Sincronizzare l'origine dati di Excel con Dataverse usando un flusso di dati
Uno degli scenari comuni che si verificano quando si integrano i dati in Dataverse lo mantiene sincronizzato con l'origine. Usando il flusso di dati standard, è possibile caricare i dati in Dataverse. Questo articolo illustra come mantenere sincronizzati i dati con il sistema di origine.
Importanza della colonna chiave
Se si usa un sistema di base dati relazionale come origine, in genere si dispone di colonne chiave nelle tabelle e i dati sono in un formato appropriato da caricare in Dataverse. Tuttavia, i dati dei file di Excel non sono sempre così puliti. Spesso si dispone di un file di Excel con fogli di dati senza avere alcuna colonna chiave. In Considerazioni sul mapping dei campi per i flussi di dati standard è possibile notare che, se è presente una colonna chiave nell'origine, può essere facilmente usata come chiave alternativa nel mapping dei campi del flusso di dati.
La presenza di una colonna chiave è importante per la tabella in Dataverse. La colonna chiave è l'identificatore di riga; questa colonna contiene valori univoci in ogni riga. La presenza di una colonna chiave consente di evitare righe duplicate e consente anche di sincronizzare i dati con il sistema di origine. Se una riga viene rimossa dal sistema di origine, la presenza di una colonna chiave è utile per trovarla e rimuoverla anche da Dataverse.
Creazione di una colonna chiave
Se non si dispone di una colonna chiave nell'origine dati (Excel, file di testo o altre origini), è possibile generarne una usando il metodo seguente:
Pulire i dati.
Il primo passaggio per creare la colonna chiave consiste nel rimuovere tutte le righe non necessarie, pulire i dati, rimuovere righe vuote e rimuovere eventuali duplicati possibili.
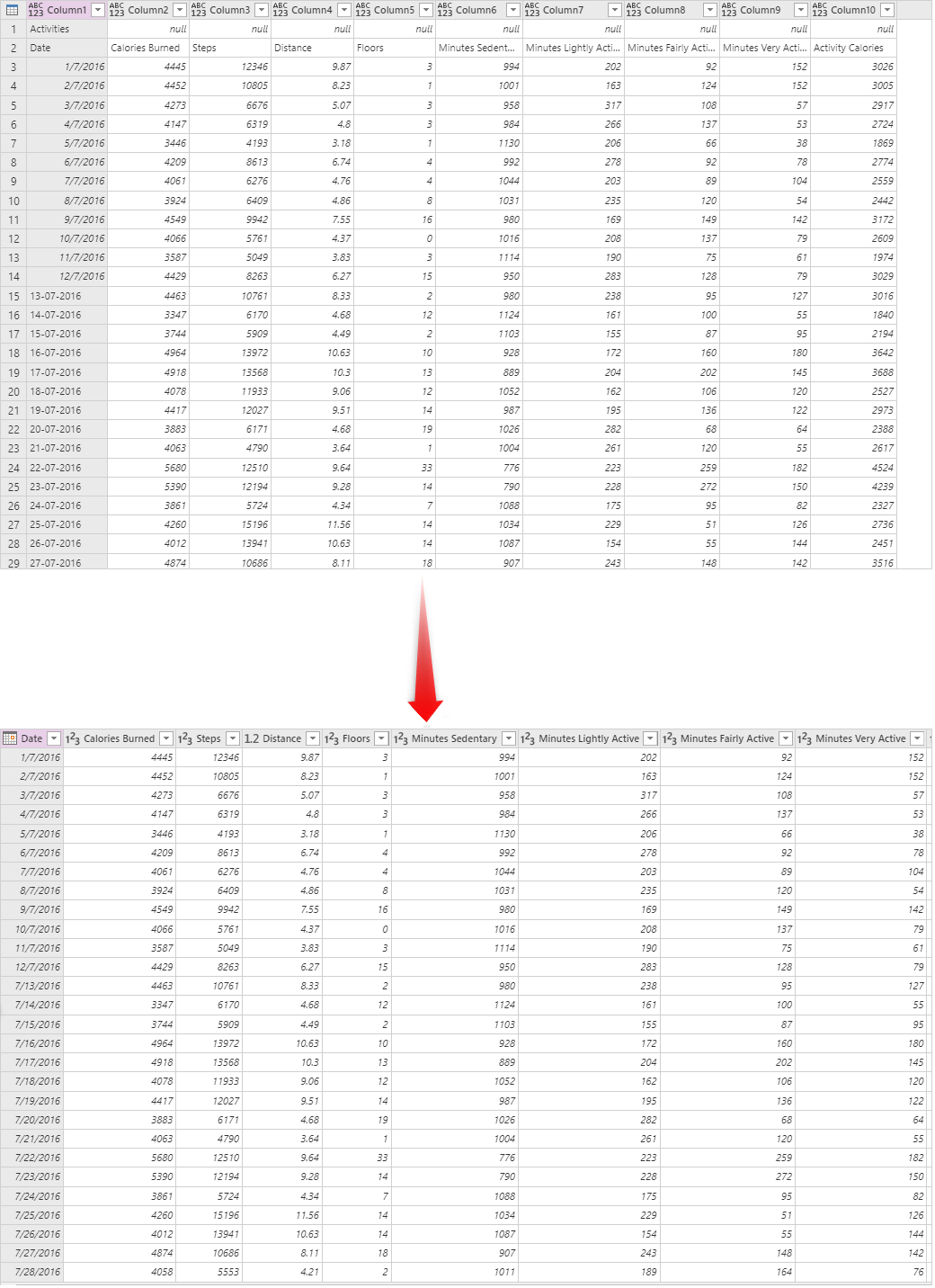
Aggiungere una colonna di indice.
