Scrivere messaggi di evento in Azure Data Lake Storage Gen2 con l'API Apache Flink® DataStream
Importante
Azure HDInsight su Azure Kubernetes Service (AKS) è stato ritirato il 31 gennaio 2025. Scopri di più con questo annuncio.
È necessario eseguire la migrazione dei carichi di lavoro a Microsoft Fabric o a un prodotto Azure equivalente per evitare la chiusura brusca dei carichi di lavoro.
Importante
Questa funzionalità è attualmente in anteprima. Le condizioni supplementari per l'utilizzo per le anteprime di Microsoft Azure includono termini legali più validi applicabili alle funzionalità di Azure in versione beta, in anteprima o altrimenti non ancora rilasciate nella disponibilità generale. Per informazioni su questa anteprima specifica, vedere informazioni sull'anteprima di Azure HDInsight su AKS. Per domande o suggerimenti sulle funzionalità, inviare una richiesta in AskHDInsight con i dettagli e seguire Microsoft per altri aggiornamenti su Comunità di Azure HDInsight.
Apache Flink usa file system per usare e archiviare in modo permanente i dati, sia per i risultati delle applicazioni che per la tolleranza di errore e il ripristino. Questo articolo illustra come scrivere messaggi di evento in Azure Data Lake Storage Gen2 con l'API DataStream.
Prerequisiti
- cluster Apache Flink in HDInsight nel servizio Azure Kubernetes
-
Il cluster Apache Kafka su HDInsight
- È necessario assicurarsi che le impostazioni di rete siano state prese in considerazione come descritto in Uso di Apache Kafka in HDInsight. Assicurarsi che HDInsight su AKS e i cluster HDInsight si trovino nella stessa rete virtuale.
- Utilizzare MSI per accedere ad ADLS Gen2
- IntelliJ per lo sviluppo su una VM di Azure in HDInsight nella rete virtuale AKS
Connettore Apache Flink FileSystem
Questo connettore di file system offre le stesse garanzie per BATCH e STREAMING ed è progettato per fornire una semantica esattamente una volta per l'esecuzione di STREAMING. Per ulteriori informazioni, vedere Flink DataStream Filesystem.
Connettore Apache Kafka
Flink fornisce un connettore Apache Kafka per la lettura e la scrittura di dati nei topic Kafka con garanzie di esecuzione esattamente una volta. Per altre informazioni, vedere connettore Apache Kafka.
Compilare il progetto per Apache Flink
pom.xml su IntelliJ IDEA
<properties>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<flink.version>1.17.0</flink.version>
<java.version>1.8</java.version>
<scala.binary.version>2.12</scala.binary.version>
<kafka.version>3.2.0</kafka.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-streaming-java -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-clients -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-connector-files -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-files</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka</artifactId>
<version>${flink.version}</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.0.0</version>
<configuration>
<appendAssemblyId>false</appendAssemblyId>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
Programma per ADLS Gen2 Sink
abfsGen2.java
Nota
Sostituire Apache Kafka nel cluster HDInsight bootStrapServers con i propri broker per Kafka 3.2
package contoso.example;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.serialization.SimpleStringEncoder;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.configuration.MemorySize;
import org.apache.flink.connector.file.sink.FileSink;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
import org.apache.flink.core.fs.Path;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.sink.filesystem.rollingpolicies.DefaultRollingPolicy;
import java.time.Duration;
public class KafkaSinkToGen2 {
public static void main(String[] args) throws Exception {
// 1. get stream execution env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
Configuration flinkConfig = new Configuration();
flinkConfig.setString("classloader.resolve-order", "parent-first");
env.getConfig().setGlobalJobParameters(flinkConfig);
// 2. read kafka message as stream input, update your broker ip's
String brokers = "<update-broker-ip>:9092,<update-broker-ip>:9092,<update-broker-ip>:9092";
KafkaSource<String> source = KafkaSource.<String>builder()
.setBootstrapServers(brokers)
.setTopics("click_events")
.setGroupId("my-group")
.setStartingOffsets(OffsetsInitializer.earliest())
.setValueOnlyDeserializer(new SimpleStringSchema())
.build();
DataStream<String> stream = env.fromSource(source, WatermarkStrategy.noWatermarks(), "Kafka Source");
stream.print();
// 3. sink to gen2, update container name and storage path
String outputPath = "abfs://<container-name>@<storage-path>.dfs.core.windows.net/flink/data/click_events";
final FileSink<String> sink = FileSink
.forRowFormat(new Path(outputPath), new SimpleStringEncoder<String>("UTF-8"))
.withRollingPolicy(
DefaultRollingPolicy.builder()
.withRolloverInterval(Duration.ofMinutes(2))
.withInactivityInterval(Duration.ofMinutes(3))
.withMaxPartSize(MemorySize.ofMebiBytes(5))
.build())
.build();
stream.sinkTo(sink);
// 4. run stream
env.execute("Kafka Sink To Gen2");
}
}
Impacchetta il jar e invialo ad Apache Flink.
