Eseguire la migrazione da Azure Batch per intelligenza artificiale al servizio Azure Machine Learning
Il servizio Azure Batch per intelligenza artificiale verrà ritirato nel mese di marzo. Le funzionalità di Batch per intelligenza artificiale per il training e l'assegnazione dei punteggi su larga scala sono ora disponibili nel servizio Azure Machine Learning, diventato disponibile a livello generale il 4 dicembre 2018.
Oltre a molte altre funzionalità di apprendimento automatico, il servizio Azure Machine Learning include una destinazione di calcolo gestita e basata sul cloud per il training, la distribuzione e l'assegnazione dei punteggi ai modelli di Machine Learning. Questa destinazione di calcolo viene chiamata ambiente di calcolo di Azure Machine Learning. Avviare la migrazione e usarla subito. È possibile interagire con il servizio Azure Machine Learning tramite gli SDK di Python, l'interfaccia della riga di comando e il portale di Azure.
L'aggiornamento dal servizio Batch per intelligenza artificiale in anteprima al servizio Azure Machine Learning nella versione di disponibilità generale offre un'esperienza migliore attraverso concetti più facili da usare come gli oggetti Estimator e gli archivi dati. Garantisce anche contratti di servizio per Azure con disponibilità generale e assistenza clienti.
Il servizio Azure Machine Learning introduce anche nuove funzionalità come l'apprendimento automatico automatizzato, l'ottimizzazione degli iperparametri e le pipeline di Machine Learning, che sono utili nella maggior parte dei carichi di lavoro di intelligenza artificiale su larga scala. La possibilità di distribuire un modello con training senza ricorrere a un servizio separato consente di completare il ciclo di data science dalla preparazione dei dati (con l'SDK di preparazione dei dati) fino all'operazionalizzazione e al monitoraggio dei modelli.
Avvio della migrazione
Per evitare interruzioni delle applicazioni e trarre vantaggio dalle funzionalità più recenti, eseguire i passaggi di seguito prima del 31 marzo 2019:
Creare un'area di lavoro del servizio Azure Machine Learning e iniziare subito:
Installare Azure Machine Learning SDK e Data Prep SDK.
Configurare un ambiente di calcolo di Azure Machine Learning per il training del modello.
Aggiornare gli script per l'utilizzo dell'ambiente di calcolo di Azure Machine Learning. Le sezioni seguenti illustrano come codificare il codice comune usato per le mappe di batch per intelligenza artificiale per Azure Machine Learning.
Creare aree di lavoro
Il concetto di inizializzazione di un'area di lavoro usando il file configuration.json in Azure Batch per intelligenza artificiale corrisponde all'uso di un file di configurazione nel servizio Azure Machine Learning.
Per Batch per intelligenza artificiale l'operazione è la seguente:
sys.path.append('../../..')
import utilities as utils
cfg = utils.config.Configuration('../../configuration.json')
client = utils.config.create_batchai_client(cfg)
utils.config.create_resource_group(cfg)
_ = client.workspaces.create(cfg.resource_group, cfg.workspace, cfg.location).result()
Per il servizio Azure Machine Learning provare quanto segue:
from azureml.core.workspace import Workspace
ws = Workspace.from_config()
print('Workspace name: ' + ws.name,
'Azure region: ' + ws.location,
'Subscription id: ' + ws.subscription_id,
'Resource group: ' + ws.resource_group, sep = '\n')
Inoltre, è anche possibile creare un'area di lavoro specificando direttamente i parametri di configurazione, ad esempio:
from azureml.core import Workspace
# Create the workspace using the specified parameters
ws = Workspace.create(name = workspace_name,
subscription_id = subscription_id,
resource_group = resource_group,
location = workspace_region,
create_resource_group = True,
exist_ok = True)
ws.get_details()
# write the details of the workspace to a configuration file to the notebook library
ws.write_config()
Altre informazioni sulla classe dell'area di lavoro di Azure Machine Learning sono disponibili nella documentazione di riferimento dell'SDK.
