Connettore CSV generico - Guida di riferimento tecnico (anteprima)
Questo articolo descrive il connettore GENERIC CSV (GCSV). L'articolo si applica ai prodotti seguenti:
- Microsoft Entra Connect Provisioning Agent (ECMA2Host)
- Microsoft Identity Manager 2016 (MIM2016)
Per MIM 2016, il connettore è disponibile come download dal Microsoft Download Center .
Per vedere questo connettore in azione, consultare l'articolo passo dopo passo del connettore SQL generico .
Nota
Il servizio di provisioning di Azure AD offre ora una soluzione semplice basata su agenti per il provisioning degli utenti nel formato CSV, senza un'implementazione completa della sincronizzazione MIM. È consigliabile valutare se soddisfa le proprie esigenze. Altre informazioni.
Panoramica del connettore CSV generico
Il connettore GENERIC CSV (GCSV) consente di integrare i dati di identità utente e di gruppo gestiti in file CSV con prodotti Microsoft, ad esempio Microsoft Entra Connect Provisioning Agent (ECMA2Host) e Microsoft Identity Manager 2016 (MIM2016).
Include diverse funzionalità, ad esempio la possibilità di orchestrare l'uso di PowerShell per gestire i dati di identità prima o dopo le importazioni o le esportazioni. Offre il supporto per più tipi di dati, inclusi i riferimenti e binari, il supporto per i valori di stringa qualificati e le stringhe multivalore.
Questo articolo descrive le funzionalità e le funzioni del connettore CSV generico e come configurarlo per MIM 2016.
Nella tabella seguente sono elencate le funzionalità supportate dalla versione corrente del connettore, dal punto di vista generale:
| Caratteristica | Dettagli |
|---|---|
| Supporto per più prodotti | L'uso di questo connettore è supportato con i prodotti Microsoft seguenti: |
| File CSV supportati | Questo connettore supporta la gestione di utenti (obbligatori) e gruppi (facoltativi), tramite la configurazione di un massimo di tre file CSV: |
| Elaborazione pre/post-operazione con PowerShell | Questo connettore supporta la configurazione di un massimo di quattro (4) script di PowerShell per facilitare l'elaborazione preliminare o post-elaborazione dei dati di identità utente e gruppo prima o dopo le importazioni o le esportazioni. |
| Codifica supportata per file CSV | Il connettore supporta tutti i tipi di codifica server predefiniti (o installati): (ad esempio Unicode, UTF-8, UTF-7, ASCII e così via) |
| Tipi di dati dei campi CSV supportati | Il connettore supporta i tipi di dati degli attributi seguenti: |
| Delimitazione di campi CSV | Supporto per virgole (,) o qualsiasi carattere alfamerico stampabile per qualificare l'inizio e la fine di qualsiasi valore stringa. |
| Supporto per la qualificazione di stringhe | Supporto per virgolette doppie (") o qualsiasi carattere alfamerico stampabile per qualificare l'inizio e la fine di qualsiasi valore stringa. |
| Supporto di stringhe multivalore | Supporto per stringhe multivalore |
| Operazioni del connettore supportate | Il connettore supporta le operazioni seguenti: |
| Schema | L'individuazione dello schema è dinamica, ma richiede la configurazione manuale per il completamento. I campi vengono identificati dinamicamente in base a un delimitatore specificato (o noto come "Separatore valore". I tipi di dati dei campi vengono designati manualmente durante la configurazione. |
Prerequisiti
Prima di usare il connettore, assicurarsi di disporre degli elementi seguenti nel server di sincronizzazione:
- Microsoft .NET 4.6.2 Framework o versione successiva
- File CSV che contengono lo schema desiderato per i tipi di identità seguenti:
- file utenti (obbligatorio)
- Gruppi (facoltativo)
- Membri del gruppo (obbligatorio se vengono usati i gruppi)
- (Facoltativo) Script di PowerShell per gestire l'elaborazione preliminare e post-elaborazione per gli eventi operation types seguenti:
- Pre-importazione: questo script viene eseguito prima dell'esecuzione di un'operazione di importazione.
- Post-Importazione: questo script viene eseguito dopo l'esecuzione di un'operazione di importazione.
- Pre-Esportazione: questo script viene eseguito prima dell'esecuzione di un'operazione di esportazione.
- Post-Esportazione: questo script viene eseguito dopo l'esecuzione di un'operazione di esportazione.
Autorizzazioni dell'account del servizio di sincronizzazione MIM
Importante
L'account del servizio di sincronizzazione MIM 2016 è il contesto di sicurezza che effettua le operazioni sui file CSV ed esegue gli script di PowerShell di pre-elaborazione e post-elaborazione. Questo account del servizio richiede autorizzazioni di lettura/scrittura per tutti i file CSV e PowerShell configurati. Sono necessarie anche le autorizzazioni di ExecutePolicy di PowerShell appropriate per eseguire tutti gli script configurati.
Creare un nuovo connettore
L'elenco seguente è una panoramica generale dei passaggi descritti in questa guida. Per iniziare, è necessario usare un account con il ruolo di amministratore di sincronizzazione MIM per eseguire queste attività:
- Apri la finestra Crea nuovo agente di gestione (MA) da MIM Sync Service Manager.
