Risolvere i problemi di asimmetria dei dati in Azure Data Lake Analytics usando Strumenti Azure Data Lake per Visual Studio
Importante
Azure Data Lake Analytics ritirato il 29 febbraio 2024. Per altre informazioni , vedere questo annuncio.
Per l'analisi dei dati, l'organizzazione può usare Azure Synapse Analytics o Microsoft Fabric.
Informazioni sull'asimmetria dei dati
In poche parole, un'asimmetria dei dati si verifica quando un valore è rappresentato in modo eccessivo. Si supponga di aver assegnato 50 esaminatori fiscali per controllare le dichiarazioni fiscali, un esaminatore per ogni stato degli Stati Uniti. L'esaminatore del Wyoming, perché la popolazione c'è piccola, ha poco da fare. In California, invece, l'esaminatore è molto indaffarato a causa dell'entità della popolazione dello stato.

In questo scenario, i dati sono distribuiti in modo non uniforme tra tutti gli esaminatori di imposta, il che significa che alcuni esaminatori lavorano di più rispetto ad altri. Nell'attività personale, non di rado si verificano situazioni simili allo scenario degli esaminatori di imposta qui presentato. In termini più tecnici, un vertice ottiene molti più dati rispetto agli altri elementi, una situazione che costringe il vertice a lavorare di più rispetto agli altri e che, di conseguenza, rallenta l'intero processo. Ancor peggio, il processo potrebbe avere esito negativo in quanto i vertici potrebbero presentare, ad esempio, un limite di runtime di 5 ore e un limite della memoria pari a 6 GB.
Risoluzione dei problemi di asimmetria dei dati
Strumenti Azure Data Lake per Visual Studio e Visual Studio Code consentono di rilevare se il processo presenta un problema di asimmetria dei dati.
- Installare Strumenti Azure Data Lake per Visual Studio
- Installare il codice Strumenti Azure Data Lake per Visual Studio
Se si verifica un problema, è possibile risolverlo tramite le soluzioni presentate in questa sezione.
Soluzione 1. Migliorare il partizionamento delle tabelle
Opzione 1. Filtrare in anticipo un valore chiave differente
Se non influisce sulla logica di business, è possibile filtrare in anticipo i valori con frequenza più elevata. Se ad esempio sono presenti molti 000-000-000-000 nel GUID di colonna, potrebbe non essere necessario aggregare tale valore. Prima di eseguire l'aggregazione, è possibile scrivere "WHERE GUID != "000-000-000"" per filtrare il valore ad alta frequenza.
Opzione 2. Selezionare una chiave di partizione o distribuzione differente
Nell'esempio precedente, se si vuole controllare solo il carico di lavoro di controllo delle imposte in tutto il paese o nell'area geografica, è possibile migliorare la distribuzione dei dati selezionando il numero ID come chiave. La scelta di una chiave di partizione o distribuzione differente consente talvolta di distribuire i dati in modo più uniforme, ma è necessario verificare che la scelta non abbia impatto sulla logica di business. Ad esempio, per calcolare l'importo dell'imposta per ogni stato, è consigliabile specificare Stato come chiave di partizione. Se il problema persiste, provare con l'opzione 3.
Opzione 3. Aggiungere più chiavi di partizione o distribuzione
Invece di usare solo Stato come chiave di partizione, è possibile impiegare più di una chiave per il partizionamento. Si consideri ad esempio l'aggiunta di codice POSTALE come un'altra chiave di partizione per ridurre le dimensioni delle partizioni dei dati e distribuire i dati in modo più uniforme.
Opzione 4. Usare la distribuzione round robin
Se non è possibile trovare una chiave appropriata per la partizione e la distribuzione, è possibile provare a usare la distribuzione round robin. La distribuzione round robin considera tutte le righe in modo uguale e le inserisce in modo casuale nei bucket corrispondenti. I dati vengono distribuiti uniformemente ma si perdono le informazioni sulla località, uno svantaggio che riduce anche le prestazioni del processo rispetto ad alcune operazioni. Inoltre, se si esegue l'aggregazione per la chiave asimmetrica, il problema di asimmetria dei dati persisterà. Per altre informazioni sulla distribuzione round robin, vedere la sezione Distribuzioni di tabelle U-SQL in CREATE TABLE (U-SQL): Creazione di una tabella con schema.
