Copiare dati di Dataverse in Azure SQL
Utilizza Azure Synapse Link per collegare i i dati Microsoft Dataverse ad Azure Synapse Analytics per esplorare i dati e accelerare il tempo per ottenere informazioni dettagliate. Questo articolo mostra come eseguire le pipeline di Azure Synapse o Azure Data Factory per copiare dati da Azure Data Lake Storage Gen2 in un database SQL di Azure con la funzionalità relativa agli aggiornamenti incrementali abilitata in Azure Synapse Link.
Nota
Azure Synapse Link for Microsoft Dataverse era precedentemente noto come Export to data lake. Il servizio è stato rinominato a partire da maggio 2021 e continuerà a esportare dati in Azure Data Lake nonché in Azure Synapse Analytics. Questo modello è un esempio di codice. Ti invitiamo a usare questo modello come guida per testare la funzionalità di recupero dei dati da Azure Data Lake Storage Gen2 al database SQL di Azure usando la pipeline fornita.
Prerequisiti
- Azure Synapse Link for Dataverse. Questa guida presuppone che i prerequisiti per creare un Azure Synapse Link con Azure Data Lake siano stati soddisfatti. Ulteriori informazioni: Prerequisiti per un Azure Synapse Link for Dataverse con Azure Data Lake
- Creare Azure Synapse Workspace o Azure Data Factory sotto lo stesso tenant di Microsoft Entra come tenant di Power Apps.
- Crea un Azure Synapse Link for Dataverse con l'aggiornamento incrementale delle cartelle abilitato per impostare l'intervallo di tempo. Ulteriori informazioni: Eseguire query e analizzare gli aggiornamenti incrementali
- Il provider Microsoft.EventGrid deve essere registrato per il trigger. Ulteriori informazioni: Portale di Azure. Nota: se stai utilizzando questa funzione in Azure Synapse Analytics, assicurati che anche la tua sottoscrizione sia registrata con il provider di risorse Data Factory, altrimenti visualizzerai un messaggio di errore che indica che la creazione di un "Sottoscrizione evento" non è riuscita.
- Creare un database SQL di Azure con la proprietà Consenti a servizi e risorse di Azure di accedere a questo server abilitata. Maggiori informazioni: Cosa devo sapere quando configuro il mio database SQL di Azure (PaaS)?
- Creare e configurare un runtime di integrazione di Azure. Maggiori informazioni: Creare un runtime di integrazione di Azure - Azure Data Factory e Azure Synapse
Importante
L'utilizzo di questo modello potrebbe comportare costi aggiuntivi. Questi costi sono correlati all'utilizzo di Azure Data Factory o della pipeline Synapse workspace e vengono fatturati su base mensile. Il costo dell'utilizzo delle pipeline dipende principalmente dall'intervallo di tempo per l'aggiornamento incrementale e dai volumi di dati. Per pianificare e gestire il costo dell'utilizzo di questa funzione, vai a: Monitorare i costi a livello di pipeline con l'analisi dei costi
È importante prendere in considerazione questi costi aggiuntivi quando si decide di utilizzare questo modello in quanto non sono facoltativi e devono essere pagati per continuare a utilizzare questa funzione.
