Copiare da Archiviazione BLOB di Azure a Lakehouse
In questa esercitazione si crea una pipeline di dati per spostare un file CSV da una cartella di input di un'origine Archiviazione BLOB di Azure a una destinazione Lakehouse.
Prerequisiti
Per iniziare, è necessario soddisfare i prerequisiti seguenti:
Assicurarsi di disporre di un'area di lavoro abilitata per Microsoft Fabric: Creare un'area di lavoro.
Selezionare il pulsante Prova adesso per preparare l'origine dati Archiviazione BLOB di Azure copia. Creare un nuovo gruppo di risorse per questo Archiviazione BLOB di Azure e selezionare Rivedi e crea>Crea.

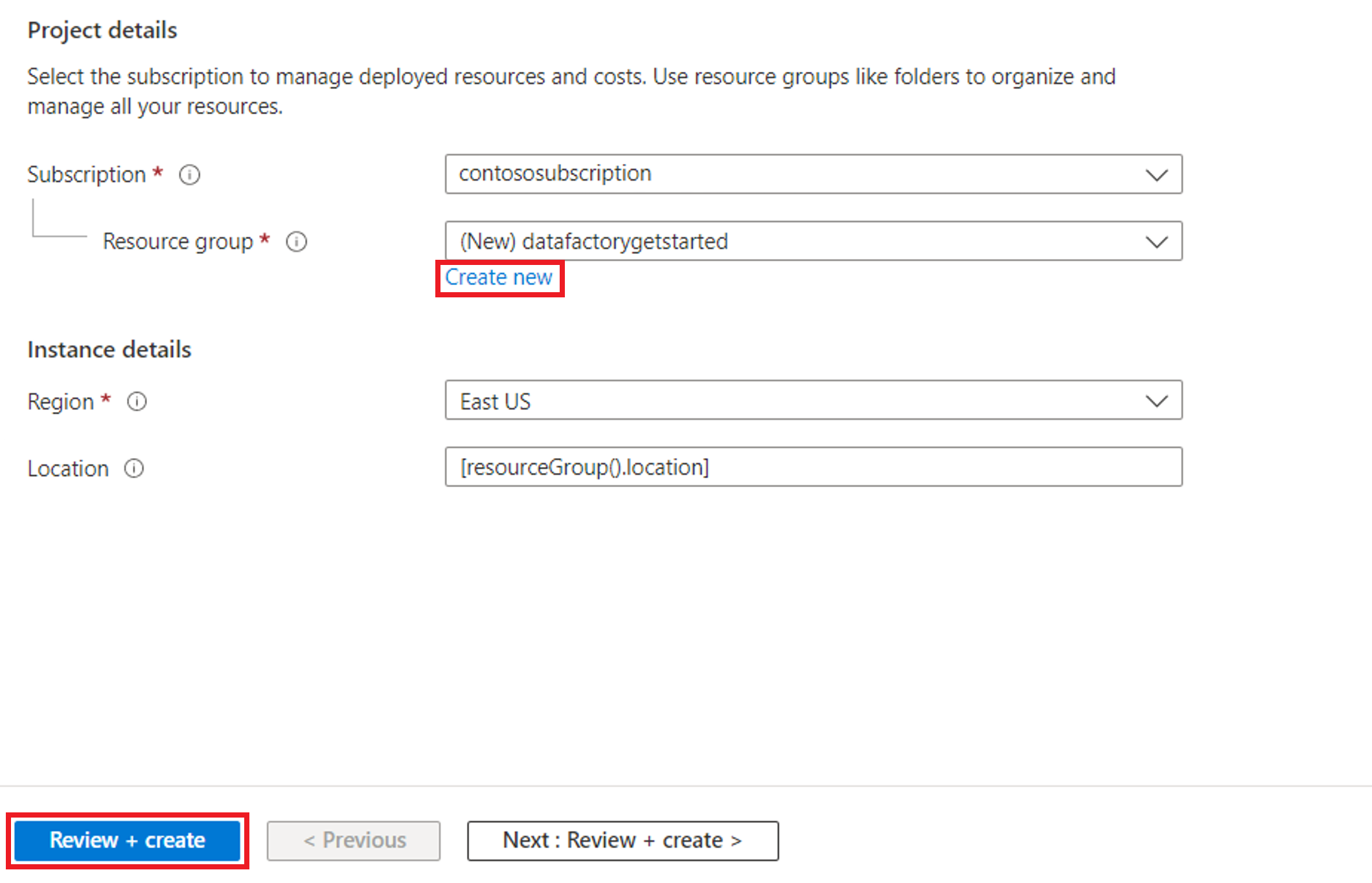
Viene quindi creata un’Archiviazione BLOB di Azure e moviesDB2.csv caricata nella cartella di input dell’Archiviazione BLOB di Azure creata.

Creazione di una pipeline di dati
Passare a Data factory nella pagina app.powerbi.com.
Creare una nuova area di lavoro per questa demo.
