Preparare set di dati pubblici in Set di dati SDOH - Trasformazioni (anteprima)
[Questo articolo fa parte della documentazione non definitiva, pertanto è soggetto a modifiche.]
I set di dati pubblici SDOH contengono dati aggregati di determinanti sociali della salute (SDOH) pubblicati da agenzie governative e altre fonti ufficiali come le università. Questi set di dati consolidano vari parametri SDOH a livello geografico come stato, contea o codice postale. Set di dati SDOH - Trasformazioni (anteprima) consente di inserire questi set di dati a livello geografico nei formati CSV (valori separatyi da virgole) o XLSX (foglio di calcolo Excel Open XML) e di normalizzarli in un modello di dati personalizzato.
La versione di anteprima fornisce i seguenti otto set di dati SDOH di esempio di vari domini SDOH per aiutarti a eseguire pipeline di dati ed esplorare le trasformazioni dei dati tramite i livelli di lakehouse Bronze, Silver e Gold:
Atlante dell'ambiente alimentare dell'USDA: include fattori come la vicinanza di negozi/ristoranti, prezzi degli alimenti, programmi di assistenza nutrizionale e caratteristiche della comunità. Questi fattori influenzano le scelte alimentari, la qualità della dieta e, in ultima analisi, i risultati sulla salute.
Atlante rurale dell'USDA: offre statistiche su fattori socio-economici come persone, professioni, classificazioni delle contee, reddito e veterani.
Dati SDOH di AHRQ: fornisce dettagli su cinque domini SDOH principali:
- Contesto sociale, come età, razza/etnia, stato di veterano.
- Contesto economico, come reddito, tasso di disoccupazione.
- Istruzione
- Infrastrutture fisiche, come alloggi, criminalità, trasporti.
- Contesto sanitario, come assicurazione sanitaria.
Indice di accessibilità della posizione: stima i costi relativi ad alloggio e trasporti delle famiglie a livello di quartiere.
Indice di giustizia ambientale: aggrega dati provenienti da più fonti per classificare gli impatti cumulativi dell'ingiustizia ambientale sulla salute per ogni area censuaria.
Obiettivo educativo ACS: fornisce informazioni dettagliate sull'istruzione per aree geografiche, derivate da un'ampia indagine demografica in corso.
Indici SEIFA australiani: combina i dati del censimento australiano come reddito, istruzione, occupazione e alloggio per riassumere le caratteristiche socio-economiche di un'area.
Indici di deprivazione del Regno Unito: una misura socio-economica ampiamente utilizzata nel Regno Unito per valutare la povertà in piccole aree e che copre varie dimensioni.
Dove:
- USDA: dipartimento dell'agricoltura degli Stati Uniti
- AHRQ: agenzia per la ricerca e la qualità dell'assistenza sanitaria
- ACS: indagine sulla comunità americana
- SEIFA: indici socio-economici per aree
Importante
Questi set di dati non sono solo esempi ma set di dati completi e reali pubblicati dalle rispettive organizzazioni. Forniscono una rappresentazione accurata dei profili SDOH delle rispettive aree geografiche. Fai attenzione quando li modifichi, poiché sono pubblicazioni ufficiali di agenzie federali.
Struttura di cartelle
La zona di destinazione per Set di dati SDOH - Trasformazioni (anteprima) comprende tre cartelle: Ingest, Process e Failed. Per altre informazioni su queste cartelle, vedi Struttura di cartelle unificata.
Preparare i set di dati SDOH prima dell'inserimento
Prima di inserire set di dati pubblici SDOH, assicurati che siano pronti per essere inseriti correttamente. Le sezioni seguenti delineano due scenari:
- Utilizzare il proprio set di dati
- Utilizzare il set di dati di esempio
Utilizzare il proprio set di dati
I set di dati pubblici SDOH variano in modo significativo tra le organizzazioni editoriali in termini di formato, volume e struttura. Non hanno uno standard stabilito per la raccolta e lo scambio delle informazioni acquisite. Pertanto, unificarli in una forma comune è essenziale prima di rappresentarli in un modello di dati.
