Come usare Azure Machine Learning Notebook in Spark
Importante
Azure HDInsight su Azure Kubernetes Service è stato ritirato il 31 gennaio 2025. Scopri di più con questo annuncio.
È necessario eseguire la migrazione dei carichi di lavoro a Microsoft Fabric o a un prodotto Azure equivalente per evitare la chiusura brusca dei carichi di lavoro.
Importante
Questa funzionalità è attualmente in anteprima. Le condizioni supplementari per l'utilizzo per le anteprime di Microsoft Azure includono termini legali più validi applicabili alle funzionalità di Azure in versione beta, in anteprima o altrimenti non ancora rilasciate nella disponibilità generale. Per informazioni su questa anteprima specifica, vedere informazioni sull'anteprima di Azure HDInsight su AKS. Per domande o suggerimenti sulle funzionalità, inviare una richiesta in AskHDInsight con i dettagli e seguire Microsoft per altri aggiornamenti su la Azure HDInsight Community.
Machine Learning è una tecnologia in continua crescita, che consente ai computer di apprendere automaticamente dai dati passati. Machine Learning usa vari algoritmi per la creazione di modelli matematici e l'esecuzione di stime usa dati o informazioni cronologiche. È stato definito un modello fino ad alcuni parametri e l'apprendimento è l'esecuzione di un programma informatico per ottimizzare i parametri del modello usando i dati o l'esperienza di training. Il modello può essere predittivo per eseguire stime in futuro o descrittive per ottenere informazioni dai dati.
Il notebook dell'esercitazione seguente illustra un esempio di addestramento di modelli di machine learning su dati tabulari. È possibile importare questo notebook ed eseguirlo manualmente.
Caricare il file CSV nella risorsa di archiviazione
