Orchestrazione dei processi Apache Flink® con Gestione orchestrazione flussi di lavoro di Azure Data Factory (basata su Apache Airflow)
Importante
Azure HDInsight su Azure Kubernetes Service (AKS) è stato ritirato il 31 gennaio 2025. Scopri di più su con questo annuncio.
È necessario eseguire la migrazione dei carichi di lavoro a Microsoft Fabric o a un prodotto Azure equivalente per evitare la chiusura brusca dei carichi di lavoro.
Importante
Questa funzionalità è attualmente in anteprima. Le condizioni supplementari per l'utilizzo per le anteprime di Microsoft Azure includono termini legali più validi applicabili alle funzionalità di Azure in versione beta, in anteprima o altrimenti non ancora rilasciate nella disponibilità generale. Per informazioni su questa anteprima specifica, vedere informazioni sull'anteprima di Azure HDInsight su AKS. Per domande o suggerimenti sulle funzionalità, inviare una richiesta in AskHDInsight con i dettagli e seguire microsoft per altri aggiornamenti su community di Azure HDInsight.
Questo articolo illustra la gestione di un processo Flink usando API REST di Azure e la pipeline di dati di orchestrazione con Azure Data Factory Workflow Orchestration Manager. servizio di Gestione orchestrazione flussi di lavoro di Azure Data Factory è un modo semplice ed efficiente per creare e gestire ambienti Apache Airflow, consentendo di eseguire facilmente pipeline di dati su larga scala.
Apache Airflow è una piattaforma open source che crea, pianificazioni e monitora flussi di lavoro di dati complessi a livello di codice. Consente di definire un set di attività, chiamati operatori che possono essere combinati in grafici aciclici diretti (DAG) per rappresentare le pipeline di dati.
Il diagramma seguente illustra il posizionamento di Airflow, Key Vault e HDInsight su AKS (Azure Kubernetes Service) in Azure.

Vengono create più entità servizio di Azure in base all'ambito per limitare l'accesso necessario e gestire il ciclo di vita delle credenziali client in modo indipendente.
È consigliabile ruotare periodicamente le chiavi di accesso o i segreti.
Procedura di installazione
Caricare il file JAR del processo Flink nell'account di archiviazione. Può essere l'account di archiviazione primario associato al cluster Flink o qualsiasi altro account di archiviazione, dove è necessario assegnare il ruolo "Proprietario dati BLOB di archiviazione" alla MSI (Managed Service Identity) assegnata dall'utente utilizzata per il cluster in questo account di archiviazione.
Azure Key Vault: È possibile seguire questa esercitazione per creare un nuovo Azure Key Vault nel caso in cui non ne abbiate già uno.
Creare entità servizio Microsoft Entra per accedere a Key Vault: concedere l'autorizzazione per accedere ad Azure Key Vault con il ruolo di "Key Vault Secrets Officer" e prendere nota di "appId", "password" e "tenant" dalla risposta. È necessario usare lo stesso per Airflow per usare l'archiviazione di Key Vault come back-end per l'archiviazione di informazioni riservate.
az ad sp create-for-rbac -n <sp name> --role “Key Vault Secrets Officer” --scopes <key vault Resource ID>Abilitare Azure Key Vault per Workflow Orchestration Manager per archiviare e gestire le informazioni riservate in modo sicuro e centralizzato. In questo modo è possibile usare variabili e connessioni e archiviarli automaticamente in Azure Key Vault. I nomi delle connessioni e delle variabili devono essere preceduti da variables_prefix definito in AIRFLOW__SECRETS__BACKEND_KWARGS. Ad esempio, se variables_prefix ha un valore come hdinsight-aks-variables, per una chiave variabile hello, si vuole archiviare la variabile in hdinsight-aks-variable -hello.
