Rilevamento anomalie multivariato
Per informazioni generali sul rilevamento anomalie multivariato in Intelligence in tempo reale, vedere Rilevamento anomalie multivariato in Microsoft Fabric - panoramica. In questa esercitazione si usano dati di esempio per eseguire il training di un modello di rilevamento anomalie multivariato usando il motore Spark in un notebook Python. Si stimano quindi le anomalie applicando il modello sottoposto a training ai nuovi dati usando il motore Eventhouse. I primi passaggi consentono di configurare gli ambienti e i passaggi seguenti eseguono il training del modello e stimano le anomalie.
Prerequisiti
- Un'area di lavoro con una capacità abilitata per Microsoft Fabric
- Ruolo di Amministratore, Membro o Collaboratore nell'area di lavoro. Questo livello di autorizzazione è necessario per creare elementi come un ambiente.
- Una eventhouse nell'area di lavoro con database.
- Scaricare il file di dati di esempio dal repository di GitHub
- Scarica il notebook dal Repository di GitHub
Parte 1- Abilitare la disponibilità di OneLake
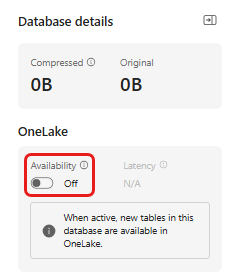
La disponibilità di OneLake deve essere abilitata prima di ottenere i dati nell’Eventhouse. Questo passaggio è importante perché consente di rendere disponibili i dati inseriti in OneLake. In un passaggio successivo si accede a questi stessi dati dal notebook di Spark per eseguire il training del modello.
Dal tuo spazio di lavoro, seleziona l'Eventhouse che hai creato nei prerequisiti. Scegliere il database in cui archiviare i dati.
Nel riquadro dettagli database di impostare il pulsante di disponibilità di OneLake su On.
Parte 2- Abilitare il plug-in Python KQL
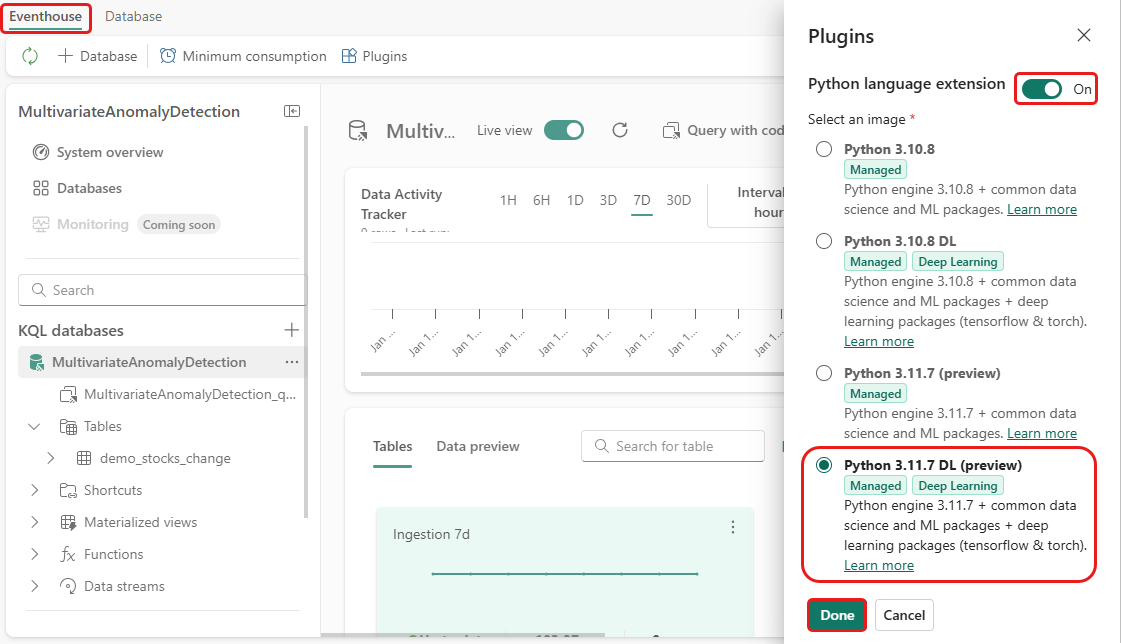
In questo passaggio si abilita il plug-in Python nella Eventhouse. Questo passaggio è necessario per eseguire il codice Python per stimare le anomalie nel set di query KQL. È importante scegliere l'immagine corretta che contiene il pacchetto rilevamento anomalie serie temporali .
