Come usare Azure Pipelines con Apache Flink® su HDInsight su AKS
Importante
Azure HDInsight su AKS è stato ritirato il 31 gennaio 2025. Scopri di più con questo annuncio.
È necessario eseguire la migrazione dei carichi di lavoro a Microsoft Fabric o a un prodotto Azure equivalente per evitare la chiusura brusca dei carichi di lavoro.
Importante
Questa funzionalità è attualmente in anteprima. Le condizioni supplementari per l'utilizzo per le anteprime di Microsoft Azure includono termini legali più validi applicabili alle funzionalità di Azure in versione beta, in anteprima o altrimenti non ancora rilasciate nella disponibilità generale. Per informazioni su questa anteprima specifica, vedere Azure HDInsight in anteprima su AKS. Per domande o suggerimenti sulle funzionalità, si prega di inviare una richiesta su AskHDInsight con i dettagli e seguire Microsoft per altri aggiornamenti sul Azure HDInsight Community.
Questo articolo illustra come usare Azure Pipelines con HDInsight su AKS per inviare processi Flink con l'API REST del cluster. Verrà illustrato il processo usando una pipeline YAML di esempio e uno script di PowerShell, entrambi semplificano l'automazione delle interazioni con l'API REST.
Prerequisiti
Sottoscrizione di Azure. Se non si ha una sottoscrizione di Azure, creare un account gratuito.
Un account GitHub in cui è possibile creare un repository. Creane uno gratuitamente.
Crea la directory
.pipeline, copia flink-azure-pipelines.yml e flink-job-azure-pipeline.ps1Organizzazione di Azure DevOps. Creane uno gratuitamente. Se il team ne ha già uno, assicurarsi di essere un amministratore del progetto Azure DevOps che si vuole usare.
Possibilità di eseguire pipeline su agenti ospitati da Microsoft. Per usare gli agenti ospitati da Microsoft, l'organizzazione Azure DevOps deve avere accesso ai processi paralleli ospitati da Microsoft. È possibile acquistare un posto di lavoro parallelo oppure richiedere una sovvenzione gratuita.
Un cluster Flink. Se non ne hai uno, Creare un cluster Flink in HDInsight su AKS.
Creare una directory nell'account di archiviazione del cluster per copiare il file JAR del job. In un secondo momento, è necessario configurare questa directory nel file YAML della pipeline per il percorso del file jar del processo (<JOB_JAR_STORAGE_PATH>).
Passaggi per configurare la pipeline
Creare un'entità servizio per Azure Pipelines
Creare 'entità servizio Microsoft Entra per accedere ad Azure: concedere l'autorizzazione per accedere a HDInsight nel cluster del servizio Azure Kubernetes con il ruolo Collaboratore, prendere nota di appId, password e tenant dalla risposta.
az ad sp create-for-rbac -n <service_principal_name> --role Contributor --scopes <Flink Cluster Resource ID>`
Esempio:
az ad sp create-for-rbac -n azure-flink-pipeline --role Contributor --scopes /subscriptions/abdc-1234-abcd-1234-abcd-1234/resourceGroups/myResourceGroupName/providers/Microsoft.HDInsight/clusterpools/hiloclusterpool/clusters/flinkcluster`
Riferimento
Nota
Apache, Apache Flink, Flink e i nomi dei progetti open source associati sono marchi della Apache Software Foundation (ASF).
Creare un archivio di chiavi
Creare l'Azure Key Vault, è possibile seguire questo tutorial per creare un nuovo Azure Key Vault.
Creare tre segreti
cluster-storage-key per la chiave di archiviazione.
chiave del service-principal per il clientId o l'appId principale.
segreto del principale del servizio per il segreto principale.

Concedi l'autorizzazione per l'accesso ad Azure Key Vault con il ruolo "Key Vault Secrets Officer" al principale del servizio.

Configurare la pipeline
Passare al progetto e fare clic su Impostazioni progetto.
Scorrere verso il basso e selezionare Connessioni al servizio e quindi Nuova connessione al servizio.