Creazione di cluster di elaborazione
Azure Machine Learning supporta più destinazioni di calcolo, alcune delle quali vengono gestite dal servizio, mentre altre possono essere collegate all'area di lavoro, ad esempio un cluster HDInsight o una macchina virtuale remota. Per altre informazioni, vedere e varie destinazioni di calcolo. Il concetto di creazione di un cluster di elaborazione in Azure Batch per intelligenza artificiale corrisponde alla creazione di un cluster AmlCompute nel servizio Azure Machine Learning. La creazione di Amlcompute richiede una configurazione di calcolo simile al modo in cui vengono passati i parametri in Azure Batch per intelligenza artificiale. Un aspetto da sottolineare è che il ridimensionamento automatico è attivato per impostazione predefinita nei cluster AmlCompute, mentre è disattivato per impostazione predefinita in Azure Batch per intelligenza artificiale.
Per Batch per intelligenza artificiale l'operazione è la seguente:
nodes_count = 2
cluster_name = 'nc6'
parameters = models.ClusterCreateParameters(
vm_size='STANDARD_NC6',
scale_settings=models.ScaleSettings(
manual=models.ManualScaleSettings(target_node_count=nodes_count)
),
user_account_settings=models.UserAccountSettings(
admin_user_name=cfg.admin,
admin_user_password=cfg.admin_password or None,
admin_user_ssh_public_key=cfg.admin_ssh_key or None,
)
)
_ = client.clusters.create(cfg.resource_group, cfg.workspace, cluster_name, parameters).result()
Per il servizio Azure Machine Learning provare quanto segue:
from azureml.core.compute import ComputeTarget, AmlCompute
from azureml.core.compute_target import ComputeTargetException
# Choose a name for your CPU cluster
gpu_cluster_name = "nc6"
# Verify that cluster does not exist already
try:
gpu_cluster = ComputeTarget(workspace=ws, name=gpu_cluster_name)
print('Found existing cluster, use it.')
except ComputeTargetException:
compute_config = AmlCompute.provisioning_configuration(vm_size='STANDARD_NC6',
vm_priority='lowpriority',
min_nodes=1,
max_nodes=2,
idle_seconds_before_scaledown='300',
vnet_resourcegroup_name='<my-resource-group>',
vnet_name='<my-vnet-name>',
subnet_name='<my-subnet-name>')
gpu_cluster = ComputeTarget.create(ws, gpu_cluster_name, compute_config)
gpu_cluster.wait_for_completion(show_output=True)
Altre informazioni sulla classe AMLCompute sono disponibili nella documentazione di riferimento dell'SDK. Si noti che nella configurazione precedente, solo vm_size e max_nodes sono obbligatori, mentre il resto delle proprietà come VNets sono solo per la configurazione avanzata del cluster.
Monitoraggio dello stato del cluster
Questa operazione è più semplice nel servizio Azure Machine Learning, come illustrato di seguito.
Per Batch per intelligenza artificiale l'operazione è la seguente:
cluster = client.clusters.get(cfg.resource_group, cfg.workspace, cluster_name)
utils.cluster.print_cluster_status(cluster)
Per il servizio Azure Machine Learning provare quanto segue:
gpu_cluster.get_status().serialize()
Ottenere un riferimento a un account di archiviazione
Il concetto di risorsa di archiviazione dati come un BLOB viene semplificato nel servizio Azure Machine Learning con l'oggetto Archivio dati. Per impostazione predefinita, un'area di lavoro del servizio Azure Machine Learning crea un account di archiviazione, ma è anche possibile associare la propria risorsa di archiviazione come parte della creazione dell'area di lavoro.
Per Batch per intelligenza artificiale l'operazione è la seguente:
azure_blob_container_name = 'batchaisample'
blob_service = BlockBlobService(cfg.storage_account_name, cfg.storage_account_key)
blob_service.create_container(azure_blob_container_name, fail_on_exist=False)
Per il servizio Azure Machine Learning provare quanto segue:
ds = ws.get_default_datastore()
print(ds.datastore_type, ds.account_name, ds.container_name)
Altre informazioni sulla registrazione di altri account di archiviazione o su come ottenere un riferimento a un altro archivio dati registrato sono disponibili nella documentazione del servizio Azure Machine Learning.
Download e caricamento dei dati
Con entrambi i servizi, è possibile caricare facilmente i dati nell'account di archiviazione usando il riferimento dell'archivio dati precedente. In Azure Batch per intelligenza artificiale viene distribuito anche lo script di training come parte della condivisione del file, sebbene si noterà come sia possibile specificarlo come parte della configurazione del processo nel caso del servizio Azure Machine Learning.
