Gestione della configurazione di Apache Flink® in HDInsight su AKS
Importante
Azure HDInsight su AKS è stato ritirato il 31 gennaio 2025. Scopri di più con questo annuncio.
È necessario eseguire la migrazione dei carichi di lavoro a Microsoft Fabric o a un prodotto Azure equivalente per evitare la chiusura brusca dei carichi di lavoro.
Importante
Questa funzionalità è attualmente in anteprima. Le condizioni supplementari per l'utilizzo per le anteprime di Microsoft Azure includono termini legali più validi applicabili alle funzionalità di Azure in versione beta, in anteprima o altrimenti non ancora rilasciate nella disponibilità generale. Per informazioni su questa anteprima specifica, vedere informazioni sull'anteprima di Azure HDInsight su AKS. Per domande o suggerimenti sulle funzionalità, inviare una richiesta in AskHDInsight con i dettagli e seguire microsoft per altri aggiornamenti su community di Azure HDInsight.
HDInsight su AKS fornisce un set di configurazioni predefinite di Apache Flink per la maggior parte delle proprietà e alcune basate su profili di applicazione comuni. Tuttavia, nel caso in cui sia necessario modificare le proprietà di configurazione Flink per migliorare le prestazioni per determinate applicazioni con impostazioni di utilizzo dello stato, parallelismo o memoria, è possibile modificare la configurazione del processo Flink usando la sezione Processi Flink in HDInsight nel cluster del servizio Azure Kubernetes.
Vai nelle Impostazioni > processi Flink > e clicca su Aggiorna.
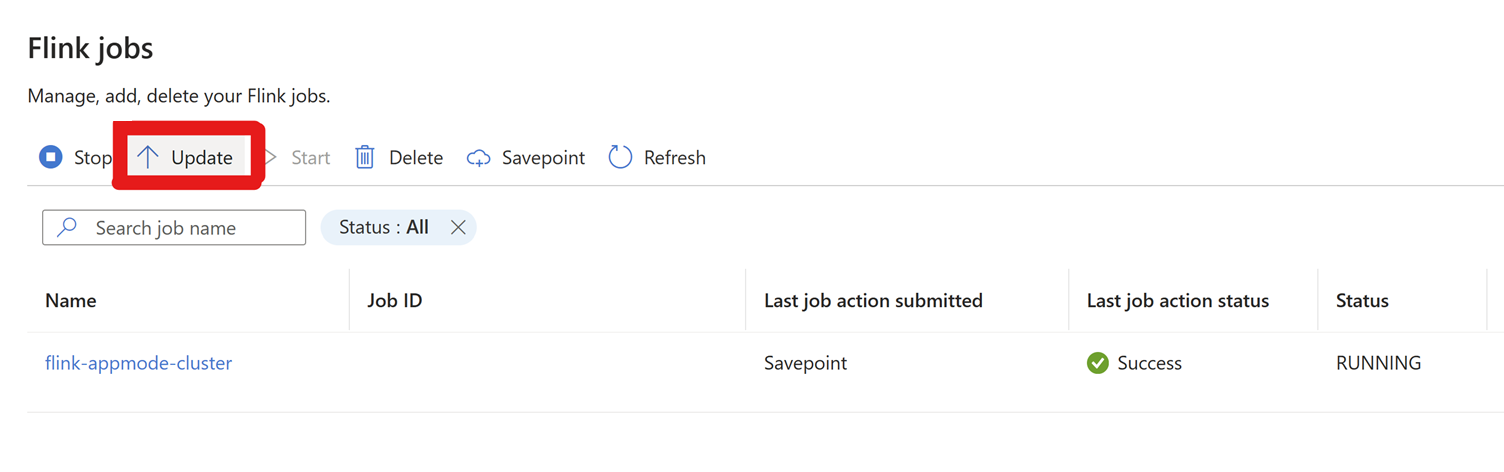
Fare clic su + Aggiungi una riga per modificare la configurazione.