Selezionare Azure Resource Manager.
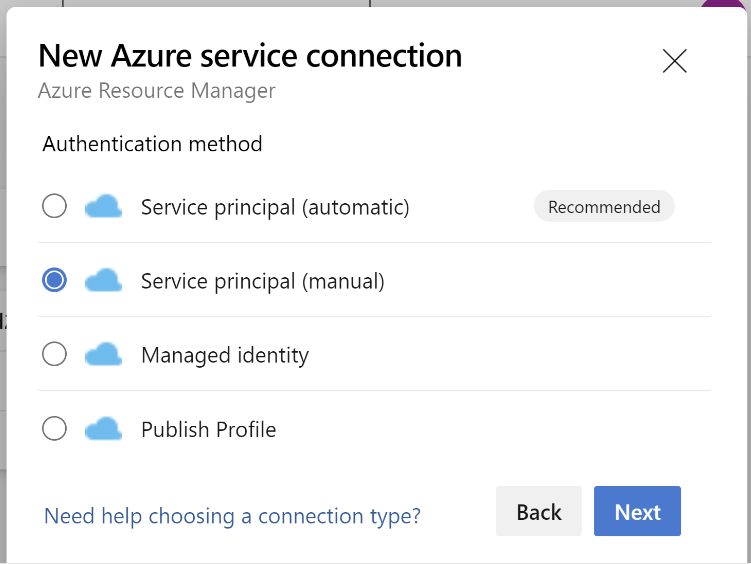
Nel metodo di autenticazione, selezionare "Entità del servizio" (manuale).
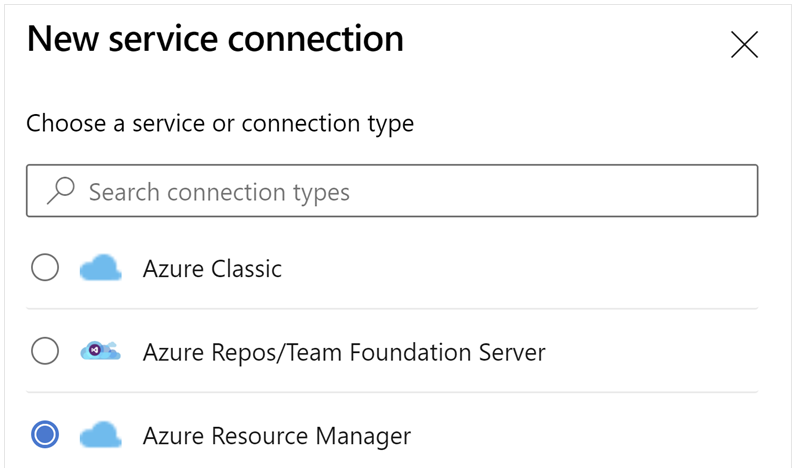
Modificare le proprietà di connessione del servizio. Selezionare l'entità servizio principale creata di recente.