Per Batch per intelligenza artificiale l'operazione è la seguente:
mnist_dataset_directory = 'mnist_dataset'
utils.dataset.download_and_upload_mnist_dataset_to_blob(
blob_service, azure_blob_container_name, mnist_dataset_directory)
script_directory = 'tensorflow_samples'
script_to_deploy = 'mnist_replica.py'
blob_service.create_blob_from_path(azure_blob_container_name,
script_directory + '/' + script_to_deploy,
script_to_deploy)
Per il servizio Azure Machine Learning provare quanto segue:
import os
import urllib
os.makedirs('./data', exist_ok=True)
download_url = 'https://s3.amazonaws.com/img-datasets/mnist.npz'
urllib.request.urlretrieve(download_url, filename='data/mnist.npz')
ds.upload(src_dir='data', target_path='mnist_dataset', overwrite=True, show_progress=True)
path_on_datastore = ' mnist_dataset/mnist.npz' ds_data = ds.path(path_on_datastore) print(ds_data)
Creazione di esperimenti
Come indicato in precedenza, il servizio Azure Machine Learning ha un concetto di esperimento simile ad Azure Batch per intelligenza artificiale. Ogni esperimento può quindi avere singole esecuzioni, in modo analogo a come avviene con i processi in Azure Batch per intelligenza artificiale. Il servizio Azure Machine Learning consente anche di avere una gerarchia in cui per ogni esecuzione padre sono presenti le singole esecuzioni figlio.
Per Batch per intelligenza artificiale l'operazione è la seguente:
experiment_name = 'tensorflow_experiment'
experiment = client.experiments.create(cfg.resource_group, cfg.workspace, experiment_name).result()
Per il servizio Azure Machine Learning provare quanto segue:
from azureml.core import Experiment
experiment_name = 'tensorflow_experiment'
experiment = Experiment(ws, name=experiment_name)
Inviare i processi
Dopo aver creato un esperimento, sono disponibili vari modi diversi per inviare un'esecuzione. In questo esempio si proverà a creare un modello di Deep Learning usando TensorFlow e a tale scopo verrà usato un oggetto Estimator del servizio Azure Machine Learning. Un oggetto Estimator è semplicemente una funzione wrapper nella configurazione di esecuzione sottostante, che rende più semplice inviare le esecuzioni ed è attualmente supportato solo per Pytorch e TensorFlow. Tramite il concetto di archivio dati, si vedrà anche come diventa semplice specificare i percorsi di montaggio
Per Batch per intelligenza artificiale l'operazione è la seguente:
azure_file_share = 'afs'
azure_blob = 'bfs'
args_fmt = '--job_name={0} --num_gpus=1 --train_steps 10000 --checkpoint_dir=$AZ_BATCHAI_OUTPUT_MODEL --log_dir=$AZ_BATCHAI_OUTPUT_TENSORBOARD --data_dir=$AZ_BATCHAI_INPUT_DATASET --ps_hosts=$AZ_BATCHAI_PS_HOSTS --worker_hosts=$AZ_BATCHAI_WORKER_HOSTS --task_index=$AZ_BATCHAI_TASK_INDEX'
parameters = models.JobCreateParameters(
cluster=models.ResourceId(id=cluster.id),
node_count=2,
input_directories=[
models.InputDirectory(
id='SCRIPT',
path='$AZ_BATCHAI_JOB_MOUNT_ROOT/{0}/{1}'.format(azure_blob, script_directory)),
models.InputDirectory(
id='DATASET',
path='$AZ_BATCHAI_JOB_MOUNT_ROOT/{0}/{1}'.format(azure_blob, mnist_dataset_directory))],
std_out_err_path_prefix='$AZ_BATCHAI_JOB_MOUNT_ROOT/{0}'.format(azure_file_share),
output_directories=[
models.OutputDirectory(
id='MODEL',
path_prefix='$AZ_BATCHAI_JOB_MOUNT_ROOT/{0}'.format(azure_file_share),
path_suffix='Models'),
models.OutputDirectory(
id='TENSORBOARD',
path_prefix='$AZ_BATCHAI_JOB_MOUNT_ROOT/{0}'.format(azure_file_share),
path_suffix='Logs')
],