Caricare il file JAR in ABFS.
Trasmettere le informazioni del job jar nella creazione del cluster
AppMode.
Nota
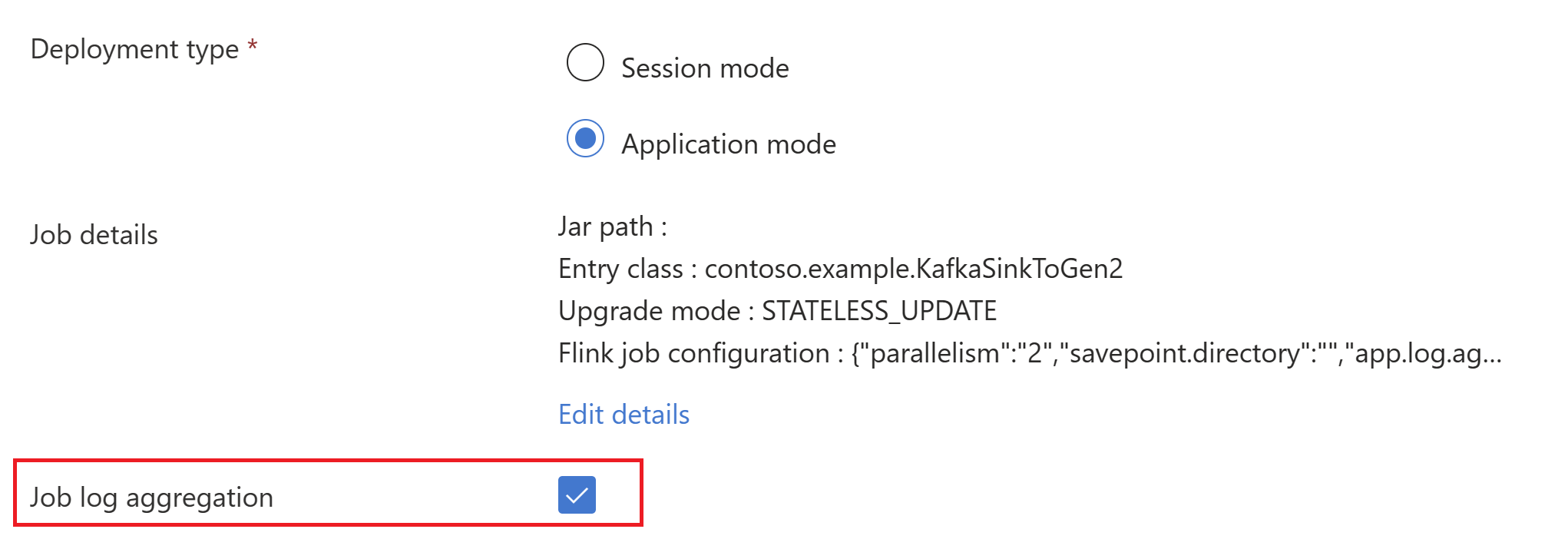
Assicurarsi di aggiungere il classloader.resolve-order come 'parent-first' e l'hadoop.classpath.enable come
trueSelezionare Aggregazione log processi per inviare i log dei processi nell'account di archiviazione.
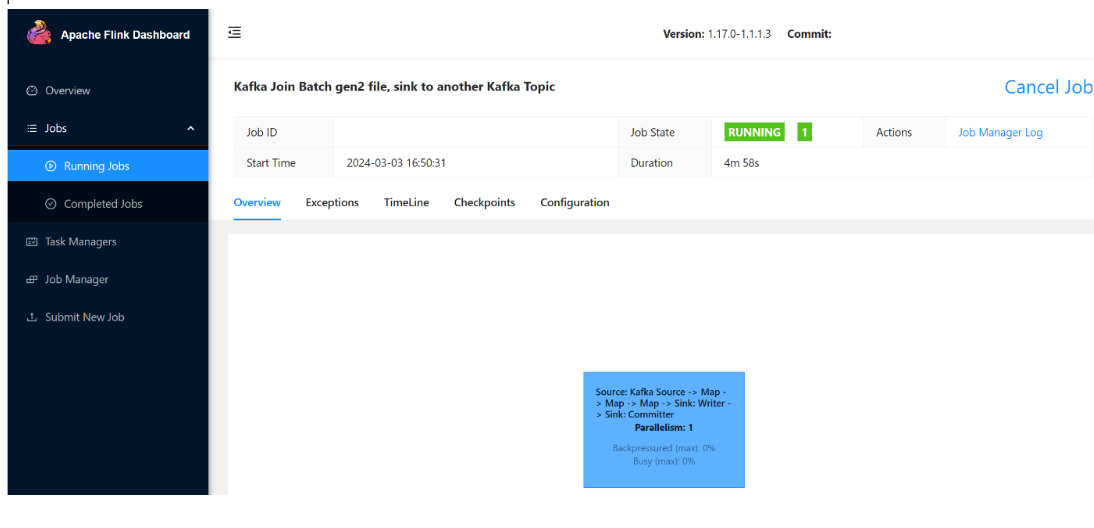
È possibile visualizzare il processo in esecuzione.




