Portare il proprio Azure Data Lake Storage Gen2
Il Process Mining di Power Automate offre la possibilità di archiviare e leggere i dati del registro eventi direttamente da Azure Data Lake Storage Gen2. Questa funzionalità semplifica la gestione di estrazione, trasformazione e caricamento (ETL) connettendosi direttamente all'account di archiviazione.
Questa funzionalità supporta attualmente l'inserimento di quanto segue:
-
CSV
- File CSV singolo.
- Cartella con più file CSV con la stessa struttura. Tutti i file vengono inseriti.
-
Parquet
- File parquet singolo.
- Cartella con più file parquet con la stessa struttura. Tutti i file vengono inseriti.
-
Delta-parquet
- Cartella che contiene una struttura delta-parquet.
Prerequisiti
L'account di archiviazione Data Lake Storage Gen2. Puoi controllare dal portale di Azure. Gli account di archiviazione Azure Data Lake Gen1 non sono supportati.
L'account di Data Lake Storage deve avere lo spazio dei nomi gerarchico abilitato.
Il ruolo Proprietario deve essere attribuito all'utente che esegue la configurazione iniziale del contenitore per l'ambiente per i seguenti utenti nello stesso ambiente. Questi utenti si connettono allo stesso contenitore e devono avere queste assegnazioni:
- Ruolo Lettore dati BLOB di archiviazione o Collaboratore dati BLOB di archiviazione assegnato
- Ruolo Azure Resource Manager Lettore assegnato, come minimo.
È necessario stabilire una regola Condivisione delle risorse (CORS) per l'account di archiviazione per la condivisione con Process Mining di Power Automate.
Le origini consentite devono essere impostate su
https://make.powerautomate.comehttps://make.powerapps.com.I metodi consentiti devono includere:
get,options,put,post.Le intestazioni consentite dovrebbero essere il più flessibili possibile. Ti consigliamo di definirli come
*.Le intestazioni esposte dovrebbero essere il più flessibili possibile. Ti consigliamo di definirli come
*.L'età massima dovrebbe essere il più flessibile possibile. Ti consigliamo di usare
86400.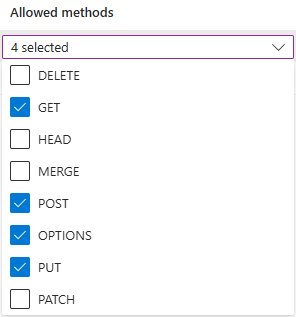
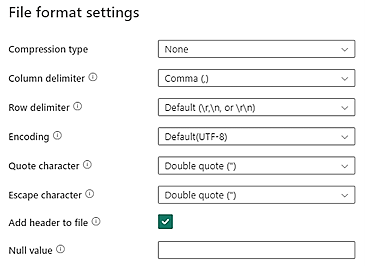
I dati CSV nel Data Lake Storage devono soddisfare i seguenti requisiti di formato file CSV:
- Tipo di compressione: nessuno
- Delimitatore di colonna: virgola (,)
- Delimitatore di riga: predefinito e codifica. Ad esempio, predefinito (\r,\n o \r\n)
Tutti i dati devono essere nel formato del registro eventi finale e soddisfare i requisiti elencati in Requisiti dei dati. I dati devono essere pronti per essere mappati allo schema del Process Mining. Nessuna trasformazione dei dati è disponibile dopo l'importazione.
Le dimensioni (larghezza) della riga di intestazione sono attualmente limitate a 1 MB.
Importante
Assicurati che il timestamp rappresentato nel tuo file CSV segua il formato standard ISO 8601 (ad esempio, YYYY-MM-DD HH:MM:SS.sss o YYYY-MM-DDTHH:MM:SS.sss).
Connettersi a Azure Data Lake Storage
Nel riquadro di spostamento a sinistra, seleziona Process Mining>Inizia qui.
Nel campo Nome processo immetti un nome per il processo.
Sotto l'intestazione Origine dati, seleziona Importa dati>Azure Data Lake> Continua.

Nella schermata Configurazione della connessione, seleziona il tuo ID sottoscrizione, Gruppo di risorse, Account di archiviazioneeContenitore dai menu a discesa.
Seleziona il file o la cartella contenente i dati del registro eventi.
È possibile selezionare un singolo file o una cartella con più file. Tutti i file devono avere le stesse intestazioni e lo stesso formato.
Seleziona Avanti.
Nella schermata Mappa i tuoi dati, mappa i dati allo schema richiesto.
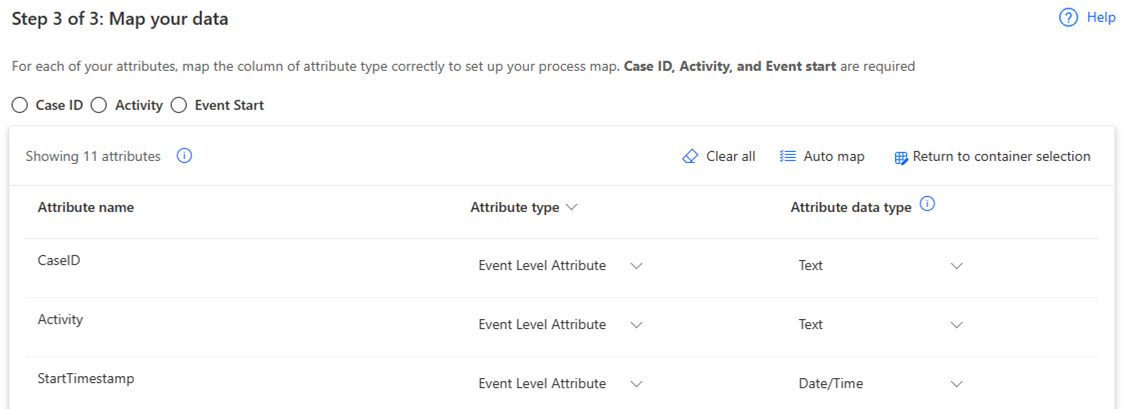
Completa la connessione selezionando Salva e analizza.
Definisci le impostazioni di aggiornamento dei dati incrementali
È possibile aggiornare un processo inserito da Azure Data Lake in base a una pianificazione, tramite un aggiornamento completo o incrementale. Sebbene non esistano criteri di conservazione, è possibile importare i dati in modo incrementale utilizzando uno dei seguenti metodi:
Se hai selezionato un file singolo nella sezione precedente, aggiungi più dati al file selezionato.
Se hai selezionato una cartella nella sezione precedente, aggiungi file incrementali alla cartella selezionata.
Importante
Quando aggiungi file incrementali a una cartella o sottocartella selezionata, assicurati di indicare l'ordine di incremento assegnando ai file nomi con date ad esempio YYYMMDD.csv o YYYYMMDDHHMMSS.csv.
Per aggiornare un processo:
Vai alla pagina Dettagli del processo.
Seleziona Impostazioni aggiornamento.
Nella schermata Aggiornamento della pianificazione, completa i seguenti passaggi:
- Abilita l'interruttore Mantieni aggiornati i dati.
- Nell'elenco a discesa Aggiorna i dati ogni, seleziona la frequenza dell'aggiornamento.
- Nei campi Inizia alle, seleziona la data e l'ora dell'aggiornamento.
- Abilita l'interruttore Aggiornamento incrementale.