Connettore Oracle SQL Microsoft Graph
Il connettore Oracle SQL Graph consente all'organizzazione di individuare e indicizzare i dati da un database Oracle locale. Il connettore indicizza il contenuto specificato in Microsoft Search. Per mantenere aggiornato l'indice con i dati di origine, supporta ricerche per indicizzazione periodiche complete e incrementali. Con il connettore Oracle SQL è anche possibile limitare l'accesso ai risultati della ricerca per determinati utenti.
Nota
Leggere l'articolo Configurare i connettori di Microsoft Graph nell'articolo interfaccia di amministrazione di Microsoft 365 per comprendere le istruzioni generali di configurazione dei connettori di Microsoft Graph.
Questo articolo è destinato a tutti gli utenti che configurano, eseguono e monitorano un connettore Oracle SQL Graph. Integra il processo di installazione generale e mostra le istruzioni valide solo per il connettore Oracle SQL Graph. Questo articolo include anche informazioni sulla risoluzione dei problemi e sulle limitazioni.
Nozioni preliminari
Installare l'agente connettore
Per accedere ai dati di terze parti locali, è necessario installare e configurare l'agente connettore Graph. Per altre informazioni, vedere Installare l'agente connettore Graph .
Passaggio 1: Aggiungere un connettore nel interfaccia di amministrazione di Microsoft 365
Aggiungere il connettore Oracle SQL
Seguire le istruzioni di configurazione generali.
Passaggio 2: Assegnare un nome alla connessione
Seguire le istruzioni di configurazione generali.
Passaggio 3: Configurare le impostazioni di connessione
Per connettere il connettore Oracle SQL a un'origine dati, è necessario configurare il server di database per cui si vuole eseguire la ricerca per indicizzazione e l'agente connettore Graph locale. È quindi possibile connettersi al database con il metodo di autenticazione richiesto.
Per il connettore Oracle SQL, è necessario specificare il nome host, la porta e il nome del servizio (database) insieme al metodo di autenticazione preferito, al nome utente e alla password.
Se il nome del servizio non è disponibile e ci si connette tramite SID, il nome del servizio può essere derivato usando uno dei comandi seguenti (da eseguire come amministratore sys) -
- selezionare SERVICE_NAME da gv$session in cui sid in (selezionare sid da v$MYSTAT);
- selezionare sys_context('userenv','service_name') da dual;
Nota
Il database deve eseguire il database Oracle versione 11g o successiva affinché il connettore possa connettersi. Il connettore supporta il database Oracle ospitato in piattaforme Windows, Linux e macchine virtuali di Azure.
Per eseguire ricerche nel contenuto del database, è necessario specificare query SQL quando si configura il connettore. Queste query SQL devono denominare tutte le colonne di database che si desidera indicizzare, ovvero le proprietà di origine, inclusi i join SQL che devono essere eseguiti per ottenere tutte le colonne. Per limitare l'accesso ai risultati della ricerca, è necessario specificare Controllo di accesso Elenchi (ACL) nelle query SQL quando si configura il connettore.
Passaggio 3a: Ricerca per indicizzazione completa (obbligatorio)
In questo passaggio viene configurata la query SQL che esegue una ricerca per indicizzazione completa del database. La ricerca per indicizzazione completa seleziona tutte le colonne o le proprietà in cui si desidera selezionare le opzioni Query, Search o Retrieve. È anche possibile specificare colonne ACL per limitare l'accesso dei risultati della ricerca a utenti o gruppi specifici.
Consiglio
Per ottenere tutte le colonne necessarie, è possibile unire più tabelle.

Selezionare colonne di dati (obbligatorio) e colonne ACL (facoltativo)
Nell'esempio viene illustrata la selezione di cinque colonne di dati che contengono i dati per la ricerca: OrderId, OrderTitle, OrderDesc, CreatedDateTime e IsDeleted. Per impostare le autorizzazioni di visualizzazione per ogni riga di dati, è possibile selezionare facoltativamente queste colonne ACL: AllowedUsers, AllowedGroups, DeniedUsers e DeniedGroups. Per tutte queste colonne di dati è possibile selezionare le opzioni Query, Search o Retrieve.
Selezionare le colonne di dati come illustrato in questa query di esempio: SELECT OrderId, OrderTitle, OrderDesc, AllowedUsers, AllowedGroups, DeniedUsers, DeniedGroups, CreatedDateTime, IsDeleted
Per gestire l'accesso ai risultati della ricerca, è possibile specificare una o più colonne ACL nella query. Il connettore SQL consente di controllare l'accesso a livello di record. È possibile scegliere di avere lo stesso controllo di accesso per tutti i record in una tabella. Se le informazioni ACL vengono archiviate in una tabella separata, potrebbe essere necessario eseguire un join con tali tabelle nella query.
L'uso di ognuna delle colonne ACL nella query precedente è descritto di seguito. L'elenco seguente illustra i quattro meccanismi di controllo di accesso.
- AllowedUsers: questa opzione specifica l'elenco di ID utente che potranno accedere ai risultati della ricerca. Nell'esempio seguente, elenco di utenti: john@contoso.com, keith@contoso.come lisa@contoso.com avrebbe accesso solo a un record con OrderId = 12.
- AllowedGroups: questa opzione specifica il gruppo di utenti che potranno accedere ai risultati della ricerca. Nell'esempio seguente, il gruppo sales-team@contoso.com avrebbe accesso al record solo con OrderId = 12.
- DeniedUsers: questa opzione specifica l'elenco di utenti che non hanno accesso ai risultati della ricerca. Nell'esempio seguente gli utenti john@contoso.com e keith@contoso.com non hanno accesso al record con OrderId = 13, mentre tutti gli altri utenti hanno accesso a questo record.
- DeniedGroups: questa opzione specifica il gruppo di utenti che non hanno accesso ai risultati della ricerca. Nell'esempio seguente i gruppi engg-team@contoso.com e pm-team@contoso.com non hanno accesso al record con OrderId = 15, mentre tutti gli altri utenti hanno accesso a questo record.