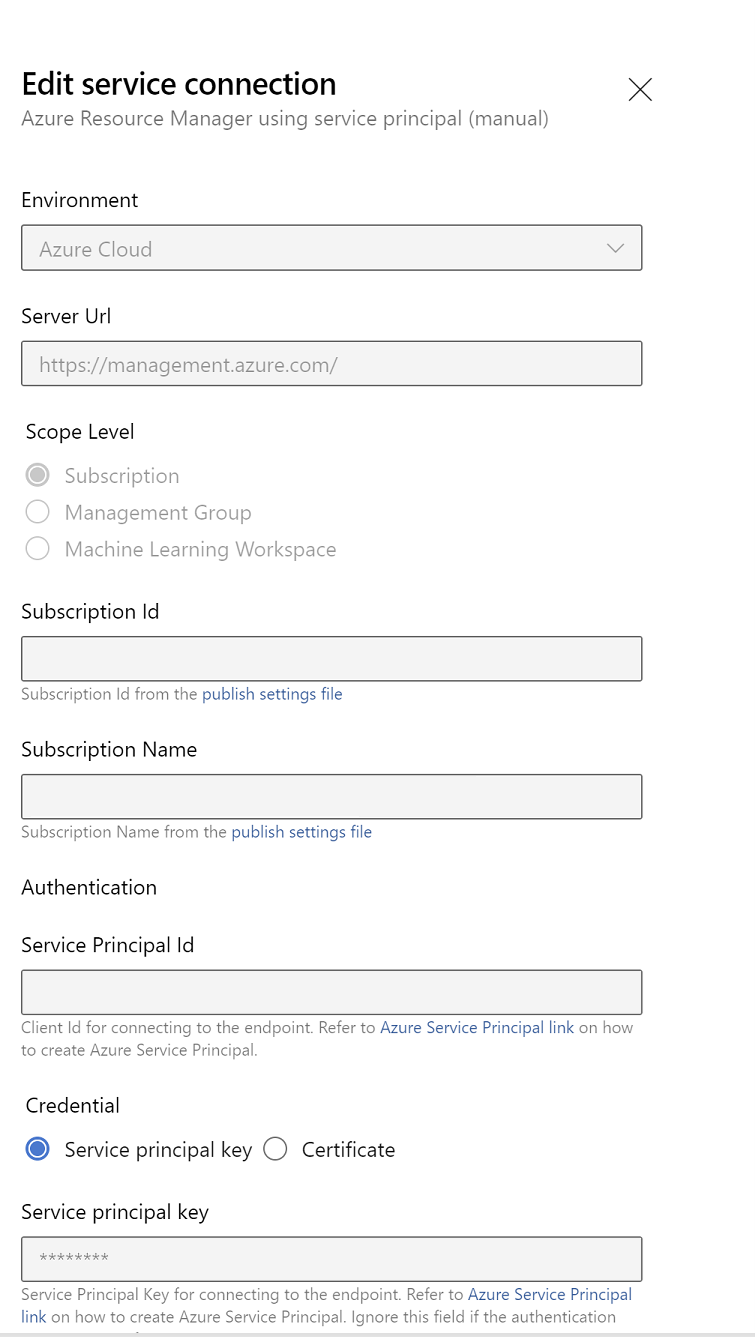
Fare clic su Verifica per verificare se la connessione è stata configurata correttamente. Se viene visualizzato l'errore seguente:

È quindi necessario assegnare il ruolo Lettore all'abbonamento.
Successivamente, la verifica dovrebbe avere successo.
Salvare la connessione al servizio.

Passare alle pipeline e fare clic su Nuova Pipeline.
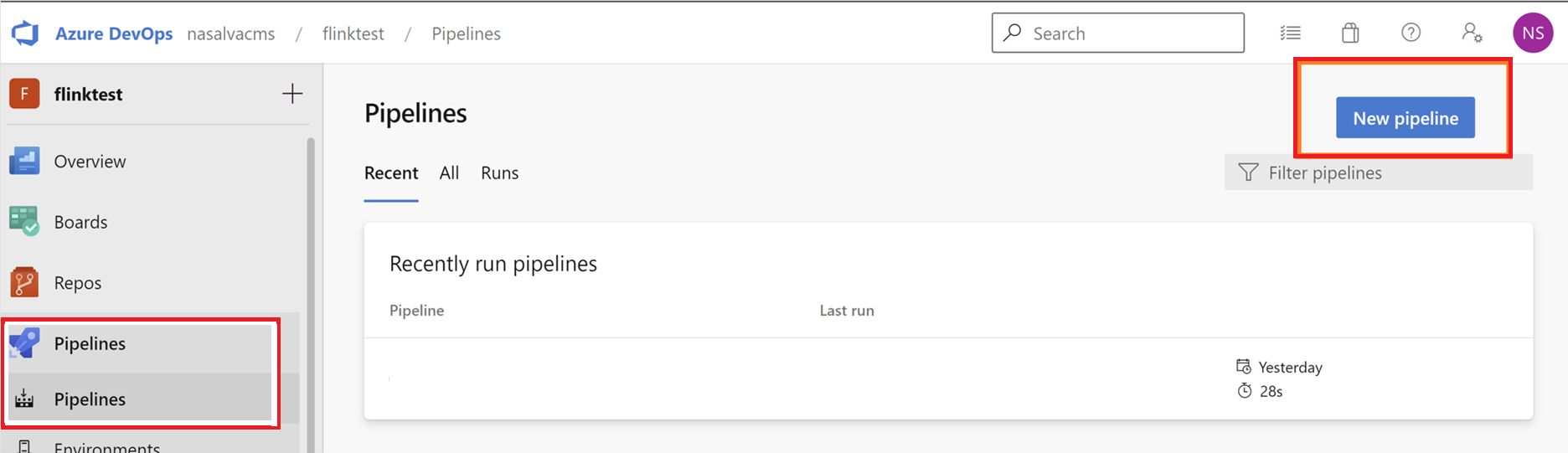
Selezionare GitHub come percorso del codice.