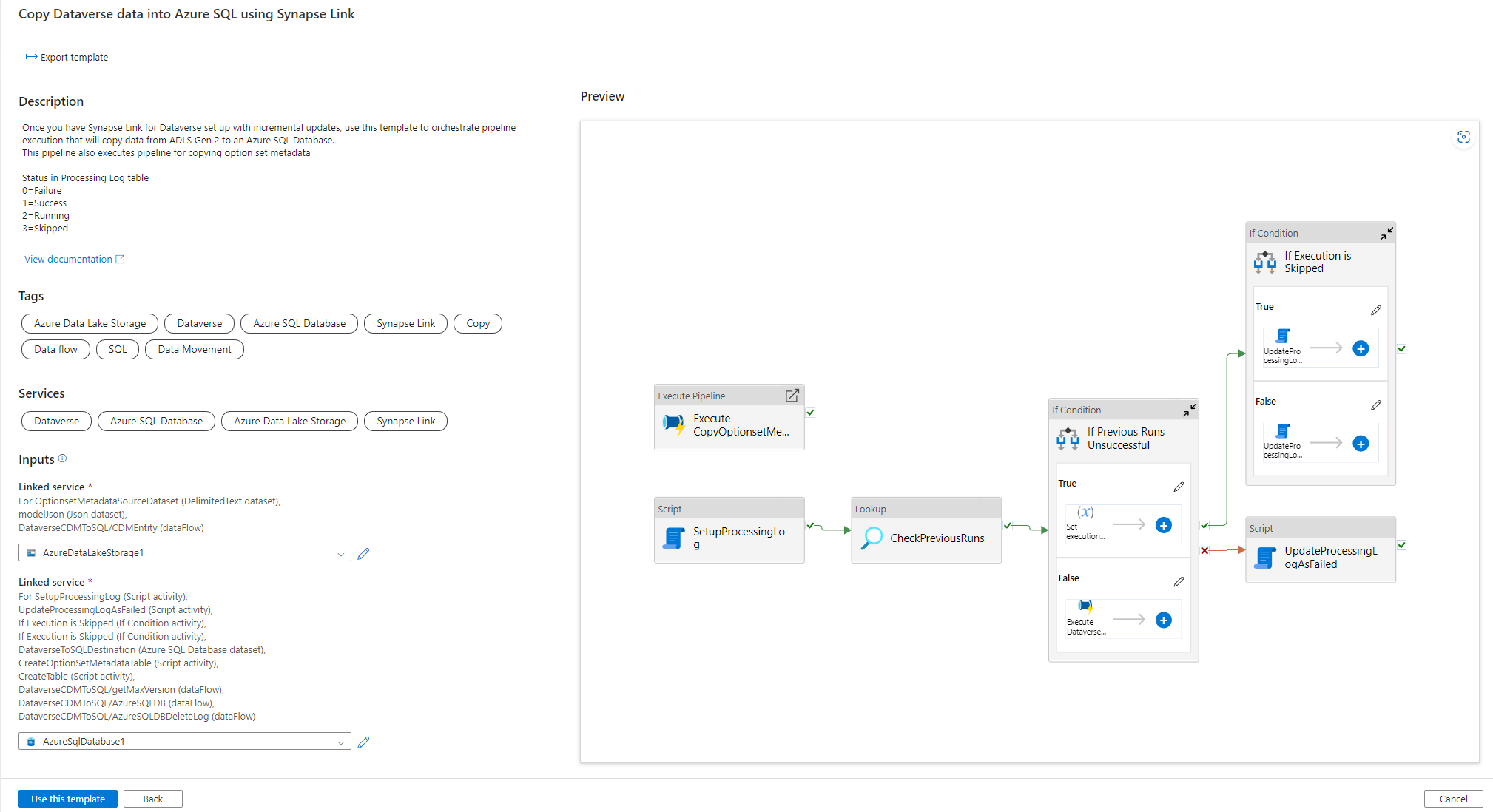
Utilizzare il modello di soluzione
- Vai al portale di Azure e apri Azure Synapse workspace.
- Seleziona Integra > Esplora raccolta.
- Seleziona Copia i dati Dataverse in Azure SQL usando Synapse Link nella raccolta di integrazione.
Configurare Il modello di soluzione
Crea un servizio collegato a Azure Data Lake Storage Gen2, che è connesso a Dataverse mediante il tipo di autenticazione appropriato. A questo proposito, seleziona Prova connessione per convalidare la connettività, quindi seleziona Crea.
Analogamente ai passaggi precedenti, crea un servizio collegato al database SQL di Azure dove i dati di Dataverse verranno sincronizzati.
Dopo la configurazione di Input, seleziona Usa questo modello.
Ora è possibile aggiungere un trigger per automatizzare questa pipeline, in modo che la pipeline possa sempre elaborare i file quando gli aggiornamenti incrementali vengono completati periodicamente. Vai a Gestisci > Trigger e crea un trigger utilizzando le seguenti proprietà:
- Nome: immetti un nome per il trigger, ad esempio triggerModelJson.