Nella schermata Eventhouse, selezionare Eventhouse>Plugins dalla barra multifunzione.
Nel riquadro Plug-in impostare l'estensione del linguaggio Python suOn.
Selezionare Python 3.11.7 DL (anteprima).
Selezionare Fatto.

Parte 3- Creare un ambiente Spark
In questo passaggio si crea un ambiente Spark per eseguire il notebook Python che esegue il training del modello di rilevamento anomalie multivariato usando il motore Spark. Per ulteriori informazioni sulla creazione di ambienti, vedi Creare e gestire ambienti.
Nella tua area di lavoro, selezionare + Nuovo elemento quindi Ambiente.
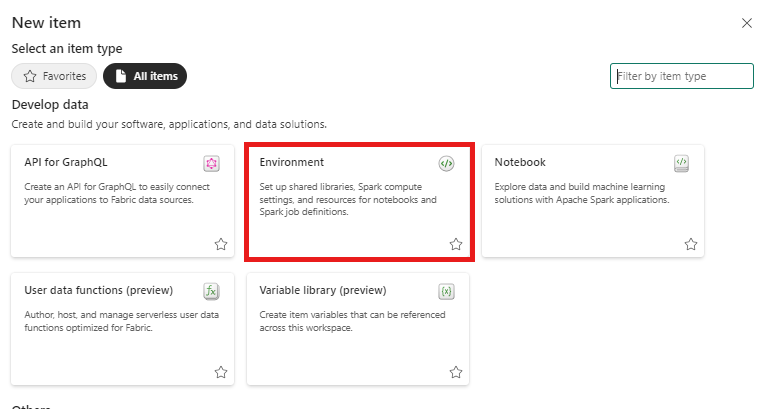
Immettere il nome MVAD_ENV per l'ambiente e poi selezionare Crea.
Nella scheda Home dell'ambiente selezionare Runtime>1.2 (Spark 3.4, Delta 2.4).
In Cataloghi selezionare Cataloghi pubblici.
Selezionare Aggiungi da PyPi.
Nella casella di ricerca immettere serie temporale-rilevamento anomalie. La versione viene popolata automaticamente con la versione più recente. Questa esercitazione è stata creata usando la versione 0.3.2.
Seleziona Salva.

Selezionare la scheda Home nell’ambiente.
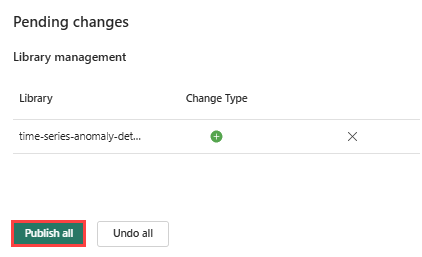
Seleziona l’icona Pubblica nella barra multifunzione.

Selezionare Pubblica tutto. Questo passaggio può richiedere alcuni minuti.


Parte 4- Ottenere i dati nell’Eventhouse
Passare il puntatore del mouse sul database KQL in cui archiviare i dati. Selezionare il menu Altro [...]>Ottieni dati>del file Locale.