mount_volumes=models.MountVolumes(
azure_file_shares=[
models.AzureFileShareReference(
account_name=cfg.storage_account_name,
credentials=models.AzureStorageCredentialsInfo(
account_key=cfg.storage_account_key),
azure_file_url='https://{0}.file.core.windows.net/{1}'.format(
cfg.storage_account_name, azure_file_share_name),
relative_mount_path=azure_file_share)
],
azure_blob_file_systems=[
models.AzureBlobFileSystemReference(
account_name=cfg.storage_account_name,
credentials=models.AzureStorageCredentialsInfo(
account_key=cfg.storage_account_key),
container_name=azure_blob_container_name,
relative_mount_path=azure_blob)
]
),
container_settings=models.ContainerSettings(
image_source_registry=models.ImageSourceRegistry(image='tensorflow/tensorflow:1.8.0-gpu')),
tensor_flow_settings=models.TensorFlowSettings(
parameter_server_count=1,
worker_count=nodes_count,
python_script_file_path='$AZ_BATCHAI_INPUT_SCRIPT/'+ script_to_deploy,
master_command_line_args=args_fmt.format('worker'),
worker_command_line_args=args_fmt.format('worker'),
parameter_server_command_line_args=args_fmt.format('ps'),
)
)
L'invio del processo stesso in Azure Batch per intelligenza artificiale avviene tramite la funzione di creazione.
job_name = datetime.utcnow().strftime('tf_%m_%d_%Y_%H%M%S')
job = client.jobs.create(cfg.resource_group, cfg.workspace, experiment_name, job_name, parameters).result()
print('Created Job {0} in Experiment {1}'.format(job.name, experiment.name))
Le informazioni complete per questo frammento di codice di training (incluso il file mnist_replica.py caricato nella condivisione del file precedente) sono disponibili nel repository github del notebook di esempio di Azure Batch per intelligenza artificiale.
Per il servizio Azure Machine Learning provare quanto segue:
from azureml.train.dnn import TensorFlow
script_params={
'--num_gpus': 1,
'--train_steps': 500,
'--input_data': ds_data.as_mount()
}
estimator = TensorFlow(source_directory=project_folder,
compute_target=gpu_cluster,
script_params=script_params,
entry_script='tf_mnist_replica.py',
node_count=2,
worker_count=2,
parameter_server_count=1,
distributed_backend='ps',
use_gpu=True)
Le informazioni complete per questo frammento di codice di training (incluso il file tf_mnist_replica.py) sono disponibili nel repository github del notebook di esempio del servizio Azure Machine Learning. L'archivio dati stesso può essere montato nei singoli nodi oppure i dati di training possono essere scaricati nel nodo stesso. Altre informazioni su come fare riferimento all'archivio dati nell'oggetto Estimator sono disponibili nella documentazione del servizio Azure Machine Learning.
L'invio di un'esecuzione nel servizio Azure Machine Learning avviene tramite la funzione di invio.
run = experiment.submit(estimator)
print(run)
Esiste un altro modo per specificare i parametri per l'esecuzione, usando una configurazione di esecuzione, particolarmente utile per la definizione di un ambiente di training personalizzato. È possibile trovare altre informazioni in questo notebook AmlCompute di esempio.
Monitoraggio delle esecuzioni
Dopo aver inviato un'esecuzione, è possibile attenderne il completamento o monitorala nel servizio Azure Machine Learning tramite i widget di Jupyter che è possibile richiamare direttamente dal codice. È anche possibile effettuare il pull del contesto di un'esecuzione precedente facendo scorrere i vari esperimenti in un'area di lavoro e le singole esecuzioni all'interno di ogni esperimento.