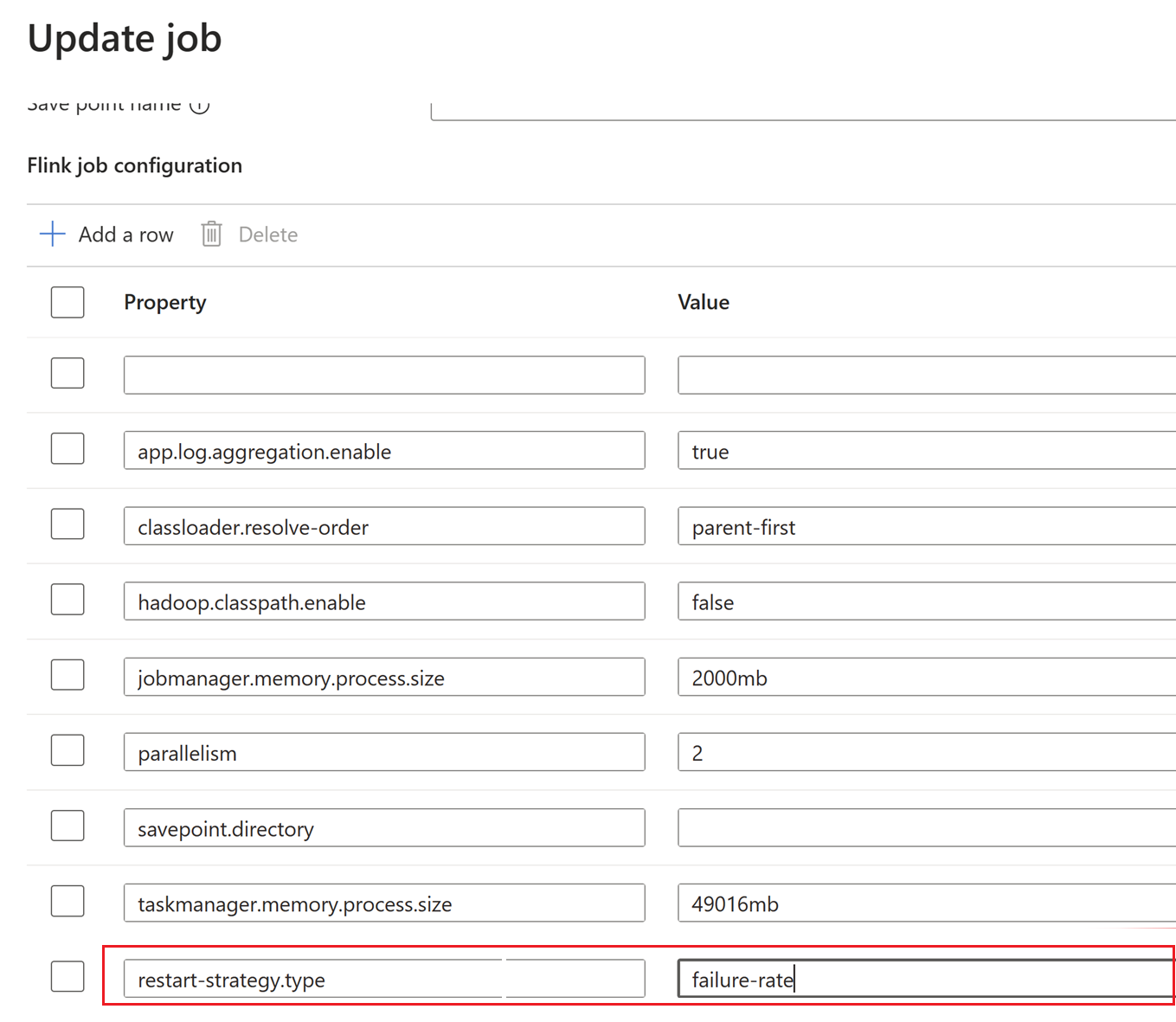
In questo caso l'intervallo di checkpoint viene modificato a livello di cluster .
Aggiornare le modifiche facendo clic su OK e quindi Salva.
Una volta salvate, le nuove configurazioni vengono aggiornate in pochi minuti (circa 5 minuti).
Configurazioni, che possono essere aggiornate usando le impostazioni di gestione della configurazione.
processMemory size:Le impostazioni predefinite per le dimensioni della memoria del processo o del gestore processi e gestione attività sono la memoria configurata dall'utente durante la creazione del cluster.
Questa dimensione può essere configurata usando la proprietà di configurazione seguente. Per modificare la memoria del processo di Task Manager, usare questa configurazione.
taskmanager.memory.process.size : <value>Esempio:
taskmanager.memory.process.size : 2000mbPer il responsabile delle attività
jobmanager.memory.process.size : <value>Nota
La memoria massima configurabile del processo è uguale alla memoria configurata per
jobmanager/taskmanager.


Intervallo checkpoint
L'intervallo di checkpoint determina la frequenza con cui Flink attiva un checkpoint. Definito in millisecondi e può essere impostato usando la proprietà di configurazione seguente
execution.checkpoint.interval: <value>
L'impostazione predefinita è 60.000 millisecondi (1 min), questo valore può essere modificato in base alle esigenze.
Backend di Stato
Il back-end di stato determina il modo in cui Flink gestisce e mantiene lo stato dell'applicazione. Influisce sulle modalità di archiviazione dei checkpoint. È possibile configurare il back-end di stato usando la proprietà seguente:
state.backend: <value>
Per impostazione predefinita, i cluster Apache Flink in HDInsight nel servizio Azure Kubernetes usano il database Rocks.