Tipi di dati supportati
La tabella seguente riepiloga i tipi di dati supportati dal connettore Oracle SQL. La tabella riepiloga anche il tipo di dati di indicizzazione per il tipo di dati SQL supportato. Per altre informazioni sui connettori di Microsoft Graph supportati dai tipi di dati per l'indicizzazione, vedere la documentazione sui tipi di risorse di proprietà.
| Categoria | Tipo di dati di origine | Tipo di dati di indicizzazione |
|---|---|---|
| Tipo di dati numero | NUMBER(p,0) | int64 (per p <= 18) double (per p > 18) |
| Tipo di dati numero a virgola mobile | NUMBER(p,s) FLOAT(p) |
doppio |
| Tipo di dati data | DATTERO TIMESTAMP TIMESTAMP(n) |
datetime |
| Tipo di dati carattere | CHAR(n) VARCHAR VARCHAR2 LUNGO CLOB NCLOB |
stringa |
| Tipo di dati carattere Unicode | NCHAR NVARCHAR |
stringa |
| Tipo di dati RowID | ROWID UROWID |
stringa |
Per qualsiasi altro tipo di dati attualmente non supportato direttamente, è necessario eseguire il cast esplicito della colonna a un tipo di dati supportato.
Filigrana (obbligatorio)
Per evitare l'overload del database, il connettore crea un batch e riprende le query con ricerca per indicizzazione completa con una colonna filigrana a ricerca per indicizzazione completa. Usando il valore della colonna filigrana, ogni batch successivo viene recuperato e l'esecuzione di query viene ripresa dall'ultimo checkpoint. Si tratta essenzialmente di un meccanismo per controllare l'aggiornamento dei dati per le ricerche per indicizzazione complete.
Creare frammenti di query per le filigrane, come illustrato negli esempi seguenti:
-
WHERE (CreatedDateTime > @watermark). Citare il nome della colonna filigrana con la parola chiave@watermarkriservata . È possibile ordinare la colonna filigrana solo in ordine crescente. -
ORDER BY CreatedDateTime ASC. Ordinare la colonna filigrana in ordine crescente.
Nella configurazione illustrata nell'immagine CreatedDateTime seguente è la colonna filigrana selezionata. Per recuperare il primo batch di righe, specificare il tipo di dati della colonna filigrana. In questo caso, il tipo di dati è DateTime.

La prima query recupera il primo numero N di righe usando: "CreatedDateTime > 1 gennaio 1753 00:00:00" (valore minimo del tipo di dati DateTime). Dopo il recupero del primo batch, il valore più alto di CreatedDateTime restituito nel batch viene salvato come checkpoint se le righe vengono ordinate in ordine crescente. Un esempio è il 1° marzo 2019 03:00:00. Il batch successivo di N righe viene quindi recuperato usando "CreatedDateTime > 1 marzo 2019 03:00:00" nella query.
Ignorare le righe eliminate temporaneamente (facoltativo)
Per escludere l'indicizzazione delle righe eliminate temporaneamente nel database, specificare il nome e il valore della colonna di eliminazione temporanea che indicano che la riga è stata eliminata.