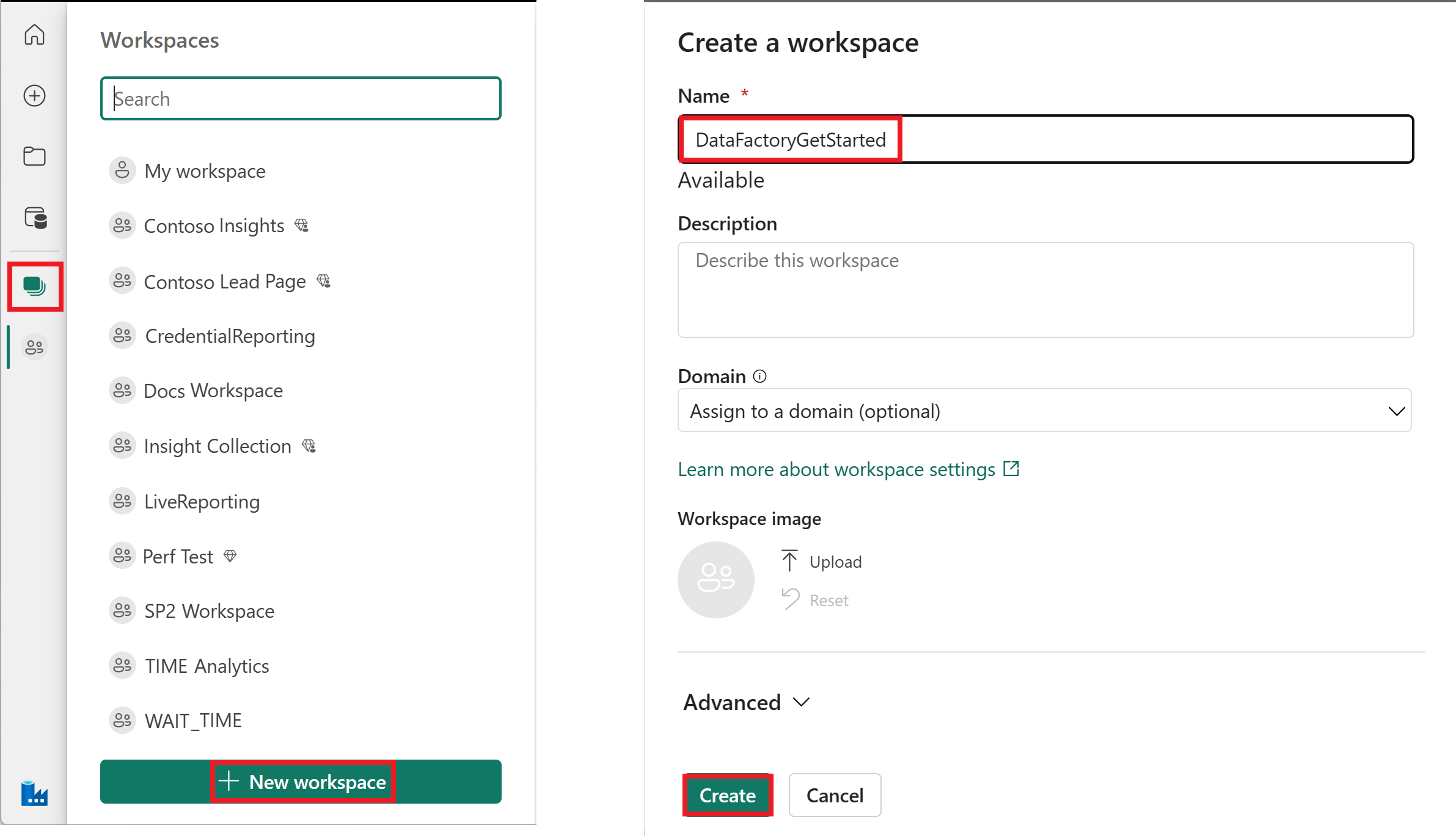
Selezionare Nuovo e quindi pipeline di dati.
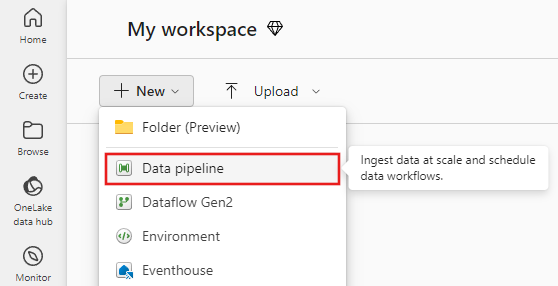

Copiare dati con l'Assistente copia
In questa sessione si inizia a creare una pipeline di dati seguendo questa procedura. Questi passaggi copiano un file CSV da una cartella di input di un Archiviazione BLOB di Azure a una destinazione Lakehouse usando l'assistente copia.
Passaggio 1: Iniziare con l'assistente copia
Selezionare Copia assistente dati nell'area di disegno per aprire lo strumento di assistente copia per iniziare. In alternativa, selezionare Usa assistente copia dall'elenco a discesa Copia dati nella scheda Attività sulla barra multifunzione.

Passaggio 2: configurare l'origine
Digitare BLOB nel filtro di selezione, quindi selezionare BLOB di Azure e selezionare Avanti.