Dopo la pulizia dei dati, il passaggio successivo consiste nell'assegnare una colonna chiave. A questo scopo, è possibile usare Aggiungi colonna indice dalla scheda Aggiungi colonna .
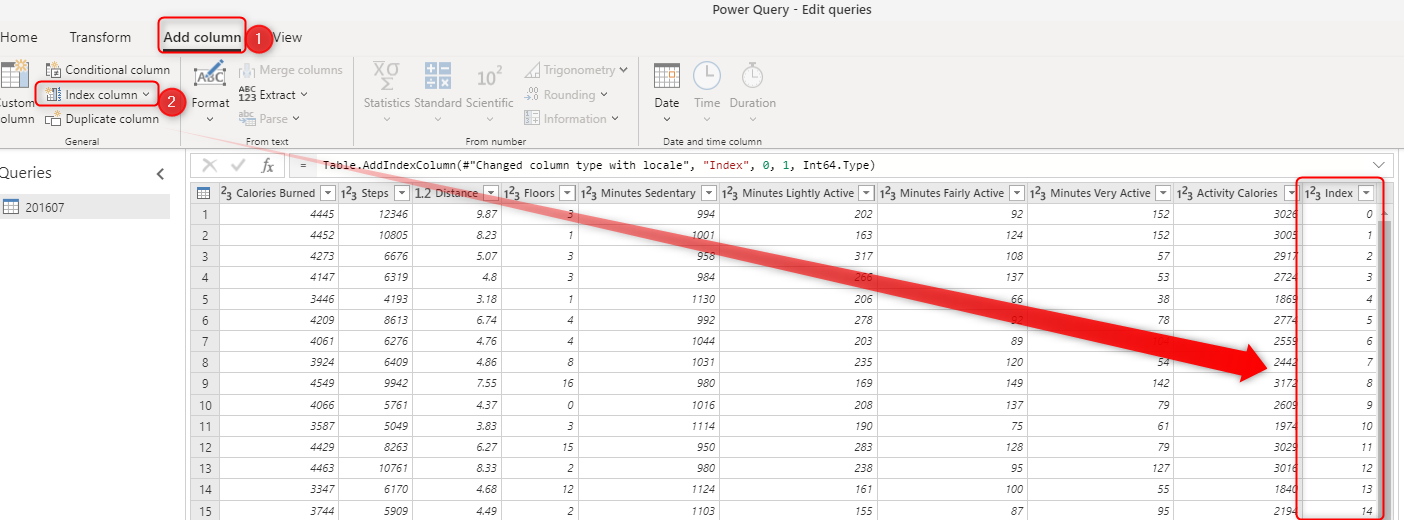
Quando si aggiunge la colonna di indice, sono disponibili alcune opzioni per personalizzarla, ad esempio personalizzazioni sul numero iniziale o sul numero di valori da saltare ogni volta. Il valore iniziale predefinito è zero e incrementa ogni volta un valore.