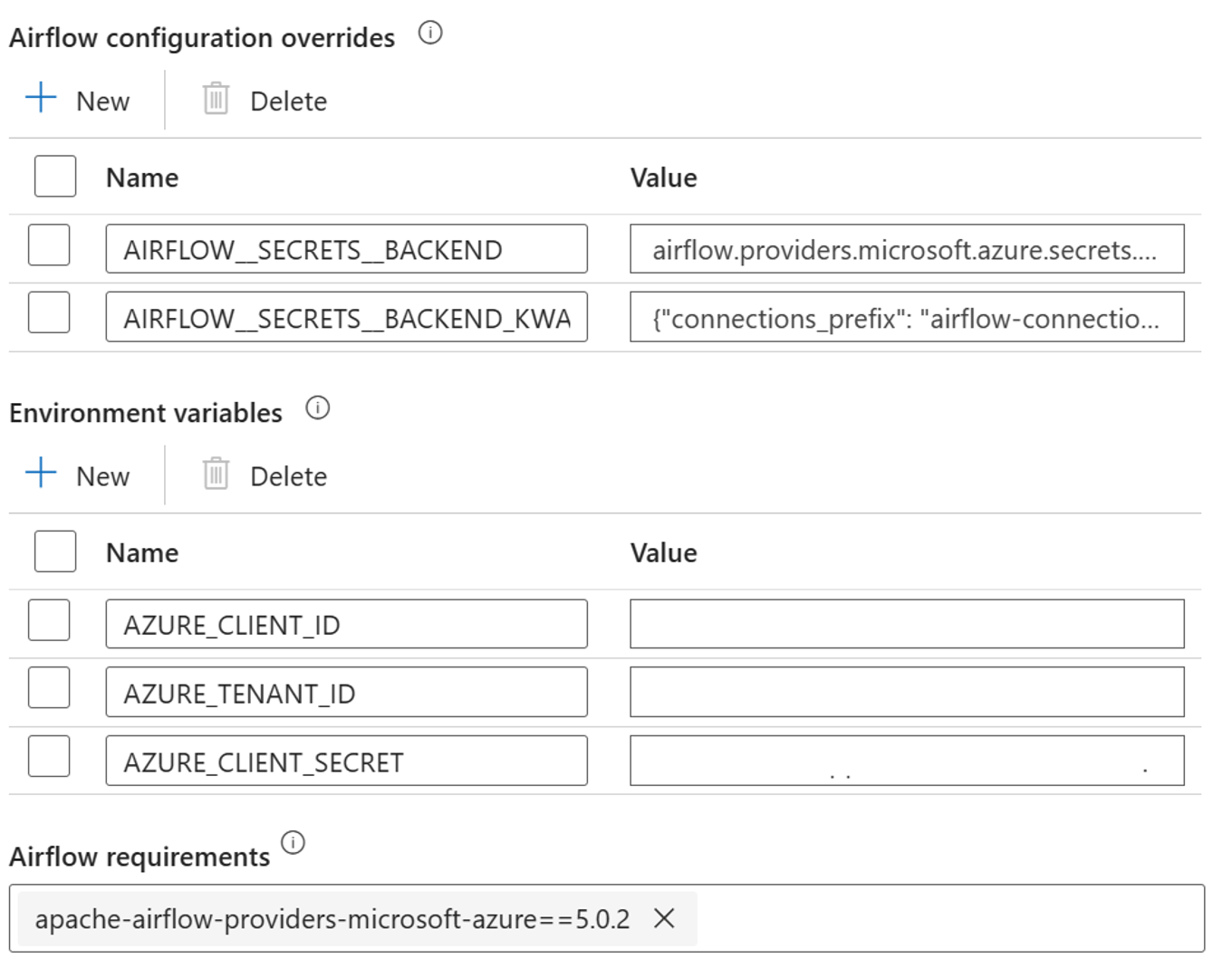
Aggiungere le impostazioni seguenti per le sostituzioni della configurazione di Airflow nelle proprietà integrate di runtime.
AIRFLOW__SECRETS__BACKEND:
"airflow.providers.microsoft.azure.secrets.key_vault.AzureKeyVaultBackend"AIRFLOW__SECRETS__BACKEND_KWARGS:
"{"connections_prefix": "airflow-connections", "variables_prefix": "hdinsight-aks-variables", "vault_url": <your keyvault uri>}”
Aggiungere l'impostazione seguente per la configurazione delle variabili di ambiente nelle proprietà del runtime integrato Airflow:
AZURE_CLIENT_ID =
<App Id from Create Azure AD Service Principal>AZURE_TENANT_ID =
<Tenant from Create Azure AD Service Principal>AZURE_CLIENT_SECRET =
<Password from Create Azure AD Service Principal>
Aggiungere i requisiti di Airflow - apache-airflow-providers-microsoft-azure
Creare 'entità servizio Microsoft Entra per accedere ad Azure: concedere l'autorizzazione per accedere al cluster del servizio Azure Kubernetes HDInsight con il ruolo Collaboratore, prendere nota di appId, password e tenant dalla risposta.
