
Funzionalità supportate
Power Query connettori vengono usati negli indicizzatori. Un indicizzatore in Ricerca cognitiva di Azure è un crawler che estrae dati e metadati ricercabili da un'origine dati esterna e popola un indice basato sui mapping da campo a campo tra l'indice e l'origine dati. Questo approccio viene talvolta definito "modello pull" perché il servizio esegue il pull dei dati in senza dover scrivere alcun codice che aggiunge dati a un indice. Gli indicizzatori offrono un modo pratico per gli utenti di indicizzare il contenuto dall'origine dati senza dover scrivere un modello di ricerca per indicizzazione o push personalizzato.
Gli indicizzatori che fanno riferimento Power Query origini dati hanno lo stesso livello di supporto per set di competenze, pianificazioni, logica di rilevamento delle modifiche al contrassegno dell'acqua elevata e la maggior parte dei parametri supportati da altri indicizzatori.
Prerequisiti
Anche se non è più possibile usare questa funzionalità, sono presenti i requisiti seguenti durante l'anteprima:
Ricerca cognitiva di Azure servizio in un'area supportata.
Registrazione di anteprima. Questa funzionalità deve essere abilitata nel back-end.
Archiviazione BLOB di Azure account, usato come intermediario per i dati. I dati verranno trasmessi dall'origine dati, quindi all'archiviazione BLOB, quindi all'indice. Questo requisito esiste solo con l'anteprima del gated iniziale.
Disponibilità a livello di area
L'anteprima è stata disponibile solo nei servizi di ricerca nelle aree seguenti:
- Stati Uniti centrali
- Stati Uniti orientali
- Stati Uniti orientali 2
- Stati Uniti centro-settentrionali
- Europa settentrionale
- Stati Uniti centro-meridionali
- Stati Uniti centro-occidentali
- Europa occidentale
- Stati Uniti occidentali
- West US 2
Limiti di anteprima
In questa sezione vengono descritte le limitazioni specifiche della versione corrente dell'anteprima.
Il pull dei dati binari dall'origine dati non è supportato.
La sessione di debug non è supportata.
Introduzione all'uso dell'portale di Azure
Il portale di Azure fornisce supporto per i connettori Power Query. Eseguendo il campionamento dei dati e la lettura dei metadati nel contenitore, la procedura guidata Importa dati in Ricerca cognitiva di Azure può creare un indice predefinito, eseguire il mapping dei campi di origine ai campi di indice di destinazione e caricare l'indice in una singola operazione. A seconda delle dimensioni e della complessità dei dati di origine, si può ottenere un indice di ricerca full-text operativo in pochi minuti.
Il video seguente illustra come configurare un connettore di Power Query in Ricerca cognitiva di Azure.
Passaggio 1: Preparare i dati di origine
Assicurarsi che l'origine dati contenga dati. La procedura guidata Importa dati legge i metadati ed esegue il campionamento dei dati per dedurre uno schema di indice, ma carica anche i dati dall'origine dati. Se i dati sono mancanti, la procedura guidata si arresterà e restituirà e restituisce un errore.
Passaggio 2 : Avviare l'importazione guidata dei dati
Dopo aver approvato l'anteprima, il team Ricerca cognitiva di Azure fornisce un collegamento portale di Azure che usa un flag di funzionalità in modo che sia possibile accedere ai connettori Power Query. Aprire questa pagina e avviare la procedura guidata dalla barra dei comandi nella pagina del servizio Ricerca cognitiva di Azure selezionando Importa dati.
Passaggio 3: selezionare l'origine dati
Esistono alcune origini dati da cui è possibile eseguire il pull dei dati tramite questa anteprima. Tutte le origini dati che usano Power Query includono un "Powered By Power Query" nel riquadro. Selezionare l'origine dati.