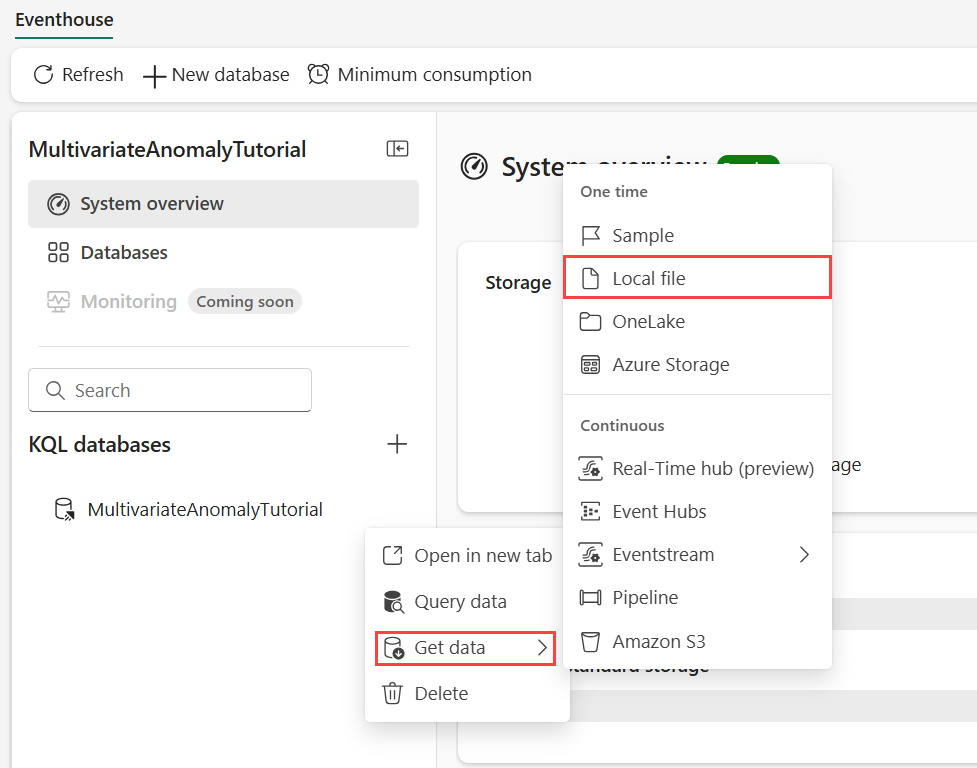
Selezionare + Nuova tabella e immettere demo_stocks_change come nome tabella.
Nella finestra di dialogo Carica dati, selezionare Cerca file e caricare il file di dati campione scaricato nella sezione Prerequisiti
Selezionare Avanti.
Nella sezione Ispezione dati, impostare Prima riga è intestazione di colonna su On.
Selezionare Fine.
Al termine del caricamento selezionare Chiudi.
Parte 5- Copiare il percorso di OneLake nella tabella
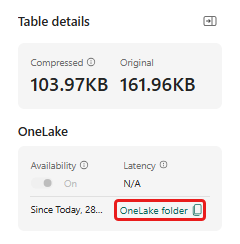
Assicurarsi di selezionare la tabella demo_stocks_change. Nel riquadro dettagli tabella , selezionare la cartella OneLake per copiare il percorso di OneLake negli Appunti. Salvare il testo copiato in un editor di testo da usare in un passaggio successivo.
Parte 6- Preparare il notebook
Selezionare l'area di lavoro.
Selezionare Importa, Notebook e quindi Da questo computer.
Selezionare Carica e scegliere il notebook scaricato nei prerequisiti.
Dopo aver caricato il notebook, è possibile trovare e aprire il notebook dall'area di lavoro.
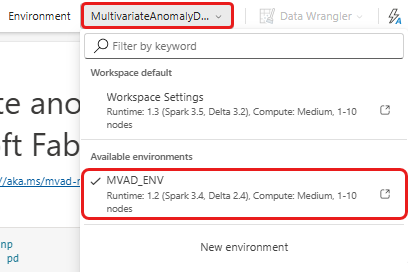
Nella barra multifunzione superiore selezionare l'elenco a discesa predefinito dell’Area di lavoro e selezionare l'ambiente creato nel passaggio precedente.