- Tipo: eventi di archiviazione.
- Sottoscrizione di Azure: seleziona la sottoscrizione che ha Azure Data Lake Storage Gen2.
- Nome account di archiviazione: seleziona l'archiviazione con i dati di Dataverse.
- Nome contenitore: seleziona il contenitore creato da Azure Synapse Link.
- Il percorso BLOB termina con: /model.json
- Evento: BLOB creato.
- Ignora BLOB vuoti: sì.
- Avvia trigger: abilita Avvia trigger alla creazione.
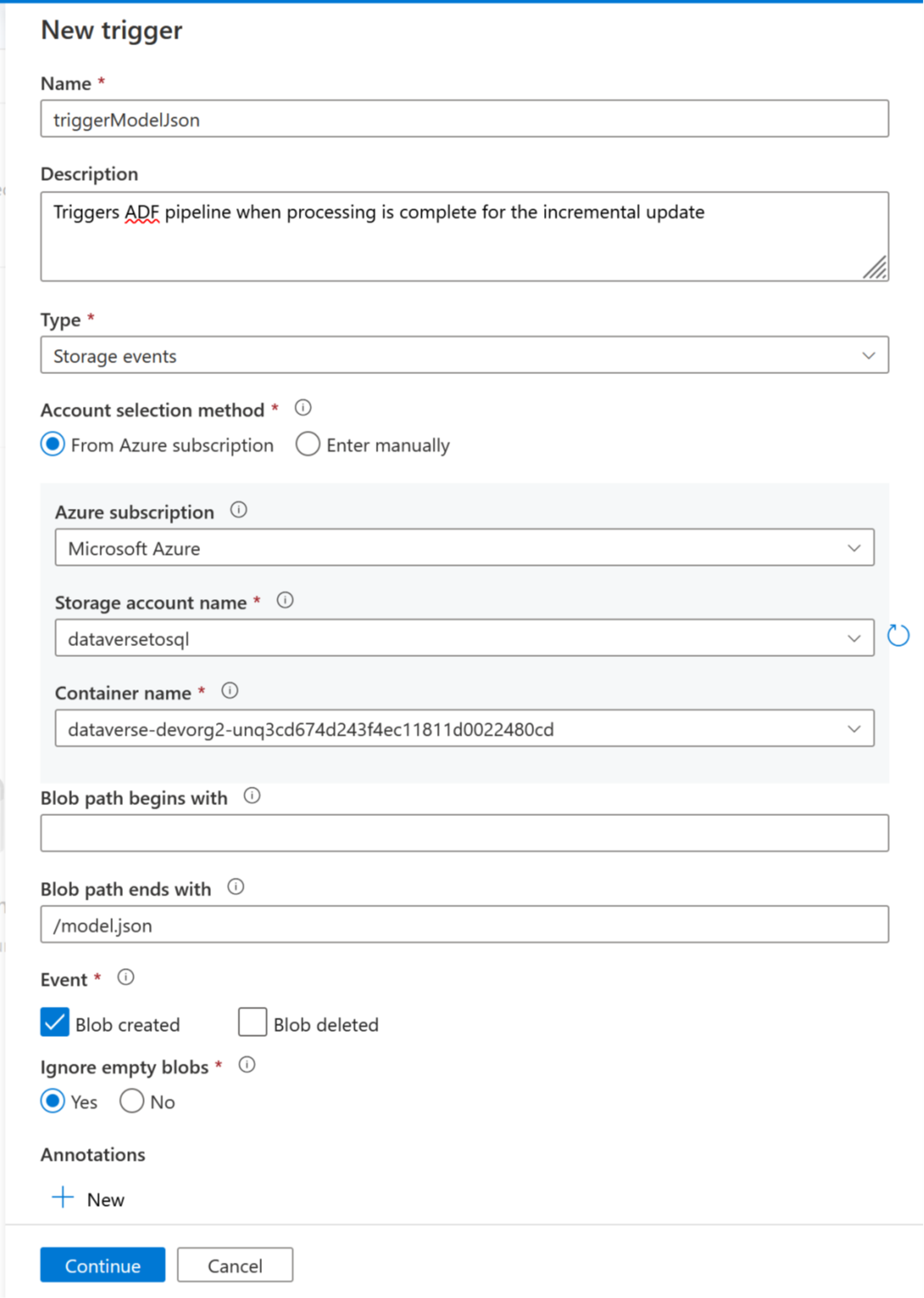
Seleziona Continua per procedere alla schermata successiva.