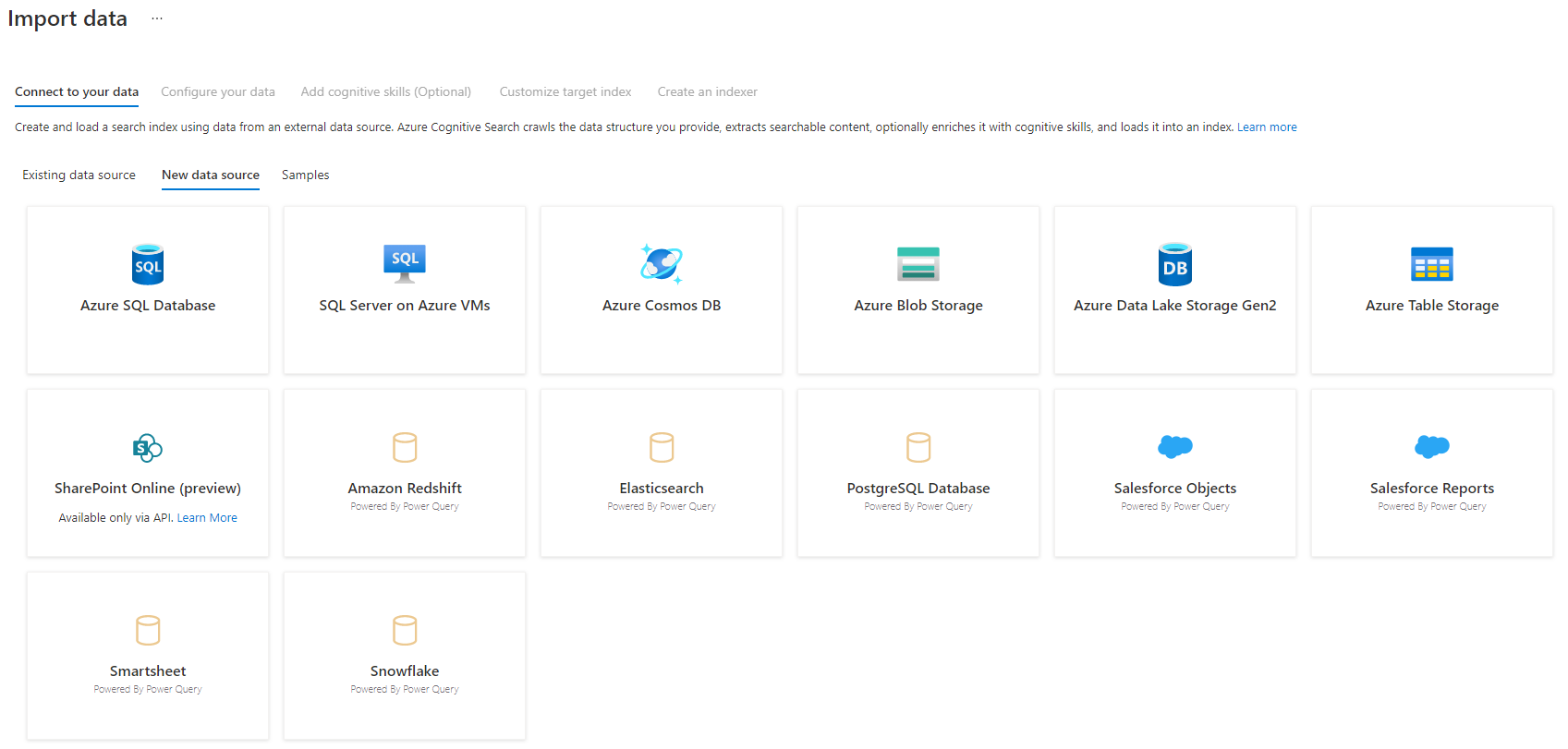
Dopo aver selezionato l'origine dati, selezionare Avanti: Configurare i dati per passare alla sezione successiva.
Passaggio 4: configurare i dati
In questo passaggio verrà configurata la connessione. Ogni origine dati richiederà informazioni diverse. Per alcune origini dati, la documentazione di Power Query fornisce maggiori dettagli su come connettersi ai dati.
Dopo aver fornito le credenziali di connessione, selezionare Avanti.
Passaggio 5: selezionare i dati
La procedura guidata di importazione visualizza in anteprima varie tabelle disponibili nell'origine dati. In questo passaggio si verificherà una tabella contenente i dati da importare nell'indice.