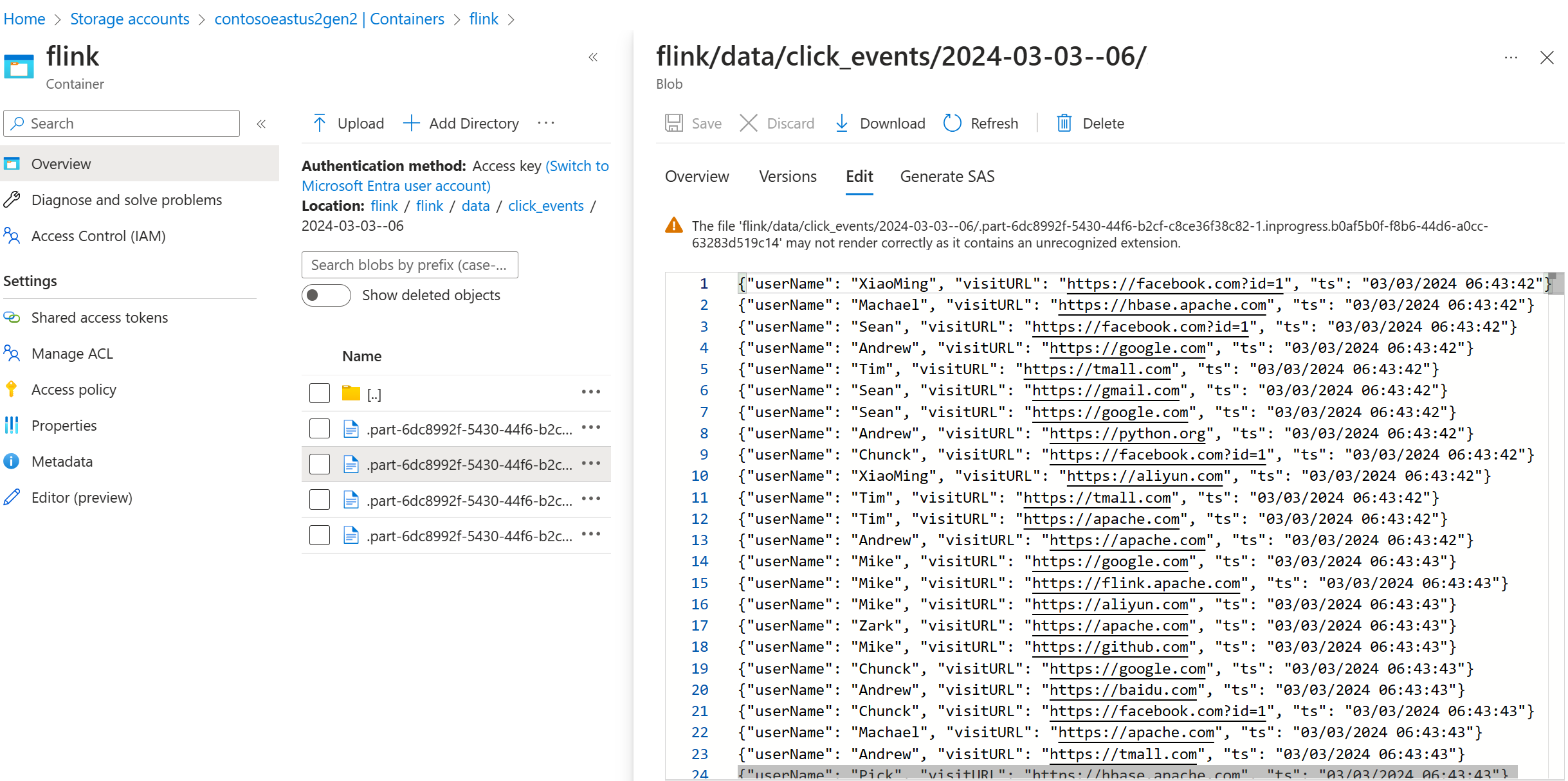
Convalidare i dati di streaming in ADLS Gen2
Stiamo vedendo il flusso di click_events in ADLS Gen2.

È possibile specificare un criterio in sequenza che esegue il rollback del file della parte in corso in una delle tre condizioni seguenti:
.withRollingPolicy(
DefaultRollingPolicy.builder()
.withRolloverInterval(Duration.ofMinutes(5))
.withInactivityInterval(Duration.ofMinutes(3))
.withMaxPartSize(MemorySize.ofMebiBytes(5))
.build())
Riferimento
- connettore Apache Kafka
- Flink DataStream Filesystem
- sito Web Apache Flink
- Apache, Apache Kafka, Kafka, Apache Flink, Flink e i nomi dei progetti open source associati sono marchi del Apache Software Foundation (ASF).