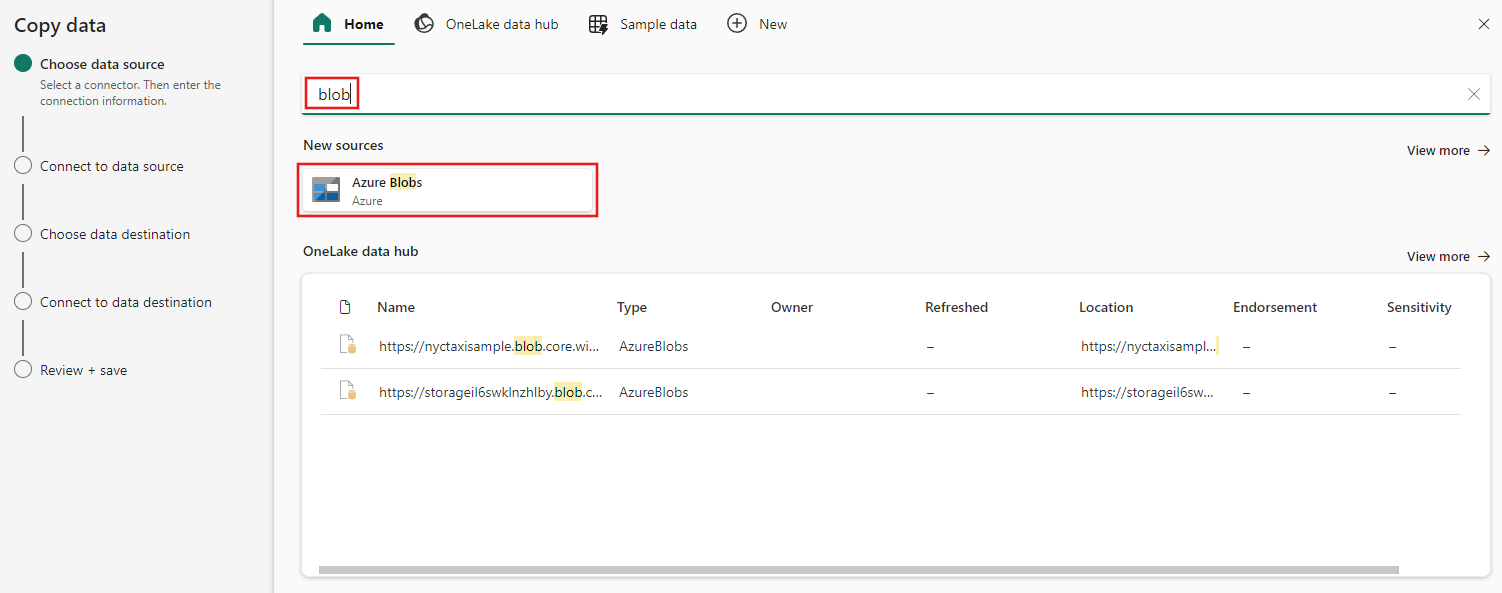
Specificare il nome o l'URL dell'account e creare una connessione all'origine dati selezionando Crea nuova connessione nell'elenco a discesa Connessione.
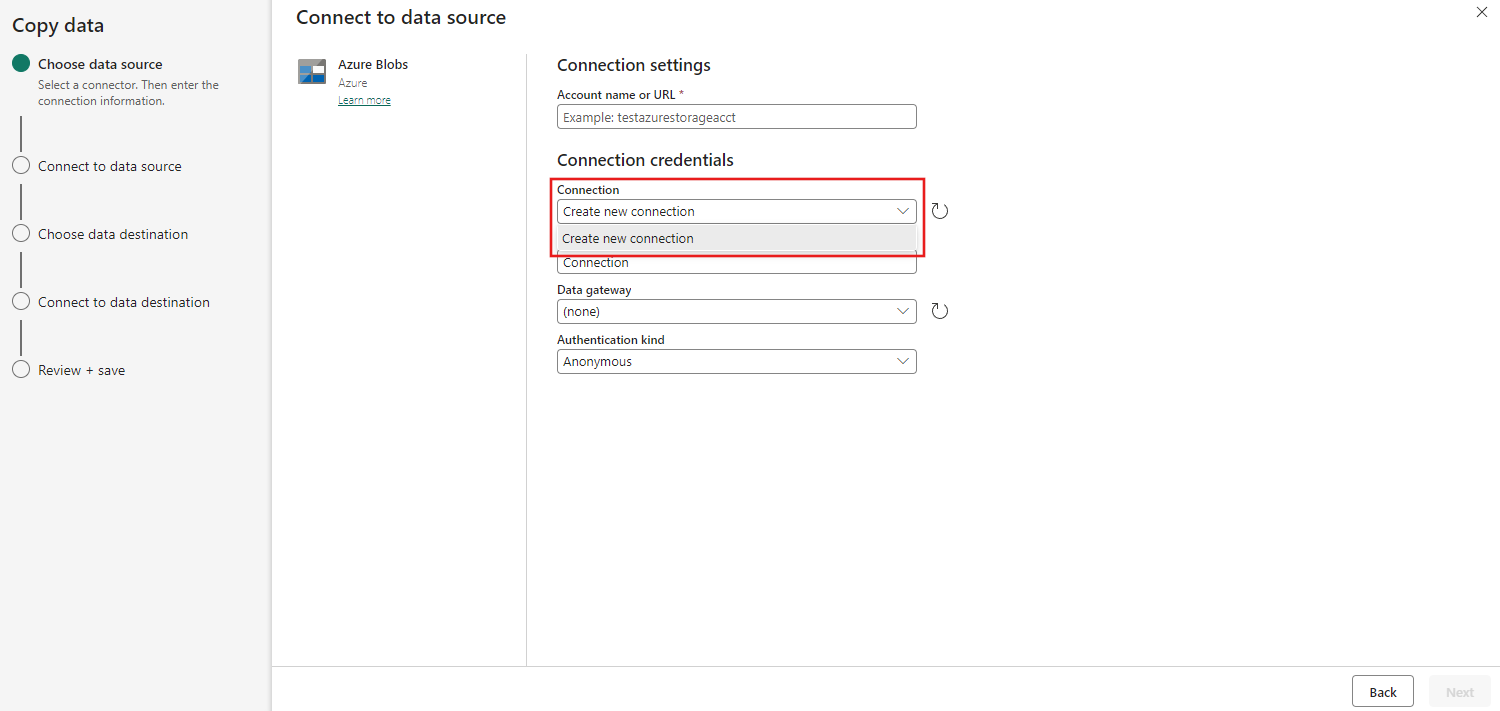
Dopo aver selezionato Crea nuova connessione con l'account di archiviazione specificato, è sufficiente compilare il tipo di autenticazione. In questa demo si sceglie Chiave account , ma è possibile scegliere un altro tipo di autenticazione in base alle preferenze.