- Selezionare il connettore CSV generico come tipo di connettore.
- Specificare il percorso e il nome del file CSV da importare o esportare.
- Specificare la codifica dei file, il separatore di valori, il separatore multivalore e il qualificatore di testo per il file CSV.
- Scegliere se usare o meno i valori nella prima riga come campi di intestazione.
- Selezionare i tipi di oggetto e gli attributi da importare o esportare dal file CSV.
- Configurare la partizione, il profilo di esecuzione e i dettagli del mapping per l'Agente di Gestione.
- Specificare i percorsi e i parametri degli script di PowerShell, se presenti.
- Esegui l'agente di gestione per eseguire le operazioni di importazione, sincronizzazione o esportazione.
Per creare un connettore CSV generico, in Servizio di Sincronizzazione selezionare Agente di Gestione e Crea. Selezionare il connettore CSV generico (Microsoft).
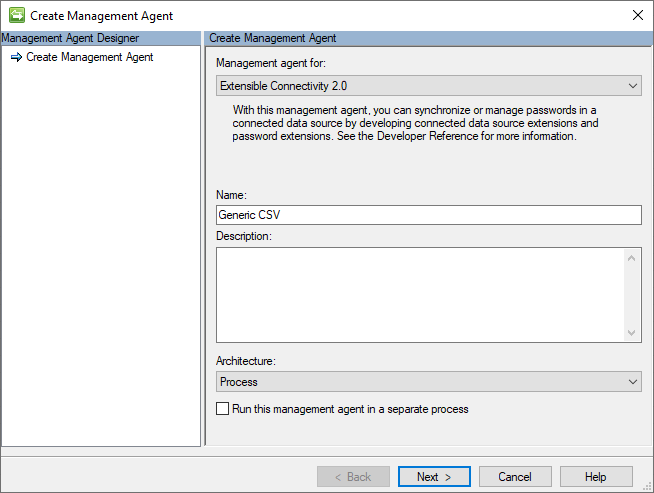
Connettività
La pagina Connettività contiene i percorsi dei file CSV Utenti, Gruppi e Membri del gruppo.
L'immagine seguente è un esempio della pagina connettività.
I percorsi dei file CSV seguenti sono specificati in questa pagina:
- Users File: percorso completo del file CSV che contiene i record utente e i relativi valori di attributo. Questo file è obbligatorio.
- gruppi file: percorso completo del file CSV che contiene i record di gruppo. Questo file è facoltativo.
- File membri: percorso completo del file CSV contenente i record di riferimento dei membri del gruppo.
Importante
L'account del servizio di sincronizzazione MIM deve avere le autorizzazioni di lettura e di scrittura per tutti i file CSV designati. Come accennato in precedenza, i file di gruppo e membro non sono necessari se sono configurati solo gli utenti.
La schermata Connettività è la prima quando si crea un nuovo connettore SQL generico. È prima necessario specificare le informazioni della sezione seguenti:
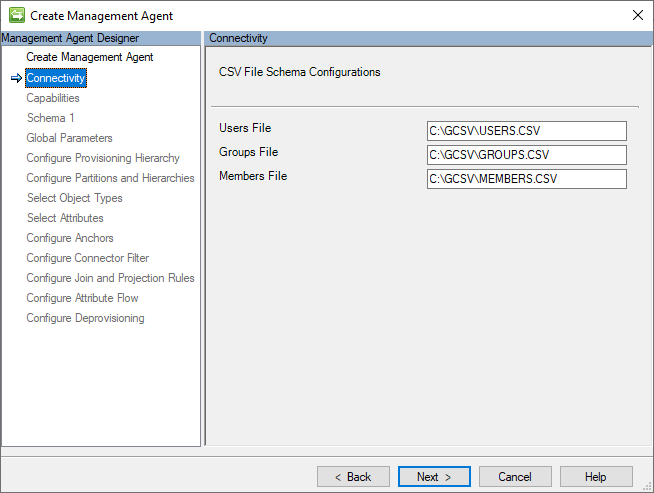
Funzionalità
Questa pagina descrive le funzionalità del connettore. Le funzionalità del connettore sono fisse e non possono essere modificate, ma sono illustrate qui per fornire informazioni sul funzionamento del connettore.
L'immagine seguente è un esempio della pagina Capacità .
La sezione seguente elenca le singole configurazioni e i relativi significati:
- Stile Nome Distinto (LDAP): Il connettore GCSV usa la sintassi LDAP (Lightweight Directory Access Protocol) per costruire il DN (Nome Distinto) per identificare in modo univoco ogni oggetto Utente o Gruppo nello spazio connettore. Tutti i valori DN sono espressi nel formato seguente: CN=[ANCHOR_VALUE],Object=[User|Group],O=CSV.