Soluzione 2. Migliorare il piano di query
Opzione 1. Usare l'istruzione CREATE STATISTICS
U-SQL fornisce l'istruzione CREATE STATISTICS nelle tabelle. Questa istruzione fornisce altre informazioni a Query Optimizer sulle caratteristiche dei dati (ad esempio, distribuzione dei valori) archiviate in una tabella. Per la maggior parte delle query, il Query Optimizer genera già le statistiche necessarie per un piano di query di elevata qualità. In alcuni casi, potrebbe essere necessario migliorare le prestazioni delle query creando più statistiche con CREATE STATISTICS o modificando la progettazione delle query. Per altre informazioni, vedere la pagina CREATE STATISTICS (U-SQL) (CREATE STATISTICS (U-SQL)).
Esempio di codice:
CREATE STATISTICS IF NOT EXISTS stats_SampleTable_date ON SampleDB.dbo.SampleTable(date) WITH FULLSCAN;
Nota
Le informazioni statistiche non vengono aggiornate in automatico. Se si aggiornano i dati in una tabella senza generare nuovamente le statistiche, le prestazioni delle query potrebbero risultare ridotte.
Opzione 2. Utilizzo di SKEWFACTOR
Se si desidera sommare le imposte per ogni stato, è necessario usare lo stato GROUP BY, un approccio che non evita il problema dell'asimmetria dei dati. Tuttavia, è possibile inserire un suggerimento dati nella query per identificare le asimmetrie dei dati nelle chiavi, in modo da preparare un piano di esecuzione personale.
In genere, è possibile impostare il parametro come 0,5 e 1, con 0,5 significato non molto asimmetria e uno che significa un'asimmetria pesante. Dal momento che il suggerimento ha un impatto sull'ottimizzazione del piano di esecuzione per l'istruzione corrente e per tutte quelle successive, è quindi necessario assicurarsi di aggiungerlo prima della potenziale aggregazione a livello della chiave con asimmetria.
SKEWFACTOR (columns) = x
Indica che le colonne specificate hanno un fattore di asimmetria x da 0 (nessuna asimmetria) a 1 (asimmetria pesante).
Esempio di codice:
//Add a SKEWFACTOR hint.
@Impressions =
SELECT * FROM
searchDM.SML.PageView(@start, @end) AS PageView
OPTION(SKEWFACTOR(Query)=0.5)
;
//Query 1 for key: Query, ClientId
@Sessions =
SELECT
ClientId,
Query,
SUM(PageClicks) AS Clicks
FROM
@Impressions
GROUP BY
Query, ClientId
;
//Query 2 for Key: Query
@Display =
SELECT * FROM @Sessions
INNER JOIN @Campaigns
ON @Sessions.Query == @Campaigns.Query
;
Opzione 3: Usare ROWCOUNT
Oltre a SKEWFACTOR, per casi specifici di unioni di chiavi asimmetriche, se si sa che gli altri set di righe unite sono ridotti, è possibile indicarlo all'Optimizer tramite l'aggiunta di un suggerimento ROWCOUNT nell'istruzione U-SQL prima di JOIN. In questo modo, l'Optimizer può scegliere una strategia di aggregazione della trasmissione per migliorare le prestazioni. Tenere presente che ROWCOUNT non risolve il problema di asimmetria dei dati, ma può offrire assistenza aggiuntiva.
OPTION(ROWCOUNT = n)
Identificare un set di righe di piccole dimensioni prima di JOIN fornendo un conteggio delle righe integer stimato.
Esempio di codice:
//Unstructured (24-hour daily log impressions)
@Huge = EXTRACT ClientId int, ...
FROM @"wasb://ads@wcentralus/2015/10/30/{*}.nif"
;
//Small subset (that is, ForgetMe opt out)
@Small = SELECT * FROM @Huge
WHERE Bing.ForgetMe(x,y,z)
OPTION(ROWCOUNT=500)
;
//Result (not enough information to determine simple broadcast JOIN)
@Remove = SELECT * FROM Bing.Sessions
INNER JOIN @Small ON Sessions.Client == @Small.Client
;
Soluzione 3. Migliorare il riduttore e il combinatore definiti dall'utente
A volte per gestire una logica di processo complessa viene usato un operatore definito dall'utente; in alcuni casi, un riduttore e un combinatore ben scritti possono ridurre il problema dell'asimmetria dei dati.
Opzione 1. Usare un riduttore ricorsivo se possibile
Per impostazione predefinita, un riduttore definito dall'utente viene eseguito in modalità non ricorsiva, il che significa che il lavoro di riduzione per una chiave viene distribuito in un singolo vertice. In caso di asimmetria dei dati, i set di dati di grandi dimensioni potrebbero essere elaborati in un unico vertice e richiedere un tempo di esecuzione lungo.