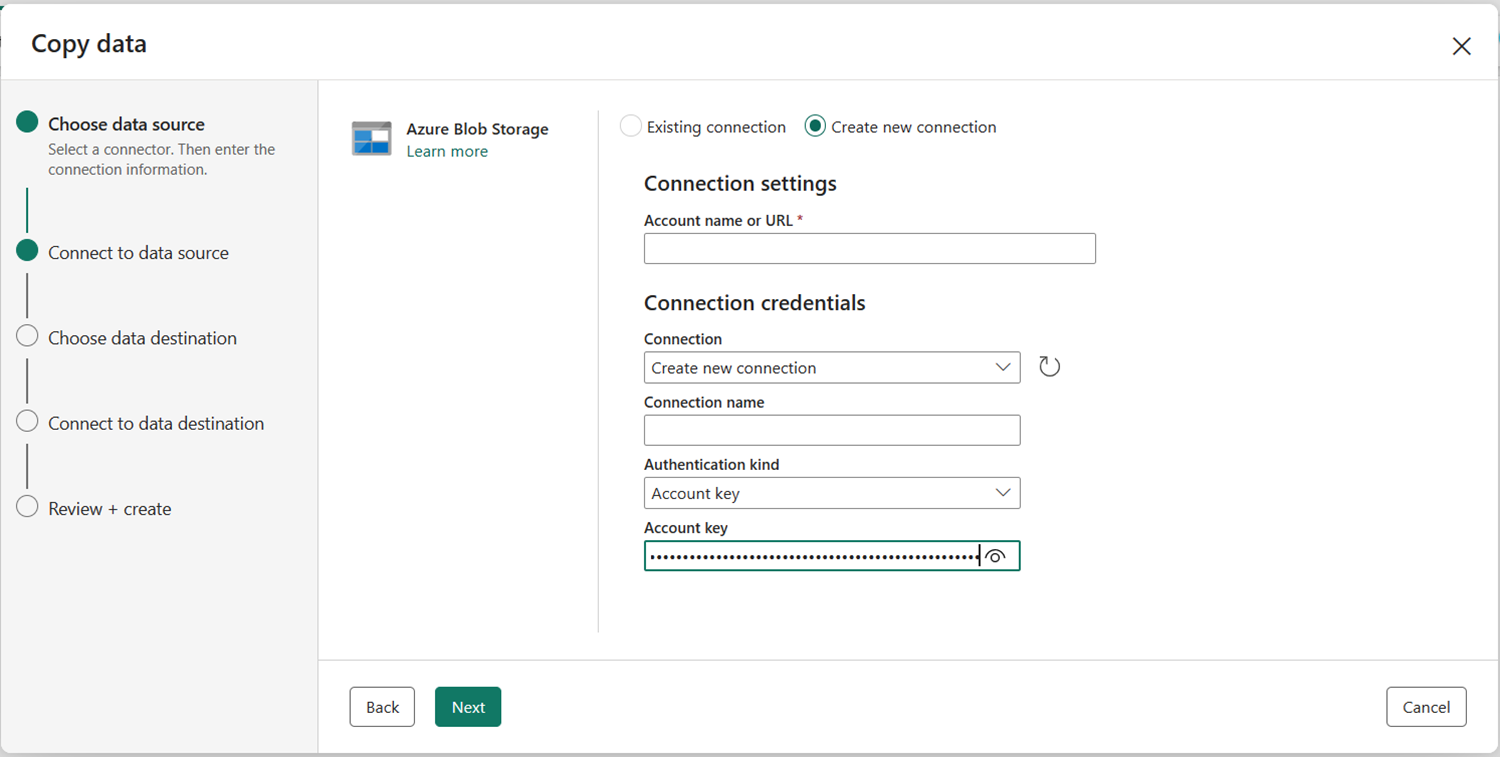
Dopo aver creato correttamente la connessione, è sufficiente selezionare Avanti per connettersi all'origine dati.
Scegliere il file moviesDB2.csv nella configurazione di origine da visualizzare in anteprima e quindi selezionare Avanti.