Percorso di archiviazione checkpoint
Per impostazione predefinita, i checkpoint permanenti sono consentiti archiviando i checkpoint nella risorsa di archiviazione abfs configurata dall'utente. Anche se il lavoro non riesce, poiché i checkpoint sono persistenti, può essere facilmente avviato con l'ultimo checkpoint.
state.checkpoints.dir: <path> Sostituire <path> con il percorso desiderato in cui sono archiviati i checkpoint.
Per impostazione predefinita, archiviato nell'account di archiviazione (ABFS), configurato dall'utente. Questo valore può essere modificato in qualsiasi percorso desiderato, purché i pod Flink possano accedervi.
Numero massimo di checkpoint simultanei
È possibile limitare il numero massimo di checkpoint simultanei impostando la proprietà seguente: checkpoint.max-concurrent-checkpoints: <value>
Sostituire <value> con il numero massimo desiderato di checkpoint simultanei. Ad esempio, 1 per consentire un solo checkpoint alla volta.
Numero massimo di checkpoint conservati
È possibile limitare il numero massimo di checkpoint da conservare impostando la proprietà seguente:
state.checkpoints.num-retained: <value> Sostituire <value> con il numero massimo desiderato. Per impostazione predefinita, vengono mantenuti al massimo cinque checkpoint.
Percorso di archiviazione del punto di salvataggio
I punti di salvataggio permanenti sono consentiti per impostazione predefinita archiviando i punti di salvataggio nella risorsa di archiviazione abfs (come configurato dall'utente). Se l'utente desidera interrompere e successivamente riavviare l'attività partendo da un punto di salvataggio specifico, può configurare questa posizione.
state.checkpoints.dir: <path> Sostituire <path> con il percorso desiderato in cui sono archiviati i punti di salvataggio.
Per impostazione predefinita, archiviato nell'account di archiviazione configurato dall'utente. (Supportiamo ABFS). Questo valore può essere modificato in qualsiasi percorso desiderato, purché i pod Flink possano accedervi.
Disponibilità elevata del gestore di processi
In HDInsight nel servizio Azure Kubernetes, Flink usa Kubernetes come back-end. Anche se il Job Manager fallisce a causa di problemi noti o sconosciuti, il pod viene riavviato nel giro di pochi secondi. Di conseguenza, anche se l'attività viene riavviata a causa di questo problema, viene comunque ripristinata dal checkpoint più recente .
Domande frequenti
Perché il processo si interrompe a metà? Anche se i job hanno esito negativo improvvisamente, se i checkpoint vengono eseguiti continuamente, il job viene riavviato per impostazione predefinita dall'ultimo checkpoint.
Cambiare la strategia nel mentre? Esistono casi d'uso in cui il processo deve essere modificato durante l'ambiente di produzione a causa di un bug a livello di processo. Durante tale periodo, l'utente può arrestare il processo, che prende automaticamente un punto di salvataggio e lo salva nella posizione di salvataggio.
Fare clic su
savepointe attendere il completamento disavepoint.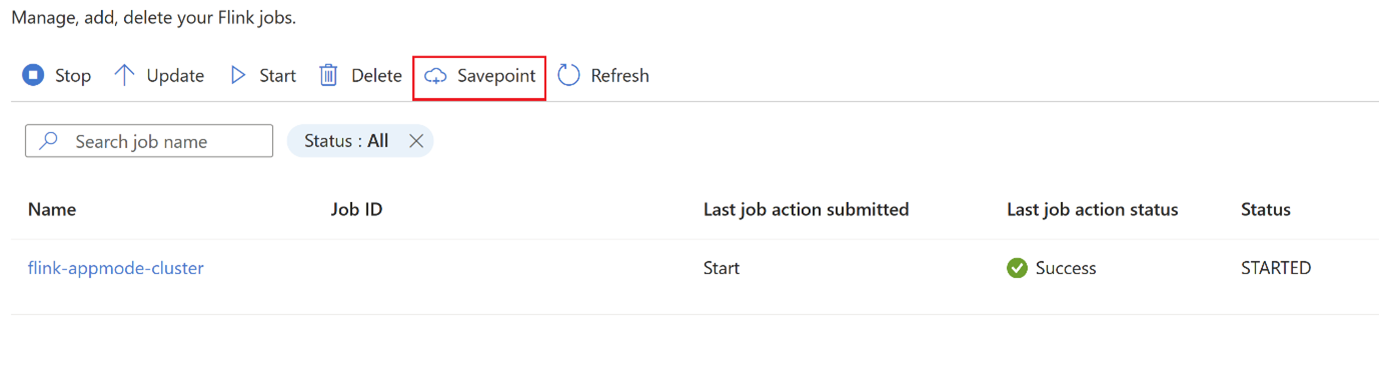
Al termine del punto di salvataggio, fare clic su Start e verrà visualizzata la scheda Start Job. Selezionare il nome del punto di salvataggio dall'elenco a discesa. Modificare eventuali configurazioni, se necessario. Fare clic su OK.