Per migliorare le prestazioni, è possibile aggiungere un attributo nel codice per definire l'esecuzione del riduttore in modalità ricorsiva. A questo punto, i set di dati di grandi dimensioni possono essere distribuiti su più vertici ed eseguiti in parallelo, al fine di velocizzare il processo.
Per modificare un riduttore non ricorsivo in ricorsivo, è necessario assicurarsi che l'algoritmo sia associativo. Ad esempio, la somma è associativa e la median non è. È necessario anche verificare che l'input e output per il riduttore rispettino lo stesso schema.
Attributo del riduttore ricorsivo:
[SqlUserDefinedReducer(IsRecursive = true)]
Esempio di codice:
[SqlUserDefinedReducer(IsRecursive = true)]
public class TopNReducer : IReducer
{
public override IEnumerable<IRow>
Reduce(IRowset input, IUpdatableRow output)
{
//Your reducer code goes here.
}
}
Opzione 2. Usare la modalità di combinazione a livello di riga, se possibile
Analogamente al suggerimento ROWCOUNT per specifici casi di unioni di chiavi asimmetriche, la modalità del combinatore tenta di distribuire set di valori di chiavi asimmetriche su più vertici, in modo da ottenere un'esecuzione simultanea. La modalità combinatore non è in grado di risolvere i problemi di asimmetria dei dati, ma può offrire un aiuto aggiuntivo per set di valori di chiave asimmetrica di grandi dimensioni.
Per impostazione predefinita, la modalità combinatore è Completa, il che significa che il set di righe sinistro e il set di righe destro non possono essere separati. L'impostazione della modalità su Left/Right/Inner consente l'unione a livello di riga. Il sistema separa il set di righe corrispondente e le distribuisce in più vertici che vengono eseguiti in parallelo. Prima di configurare la modalità del combinatore, tuttavia, assicurarsi che sia possibile separare i set di righe corrispondente.
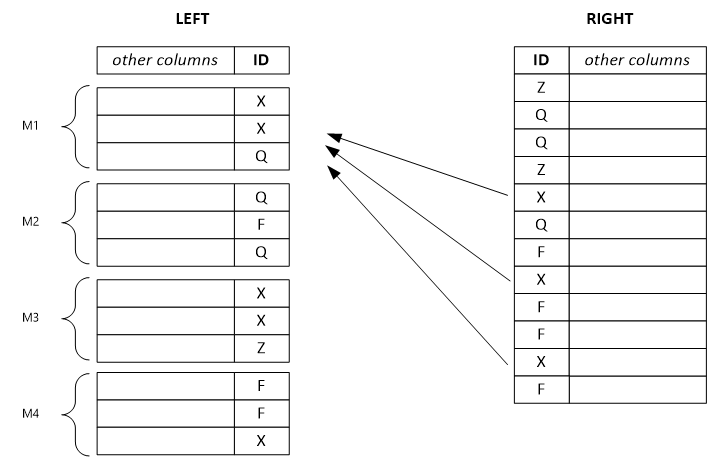
L'esempio seguente illustra un set di righe sinistro separato. Ogni riga di output dipende da una singola riga di input a sinistra e potenzialmente da tutte le righe a destra con lo stesso valore chiave. Se si imposta la modalità del combinatore su Left, il sistema separa il grande set di righe a sinistra in set più piccoli e li assegna a più vertici.
Nota
Se si imposta la modalità del combinatore errata, la combinazione è meno efficiente e i risultati potrebbero essere errati.
Attributi della modalità del combinatore:
SqlUserDefinedCombiner(Mode=CombinerMode.Full): ogni riga di output dipende potenzialmente da tutte le righe di input da sinistra e destra con lo stesso valore di chiave.
SqlUserDefinedCombiner(Mode=CombinerMode.Left): ogni riga di output dipende da una singola riga di input a sinistra e potenzialmente da tutte le righe a destra con lo stesso valore chiave.
SqlUserDefinedCombiner(Mode=CombinerMode.Right): ogni riga di output dipende da una singola riga di input a destra e potenzialmente da tutte le righe a sinistra con lo stesso valore chiave.
SqlUserDefinedCombiner(Mode=CombinerMode.Inner): ogni riga di output dipende da una sola riga di input a sinistra e a destra con lo stesso valore.
Esempio di codice:
[SqlUserDefinedCombiner(Mode = CombinerMode.Right)]
public class WatsonDedupCombiner : ICombiner
{
public override IEnumerable<IRow>
Combine(IRowset left, IRowset right, IUpdatableRow output)
{
//Your combiner code goes here.
}
}