TripPin parte 7 - Schema avanzato con tipi M
Nota
Questo contenuto fa attualmente riferimento al contenuto di un'implementazione legacy per il testing unità in Visual Studio. Il contenuto verrà aggiornato nel prossimo futuro per coprire il nuovo framework di test di Power Query SDK.
Questa esercitazione in più parti illustra la creazione di una nuova estensione dell'origine dati per Power Query. L'esercitazione è destinata a essere eseguita in sequenza: ogni lezione si basa sul connettore creato nelle lezioni precedenti, aggiungendo in modo incrementale nuove funzionalità al connettore.
In questa lezione verranno illustrate le procedure seguenti:
- Applicare uno schema di tabella usando i tipi M
- Impostare tipi per record e elenchi annidati
- Effettuare il refactoring del codice per il riutilizzo e l'unit test
Nella lezione precedente sono stati definiti gli schemi di tabella usando un semplice sistema "Schema Table". Questo approccio alla tabella dello schema funziona per molte API REST/Connessione or di dati, ma i servizi che restituiscono set di dati completi o annidati in modo approfondito possono trarre vantaggio dall'approccio in questa esercitazione, che sfrutta il sistema di tipi M.
Questa lezione illustra i passaggi seguenti:
- Aggiunta di unit test.
- Definizione di tipi M personalizzati.
- Applicazione di uno schema tramite tipi.
- Refactoring del codice comune in file separati.
Aggiunta di unit test
Prima di iniziare a usare la logica avanzata dello schema, si aggiungerà un set di unit test al connettore per ridurre la probabilità di interruzione accidentale di un elemento. Gli unit test funzionano come segue:
- Copiare il codice comune dall'esempio UnitTest nel
TripPin.query.pqfile. - Aggiungere una dichiarazione di sezione all'inizio del
TripPin.query.pqfile. - Creare un record condiviso (denominato
TripPin.UnitTest). - Definire un
Factoggetto per ogni test. - Chiamare
Facts.Summarize()per eseguire tutti i test. - Fare riferimento alla chiamata precedente come valore condiviso per assicurarsi che venga valutata quando il progetto viene eseguito in Visual Studio.
section TripPinUnitTests;
shared TripPin.UnitTest =
[
// Put any common variables here if you only want them to be evaluated once
RootTable = TripPin.Contents(),
Airlines = RootTable{[Name="Airlines"]}[Data],
Airports = RootTable{[Name="Airports"]}[Data],
People = RootTable{[Name="People"]}[Data],
// Fact(<Name of the Test>, <Expected Value>, <Actual Value>)
// <Expected Value> and <Actual Value> can be a literal or let statement
facts =
{
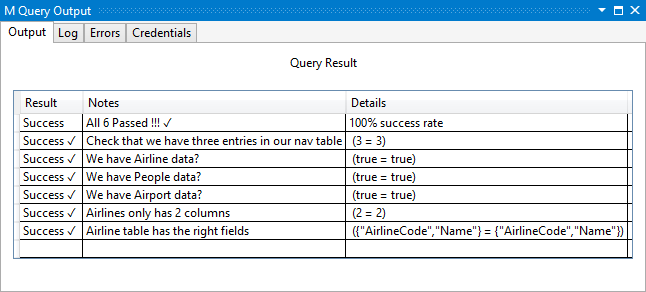
Fact("Check that we have three entries in our nav table", 3, Table.RowCount(RootTable)),
Fact("We have Airline data?", true, not Table.IsEmpty(Airlines)),
Fact("We have People data?", true, not Table.IsEmpty(People)),
Fact("We have Airport data?", true, not Table.IsEmpty(Airports)),
Fact("Airlines only has 2 columns", 2, List.Count(Table.ColumnNames(Airlines))),
Fact("Airline table has the right fields",
{"AirlineCode","Name"},
Record.FieldNames(Type.RecordFields(Type.TableRow(Value.Type(Airlines))))
)
},
report = Facts.Summarize(facts)
][report];
La selezione dell'esecuzione nel progetto valuterà tutti i fatti e restituirà un output del report simile al seguente:
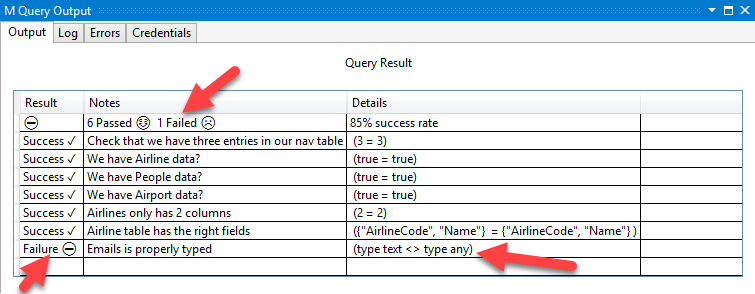
Usando alcuni principi dello sviluppo basato su test, si aggiungerà ora un test che attualmente ha esito negativo, ma presto verrà riimplezionato e corretto (entro la fine di questa esercitazione). In particolare, si aggiungerà un test che controlla uno dei record annidati (messaggi di posta elettronica) restituiti nell'entità Persone.
