Che cos'è Apache Spark™ in HDInsight su AKS? (Anteprima)
Importante
Azure HDInsight su Azure Kubernetes Service è stato ritirato il 31 gennaio 2025. Scopri di più con questo annuncio.
È necessario eseguire la migrazione dei carichi di lavoro a Microsoft Fabric o a un prodotto Azure equivalente per evitare la chiusura brusca dei carichi di lavoro.
Importante
Questa funzionalità è attualmente in anteprima. Le condizioni supplementari per l'utilizzo per le anteprime di Microsoft Azure includono termini legali più validi applicabili alle funzionalità di Azure in versione beta, in anteprima o altrimenti non ancora rilasciate nella disponibilità generale. Per informazioni su questa anteprima specifica, vedere informazioni sull'anteprima di Azure HDInsight su AKS. Per domande o suggerimenti sulle funzionalità, invia una richiesta su AskHDInsight con i dettagli e seguici per ulteriori aggiornamenti su Azure HDInsight Community.
Apache Spark™ è un framework di elaborazione parallela che supporta l'elaborazione in memoria per migliorare le prestazioni delle applicazioni analitiche di Big Data.
Apache Spark™ offre primitive per il calcolo dei cluster in memoria. Un processo Spark può caricare e memorizzare nella cache i dati in memoria e interrogarlo ripetutamente. L'elaborazione in memoria è più veloce rispetto alle applicazioni basate su disco, ad esempio Hadoop, che condivide i dati tramite hadoop distributed file system (HDFS). Apache Spark consente l'integrazione con i linguaggi di programmazione Scala e Python per consentire di modificare set di dati distribuiti come raccolte locali. Non è necessario strutturare tutto come operazioni di mapping e riduzione.
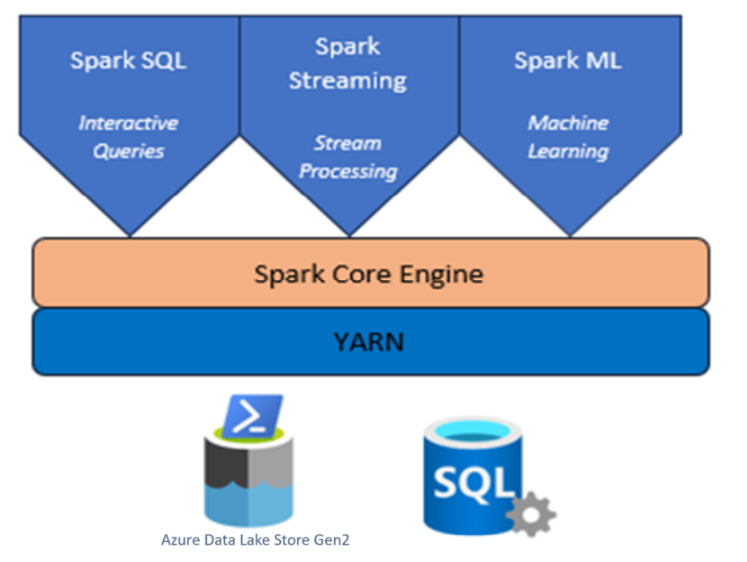
Cluster Apache Spark con HDInsight su Azure Kubernetes Service (AKS)
Azure HDInsight è un servizio di analisi open source gestito e a spettro completo per le aziende.
Apache Spark™ in Azure HDInsight nel Servizio Azure Kubernetes (AKS) è il servizio Spark gestito in Microsoft Azure. Con Apache Spark in Azure HDInsight su Azure Kubernetes Service (AKS), è possibile archiviare ed elaborare i dati all'interno di Azure. I cluster Spark in HDInsight sono compatibili con o Azure Data Lake Storage Gen2, consente di applicare l'elaborazione Spark negli archivi dati esistenti.
Il framework Apache Spark per HDInsight nel servizio Azure Kubernetes consente l'analisi rapida dei dati e il cluster computing usando l'elaborazione in memoria. Jupyter Notebook consente di interagire con i dati, combinare il codice con il testo markdown ed eseguire visualizzazioni semplici.
Apache Spark su Azure Kubernetes in HDInsight è composto da più componenti, definiti come pod.
Controller del cluster
I controller del cluster sono responsabili dell'installazione e della gestione del rispettivo servizio. Diversi controller vengono installati e gestiti in un cluster Spark.
Componenti del servizio Apache Spark
servizio Zookeeper: un cluster Zookeeper a tre nodi, funge da coordinatore distribuito o archiviazione a disponibilità elevata per altri servizi.
servizio Yarn: cluster Hadoop Yarn, i processi Spark verranno pianificati nel cluster come applicazioni Yarn.
interfacce client: i cluster Apache Spark in HDInsight su AKS forniscono varie interfacce client. Livy Server, Jupyter Notebook, Spark History Server, fornisce servizi Spark agli utenti di HDInsight su AKS.
Riferimento
- Apache, Apache Spark, Spark e i nomi dei progetti open source associati sono marchi della Apache Software Foundation (ASF).