7- Eseguire il notebook
Importare pacchetti standard.
import numpy as np import pandas as pdSpark richiede un URI ABFSS per connettersi in modo sicuro all'archiviazione OneLake, quindi il passaggio successivo definisce questa funzione per convertire l'URI di OneLake in URI ABFSS.
def convert_onelake_to_abfss(onelake_uri): if not onelake_uri.startswith('https://'): raise ValueError("Invalid OneLake URI. It should start with 'https://'.") uri_without_scheme = onelake_uri[8:] parts = uri_without_scheme.split('/') if len(parts) < 3: raise ValueError("Invalid OneLake URI format.") account_name = parts[0].split('.')[0] container_name = parts[1] path = '/'.join(parts[2:]) abfss_uri = f"abfss://{container_name}@{parts[0]}/{path}" return abfss_uriSostituire il segnaposto OneLakeTableURI con il vostro URI di OneLake copiato dalla Parte 5- Copiare il percorso OneLake nella tabella per caricare la tabella demo_stocks_change in un dataframe pandas.
onelake_uri = "OneLakeTableURI" # Replace with your OneLake table URI abfss_uri = convert_onelake_to_abfss(onelake_uri) print(abfss_uri)df = spark.read.format('delta').load(abfss_uri) df = df.toPandas().set_index('Date') print(df.shape) df[:3]Eseguire le celle seguenti per preparare i dataframe di training e previsione.
Nota
Le stime effettive verranno eseguite sui dati dalla Eventhouse nella parte 9- Previsione-anomalie-nel-set-di-query-kql. In uno scenario di produzione, se si esegue lo streaming dei dati nell’eventhouse, le stime verrebbero effettuate sui nuovi dati di streaming. Ai fini dell'esercitazione, il set di dati è stato suddiviso per data in due sezioni per il training e la previsione. Si tratta di simulare dati storici e nuovi dati di streaming.
features_cols = ['AAPL', 'AMZN', 'GOOG', 'MSFT', 'SPY'] cutoff_date = pd.to_datetime('2023-01-01')train_df = df[df.Date < cutoff_date] print(train_df.shape) train_df[:3]train_len = len(train_df) predict_len = len(df) - train_len print(f'Total samples: {len(df)}. Split to {train_len} for training, {predict_len} for testing')Eseguire le celle per eseguire il training del modello e salvarlo nel registro dei modelli MLflow di Fabric.
import mlflow from anomaly_detector import MultivariateAnomalyDetector model = MultivariateAnomalyDetector()sliding_window = 200 param s = {"sliding_window": sliding_window}model.fit(train_df, params=params)with mlflow.start_run(): mlflow.log_params(params) mlflow.set_tag("Training Info", "MVAD on 5 Stocks Dataset") model_info = mlflow.pyfunc.log_model( python_model=model, artifact_path="mvad_artifacts", registered_model_name="mvad_5_stocks_model", )Eseguire la cella seguente per estrarre il percorso del modello registrato da usare per la predizione usando la sandbox Python Kusto.
mi = mlflow.search_registered_models(filter_string="name='mvad_5_stocks_model'")[0] model_abfss = mi.latest_versions[0].source print(model_abfss)Copiare l'URI del modello dall'ultimo output della cella da usare in un passaggio successivo.
Parte 8- Configurare il set di query KQL
Per informazioni generali, vedere Creare un set di query KQL.
- Dalla tua area di lavoro, seleziona +Nuovo elemento>set di query KQL.
- Immettere il nome MultivariateAnomalyDetectionTutoriale quindi selezionare Crea.
- Nella finestra dell'hub dati OneLake selezionare il database KQL in cui sono stati archiviati i dati.
- Selezionare Connetti.