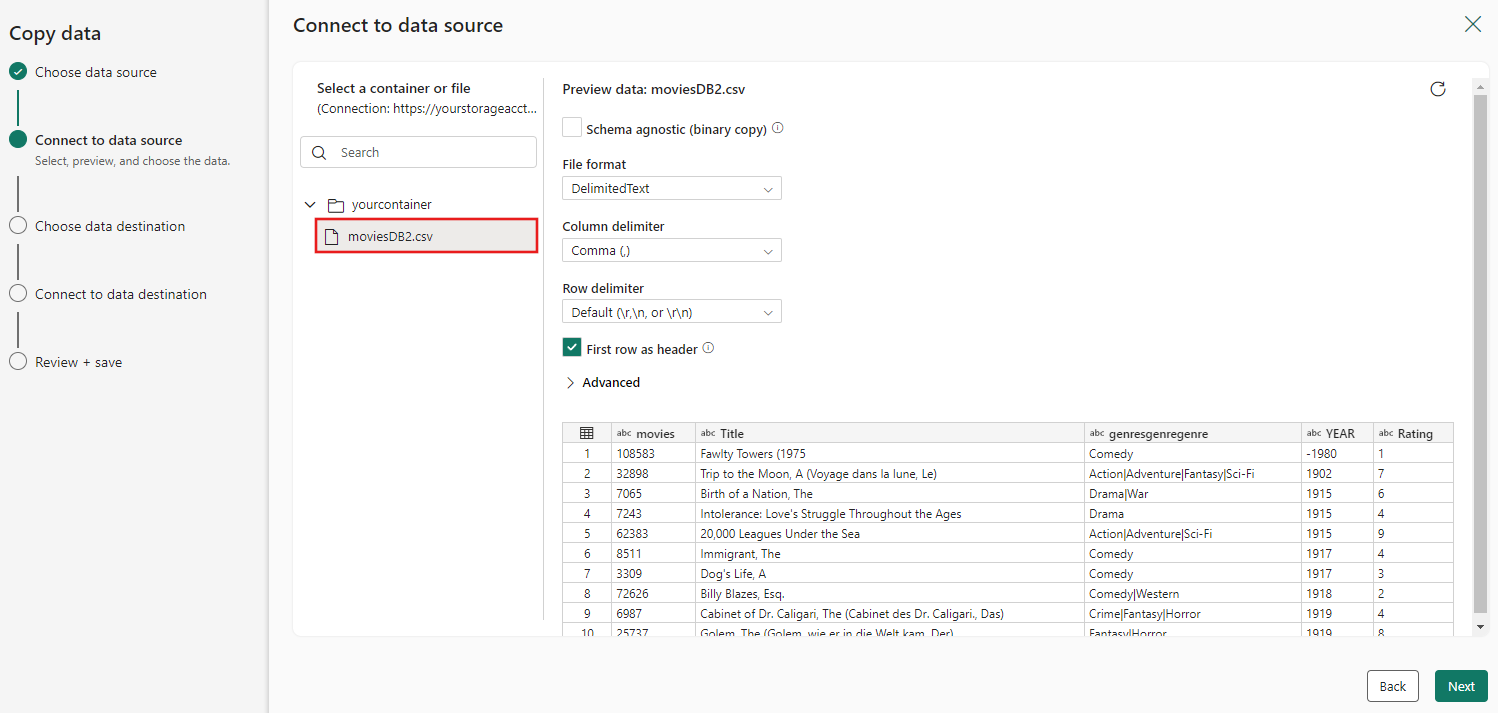




Passaggio 3: configurare la destinazione
Selezionare Lakehouse.
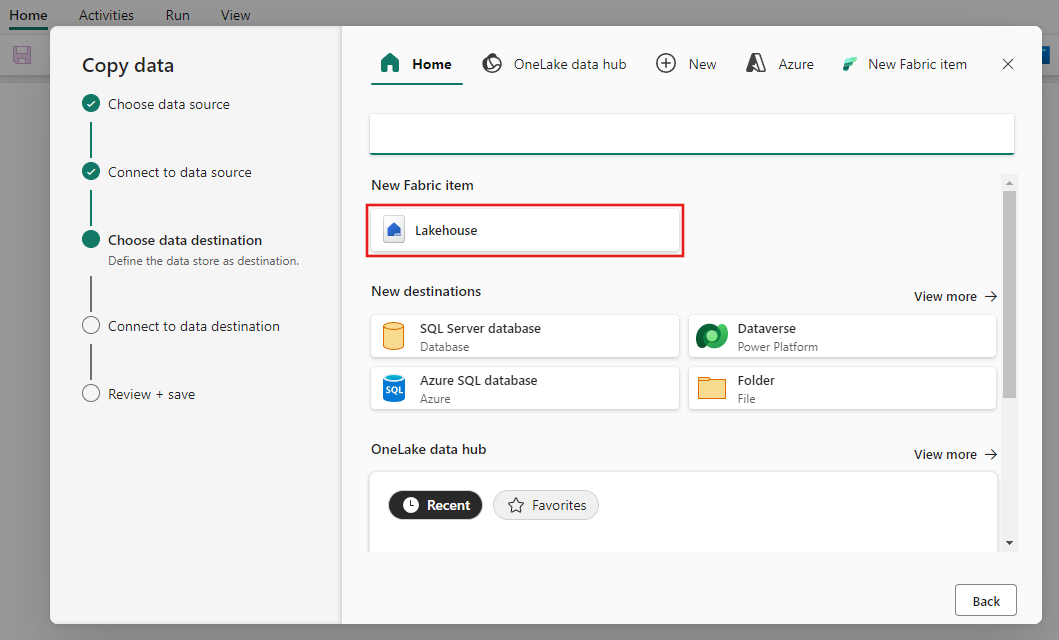
Specificare un nome per il nuovo Lakehouse. Selezionare quindi Crea e Connetti.