-
conferma oggetto (normale): in genere, il motore di sincronizzazione presuppone che possa recuperare nuovamente l'oggetto in un'importazione differenziale successiva dopo un'esportazione. Questo è il funzionamento del motore di sincronizzazione in genere, ma non tutti i sistemi connessi funzionano in questo modo. Questa impostazione di Normale assicura che non sia presente alcun avviso
exported-change-not-reimportednell'importazione di completamento. - Tipo di esportazione (MultivaluedReferenceAttributeUpdate): il tipo di esportazione specifica il modo in cui gli oggetti vengono formattati e inviati al sistema di destinazione durante la sincronizzazione. MultivaluedReferenceAttributeUpdate è un tipo di esportazione progettato per l'uso con Microsoft Entra ID. Invia solo gli attributi modificati. Per gli attributi di tipo valore, usa AttributeReplace e per gli attributi di riferimento, usa AttributeUpdate.
- normalizzazioni (Nessuna): le normalizzazioni fanno riferimento alla standardizzazione dei dati in un formato coerente. Nessuno significa che non vengono applicate regole di normalizzazione specifiche. I dati rimangono as-is senza alcuna trasformazione aggiuntiva da parte del connettore.
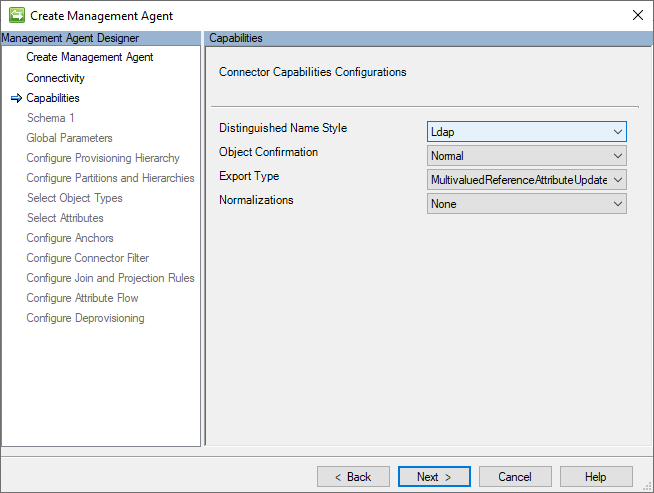
Schema 1 (configurazioni del formato di file CSV)
Il connettore GCSV usa tre tipi di separatori (o delimitatori) per delimitare e analizzare i campi CSV e i relativi valori.
Questa pagina contiene le impostazioni dei valori di carattere per questi separatori e il tipo di codifica usato per creare il file come CSV.
L'immagine seguente è un'immagine della pagina Schema 1 (Configurazioni del Formato di File CSV).
La sezione seguente è un elenco delle singole configurazioni:
- Usa intestazioni per l'individuazione dello schema: quando questa opzione è selezionata, indica al connettore di considerare il primo record di ogni file CSV come record di intestazione e non come record di dati identità. Se questa opzione non è selezionata, il connettore assegna il nome Attributo con un valore intero incrementato univoco aggiunto (ad esempio, Attributo1, Attributo2e così via) e considera la prima riga come record di dati di identità.
- separatore Valori: questo carattere separa i campi (ovvero i valori) dei record CSV. La virgola (,) è l'impostazione predefinita, ma è consentito qualsiasi carattere alfanumerico che può essere stampato.
- separatore multivalore: questo tipo di separatore viene usato per delimitare i singoli valori di una stringa multivalore (ad esempio, indirizzi proxy) o attributi di riferimento (ad esempio, subordinati). Il valore predefinito è un punto e virgola (;) ma qualsiasi carattere alfanumerico stampabile è accettabile.
- qualificatore di testo: quando un valore stringa contiene caratteri che altrimenti verrebbero interpretati come delimitatori (ad esempio, virgole), richiede che il valore sia qualificato in modo che il parser CSV possa interpretare correttamente la stringa come un singolo campo. Le virgolette doppie (") sono il valore predefinito, ma è consentito qualsiasi carattere alfanumerico che può essere stampato.
Nota
Sebbene gli schemi dei file CSV non contengano campi multivalore o non contengano valori che richiedono la qualificazione di stringa, è necessaria la designazione di un carattere stampabile univoco per ogni tipo di separatore.
- Codifica file: questa impostazione indica la codifica usata nei file CSV aggiunti nella scheda Connettività. Assicurarsi che corrisponda alla codifica dei file CSV.
Nota
Se non si è certi del tipo di codifica dei file CSV, provare a usare il tipo di codifica Unicode predefinito. Unicode è uno standard comune che supporta molti caratteri e simboli, rendendolo un'opzione valida per la codifica dei dati di testo nella maggior parte delle lingue o del set di caratteri.
Schema 2 (configurazioni dei campi Identity e Reference)
Il valore di ancoraggio è un identificatore univoco per un record in un file CSV. Distingue un record dagli altri. Il connettore GCSV usa anche questo valore per creare il nome distinto (DN) che identifica l'oggetto spazio connettore correlato.
In questa pagina vengono configurate le impostazioni dell'attributo di ancoraggio per ogni file CSV elencato nella pagina Connettività.
L'immagine seguente è un esempio della pagina Schema 2 (Configurazioni del Campo di Identità e Riferimento).