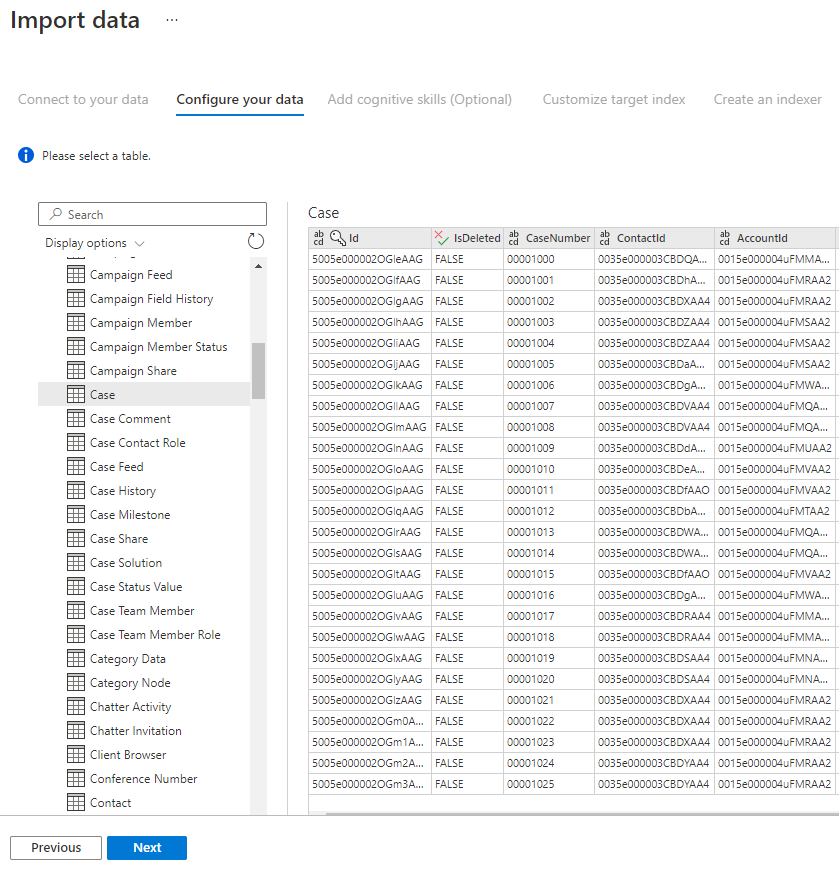
Dopo aver selezionato la tabella, selezionare Avanti.
Passaggio 6 : Trasformare i dati (facoltativo)
Power Query connettori offrono un'esperienza avanzata dell'interfaccia utente che consente di modificare i dati in modo da poter inviare i dati corretti all'indice. È possibile rimuovere colonne, filtrare righe e molto altro ancora.
Non è necessario trasformare i dati prima di importarlo in Ricerca cognitiva di Azure.
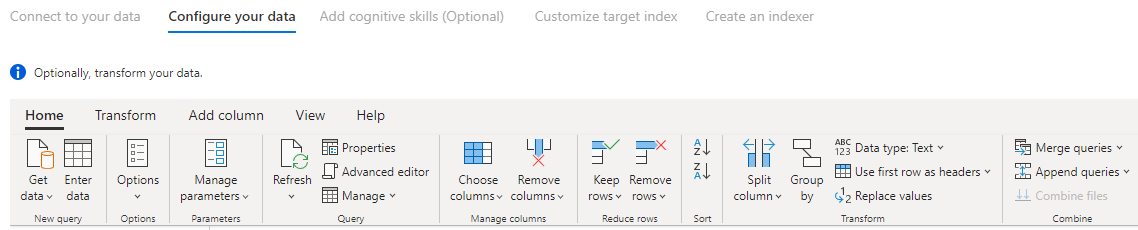
Per altre informazioni sulla trasformazione dei dati con Power Query, vedere Uso di Power Query in Power BI Desktop.
Dopo la trasformazione dei dati, selezionare Avanti.
Passaggio 7 : Aggiungere l'archiviazione BLOB di Azure
L'anteprima del connettore Power Query richiede attualmente di fornire un account di archiviazione BLOB. Questo passaggio esiste solo con l'anteprima del gated iniziale. Questo account di archiviazione BLOB fungerà da archiviazione temporanea per i dati che si spostano dall'origine dati a un indice Ricerca cognitiva di Azure.
È consigliabile fornire un account di archiviazione di accesso completo stringa di connessione:
{ "connectionString" : "DefaultEndpointsProtocol=https;AccountName=<your storage account>;AccountKey=<your account key>;" }
È possibile ottenere la stringa di connessione dalla portale di Azure passando al pannello > Impostazioni > account di archiviazione (per account di archiviazione classici) o Impostazioni > chiavi di accesso (per gli account di archiviazione di Azure Resource Manager).
Dopo aver fornito un nome origine dati e stringa di connessione, selezionare "Avanti: Aggiungere competenze cognitive (facoltativo)".