Nella schermata successiva, il trigger convalida i file corrispondenti. Seleziona OK per creare il trigger.
Associa il trigger a una pipeline. Vai alla pipeline importata in precedenza e quindi seleziona Aggiungi trigger > Nuovo/Modifica.

Seleziona il trigger nel passaggio precedente, quindi seleziona Continua per passare alla schermata successiva in cui il trigger convalida i file corrispondenti.
Seleziona Continua per procedere alla schermata successiva.
Nella sezione Attiva parametro di esecuzione, immetti i parametri seguenti e quindi seleziona OK.
- Contenitore:
@split(triggerBody().folderPath,'/')[0] - Cartella:
@split(triggerBody().folderPath,'/')[1]
- Contenitore:
Dopo aver associato il trigger alla pipeline, seleziona Convalida tutto.
Una volta completata la convalida, seleziona Pubblica tutto.
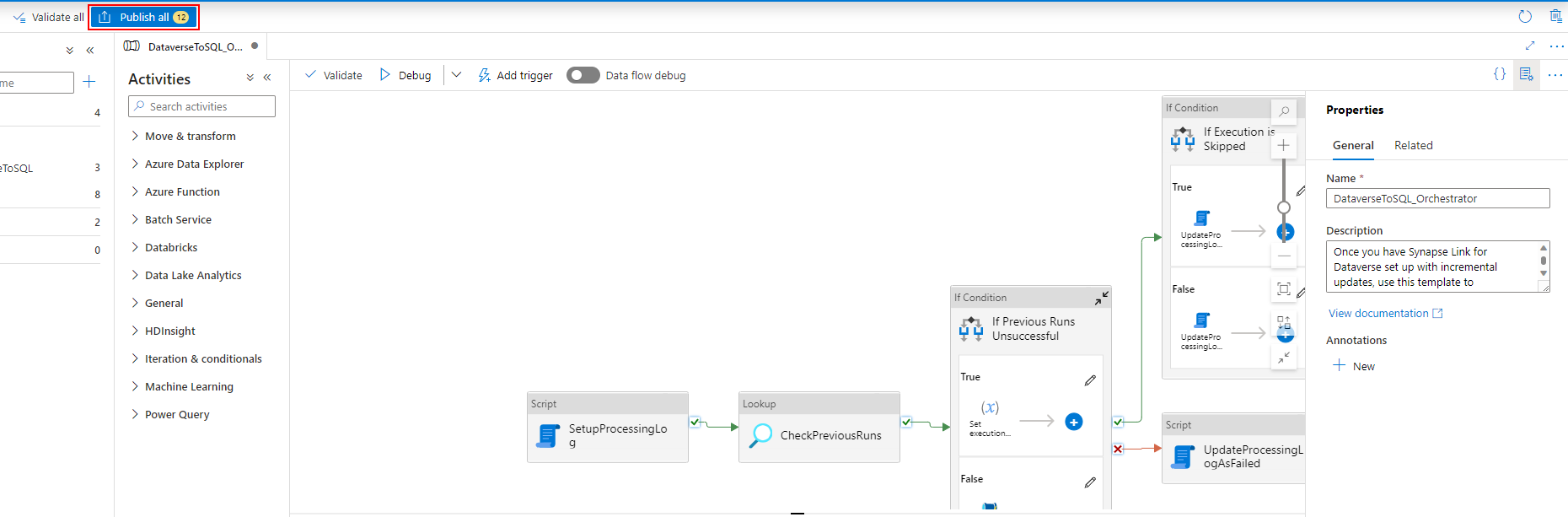
Seleziona Pubblica per pubblicare tutte le modifiche.