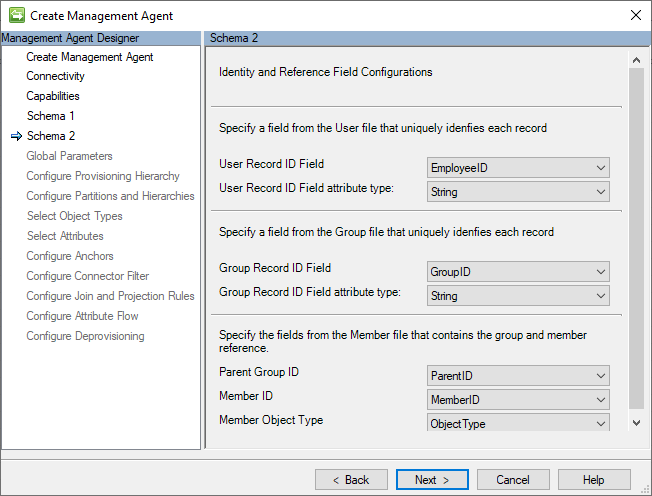
La sezione seguente è un elenco delle singole configurazioni in questa pagina:
-
Utente
- Ancoraggio utente: Il campo nel file Utenti che funge da valore di ancoraggio per il record utente. Il primo campo di intestazione nel file Users è la scelta predefinita.
- tipo di attributo di ancoraggio utente: Questo è il tipo di attributo dell'ancoraggio selezionato.
-
Gruppo
- group anchor: campo nel file Groups che funge da valore di ancoraggio per il record di gruppo. Il primo campo di intestazione nel file Groups è la scelta predefinita.
- Tipo di attributo di Group Anchor: Questo è il tipo di attributo dell'ancora selezionata.
-
membro
- ID gruppo padre: campo nel file Membri con lo stesso valore (ancoraggio) del gruppo padre nel file CSV Gruppi. Il primo campo nel file Members viene utilizzato per impostazione predefinita.
- ID membro: il campo nel file Membri con lo stesso valore (ancoraggio) del file CSV Utenti o gruppi. Il secondo campo nel file Membri è selezionato per impostazione predefinita.
- Tipo di oggetto membro: campo contenente un valore stringa "User" o "Group" per indicare il tipo di oggetto del membro. Questo campo è obbligatorio solo se il file membro contiene più di due campi. Il campo Tipo di oggetto deve contenere solo il valore stringa "User" o "Group". Se questo campo non è presente, il connettore presuppone che i record del file Members facciano riferimento a un membro dell'oggetto User. Il terzo campo trovato nel file Membri è selezionato per impostazione predefinita.
Importante
I nomi degli attributi designati come ancoraggi devono essere univoci in tutti gli schemi dei tipi di oggetto. Sono inclusi gli ancoraggi specificati nel file Membri del Gruppo.
Schema 3 (configurazioni dello schema degli attributi dei file degli utenti)
Questa pagina consente di specificare e spiegare il tipo di dati di ognuno dei campi identificati nello schema del file CSV Users e se possono avere più di un valore.
L'immagine seguente è un esempio della pagina dello Schema Schema 3 (configurazioni dello schema degli attributi dei file utenti).
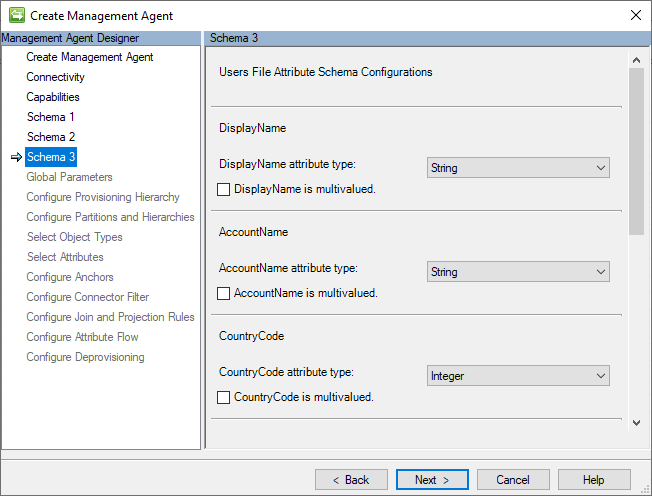
Nella sezione seguente sono elencate le considerazioni relative all'assegnazione dei tipi di dati dell'attributo.
Tipi di dati supportati
Il connettore GCSV supporta l'uso dei tipi di dati della sezione seguenti:
- booleano : valore che può essere true o false.
- binary: valore archiviato come sequenza di byte, in genere usato per archiviare dati come immagini o altri file.
- Integer: valore intero che rappresenta un numero intero, senza posizioni decimali.
- stringa: valore che è una sequenza di caratteri, in genere usato per archiviare i dati di testo.
- riferimento: valore che rappresenta un riferimento a un altro oggetto utente. Per specificare un valore di riferimento in un file CSV, popolare il relativo campo con il valore di ancoraggio dell'oggetto utente di riferimento.
Importante
Gli attributi di riferimento utente o gruppo possono essere usati solo per fare riferimento agli oggetti utente. Ciò non si applica all'attributo membro degli oggetti Group, che può contenere riferimenti a utenti o gruppi, purché venga specificato il campo del tipo di oggetto.
Tipi di dati Multiple-Value supportati
Il connettore supporta l'uso di attributi multivalore solo per i tipi di dati seguenti:
- Stringa
Nota
Se lo schema degli oggetti User e Group dispone entrambi di un attributo (non ancoraggio) con lo stesso nome, è possibile che non vengano assegnati tipi di dati diversi tra di essi. Entrambi devono condividere lo stesso tipo di dati.