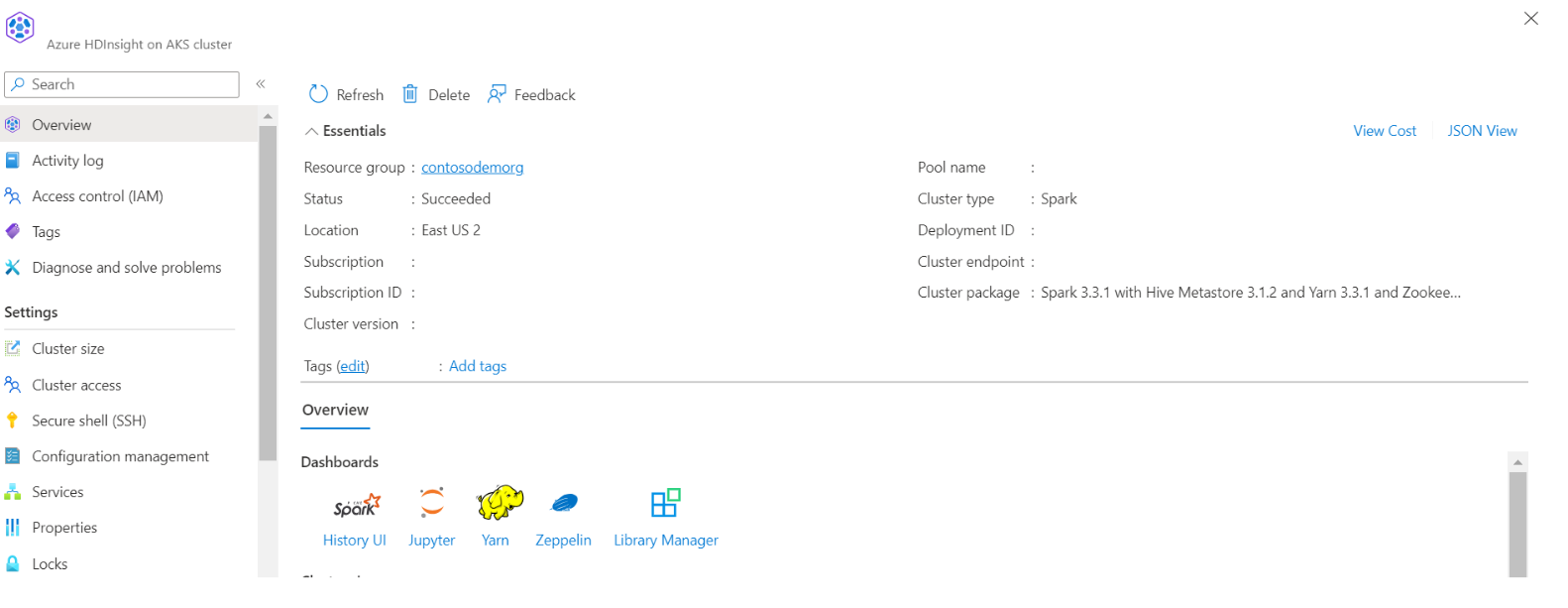
Trovare il nome dell'archiviazione e del contenitore nella visualizzazione JSON del portale
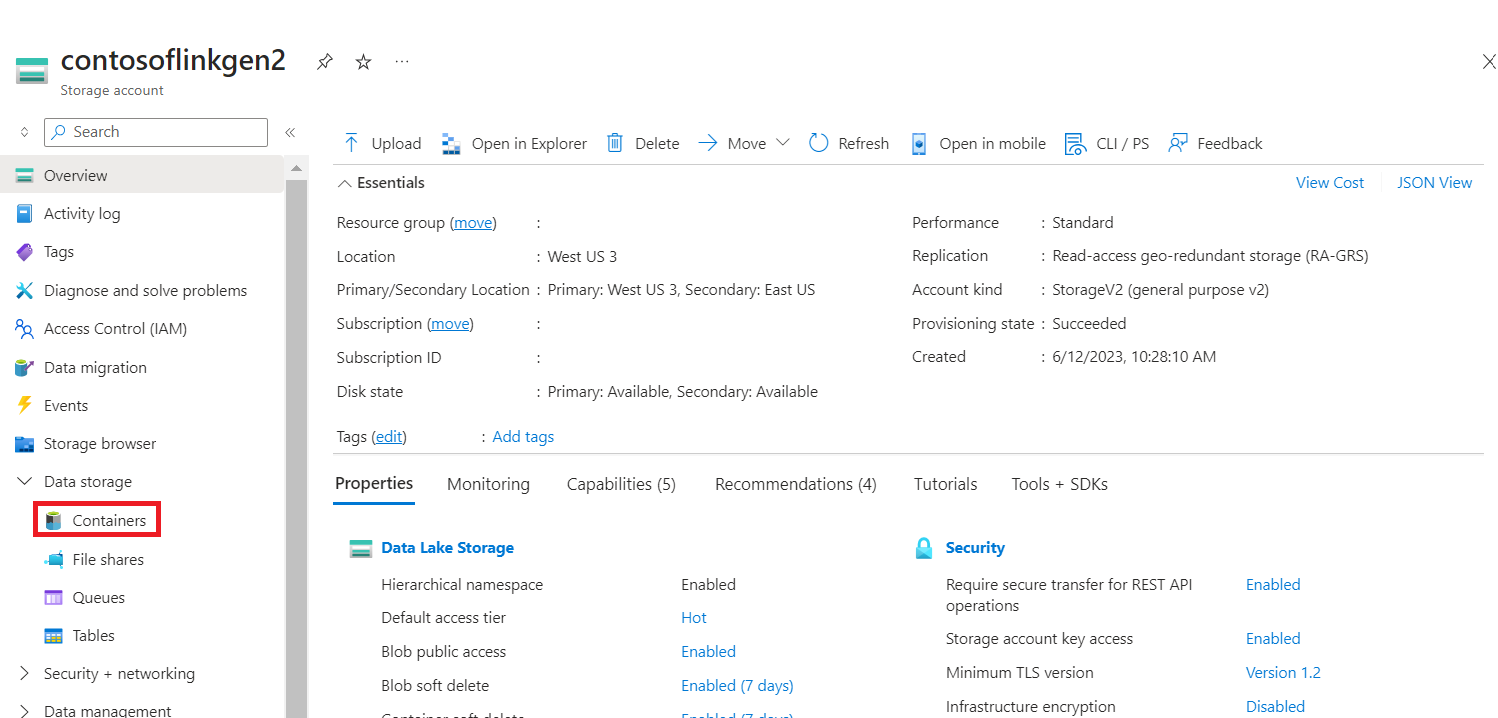
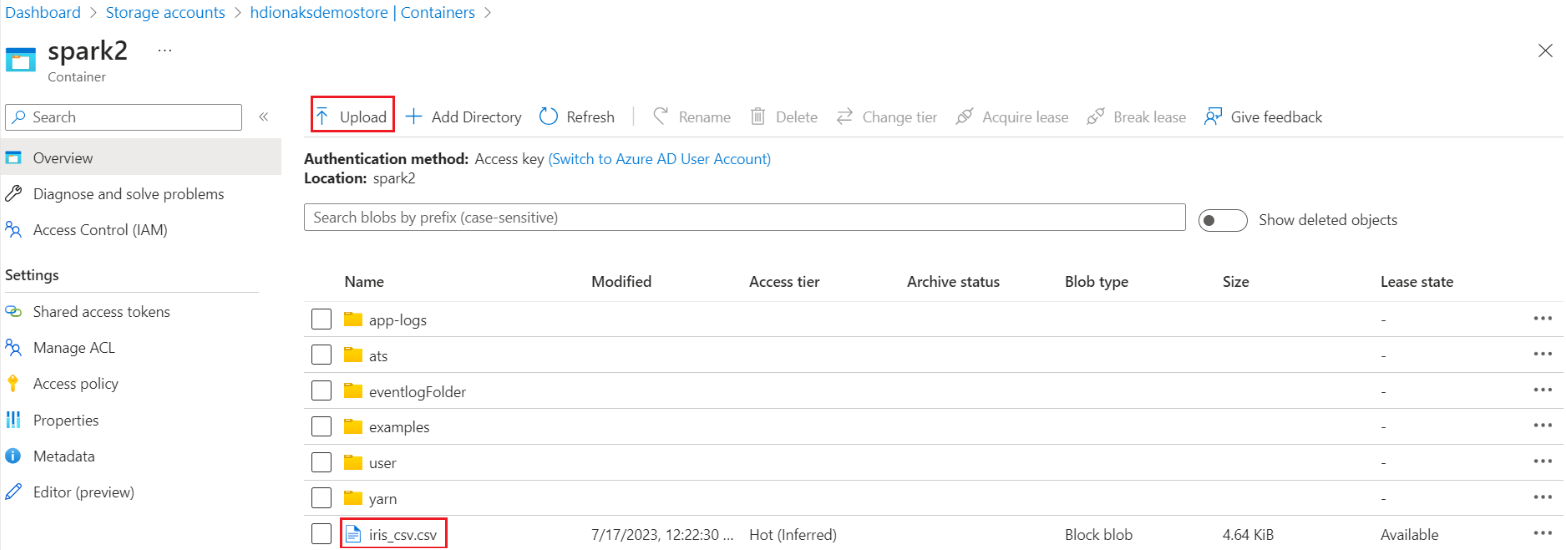
Accedere alla cartella di base del contenitore di archiviazione HDI primario>>> e caricare il CSV
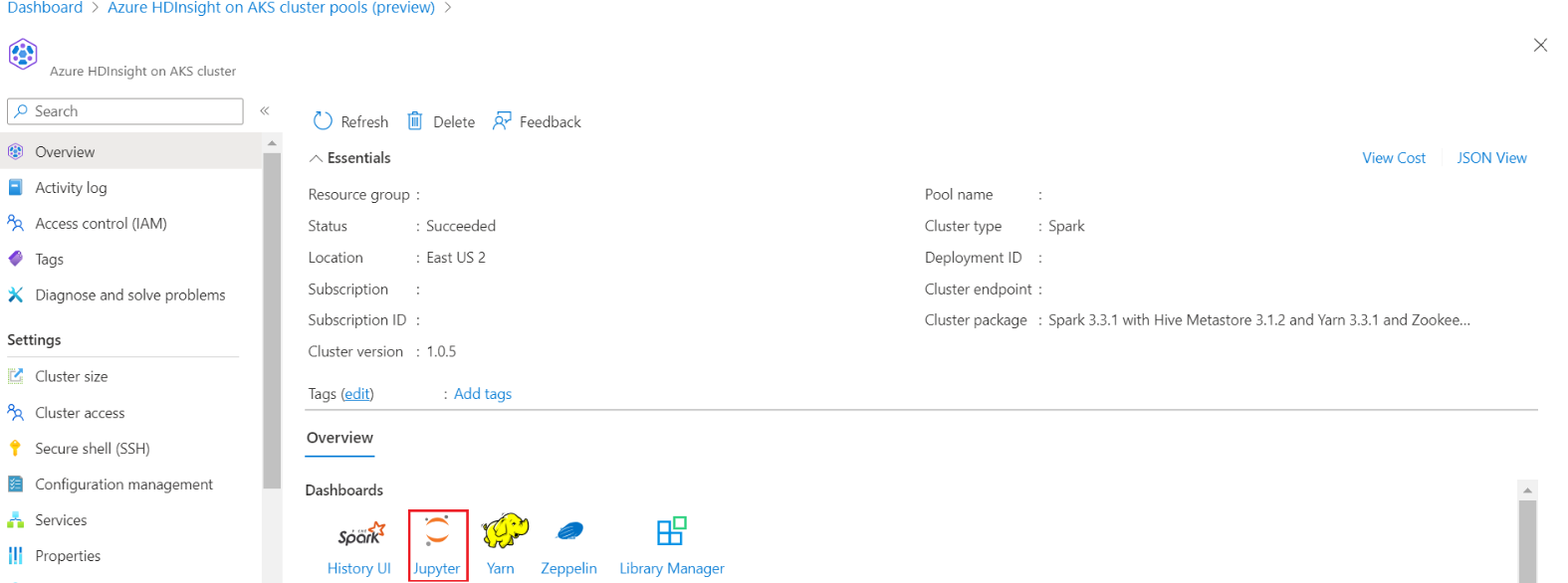
Accedere al cluster e aprire Jupyter Notebook
Importare librerie MLlib Spark per creare la pipeline
import pyspark from pyspark.ml import Pipeline, PipelineModel from pyspark.ml.classification import LogisticRegression from pyspark.ml.feature import VectorAssembler, StringIndexer, IndexToString
Leggere il file CSV in un dataframe Spark
df = spark.read.("abfss:///iris_csv.csv",inferSchema=True,header=True)Suddividere i dati per il training e il test
iris_train, iris_test = df.randomSplit([0.7, 0.3], seed=123)Creare la pipeline ed eseguire il training del modello
assembler = VectorAssembler(inputCols=['sepallength', 'sepalwidth', 'petallength', 'petalwidth'],outputCol="features",handleInvalid="skip") indexer = StringIndexer(inputCol="class", outputCol="classIndex", handleInvalid="skip") classifier = LogisticRegression(featuresCol="features", labelCol="classIndex", maxIter=10, regParam=0.01) pipeline = Pipeline(stages=[assembler,indexer,classifier]) model = pipeline.fit(iris_train) # Create a test `dataframe` with predictions from the trained model test_model = model.transform(iris_test) # Taking an output from the test dataframe with predictions test_model.take(1)
Valutare l'accuratezza del modello
import pyspark.ml.evaluation as ev evaluator = ev.MulticlassClassificationEvaluator(labelCol='classIndex') print(evaluator.evaluate(test_model,{evaluator.metricName: 'accuracy'}))