Fact("Emails is properly typed", type text, Type.ListItem(Value.Type(People{0}[Emails])))
Se si esegue di nuovo il codice, si noterà ora che si è verificato un test non riuscito.
A questo scopo, è sufficiente implementare la funzionalità.
Definizione di tipi M personalizzati
L'approccio di imposizione dello schema nella lezione precedente usava le "tabelle dello schema" definite come coppie Nome/Tipo. Funziona bene quando si lavora con dati flat/relazionali, ma non è supportata l'impostazione dei tipi su record/tabelle/elenchi annidati o consente di riutilizzare le definizioni dei tipi tra tabelle/entità.
Nel caso TripPin, i dati nelle entità Persone e Airports contengono colonne strutturate e condividono anche un tipo (Location) per rappresentare le informazioni sull'indirizzo. Anziché definire coppie Nome/Tipo in una tabella dello schema, ognuna di queste entità verrà definita usando dichiarazioni di tipo M personalizzate.
Di seguito è riportato un rapido aggiornamento dei tipi nel linguaggio M dalla specifica del linguaggio:
Un valore tipo è un valore che classifica altri valori. Si dice che un valore classificato in base a un tipo sia conforme a quel tipo. Il sistema di tipi del linguaggio M è costituito dai tipi seguenti:
- Tipi primitivi, che classificano i valori primitivi (, ,
datetime, ,durationlist,recordtexttimetypenullnumberlogical) e includono anche diversi tipi astratti (functionbinary,table,anye )nonedatetimezonedate- Tipi record, che classificano i valori record in base ai nomi dei campi e ai tipi di valore
- Tipi elenco, che classificano gli elenchi usando un tipo di base a elemento singolo
- Tipi funzione, che classificano i valori funzione in base ai rispettivi tipi di parametri e valori restituiti
- Tipi tabella, che classificano i valori tabella in base ai nomi delle colonne, ai tipi di colonna e alle chiavi
- Tipi nullable, che classificano il valore Null, oltre a tutti i valori classificati a partire da un tipo di base
- Tipi "tipo", che classificano i valori costituiti da tipi
Usando l'output JSON non elaborato che si ottiene (e/o cercando le definizioni nella $metadata del servizio), è possibile definire i tipi di record seguenti per rappresentare i tipi complessi OData:
LocationType = type [
Address = text,
City = CityType,
Loc = LocType
];
CityType = type [
CountryRegion = text,
Name = text,
Region = text
];
LocType = type [
#"type" = text,
coordinates = {number},
crs = CrsType
];
CrsType = type [
#"type" = text,
properties = record
];
Si noti come fa riferimento a LocationType CityType e LocType per rappresentare le colonne strutturate.
Per le entità di primo livello (che si desidera rappresentare come tabelle), si definiscono i tipi di tabella:
AirlinesType = type table [
AirlineCode = text,
Name = text
];
AirportsType = type table [
Name = text,
IataCode = text,
Location = LocationType
];
PeopleType = type table [
UserName = text,
FirstName = text,
LastName = text,
Emails = {text},
AddressInfo = {nullable LocationType},
Gender = nullable text,
Concurrency = Int64.Type
];
Si aggiorna quindi la SchemaTable variabile (che viene usata come "tabella di ricerca" per i mapping di entità a tipi) per usare queste nuove definizioni di tipo:
SchemaTable = #table({"Entity", "Type"}, {
{"Airlines", AirlinesType },
{"Airports", AirportsType },
{"People", PeopleType}
});
Applicazione di uno schema tramite tipi
Si farà affidamento su una funzione comune (Table.ChangeType) per applicare uno schema ai dati, in modo analogo a quello usato SchemaTransformTable nella lezione precedente.
A differenza di SchemaTransformTable, Table.ChangeType accetta un tipo di tabella M effettivo come argomento e applicherà lo schema in modo ricorsivo per tutti i tipi annidati. La firma è simile alla seguente:
Table.ChangeType = (table, tableType as type) as nullable table => ...
Il listato di codice completo per la Table.ChangeType funzione è disponibile nel file Table.ChangeType.pqm .
Nota
Per una maggiore flessibilità, la funzione può essere usata nelle tabelle, nonché elenchi di record (che è il modo in cui le tabelle vengono rappresentate in un documento JSON).
È quindi necessario aggiornare il codice connettore per modificare il schema parametro da a table a typee aggiungere una chiamata a Table.ChangeType in GetEntity.