Schema 4 (configurazioni dello schema degli attributi dei file di gruppi)
Questa pagina consente di specificare e spiegare il tipo di dati di ognuno dei campi identificati nello schema del file CSV Groups e se possono avere più di un valore.
L'immagine seguente è un esempio della pagina Schema Schema 4 (Configurazioni dello schema dell'attributo di file di gruppi).
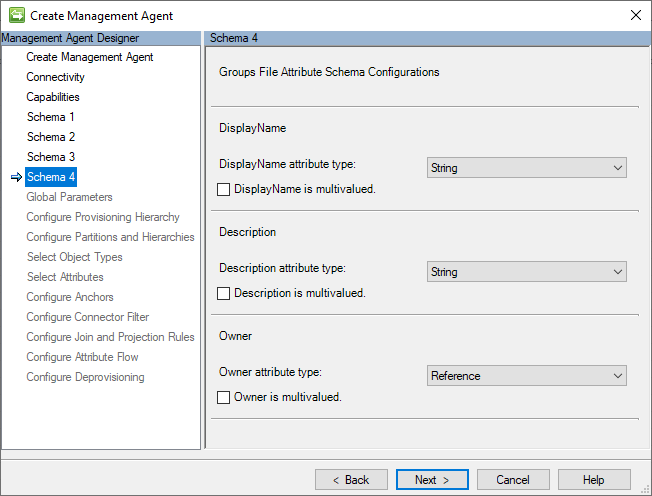
Le indicazioni disponibili in Schema 3 (Users File Attribute Configurations si applicano anche a questa sezione. .
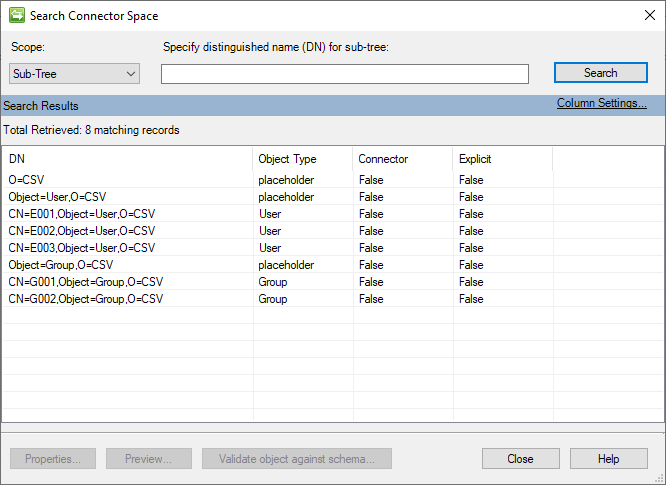
Dopo l'esecuzione di un'operazione di importazione completa iniziale, lo spazio connettore sarà simile all'immagine seguente:
Parametri globali (configurazione degli script di PowerShell)
Questa pagina consente la configurazione degli script di PowerShell che verranno eseguiti prima e/o dopo le operazioni di importazione e/o esportazione. Queste funzionalità offrono opportunità per eseguire un'ampia gamma di azioni di pre-e-post-elaborazione sui record di utenti e gruppi di identità.
L'immagine seguente è un esempio della pagina parametri globali.
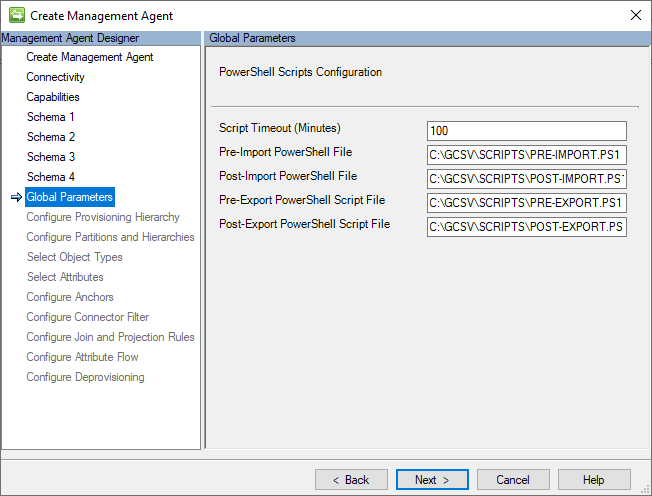
La sezione seguente elenca le singole impostazioni di configurazione in questa pagina:
- Tempo di attesa script (minuti): numero di minuti di esecuzione di uno script prima che venga interrotto automaticamente. Il valore predefinito per questa impostazione è 100 e richiede un valore maggiore di zero (0).
- file di script di pre-importazione: percorso completo dello script di PowerShell da eseguire prima di un'importazione. Questa impostazione è facoltativa e non richiede un valore.
- file di script post-importazione: percorso completo dello script di PowerShell che deve essere eseguito dopo un'importazione. Questa impostazione è facoltativa e non richiede un valore.
- file di script di pre-esportazione: percorso completo dello script di PowerShell da eseguire prima di un'esportazione. Questa impostazione è facoltativa e non richiede un valore.