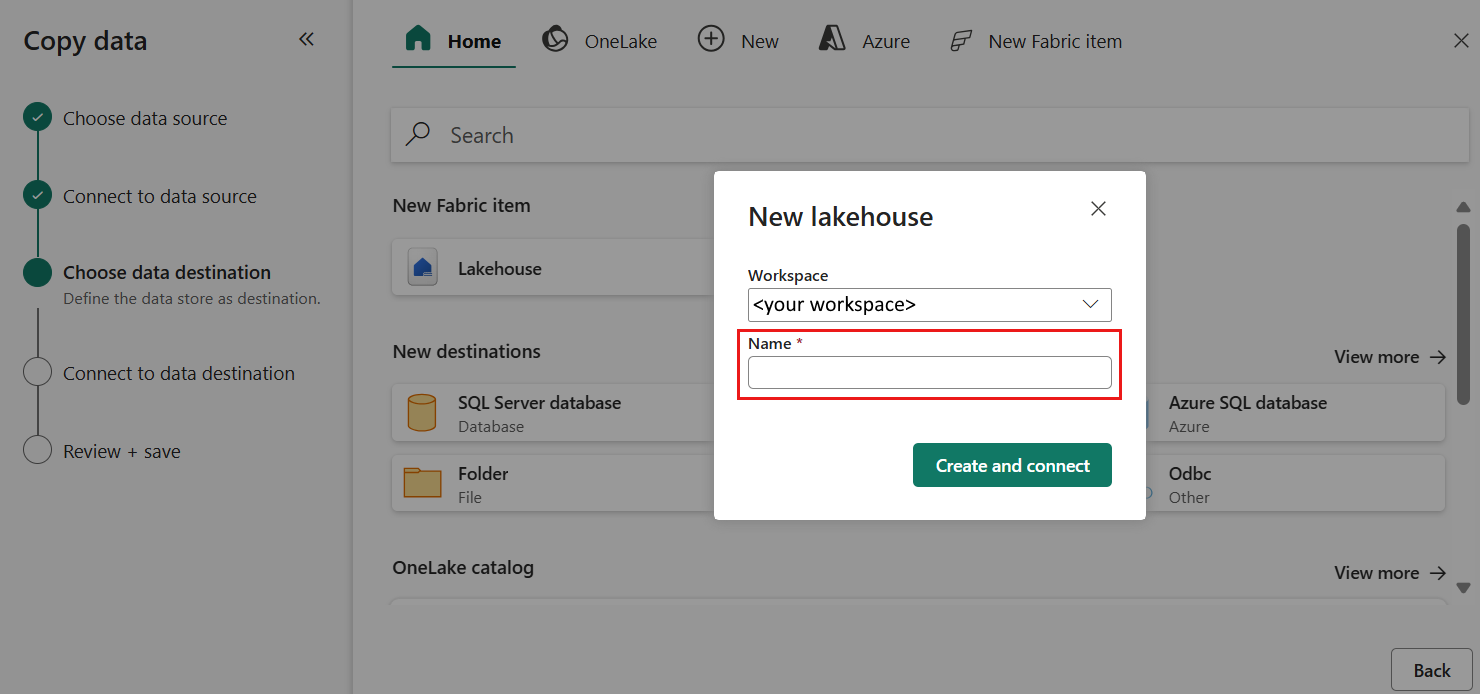
Configurare ed eseguire il mapping dei dati di origine alla destinazione; quindi selezionare Avanti per completare le configurazioni di destinazione.



Passaggio 4: esaminare e creare l'attività di copia
Esaminare le impostazioni dell'attività Copy nei passaggi precedenti e selezionare Salva ed Esegui per completare. In alternativa, è possibile tornare ai passaggi precedenti per modificare le impostazioni, se necessario nello strumento.
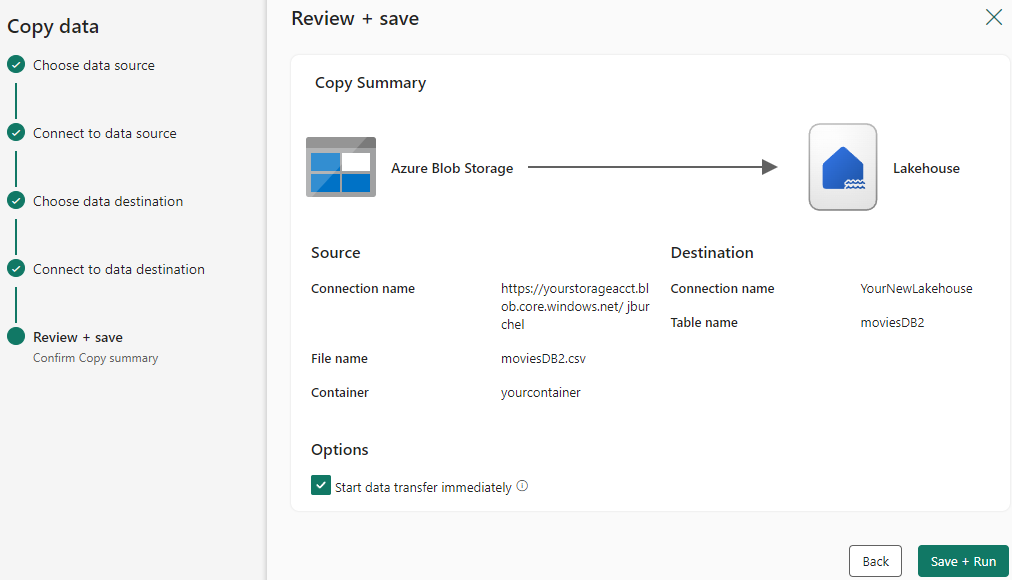
Al termine, l'attività di copia viene aggiunta all'area di disegno della pipeline di dati ed eseguita direttamente se è stata lasciata la casella di controllo Avvia trasferimento dati immediatamente selezionata.
