Esplorare i dati nel database con mirroring con Notebook
È possibile esplorare i dati replicati dal database con mirroring con le query Spark nei Notebook.
I Notebook sono un potente elemento di codice che consente di sviluppare processi Apache Spark ed esperimenti di Machine Learning sui dati. È possibile usare i Notebook in Fabric Lakehouse per esplorare le tabelle con mirroring.
Prerequisiti
- Completare l'esercitazione per creare un database con mirroring dal database di origine.
- Esercitazione: Configurare il database con mirroring di Microsoft Fabric per Azure Cosmos DB (anteprima)
- Esercitazione: Configurare database con mirroring di Microsoft Fabric da Azure Databricks (anteprima)
- Esercitazione: Configurare database con mirroring di Microsoft Fabric da database SQL di Azure
- Esercitazione: Configurare database con mirroring di Microsoft Fabric da Istanza gestita di SQL di Azure (anteprima)
- Esercitazione: Configurare database con mirroring di Microsoft Fabric da Snowflake
Creare un collegamento
È prima necessario creare un collegamento dalle tabelle con mirroring in Lakehouse e quindi creare Notebook con query Spark in Lakehouse.
Nel portale Fabric, aprire Ingegneria dei dati.
Se non è già stato creato un Lakehouse, selezionare Lakehouse e creare un nuovo Lakehouse assegnandogli un nome.
Selezionare Recupera dati ->Nuovo collegamento.
Selezionare Microsoft OneLake.
È possibile visualizzare tutti i database con mirroring nell'area di lavoro di Fabric.
Selezionare il database con mirroring da aggiungere a Lakehouse come collegamento.
Selezionare le tabelle desiderate dal database con mirroring.
Selezionare Avanti e poi Crea.
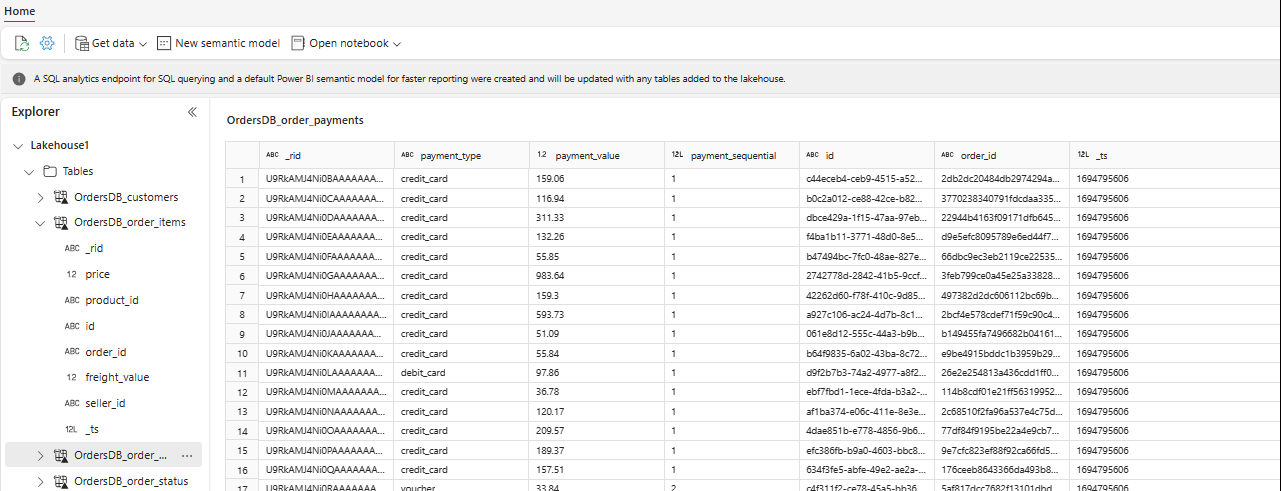
In Esplora risorse è ora possibile visualizzare i dati della tabella selezionati in Lakehouse.
Suggerimento
È possibile aggiungere altri dati direttamente in Lakehouse o usare collegamenti come S3, ADLS Gen2. È possibile passare all'endpoint di analisi SQL di Lakehouse e unire senza problemi i dati di tutte queste origini con i dati con mirroring.