- file di script post-esportazione: percorso completo dello script di PowerShell che deve essere eseguito dopo un'esportazione. Questa impostazione è facoltativa e non richiede un valore.
Parametri di input e esecuzione di script di PowerShell
Il connettore GCSV esegue ognuno degli script di PowerShell configurati nella propria sessione e non supporta il passaggio di parametri tra le fasi non è supportato.
Il connettore passa un parametro di input in ogni script denominato OperationType. Il valore di questo parametro varia a seconda dell'operazione Esegui profilo eseguita e può essere uno dei tre valori seguenti:
Importante
La creazione dinamica di file CSV prima delle operazioni di importazione o esportazione non è supportata. Tutti i file CSV devono essere presenti prima dell'esecuzione di tutti i profili di esecuzione.
Parametro di input di PowerShell: OperationType
Anche se l'uso dei parametri di input non è supportato, il connettore GCSV passa un parametro di input all'esecuzione di ogni script di PowerShell: OperationType.
- completo: questo valore viene fornito durante le operazioni di importazione completa o esportazione completa.
- delta: questo valore viene fornito durante le operazioni di esportazione.
Questo valore di parametro può essere usato all'interno della logica degli script di PowerShell per determinare l'operazione o l'azione di pre/post-elaborazione appropriata da eseguire.
Gerarchia di provisioning
Poiché i file CSV non archiviano informazioni in una struttura gerarchica, GCSV Connector non supporta alcuna configurazione di provisioning gerarchica.
La seguente immagine è un esempio della pagina Gerarchia di Provisioning.
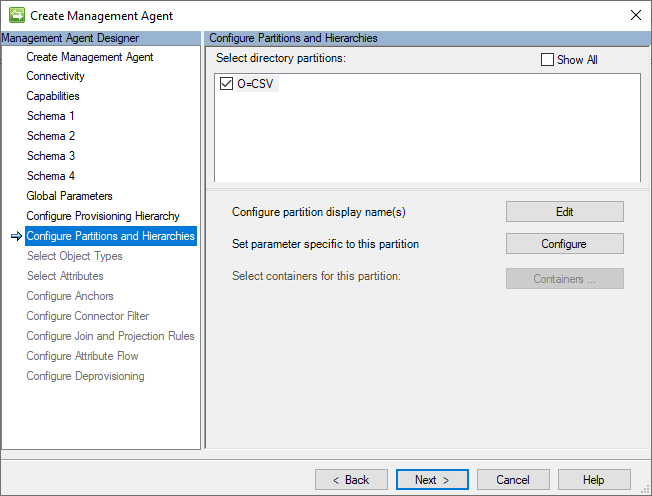
Partizioni e gerarchie
Il connettore GCSV compila un nome distinto distinto (DN) per ogni record utente e gruppo nello spazio connettore, seguendo questo formato LDAP:
CN=[ANCHOR_VALUE],Object=User|Group,O=CSV
L'immagine seguente è un esempio della pagina Partizioni e gerarchie.
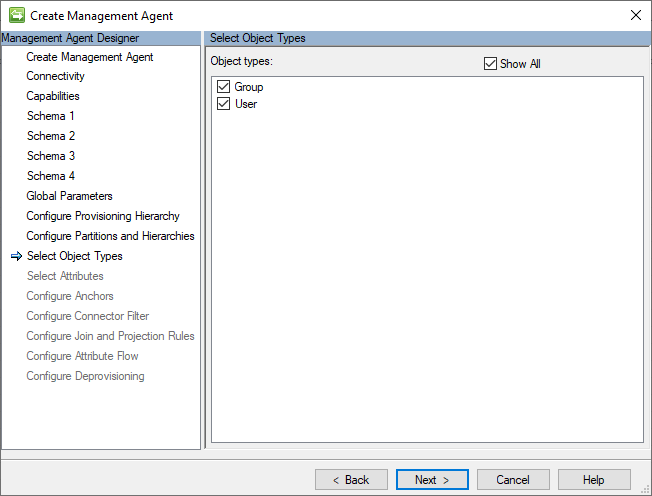
Tipi di oggetto
Il connettore GCSV richiede che sia selezionato almeno il tipo di oggetto User. La scelta del tipo di oggetto Group è facoltativa.
L'immagine seguente è un esempio della pagina Tipi di oggetto.
Attributi
In questa pagina viene visualizzato un elenco normalizzato di tutti gli attributi in tutti gli schemi dei tipi di oggetto selezionati.
L'immagine seguente è un esempio della pagina Attributi.
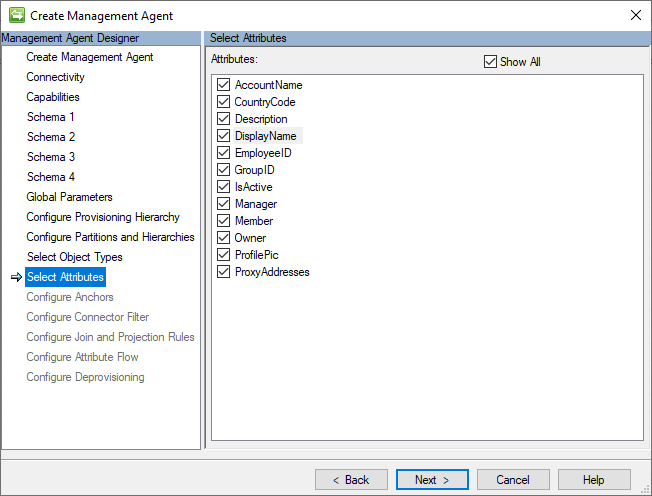
Nota
L'attributo Member esisterà solo se sono selezionati Gruppi e conterrà i riferimenti agli oggetti gestiti nei file CSV dei membri del gruppo.