Per inserire e trasformare un set di dati pubblico SDOH di tua scelta, aggiungi le seguenti tre informazioni chiave:
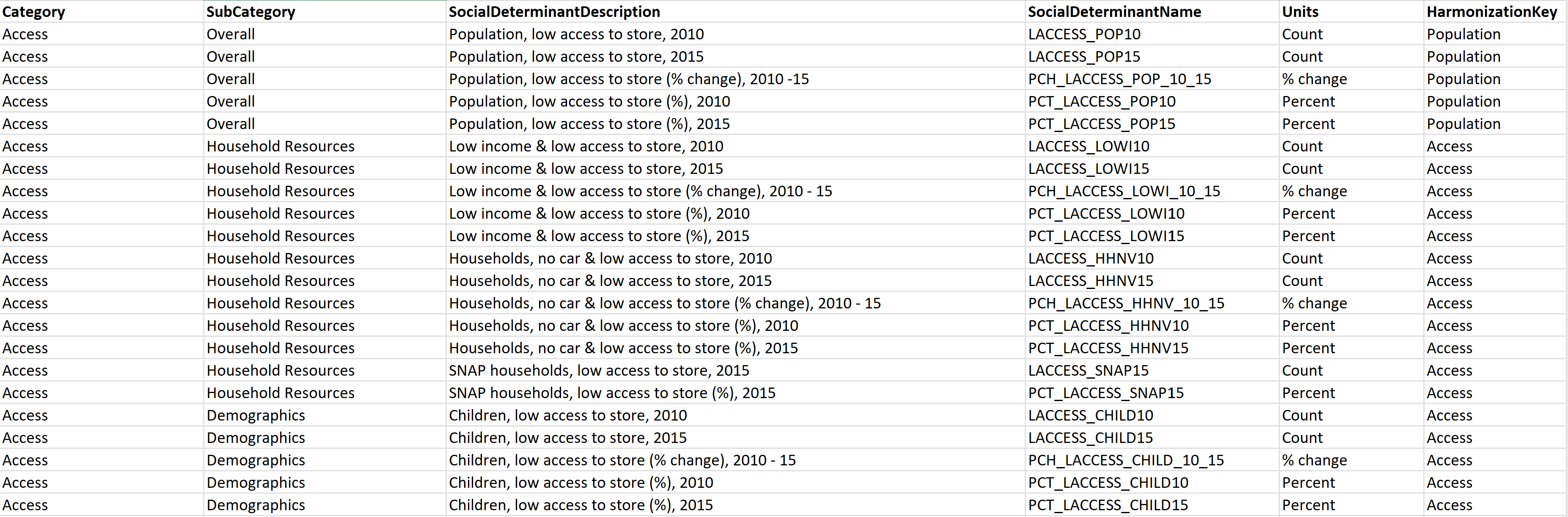
Layout: a causa dell'assenza di un set standard di codici per l'acquisizione di dati SDOH, la comprensione del significato di ciascun campo è complessa. Per risolvere questo problema, crea un dizionario di dati per il set di dati aggiungendo un nuovo foglio denominato Layout (se il set di dati è in formato XLSX) o crea un nuovo file CSV (se il set di dati è in formato CSV) con le colonne visualizzate nell'esempio seguente:
DataSetMetadata: poiché i set di dati SDOH provengono da editori diversi, la registrazione dei dettagli chiave relativi al set di dati è fondamentale. Aggiungi un nuovo foglio denominato DataSetMetadata (se il tou set di dati è in formato XLSX) o crea un nuovo file CSV (se il set di dati è in formato CSV) con le colonne visualizzate nell'esempio seguente:

LocationConfiguration: diverse aree geografiche definiscono e organizzano i dati sulla posizione in vari modi. Per aiutare le pipeline SDOH a comprendere la struttura geografica del set di dati, aggiungi un nuovo foglio denominato LocationConfiguration (se il set di dati è in formato XLSX) o crea un nuovo file CSV (se il set di dati è in formato CSV) con le colonne visualizzate nell'esempio seguente:
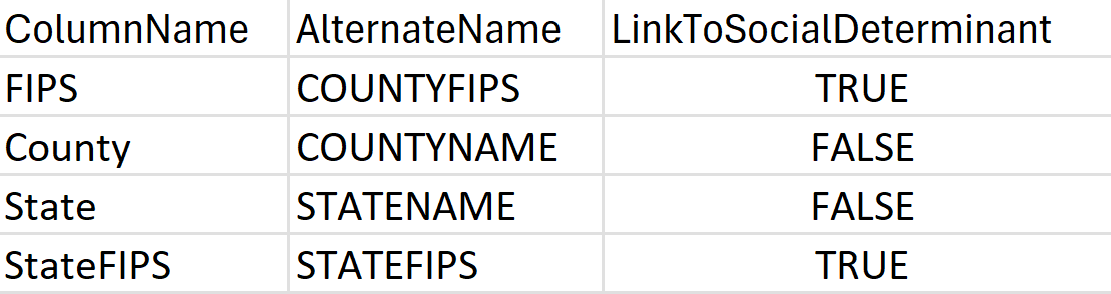



Inoltre:
- Puoi fare riferimento alla struttura dei set di dati SDOH di esempio per popolare le informazioni necessarie, ad esempio la categoria dei determinanti sociali, metadati e la chiave di armonizzazione.