Selezionare il repository. Vedere come creare un repository in GitHub. immagine select-github-repo.
Seleziona il repository. Per altre informazioni, consulta la guida su come creare un repository su GitHub.
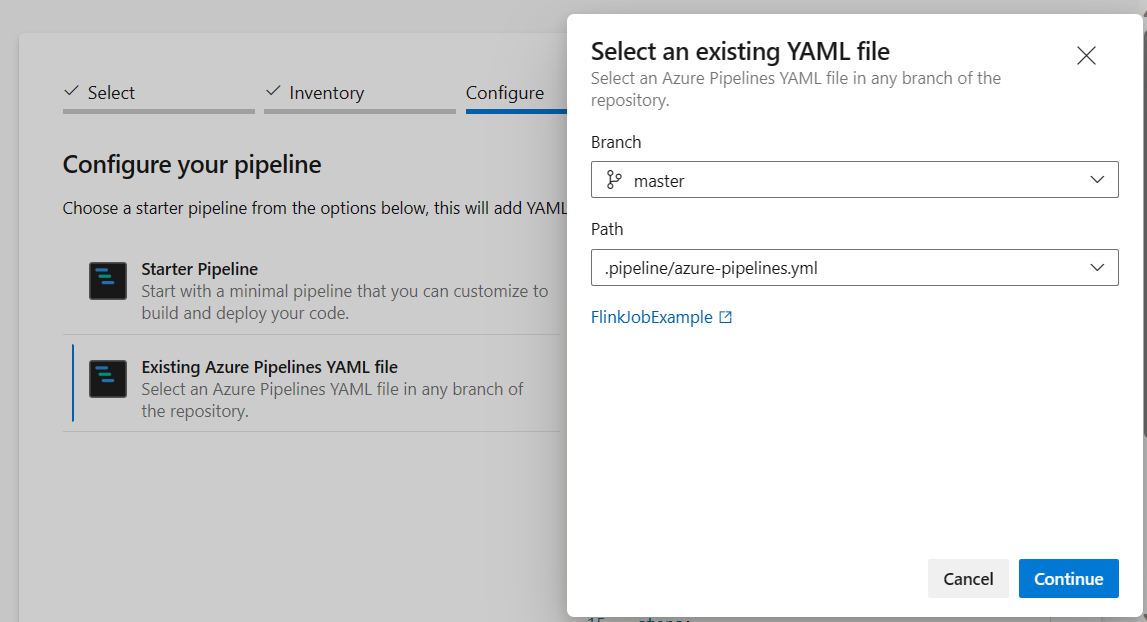
Dall'opzione configura la pipeline è possibile scegliere file YAML di Azure Pipelines esistente. Selezionare il branch e lo script della pipeline che hai copiato in precedenza. (.pipeline/flink-azure-pipelines.yml)
Sostituire il valore nella sezione della variabile.

Correggere la sezione di compilazione del codice in base alle esigenze e configurare <JOB_JAR_LOCAL_PATH> nella sezione variabile per il percorso locale del file JAR del processo.