az ad sp create-for-rbac -n <sp name> --role Contributor --scopes <Flink Cluster Resource ID>Crea i seguenti segreti nel tuo insieme di credenziali delle chiavi con il valore dell'AppId, della password e del tenant dell'entità servizio AD precedente, che abbia come prefisso la variabile variables_prefix definita in AIRFLOW__SECRETS__BACKEND_KWARGS. Il codice DAG può accedere a una di queste variabili senza variables_prefix.
hdinsight-aks-variables-api-client-id=
<App ID from previous step>hdinsight-aks-variables-api-secret=
<Password from previous step>hdinsight-aks-variables-tenant-id=
<Tenant from previous step>
from airflow.models import Variable def retrieve_variable_from_akv(): variable_value = Variable.get("client-id") print(variable_value)

Definizione di DAG
Un DAG (Directed Acyclic Graph) è il concetto principale di Airflow, raccogliendo le attività e organizzandole con dipendenze e relazioni per stabilire come devono essere eseguite.
Esistono tre modi per dichiarare un DAG:
È possibile usare un gestore del contesto, che aggiunge il DAG a qualsiasi elemento all'interno di esso in modo implicito
È possibile usare un costruttore standard, passando il DAG a qualsiasi operatore usato
È possibile usare l'@dag decorator per trasformare una funzione in un generatore DAG (da airflow.decorators importare dag)
I DAG non sono niente senza Attività da eseguire e questi sono sotto forma di operatori, sensori o TaskFlow.
È possibile leggere altri dettagli sui dag, sul flusso di controllo, sui sottoDAg, sui gruppi di attività e così via direttamente da Apache Airflow.
Esecuzione di DAG
Il codice di esempio è disponibile nel git; scaricare il codice in locale nel computer e caricare il wordcount.py in un archivio BLOB. Seguire i passaggi per importare DAG nel flusso di lavoro creato durante l'installazione.
Il wordcount.py è un esempio di orchestrazione di un invio di job Flink tramite Apache Airflow con HDInsight su AKS. Il DAG ha due attività:
ottenere
OAuth TokenRichiamare l'API REST per l'invio di processi Flink di HDInsight per inviare un nuovo processo
Il DAG prevede di disporre della configurazione per il Service Principal, come descritto durante il processo di installazione per le credenziali client OAuth e passare la seguente configurazione di input per l'esecuzione.
Passaggi di esecuzione
Eseguire il DAG dall'interfaccia utente di Airflow . È possibile aprire l'interfaccia utente di Gestione dell'orchestrazione dei flussi di lavoro di Azure Data Factory facendo clic sull'icona Monitor.

Selezionare il DAG "FlinkWordCountExample" nella sezione "DAGs".

Fare clic sull'icona "esegui" nell'angolo in alto a destra e selezionare "Trigger DAG w/ config".
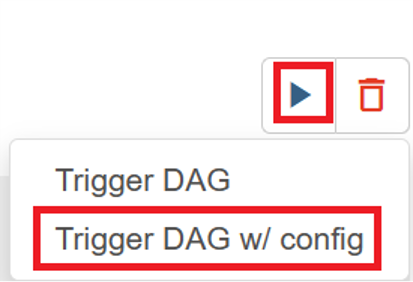
Passare il codice JSON di configurazione richiesto
{ "jarName":"WordCount.jar", "jarDirectory":"abfs://filesystem@<storageaccount>.dfs.core.windows.net", "subscription":"<cluster subscription id>", "rg":"<cluster resource group>", "poolNm":"<cluster pool name>", "clusterNm":"<cluster name>" }Fare clic sul pulsante "Trigger" per avviare l'esecuzione del DAG.