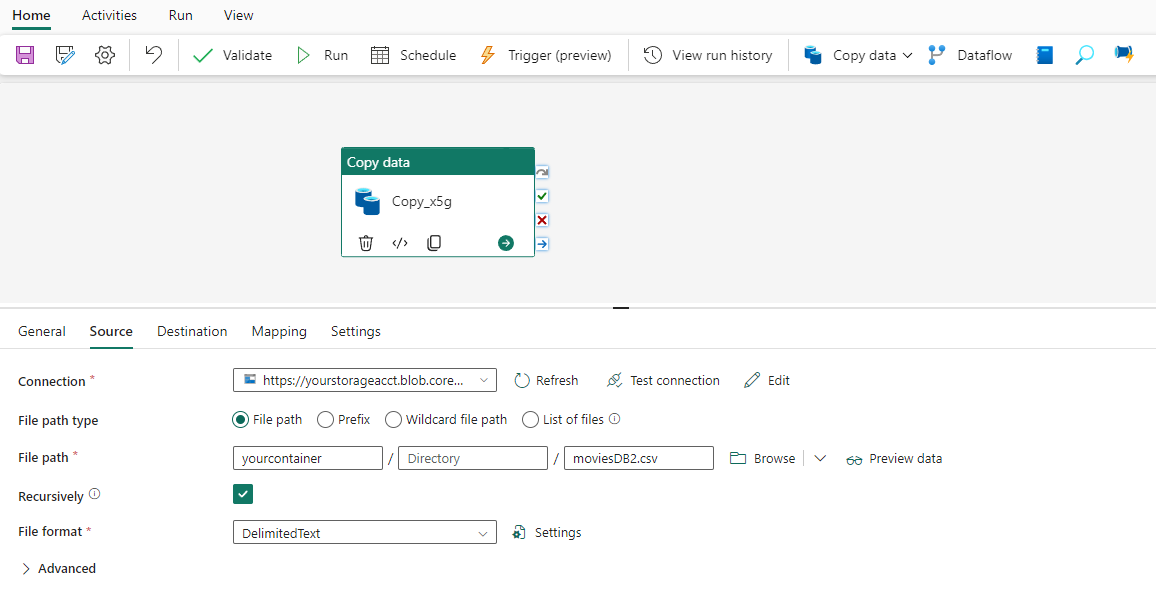


Eseguire e pianificare la pipeline di dati
Se la casella di controllo Avvia trasferimento dati non è stata lasciata immediatamente nella pagina Rivedi e crea, passare alla scheda Home e selezionare Esegui. Selezionare quindi Salva ed esegui.
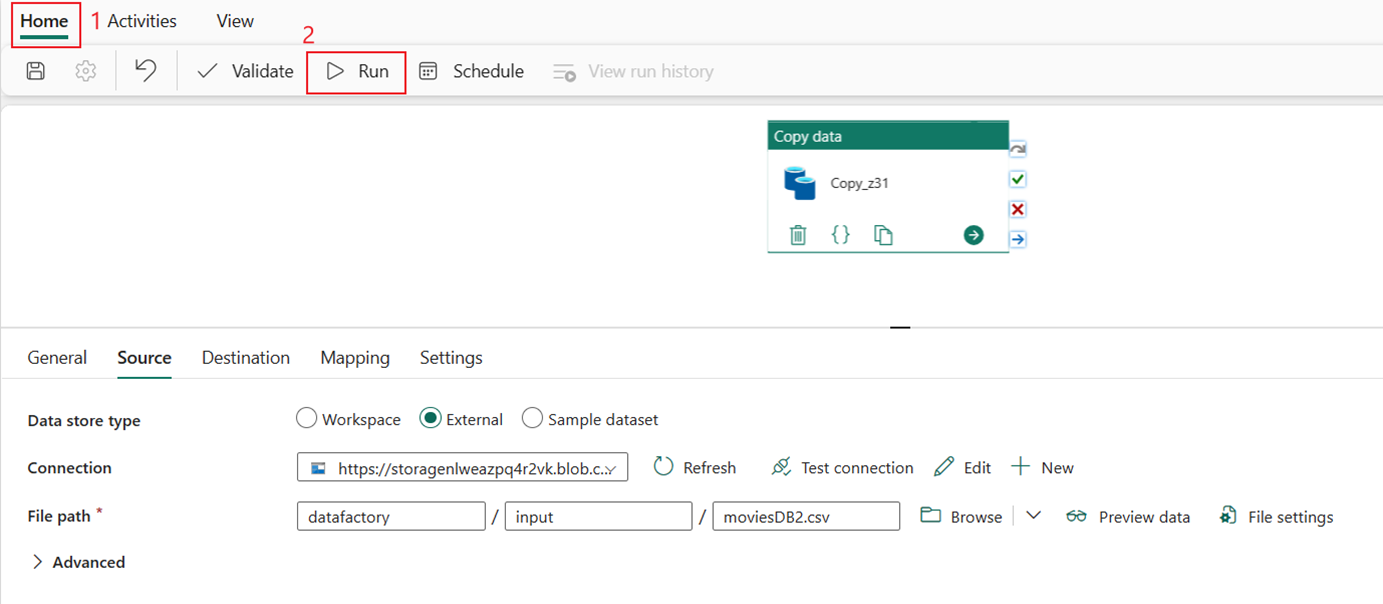
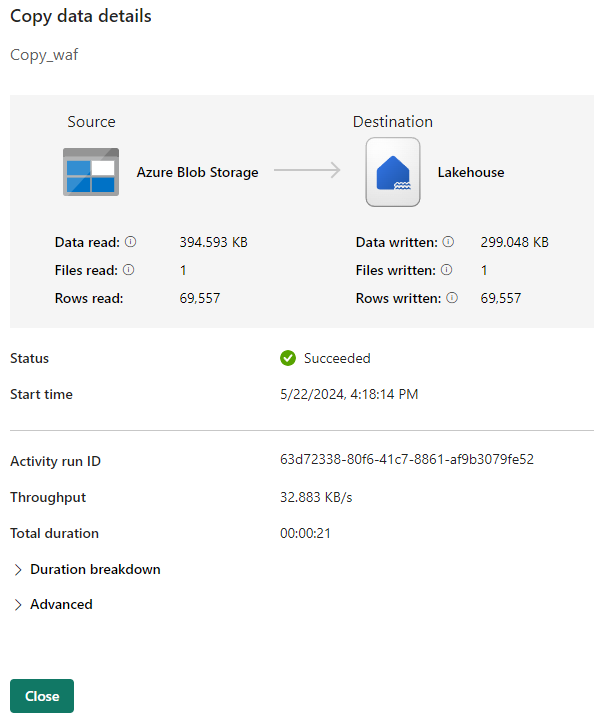
Nella scheda Output selezionare il collegamento con il nome del attività Copy per monitorare lo stato di avanzamento e controllare i risultati dell'esecuzione.