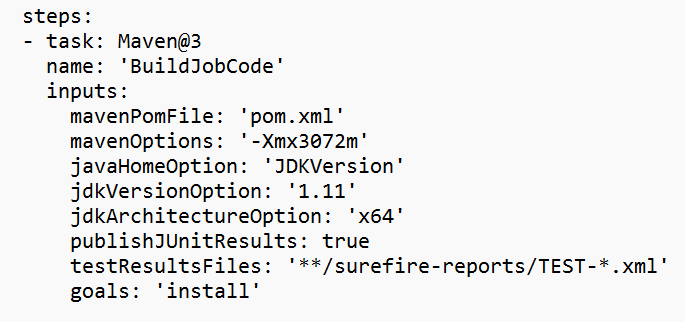
Aggiungere la variabile di pipeline "action" e configurare il valore "RUN".
è possibile modificare i valori della variabile prima di eseguire la pipeline.
NEW: questo valore è predefinito. Avvia un nuovo processo e, se il processo è già in esecuzione, aggiorna il processo in esecuzione con il file JAR più recente.
SAVEPOINT: questo valore accetta il punto di salvataggio per l'esecuzione del processo.
DELETE: annullare o eliminare il processo in esecuzione.
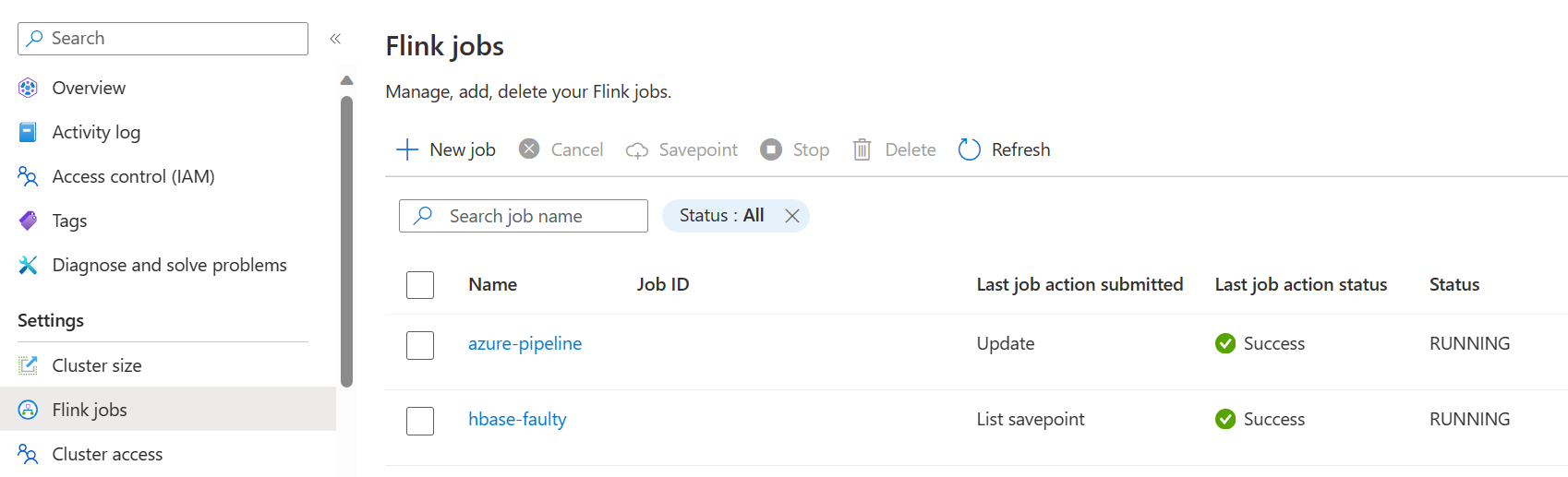
Salvare ed eseguire la pipeline. È possibile vedere il job in esecuzione nel portale nella sezione Flink Job.








Nota
Questo è un esempio per inviare il lavoro usando la pipeline. È possibile seguire la documentazione dell'API REST di Flink per scrivere il tuo codice per sottomettere il job.