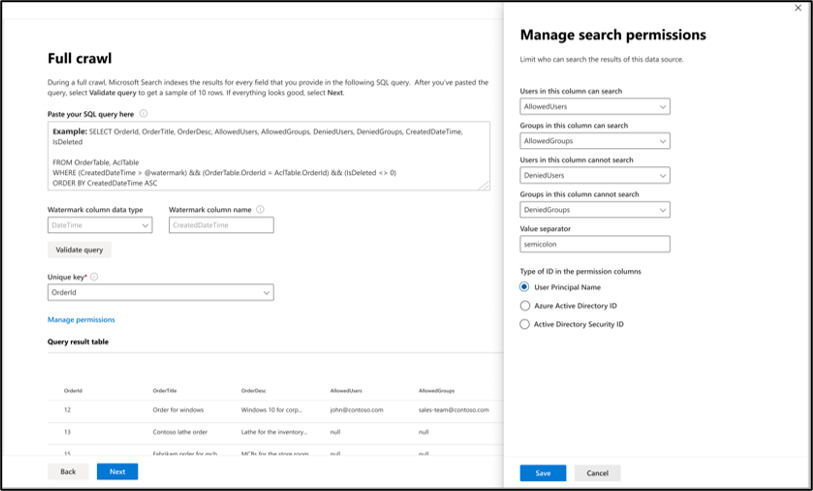
Ricerca per indicizzazione completa: gestire le autorizzazioni di ricerca
Selezionare Gestisci autorizzazioni per scegliere le varie colonne di controllo di accesso (ACL) che specificano il meccanismo di controllo di accesso. Selezionare il nome di colonna specificato nella query SQL per indicizzazione completa.
Ogni colonna ACL deve essere una colonna multivalore. Questi valori ID multipli possono essere separati da separatori, ad esempio punto e virgola (;), virgola (,) e così via. È necessario specificare questo separatore nel campo separatore di valori .
I tipi di ID seguenti sono supportati per l'uso come ACL:
- Nome entità utente (UPN): un nome dell'entità utente (UPN) è il nome di un utente di sistema in formato indirizzo di posta elettronica. Un UPN (ad esempio: john.doe@domain.com) è costituito dal nome utente (nome di accesso), dal separatore (simbolo @) e dal nome di dominio (suffisso UPN).
- Microsoft Entra ID: in Microsoft Entra ID, ogni utente o gruppo ha un ID oggetto simile a "e0d3ad3d-0000-1111-2222-3c5f5c52ab9b"
- ID di sicurezza di Active Directory (AD): in un'installazione di Active Directory locale, ogni utente e gruppo ha un identificatore di sicurezza univoco non modificabile simile a "S-1-5-21-3878594291-2115959936-132693609-65242".
Passaggio 3b: Ricerca per indicizzazione incrementale (facoltativo)
In questo passaggio facoltativo specificare una query SQL per eseguire una ricerca per indicizzazione incrementale del database. Con questa query, il connettore SQL determina eventuali modifiche ai dati dopo l'ultima ricerca per indicizzazione incrementale. Come nella ricerca per indicizzazione completa, selezionare tra le opzioni Query, Search o Retrieve. Specificare lo stesso set di colonne ACL specificato nella query di ricerca per indicizzazione completa.
I componenti nell'immagine seguente sono simili ai componenti di ricerca per indicizzazione completi con un'eccezione. In questo caso, "ModifiedDateTime" è la colonna di filigrana selezionata. Esaminare i passaggi completi della ricerca per indicizzazione per informazioni su come scrivere la query di ricerca per indicizzazione incrementale e vedere l'immagine seguente come esempio.

Passaggio 4: Assegnare etichette di proprietà
Seguire le istruzioni di configurazione generali.
Passaggio 5: Gestire lo schema
Seguire le istruzioni di configurazione generali.
Passaggio 6: Gestire le autorizzazioni di ricerca
È possibile scegliere di usare gli ACL specificati nella schermata di ricerca per indicizzazione completa oppure eseguirne l'override per rendere visibile il contenuto a tutti.
Passaggio 7: Scegliere le impostazioni di aggiornamento
Il connettore Oracle SQL supporta pianificazioni di aggiornamento sia per le ricerche per indicizzazione complete che per le ricerche per indicizzazione incrementali. È consigliabile impostare entrambi.
Una pianificazione di ricerca per indicizzazione completa trova le righe eliminate sincronizzate in precedenza con l'indice di Microsoft Search e tutte le righe spostate al di fuori del filtro di sincronizzazione. Quando ci si connette per la prima volta al database, viene eseguita una ricerca per indicizzazione completa per sincronizzare tutte le righe recuperate dalla query di ricerca per indicizzazione completa. Per sincronizzare le nuove righe e apportare aggiornamenti, è necessario pianificare ricerche per indicizzazione incrementali.
Passaggio 8: Esaminare la connessione
Seguire le istruzioni di configurazione generali.
Limitazioni
Il connettore Oracle SQL presenta queste limitazioni nella versione di anteprima:
- Il database locale deve eseguire Oracle Database versione 11g o successiva.
- Gli elenchi di controllo di accesso sono supportati solo tramite un nome dell'entità utente (UPN), Microsoft Entra ID o sicurezza di Active Directory.
- L'indicizzazione di contenuto avanzato all'interno di colonne di database non è supportata. Esempi di tali contenuti sono HTML, JSON, XML, BLOB e analisi di documenti esistenti come collegamenti all'interno delle colonne del database.
Risoluzione dei problemi
Dopo aver pubblicato la connessione, è possibile esaminare lo stato nella scheda Origini datinell'interfaccia di amministrazione. Per informazioni su come eseguire aggiornamenti ed eliminazioni, vedere Gestire il connettore. È possibile trovare i passaggi per la risoluzione dei problemi più comuni qui.
Se si verificano altri problemi o si vuole fornire commenti e suggerimenti, scrivere aka.ms/TalkToGraphConnectors.