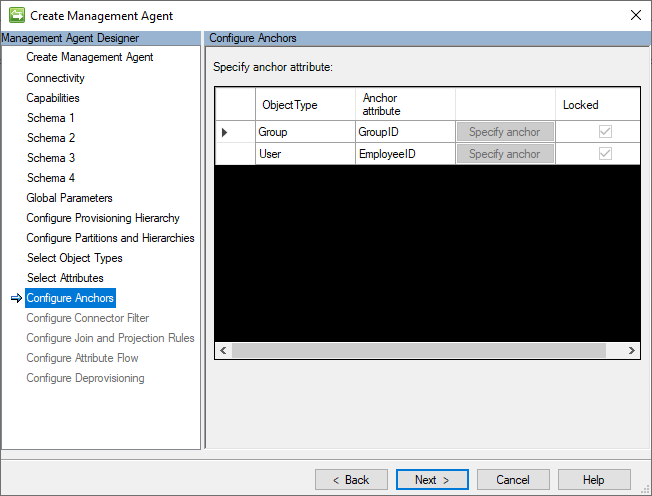
Ancore
Il connettore GCSV non supporta l'uso di ancoraggi complessi né configurazioni degli attributi di ancoraggio che differiscono dai campi ID di ancoraggio del file CSV corrispondente.
Per modificare le designazioni di ancoraggio visualizzate in questa pagina, tornare allo schema 2 (configurazioni di ancoraggio).
L'immagine seguente è un esempio della pagina ancoraggi di .
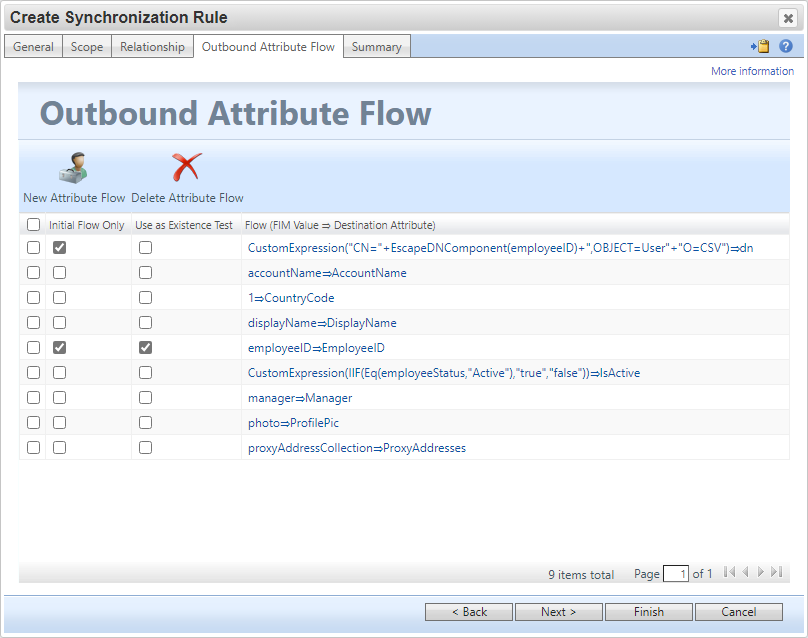
Provisioning di record CSV
Per consentire al connettore GCSV di aggiungere nuovi oggetti User o Group nei file CSV corrispondenti, è necessario eseguirne il provisioning in un nuovo oggetto Spazio connettore.
Se si usa il provisioning dichiarativo di MIM 2016 o si scrivono estensioni delle Regole di Sincronizzazione di MIM , i nuovi oggetti Spazio connettore devono avere un DN costruito usando il formato seguente:
CN=[ANCHOR_VALUE],Object=User|Group,O=CSV
La tabella seguente fornisce informazioni dettagliate su ognuno dei valori dei componenti:
| Componente | Note |
|---|---|
| CN=[ANCHOR VALUE] | Il nome comune (CN) deve essere un valore univoco in e verrà scritto nel campo di ancoraggio designato del file CSV. |
| Oggetto=Utente/Gruppo | Questo componente indica il tipo di oggetto di questo connettore. Supporta solo "user" o "Group". |
| O=CSV | Il componente radice comune a tutti gli oggetti dello spazio connettore GCSV. |
L'immagine seguente è una regola di sincronizzazione che illustra come costruire correttamente un DN durante la fornitura di un nuovo oggetto User in un connettore GCSV.