Parte 9- Stimare le anomalie nel set di query KQL
Eseguire la query '.create-or-alter function' seguente per definire la funzione memorizzata
predict_fabric_mvad_fl():.create-or-alter function with (folder = "Packages\\ML", docstring = "Predict MVAD model in Microsoft Fabric") predict_fabric_mvad_fl(samples:(*), features_cols:dynamic, artifacts_uri:string, trim_result:bool=false) { let s = artifacts_uri; let artifacts = bag_pack('MLmodel', strcat(s, '/MLmodel;impersonate'), 'conda.yaml', strcat(s, '/conda.yaml;impersonate'), 'requirements.txt', strcat(s, '/requirements.txt;impersonate'), 'python_env.yaml', strcat(s, '/python_env.yaml;impersonate'), 'python_model.pkl', strcat(s, '/python_model.pkl;impersonate')); let kwargs = bag_pack('features_cols', features_cols, 'trim_result', trim_result); let code = ```if 1: import os import shutil import mlflow model_dir = 'C:/Temp/mvad_model' model_data_dir = model_dir + '/data' os.mkdir(model_dir) shutil.move('C:/Temp/MLmodel', model_dir) shutil.move('C:/Temp/conda.yaml', model_dir) shutil.move('C:/Temp/requirements.txt', model_dir) shutil.move('C:/Temp/python_env.yaml', model_dir) shutil.move('C:/Temp/python_model.pkl', model_dir) features_cols = kargs["features_cols"] trim_result = kargs["trim_result"] test_data = df[features_cols] model = mlflow.pyfunc.load_model(model_dir) predictions = model.predict(test_data) predict_result = pd.DataFrame(predictions) samples_offset = len(df) - len(predict_result) # this model doesn't output predictions for the first sliding_window-1 samples if trim_result: # trim the prefix samples result = df[samples_offset:] result.iloc[:,-4:] = predict_result.iloc[:, 1:] # no need to copy 1st column which is the timestamp index else: result = df # output all samples result.iloc[samples_offset:,-4:] = predict_result.iloc[:, 1:] ```; samples | evaluate python(typeof(*), code, kwargs, external_artifacts=artifacts) }Eseguire la query di stima seguente, sostituendo l'URI del modello di output con l'URI copiato alla fine di passaggio 7.
La query rileva anomalie multivariate sui cinque titoli, in base al modello addestrato e restituisce i risultati come
anomalychart. I punti anomali vengono sottoposti a rendering sul primo titolo (AAPL), anche se rappresentano anomalie multivariate (in altre parole, anomalie delle modifiche comuni delle cinque azioni nella data specifica).let cutoff_date=datetime(2023-01-01); let num_predictions=toscalar(demo_stocks_change | where Date >= cutoff_date | count); // number of latest points to predict let sliding_window=200; // should match the window that was set for model training let prefix_score_len = sliding_window/2+min_of(sliding_window/2, 200)-1; let num_samples = prefix_score_len + num_predictions; demo_stocks_change | top num_samples by Date desc | order by Date asc | extend is_anomaly=bool(false), score=real(null), severity=real(null), interpretation=dynamic(null) | invoke predict_fabric_mvad_fl(pack_array('AAPL', 'AMZN', 'GOOG', 'MSFT', 'SPY'), // NOTE: Update artifacts_uri to model path artifacts_uri='enter your model URI here', trim_result=true) | summarize Date=make_list(Date), AAPL=make_list(AAPL), AMZN=make_list(AMZN), GOOG=make_list(GOOG), MSFT=make_list(MSFT), SPY=make_list(SPY), anomaly=make_list(toint(is_anomaly)) | render anomalychart with(anomalycolumns=anomaly, title='Stock Price Changest in % with Anomalies')
Il grafico delle anomalie risultante dovrebbe essere simile all'immagine seguente:

Pulire le risorse
Al termine del tutorial, è possibile eliminare le risorse create per evitare di incorrere in altri costi. Per rimuovere le risorse, seguire questa procedura:
- Passare alla home page dell'area di lavoro.
- Eliminare l’ambiente creato in questa esercitazione.
- Eliminare il notebook creato in questo tutorial.
- Eliminare l'eventhouse o il database usato in questo tutorial.
- Eliminare il KQL creato in questa esercitazione.