Aggiungere un filtro di sottoscrizione evento
Per garantire che il trigger si attivi solo al termine della creazione di model.json, devi aggiornare i filtri avanzati per la sottoscrizione dell'evento del trigger. Un evento viene registrato nell'account di archiviazione alla prima esecuzione del trigger.
Al termine dell'esecuzione di un trigger, vai all'account di archiviazione > Eventi > Sottoscrizione evento.
Seleziona l'evento che è stato registrato per il trigger model.json.
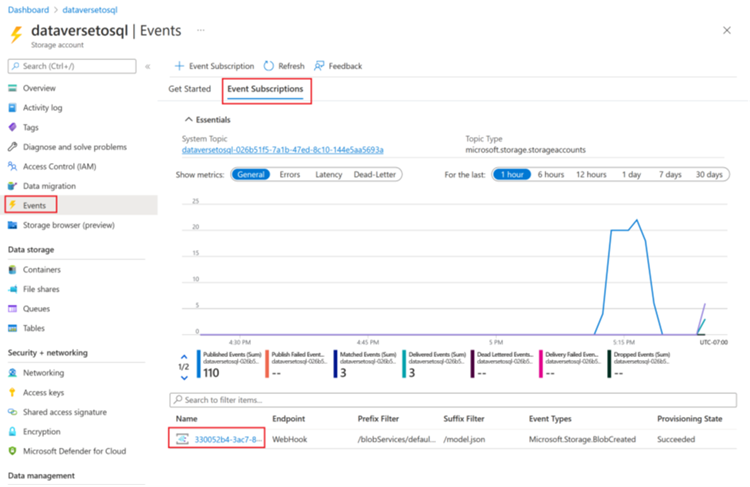
Seleziona la scheda Filtri e quindi seleziona Aggiungi nuovo filtro.