- Se preferisci non inserire determinati campi dal set di dati originale, rimuovili dal foglio dati o lascia vuoti i relativi dettagli nel foglio di layout. In entrambi i casi, non sono inclusi nel modello di dati Silver.
- I set di dati con lo stesso nome, data di pubblicazione ed editore vengono trattati come duplicati.
Utilizzare il set di dati di esempio
I set di dati SDOH di esempio forniti con le soluzioni per dati sanitari sono precompilati con tutte le informazioni preliminari e sono disponibili in OneLake. Puoi estrarli localmente.
Caricare i set di dati nell'area di lavoro Fabric
Quando i set di dati sono pronti, scegli una delle due opzioni seguenti per caricarli. Puoi usare l'opzione 2 solo se usi il set di dati di esempio fornito con Set di dati SDOH - Trasformazioni (anteprima).
- Opzione 1: caricare manualmente i set di dati.
- Opzione 2: utilizzare uno script per caricare i set di dati.
Caricare manualmente i set di dati
Nel tuo ambiente di soluzioni per dati sanitari, seleziona il lakehouse healthcare#_msft_bronze.
Aprire la cartella Ingest. Per altre informazioni, vedi Descrizioni delle cartelle.
Seleziona i puntini di sospensione (...) accanto al nome della cartella e seleziona Carica cartella.
Caricare i set di dati dal sistema locale. Usa Esplora dati di OneLake per trovare i set di dati nel seguente percorso:
<workspace name>\healthcare#.HealthDataManager\DMHSampleData\8SdohPublicDataset.Aggiorna la cartella Ingest. Ora dovresti vedere i file del set di dati nella sottocartella SDOH.
Utilizzare uno script per caricare i set di dati
Importante
Usa questa opzione solo se stai usando il set di dati di esempio fornito.
Vai all'area di lavoro Fabric delle soluzioni per dati sanitari.
Seleziona + Nuovo elemento.
Nel riquadro Nuovo elemento cerca e seleziona Notebook.
Copia e incolla il seguente frammento di codice nel layout.
workspace_id = '<workspace_id>' # Workspace ID. Retrieve the value from the healthcare#_msft_config_notebook. one_lake_endpoint = "<OneLake_endpoint>" # OneLake endpoint. Retrieve the value from the healthcare#_msft_config_notebook. solution_id = "<solution_id>" # Solution ID. Retrieve the value from the healthcare#_msft_config_notebook. bronze_lakehouse_id = "<bronze_lakehouse_id>" # To locate the bronze lakehouse ID, open the bronze lakehouse and check the URL in the browser's address bar: https://{baseurl}/lakehouse/{GUID}/details). The {GUID} value in the URL is the bronze lakehouse ID. def copy_source_files_and_folders(source_path, destination_path): # List the contents of the source directory source_contents = mssparkutils.fs.ls(source_path) # List the contents of the destination directory try: destination_contents = mssparkutils.fs.ls(destination_path) destination_files = {item.path.split('/')[-1]: item.path for item in destination_contents} except Exception as e: print(f"Destination path {destination_path} does not exist or is empty. Creating the path.") destination_files = {} mssparkutils.fs.mkdirs(destination_path) # Copy each item inside the source directory to the destination directory for item in source_contents: item_path = item.path item_name = item_path.split('/')[-1] destination_item_path = f"{destination_path}/{item_name}" if item.isDir: # Recursively copy the contents of the directory copy_source_files_and_folders(item_path, destination_item_path) else: if item_name in destination_files: print(f"File already exists, skipping: {destination_item_path}") else: print(f"Creating new file: {destination_item_path}") mssparkutils.fs.cp(item_path, destination_item_path, recurse=True) # Define the source and destination paths with placeholder values data_manager_solution_path = f"abfss://{workspace_id}@{one_lake_endpoint}/{solution_id}" data_manager_sample_data_path = f"{data_manager_solution_path}/DMHSampleData" sdoh_csv_data_path = f"{data_manager_sample_data_path}/8SdohPublicDataset/csv" sdoh_xlsx_data_path = f"{data_manager_sample_data_path}/8SdohPublicDataset/xlsx" destination_path_csv = f"abfss://{workspace_id}@{one_lake_endpoint}/{bronze_lakehouse_id}/Files/Ingest/SDOH/CSV" destination_path_xlsx = f"abfss://{workspace_id}@{one_lake_endpoint}/{bronze_lakehouse_id}/Files/Ingest/SDOH/XLSX" # Copy the files along with their parent folders copy_source_files_and_folders(sdoh_csv_data_path, destination_path_csv) copy_source_files_and_folders(sdoh_xlsx_data_path, destination_path_xlsx)Esegui il notebook. I set di dati SDOH di esempio vengono ora spostati nella posizione designata nella cartella Ingest.
I set di dati SDOH sono ora pronti per l'inserimento.