Il codice seguente illustra la logica di provisioning equivalente usando Metaverse Rules Extensions.
void IMVSynchronization.Provision(MVEntry mventry)
{
if (mventry["employeeID"].IsPresent)
{
ConnectedMA GCSVConnector = = mventry.ConnectedMAs["Generic CSV Conenctor"];
if (GCSVConnector.Connectors.Count == 0)
{
CSEntry csentry = GCSVConnector.Connectors.StartNewConnector("user");
//Sets DN to "CN=[ANCHOR_VALUE],OBJECT=[User|Group],O=CSV"
csentry.DN = GCSVConnector.EscapeDNComponent("CN=" + mventry["employeeID"].Value).Concat("OBJECT=User,O=CSV");
csentry["AccountName"].StringValue = mventry["accountName"].StringValue;
csentry["CountryCode"].IntegerValue = 1;
csentry["DisplayName"].Value = mventry["displayName"].Value;
csentry["ProxyAddresses"].Value = mventry["proxyAddressCollection"].Value;
csentry["IsActive"].BooleanValue = true;
csentry["Manager"].Value = mventry["manager"].Value;
csentry["ProfilePic"].Value = mventry["pic"].Value;
csentry.CommitNewConnector();
}
}
}
Nell'immagine precedente si noti l'uso della funzione EcapeDNComponent() per assicurarsi che il valore di ancoraggio sia correttamente sottoposto a escape per essere conforme alla sintassi LDAP.
Importante
Una gestione scorretta del valore di escape durante la costruzione di un DN genererà un errore invalid‑dn.
Esempi di formattazione dei campi CSV
Le sezioni seguenti elencano esempi di come formattare tipi di dati diversi nei file CSV. Tutti gli esempi La sezione seguente presuppone l'uso delle impostazioni predefinite del delimitatore di campo del connettore:
- Valore separato: virgola (,)
- Separatore multivalore: Semi-Colon (;)
- Qualificatore di testo: virgolette doppie (")
Esempio: Qualificazione del testo
Se un valore stringa contiene caratteri che altrimenti verrebbero interpretati come delimitatori (ad esempio, virgole), è necessario che il valore sia qualificato in modo che il parser CSV possa interpretare correttamente la stringa come un singolo campo.
L'esempio CSV della sezione seguente illustra come il campo displayName ha valori formattati come testo completo:
EmployeeID,DisplayName
E001,"Smith, John"
E002,"Doe, Jane"
E003,"Perez, Juan"
Esempio: Delimitazione di stringhe multivalore
Per fornire più valori stringa all'interno di un campo stringa, delimitare i valori con il separatore multivalore . L'esempio CSV della sezione seguente illustra come viene utilizzato il campo ProxyAddress con più valori:
EmployeeID,DisplayName,ProxyAddresses
E001,"Smith, John",SMTP:john.smith@contoso.com;smtp:js001@contoso.com
E002,"Doe, Jane",SMTP:jane.doe@contoso.com;smtp:jd002@contoso.com
Nota
Stringa multivalore supporta anche l'uso di valori qualificati di stringa. I valori qualificati di testo possono essere delimitati da separatori di valori multipli.
Esempio: Campi di riferimento
Per specificare un valore di riferimento in un file CSV, popolare il relativo campo con il valore di ancoraggio dell'oggetto utente di riferimento. Nell'esempio CSV della sezione seguente il campo Manager contiene il valore di ancoraggio del record utente a cui fa riferimento:
EmployeeID,DisplayName,Manager
E001,"Smith, John",
E002,"Doe, Jane",E001
E003,"Doe, Jane",
E004,"Perez, Juan",
Esempio: Campi binari
Per esprimere i valori binari nei file CSV, è necessario convertirli in stringhe base64 che usano lo stesso tipo di codifica del file CSV. La sezione seguente della funzione di PowerShell illustra come codificare un valore stringa nella stringa con codifica Base64 in Unicode:
function ConvertTo-Base64([string]$text)
{
$bytes = [System.Text.Encoding]::Unicode.GetBytes($text)
$encodedText = [System.Convert]::ToBase64String($bytes)
return $encodedText
}
Ecco la funzione equivalente in C# che accetta un parametro di input denominato text e restituisce una stringa con codifica Base64 in Unicode.
public static string ConvertToBase64(string text)
{
byte[] bytes = System.Text.Encoding.UTF8.GetBytes(text);
string encodedText = System.Convert.ToBase64String(bytes);
return encodedText;
}
Esempio: Campi booleani
I file CSV che contengono campi booleani devono usare il testo True o False per indicare il valore. La sezione seguente è un
EmployeeID,DisplayName,IsActive
E001,"Smith, John",true
E002,"Doe, Jane",true
E003,"Perez, Juan",false
Limitazioni note
L'elenco seguente contiene le limitazioni note del connettore GCSV.
-
attributi di riferimento
- Oltre all'attributo del gruppo e del membro, gli attributi di riferimento multivalore non vengono supportati.
- Il valore di riferimento deve fare riferimento agli oggetti utente. I riferimenti agli oggetti gruppo non sono supportati.
-
ancoraggi
- I valori di ancoraggio duplicati tra gli oggetti utente e gruppo non sono supportati.
- I nomi degli attributi di ancoraggio devono essere univoci tra gli schemi utente e di gruppo.
-
PowerShell
- Il passaggio di variabili di input negli script di PowerShell non è supportato.