GetEntity = (url as text, entity as text) as table =>
let
fullUrl = Uri.Combine(url, entity),
schema = GetSchemaForEntity(entity),
result = TripPin.Feed(fullUrl, schema),
appliedSchema = Table.ChangeType(result, schema)
in
appliedSchema;
GetPage viene aggiornato per usare l'elenco dei campi dello schema (per conoscere i nomi di cosa espandere quando si ottengono i risultati), ma lascia l'effettiva imposizione dello schema a GetEntity.
GetPage = (url as text, optional schema as type) as table =>
let
response = Web.Contents(url, [ Headers = DefaultRequestHeaders ]),
body = Json.Document(response),
nextLink = GetNextLink(body),
// If we have no schema, use Table.FromRecords() instead
// (and hope that our results all have the same fields).
// If we have a schema, expand the record using its field names
data =
if (schema <> null) then
Table.FromRecords(body[value])
else
let
// convert the list of records into a table (single column of records)
asTable = Table.FromList(body[value], Splitter.SplitByNothing(), {"Column1"}),
fields = Record.FieldNames(Type.RecordFields(Type.TableRow(schema))),
expanded = Table.ExpandRecordColumn(asTable, fields)
in
expanded
in
data meta [NextLink = nextLink];
Conferma dell'impostazione dei tipi annidati
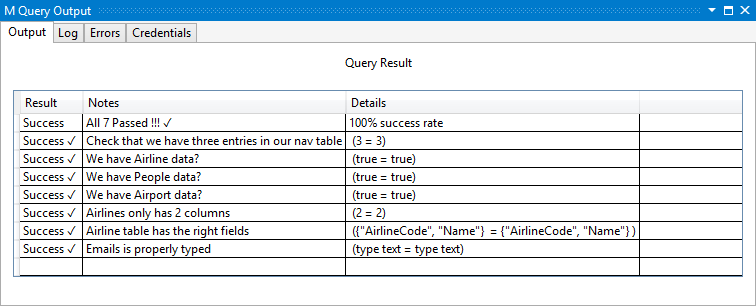
La definizione per ora PeopleType imposta il Emails campo su un elenco di testo ({text}).
Se si applicano correttamente i tipi, la chiamata a Type.ListItem nello unit test dovrebbe ora restituire type text anziché type any.
L'esecuzione degli unit test mostra di nuovo che sono tutti superati.
Refactoring di codice comune in file separati
Nota
Il motore M avrà migliorato il supporto per fare riferimento a moduli esterni/codice comune in futuro, ma questo approccio dovrebbe portare avanti fino ad allora.
A questo punto, l'estensione ha quasi il codice "comune" come il codice del connettore TripPin. In futuro queste funzioni comuni faranno parte della libreria di funzioni standard predefinita oppure sarà possibile farvi riferimento da un'altra estensione. Per il momento, si esegue il refactoring del codice nel modo seguente:
- Spostare le funzioni riutilizzabili in file separati (con estensione pqm).
- Impostare la proprietà Azione di compilazione nel file su Compila per assicurarsi che venga inclusa nel file di estensione durante la compilazione .
- Definire una funzione per caricare il codice usando Expression.Evaluate.
- Caricare ognuna delle funzioni comuni da usare.
Il codice per eseguire questa operazione è incluso nel frammento di codice seguente:
Extension.LoadFunction = (fileName as text) =>
let
binary = Extension.Contents(fileName),
asText = Text.FromBinary(binary)
in
try
Expression.Evaluate(asText, #shared)
catch (e) =>
error [
Reason = "Extension.LoadFunction Failure",
Message.Format = "Loading '#{0}' failed - '#{1}': '#{2}'",
Message.Parameters = {fileName, e[Reason], e[Message]},
Detail = [File = fileName, Error = e]
];
Table.ChangeType = Extension.LoadFunction("Table.ChangeType.pqm");
Table.GenerateByPage = Extension.LoadFunction("Table.GenerateByPage.pqm");
Table.ToNavigationTable = Extension.LoadFunction("Table.ToNavigationTable.pqm");
Conclusione
Questa esercitazione ha apportato numerosi miglioramenti al modo in cui si applica uno schema ai dati che si ottengono da un'API REST. Il connettore attualmente imposta come hardcoded le informazioni sullo schema, con un vantaggio sulle prestazioni in fase di esecuzione, ma non è in grado di adattarsi alle modifiche apportate ai metadati del servizio nel tempo straordinario. Le esercitazioni future passeranno a un approccio puramente dinamico che dedurrà lo schema dal documento $metadata del servizio.
Oltre alle modifiche dello schema, in questa esercitazione sono stati aggiunti unit test per il codice ed è stato effettuato il refactoring delle funzioni helper comuni in file separati per migliorare la leggibilità complessiva.