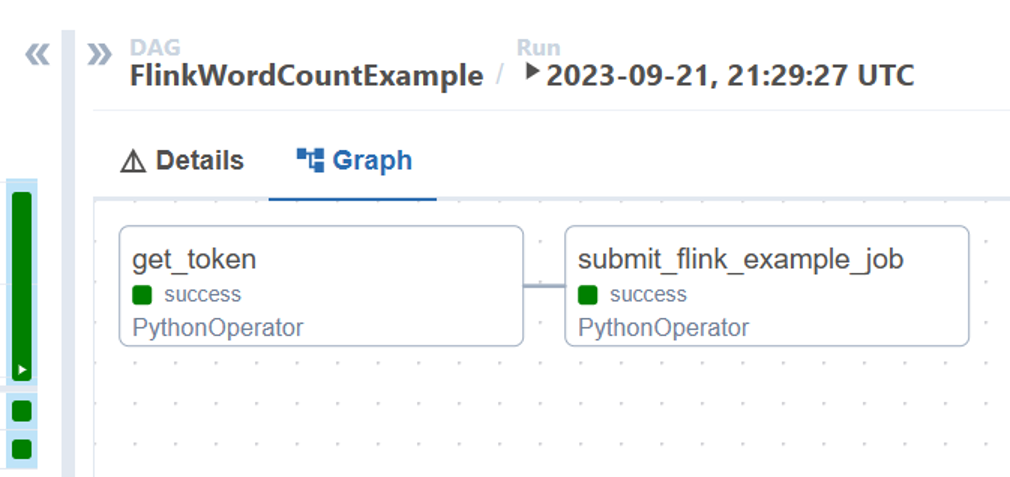
È possibile vedere lo stato delle attività DAG dalla run del DAG
Verificare l'esecuzione del lavoro dal portale
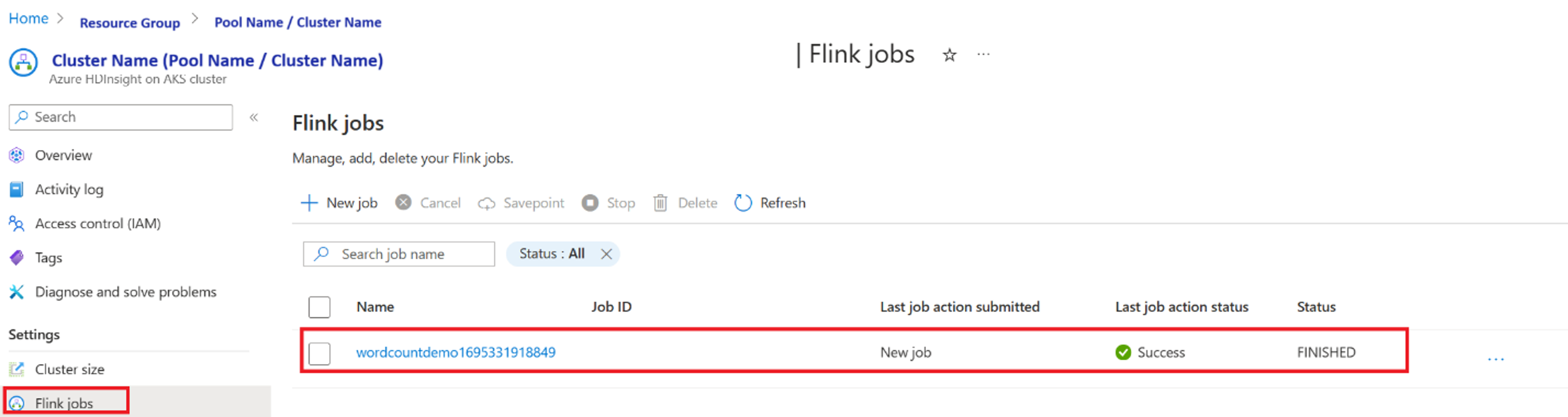
Verificare il lavoro da "Apache Flink Dashboard"






Codice di esempio
Questo è un esempio di orchestrazione della pipeline di dati utilizzando Airflow con HDInsight nel servizio Azure Kubernetes (AKS).
Il DAG prevede di avere la configurazione per il principale del servizio per la credenziale del cliente OAuth e passare la seguente configurazione di input per l'esecuzione.
{
'jarName':'WordCount.jar',
'jarDirectory':'abfs://filesystem@<storageaccount>.dfs.core.windows.net',
'subscription':'<cluster subscription id>',
'rg':'<cluster resource group>',
'poolNm':'<cluster pool name>',
'clusterNm':'<cluster name>'
}
Riferimento
- Fare riferimento al codice di esempio .
- sito Web Apache Flink
- Apache, Apache Airflow, Airflow, Apache Flink, Flink e i nomi dei progetti di open source associati sono marchi della Apache Software Foundation (ASF).