Passaggio 8 : Aggiungere competenze cognitive (facoltativo)
L'arricchimento dell'intelligenza artificiale è un'estensione di indicizzatori che possono essere usati per rendere il contenuto più ricercabile.
È possibile aggiungere eventuali arricchimenti che aggiungono vantaggio allo scenario. Al termine, selezionare Avanti: Personalizzare l'indice di destinazione.
Passaggio 9 : Personalizzare l'indice di destinazione
Nella pagina Indice verrà visualizzato un elenco di campi con un tipo di dati e una serie di caselle di controllo per l'impostazione degli attributi di indice. La procedura guidata può generare un elenco di campi in base ai metadati e campionamento dei dati di origine.
È possibile selezionare in blocco gli attributi selezionando la casella di controllo nella parte superiore di una colonna di attributi. Scegliere Recuperabile e Cercabile per ogni campo che deve essere restituito a un'app client e soggetto all'elaborazione della ricerca full-text. Si noterà che i numeri interi non sono full text o ricercabili fuzzy (i numeri vengono valutati verbatim e spesso sono utili nei filtri).
Per altre informazioni, vedere la descrizione degli attributi dell'indice e degli analizzatori del linguaggio.
Dedicare qualche momento alla revisione delle selezioni. Dopo aver eseguito la procedura guidata, le strutture dati fisiche vengono create e non sarà possibile modificare la maggior parte delle proprietà per questi campi senza eliminare e ricreare tutti gli oggetti.
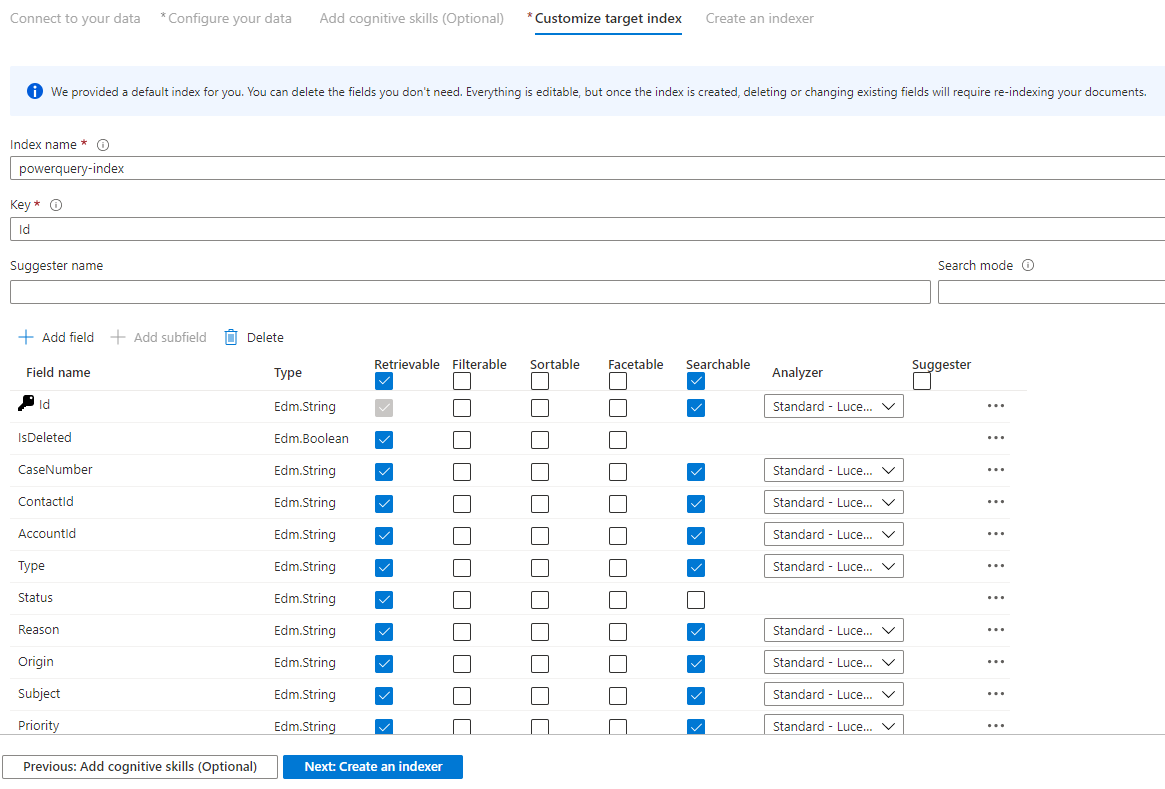
Al termine, selezionare Avanti: Creare un indicizzatore.