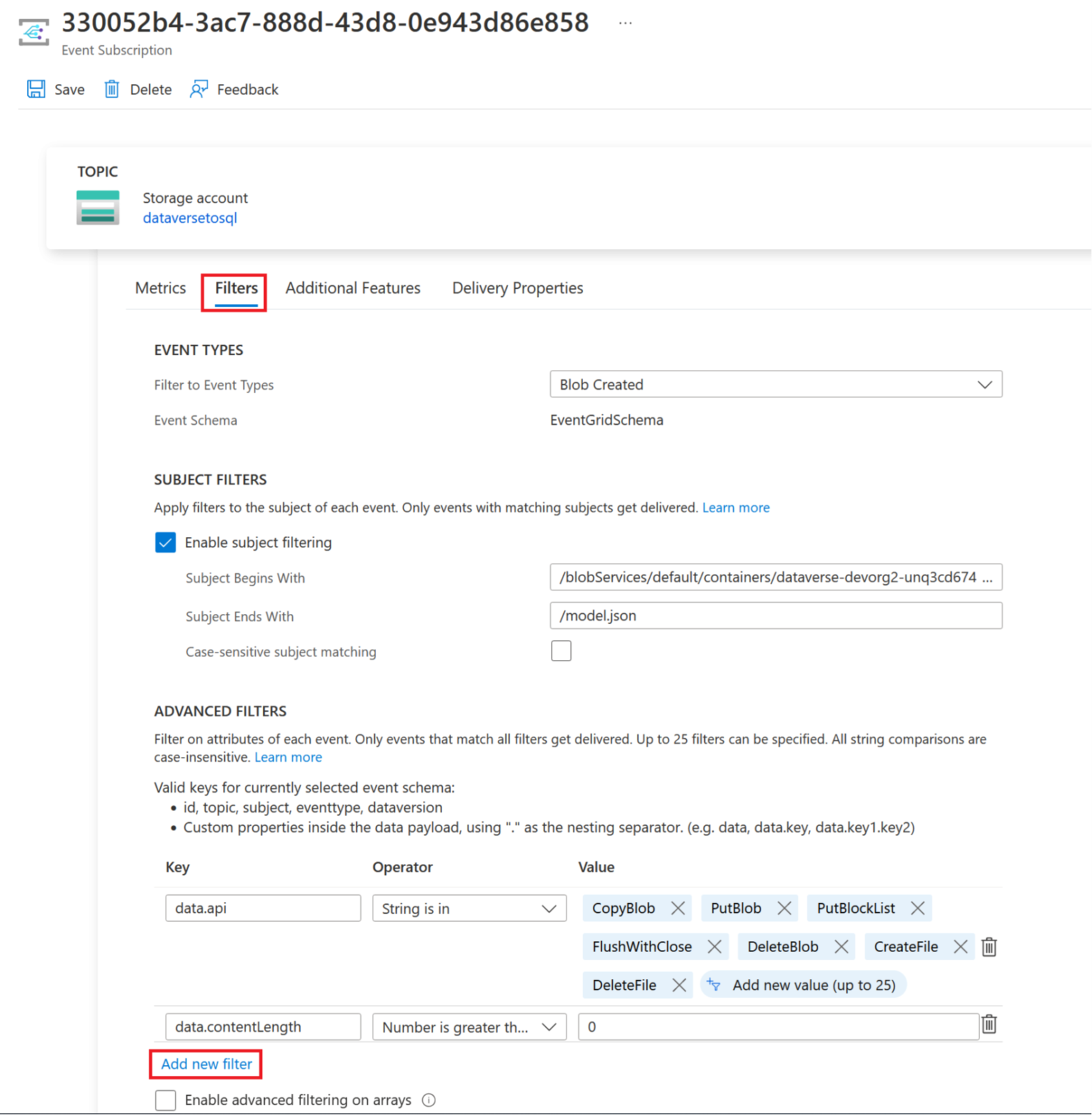
Crea il filtro:
- Chiave: oggetto
- Operatore: la stringa non termina con
- Valore: /blobs/modello.json
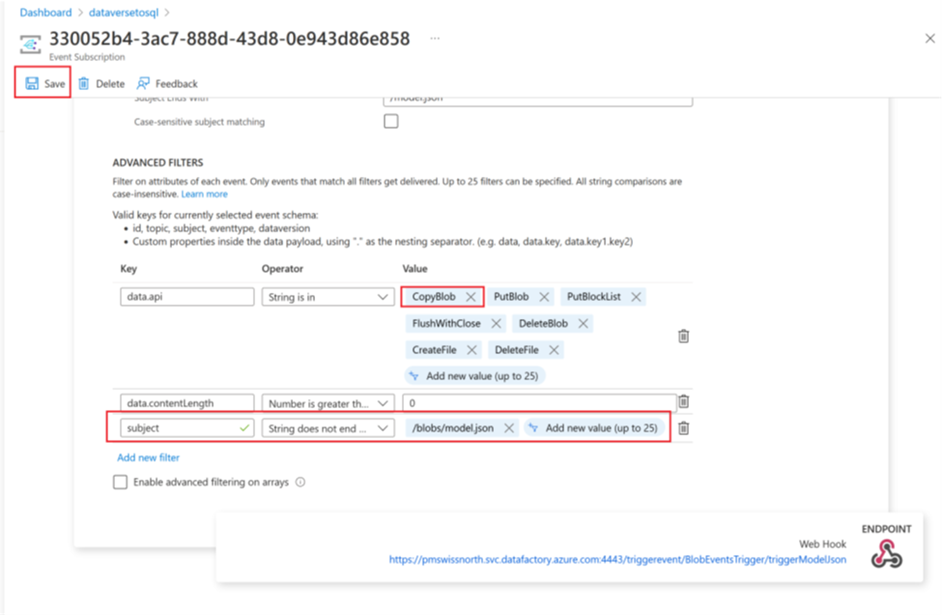
Rimuovi il parametro CopyBlob della matrice Valore data.api.
Seleziona Salva per distribuire il filtro aggiuntivo.
Vedi anche
Blog: Annuncio di Azure Synapse Link for Dataverse
Nota
Puoi indicarci le tue preferenze di lingua per la documentazione? Partecipa a un breve sondaggio. (il sondaggio è in inglese)
Il sondaggio richiederà circa sette minuti. Non viene raccolto alcun dato personale (Informativa sulla privacy).