Per esplorare questi dati in Spark, selezionare i puntini
...accanto a qualsiasi tabella. Per iniziare l’analisi, selezionare Nuovo Notebook oppure Notebook esistente.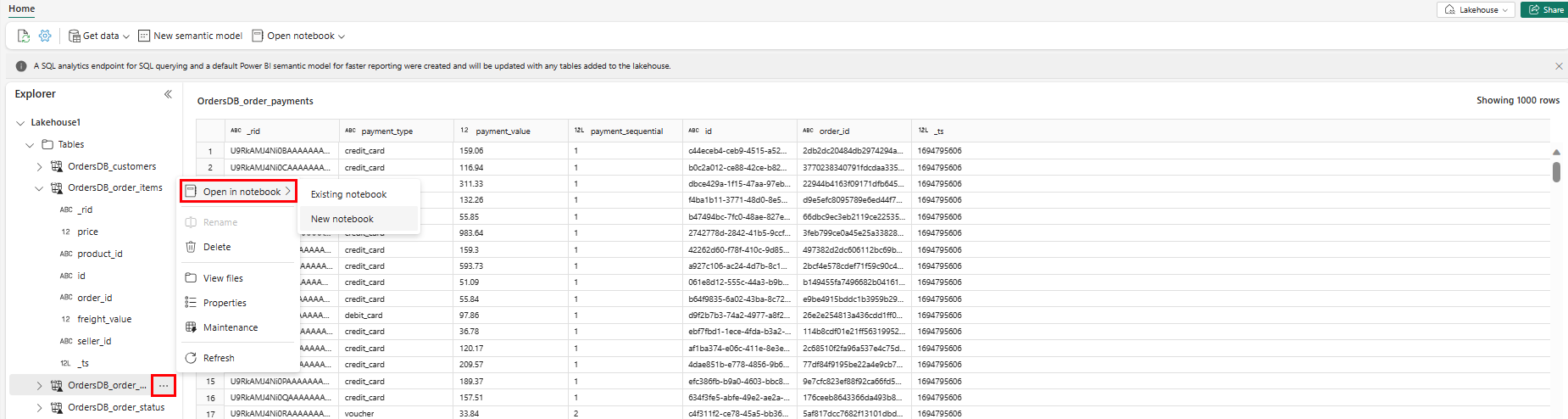
Il notebook verrà aperto automaticamente e il dataframe verrà caricato con una
SELECT ... LIMIT 1000query Spark SQL.- Ci possono volere fino a due minuti per caricare completamente i nuovi notebook. È possibile evitare questo ritardo usando un notebook esistente con una sessione attiva.
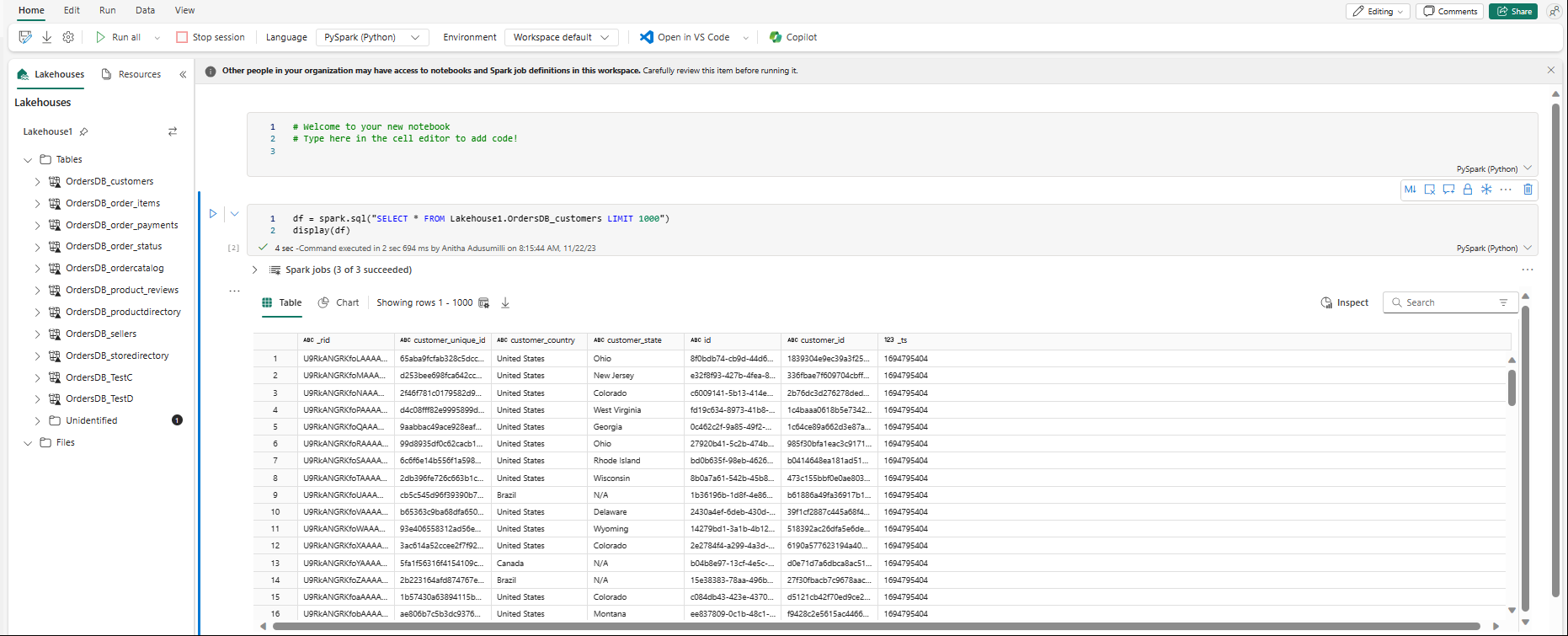
- Ci possono volere fino a due minuti per caricare completamente i nuovi notebook. È possibile evitare questo ritardo usando un notebook esistente con una sessione attiva.