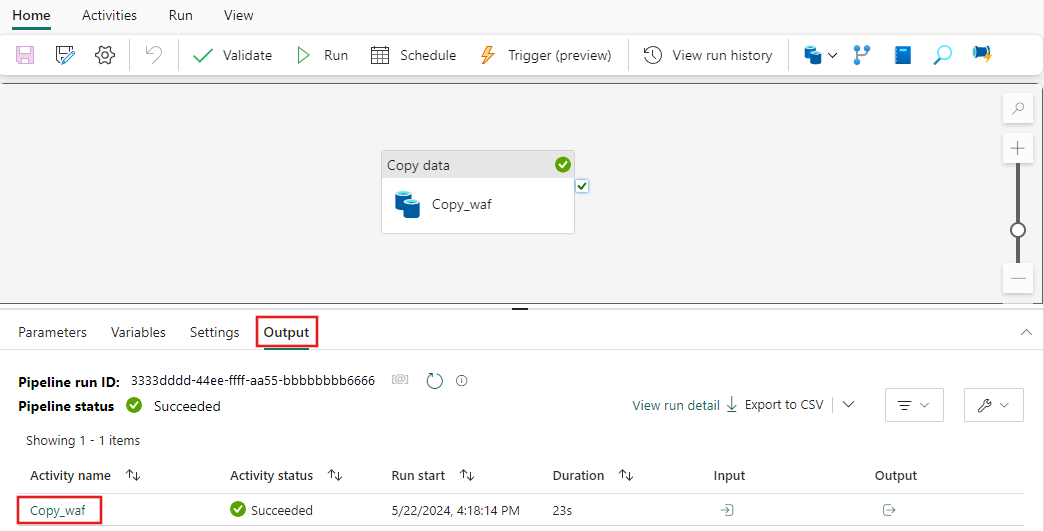
Nella finestra di dialogo Copia dettagli dati vengono visualizzati i risultati dell'esecuzione, inclusi lo stato, il volume di dati letti e scritti, gli orari di avvio e di arresto e la durata.
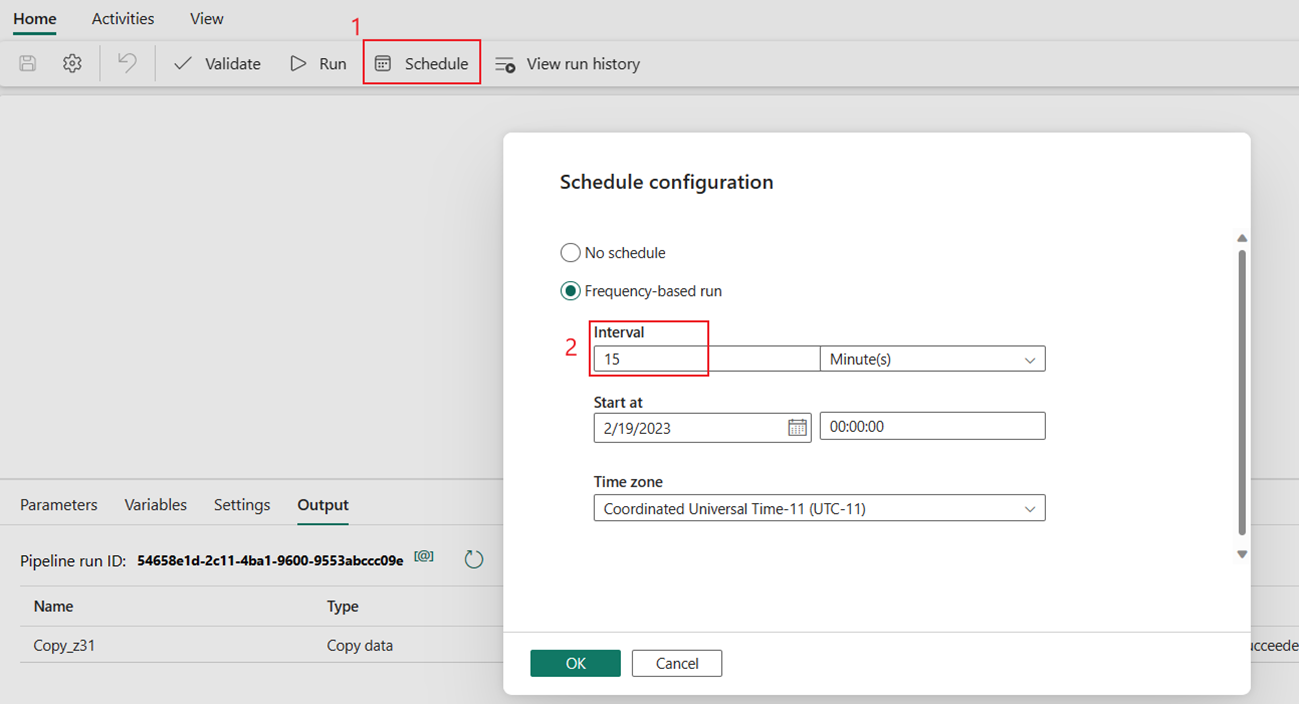
È anche possibile pianificare l'esecuzione della pipeline con una frequenza specifica in base alle esigenze. L'esempio seguente illustra come pianificare l'esecuzione della pipeline ogni 15 minuti.



Contenuto correlato
La pipeline di questo esempio illustra come copiare dati da Archiviazione BLOB di Azure a Lakehouse. Contenuto del modulo:
- Creazione di una pipeline di dati.
- Copiare dati con l'Assistente copia.
- Eseguire e pianificare la pipeline di dati.
Passare quindi a altre informazioni sul monitoraggio delle esecuzioni della pipeline.