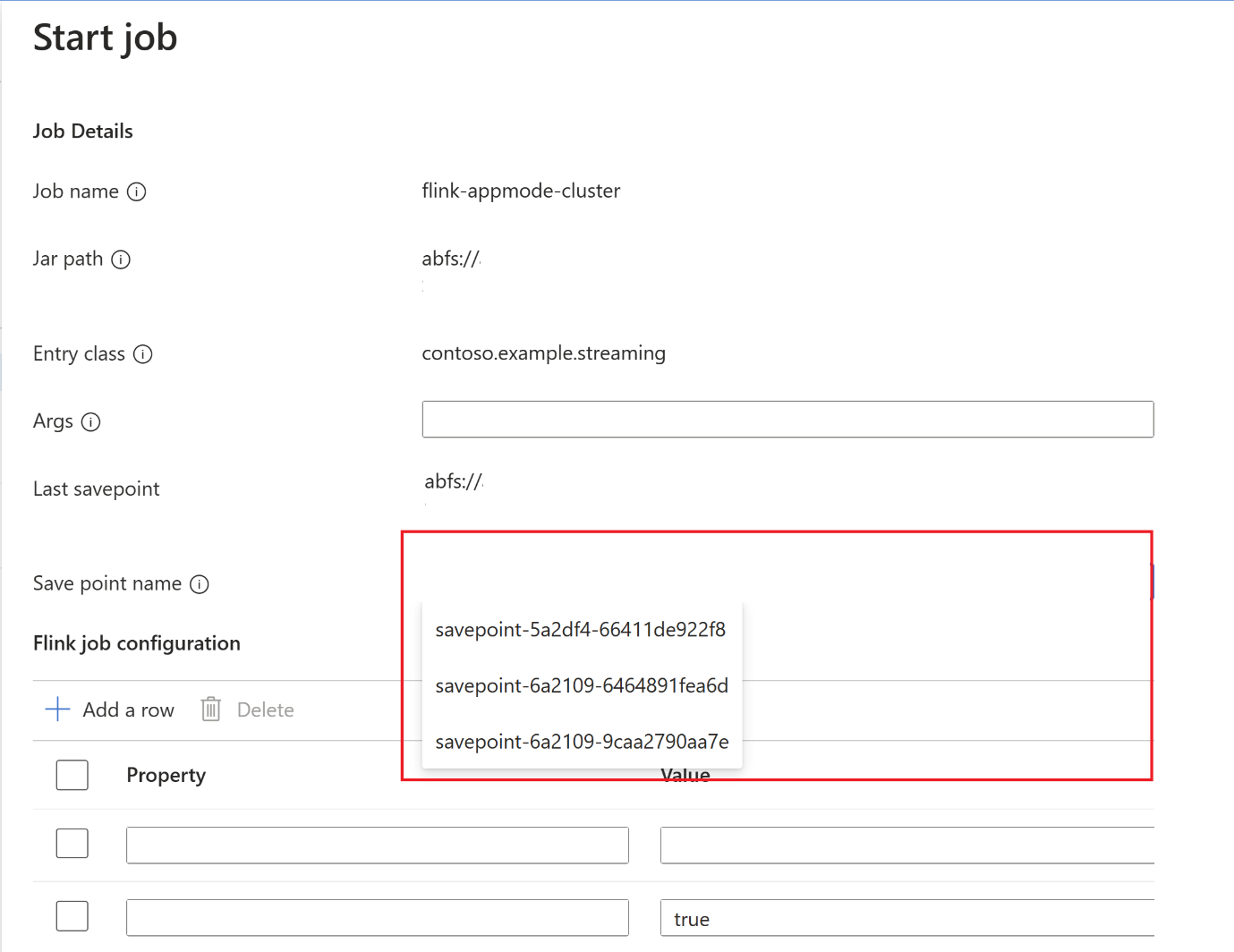


Poiché il savepoint è fornito nel job, Flink sa da dove iniziare a elaborare i dati.
Riferimento
- Configurazioni di Apache Flink
- Apache, Apache Kafka, Kafka, Apache Flink, Flink e i nomi dei progetti open source associati sono marchi della Apache Software Foundation (ASF).