Passaggio 10 - Creare un indicizzatore
L'ultimo passaggio crea l'indicizzatore. La denominazione dell'indicizzatore ne consente l'esistenza come risorsa autonoma, che può essere pianificata e gestita in modo indipendente dagli oggetti indice e origine dati, creati nella stessa sequenza della procedura guidata.
L'output della procedura guidata Importa dati è un indicizzatore che esegue la ricerca per indicizzazione dell'origine dati e importa i dati selezionati in un indice in Ricerca cognitiva di Azure.
Quando si crea l'indicizzatore, è possibile scegliere facoltativamente di eseguire l'indicizzatore in una pianificazione e aggiungere il rilevamento delle modifiche. Per aggiungere il rilevamento delle modifiche, designare una colonna "contrassegno di acqua elevata".
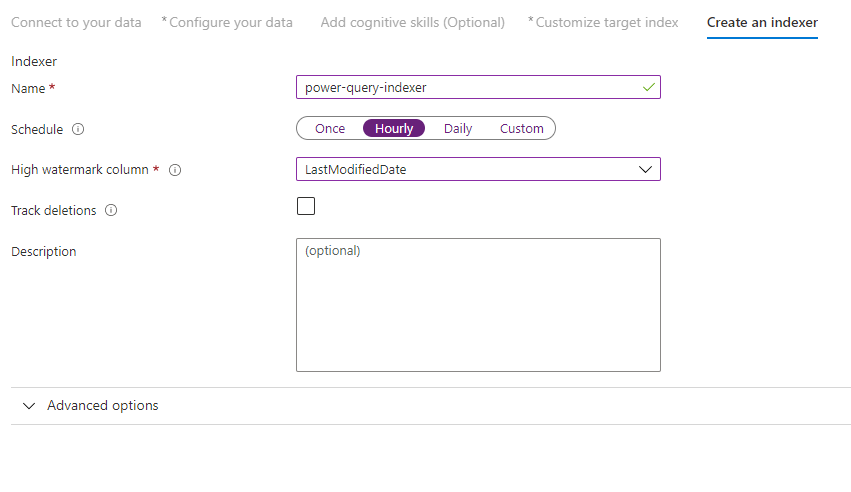
Dopo aver completato la compilazione di questa pagina, selezionare Invia.
Criteri di rilevamento delle modifiche con limite massimo
Questi criteri di rilevamento delle modifiche si basano su una colonna di "livello più alto" che acquisisce la versione o l'ora dell'ultimo aggiornamento di una riga.
Requisiti
- Tutti gli inserimenti specificano un valore per la colonna.
- Tutti gli aggiornamenti a un elemento modificano anche il valore della colonna.
- Il valore di questa colonna aumenta in base a ogni modifica o aggiornamento.
Nomi di colonna non supportati
I nomi dei campi in un indice Ricerca cognitiva di Azure devono soddisfare determinati requisiti. Uno di questi requisiti è che alcuni caratteri come "/" non sono consentiti. Se un nome di colonna nel database non soddisfa questi requisiti, il rilevamento dello schema di indice non riconoscerà la colonna come nome di campo valido e non verrà visualizzato tale colonna come campo suggerito per l'indice. In genere, l'uso dei mapping dei campi risolve questo problema, ma i mapping dei campi non sono supportati nel portale.
Per indicizzare il contenuto da una colonna nella tabella con un nome di campo non supportato, rinominare la colonna durante la fase "Trasforma i dati" del processo di importazione dei dati. Ad esempio, è possibile rinominare una colonna denominata "Codice di fatturazione/Codice zip" in "zipcode". Rinominando la colonna, il rilevamento dello schema di indice lo riconoscerà come nome di campo valido e lo aggiungerà come suggerimento alla definizione dell'indice.
Passaggi successivi
Questo articolo illustra come eseguire il pull dei dati usando i connettori di Power Query. Poiché questa funzionalità di anteprima viene interrotta, spiega anche come eseguire la migrazione di soluzioni esistenti a uno scenario supportato.
Per altre informazioni sugli indicizzatori, vedere Indicizzatori in Ricerca cognitiva di Azure.