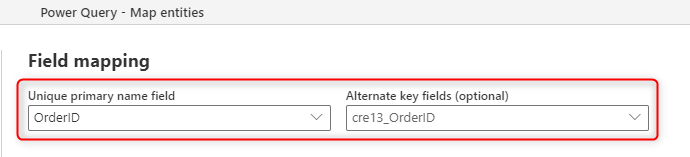
Usare la colonna chiave come chiave alternativa
Dopo aver creato le colonne chiave, è possibile assegnare il mapping dei campi del flusso di dati alla chiave alternativa.
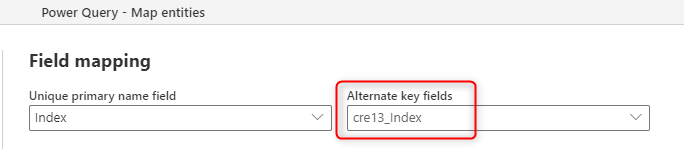
L'impostazione è semplice, è sufficiente impostare la chiave alternativa. Tuttavia, se sono presenti più file o tabelle, è necessario prendere in considerazione un altro passaggio.
Se sono presenti più file
Se si dispone di un solo file di Excel (o foglio o tabella), i passaggi della procedura precedente sono sufficienti per impostare la chiave alternativa. Tuttavia, se sono presenti più file (o fogli o tabelle) con la stessa struttura (ma con dati diversi), è necessario aggiungerli insieme.
Se si recuperano dati da più file di Excel, l'opzione Combina file di Power Query accoderà automaticamente tutti i dati e l'output sarà simile all'immagine seguente.
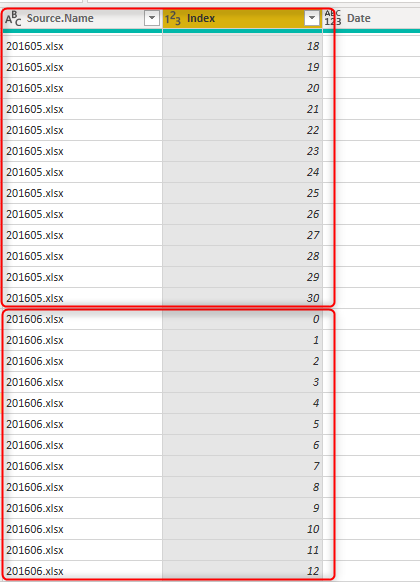
Come illustrato nell'immagine precedente, oltre al risultato dell'accodamento, Power Query inserisce anche la colonna Source.Name, che contiene il nome del file. Il valore index in ogni file potrebbe essere univoco, ma non è univoco in più file. Tuttavia, la combinazione della colonna Index e della colonna Source.Name è una combinazione univoca. Scegliere una chiave alternativa composita per questo scenario.
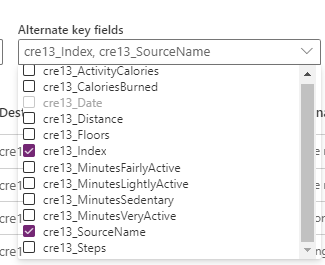
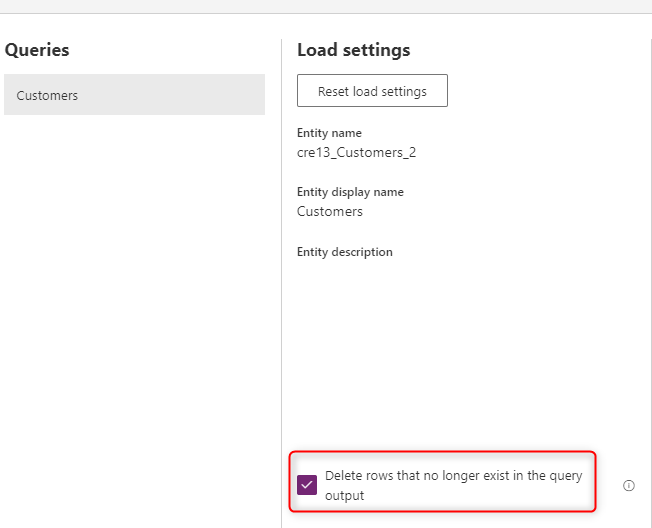
Eliminare righe che non esistono più nell'output della query
L'ultimo passaggio consiste nel selezionare le elimina righe che non esistono più nell'output della query. Questa opzione confronta i dati nella tabella Dataverse con i dati provenienti dall'origine in base alla chiave alternativa (che potrebbe essere una chiave composita) e rimuove le righe che non esistono più. Di conseguenza, i dati in Dataverse verranno sempre sincronizzati con l'origine dati.