Per Batch per intelligenza artificiale l'operazione è la seguente:
utils.job.wait_for_job_completion(client, cfg.resource_group, cfg.workspace,
experiment_name, job_name, cluster_name, 'stdouterr', 'stdout-wk-0.txt')
files = client.jobs.list_output_files(cfg.resource_group, cfg.workspace, experiment_name, job_name,
models.JobsListOutputFilesOptions(outputdirectoryid='stdouterr'))
for f in list(files):
print(f.name, f.download_url or 'directory')
Per il servizio Azure Machine Learning provare quanto segue:
run.wait_for_completion(show_output=True)
from azureml.widgets import RunDetails
RunDetails(run).show()
Ecco uno snapshot del caricamento del widget nel notebook per esaminare i log in tempo reale: 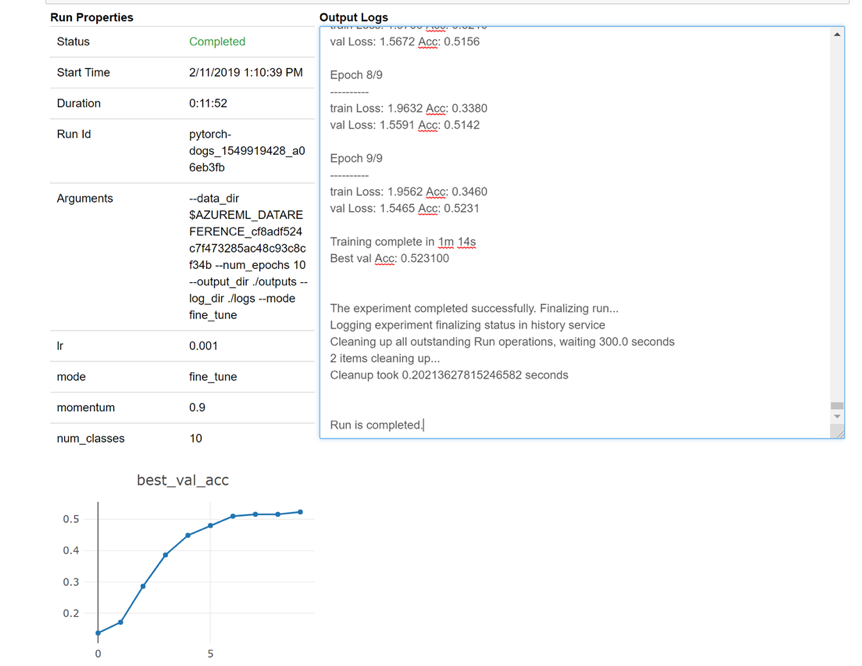
Modifica dei cluster
L'eliminazione di un cluster è molto semplice. Inoltre, il servizio Azure Machine Learning consente anche di aggiornare un cluster dall'interno del notebook nel caso in cui si voglia ridimensionarlo aumentando il numero di nodi o aumentare il tempo di attesa per inattività prima di ridurre il cluster. Non è possibile modificare le dimensioni della macchina virtuale del cluster stesso, perché richiede una nuova distribuzione efficace nel back-end.
Per Batch per intelligenza artificiale l'operazione è la seguente:
_ = client.clusters.delete(cfg.resource_group, cfg.workspace, cluster_name)
Per il servizio Azure Machine Learning provare quanto segue:
gpu_cluster.delete()
gpu_cluster.update(min_nodes=2, max_nodes=4, idle_seconds_before_scaledown=600)
Supporto
L'intelligenza artificiale batch è prevista per il ritiro il 31 marzo e blocca già la registrazione di nuove sottoscrizioni rispetto al servizio, a meno che non sia consentito generare un'eccezione tramite il supporto. Contattare Microsoft in Anteprima del training di Azure Batch per intelligenza artificiale per qualsiasi domanda o per commenti e suggerimenti durante la migrazione al servizio Azure Machine Learning.
Il servizio Azure Machine Learning è ora disponibile a livello generale. Ciò significa che viene fornito con un contratto di servizio e vari piani di supporto tra cui scegliere.
I prezzi per l'uso dell'infrastruttura di Azure tramite il servizio di intelligenza artificiale di Azure Batch o tramite il servizio Azure Machine Learning non devono variare, perché vengono addebitati solo il prezzo per il calcolo sottostante in entrambi i casi. Per altre informazioni, vedere il calcolatore dei prezzi.
Vedere la disponibilità a livello di area tra i due servizi nel portale di Azure.
Passaggi successivi
Leggere la panoramica del servizio Azure Machine Learning.
Configurare una destinazione di calcolo per il training del modello con il servizio Azure Machine Learning.
Rivedere la roadmap per Azure per informazioni su altri aggiornamenti del servizio di Azure.