Trasformare i dati eseguendo un notebook
L’attività Notebook nella pipeline consente di eseguire notebook creati in Microsoft Fabric. È possibile creare un’attività notebook direttamente tramite l’interfaccia utente di Fabric. Questo articolo fornisce una procedura dettagliata che descrive come creare un'attività notebook usando l'interfaccia utente di Data Factory.
Aggiungere un'attività di Notebook a una pipeline
Questa sezione descrive come usare un’attività Notebook in una pipeline.
Prerequisiti
Per iniziare, è necessario soddisfare i prerequisiti seguenti:
- Un account locatario con una sottoscrizione attiva. Creare un account gratuito.
- Viene creata un’area di lavoro.
- Un notebook è stato creato nell'area di lavoro. Per creare un nuovo notebook, vedere Come creare notebook di Microsoft Fabric.
Creazione dell’attività
Creare una nuova pipeline nell'area di lavoro.
Cerca Notebook nel riquadro Attività della pipeline, e selezionalo per aggiungerlo al canvas della pipeline.
Selezionare la nuova attività Notebook nell’area di disegno, se non è già selezionata.
Fare riferimento alla guida alle impostazioni Generali per configurare la scheda impostazioni Generali.
Impostazioni notebook
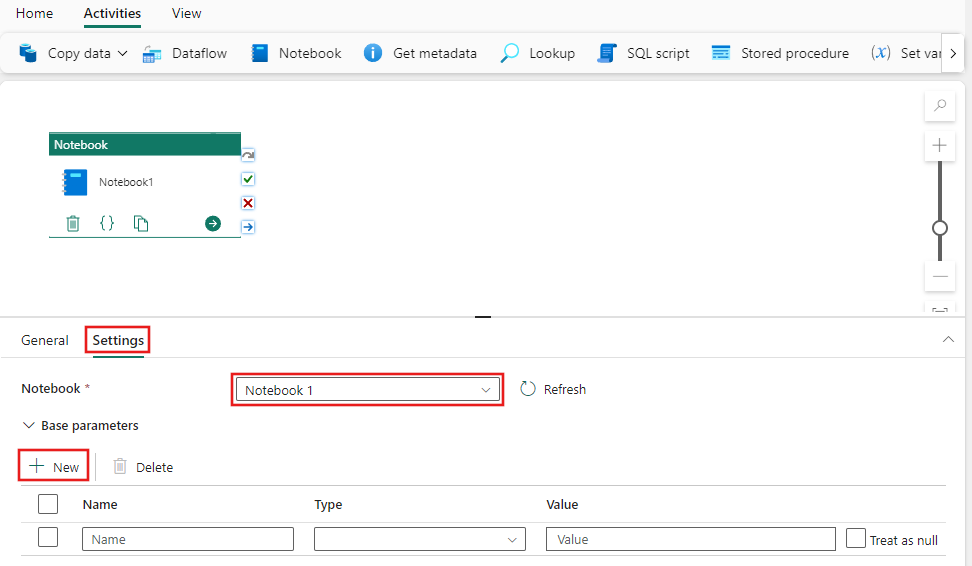
Selezionare la scheda Impostazioni, selezionare un notebook esistente dall'elenco a discesa Notebook e, facoltativamente, specificare eventuali parametri da passare al notebook.
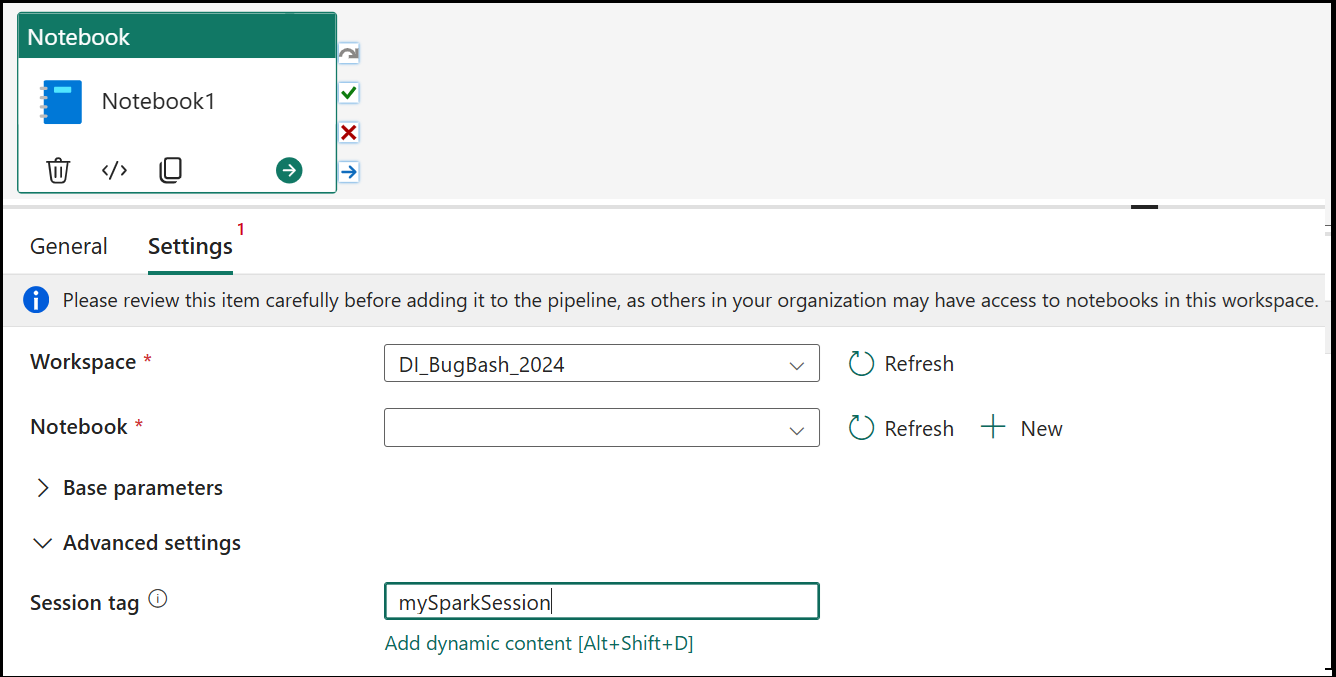
Tag di sessione
Per ridurre al minimo il tempo necessario per eseguire il processo del notebook, è possibile impostare facoltativamente un tag di sessione. L'impostazione del tag di sessione indicherà a Spark di riutilizzare qualsiasi sessione Spark esistente riducendo al minimo il tempo di avvio. Qualsiasi valore stringa arbitrario può essere usato per il tag di sessione. Se non esiste alcuna sessione, ne verrà creata una nuova usando il valore del tag.
Nota
Per poter utilizzare il tag di sessione, è necessario attivare l'impostazione di modalità ad alta concorrenza per l'esecuzione di pipeline che coinvolge più notebook. Questa opzione è disponibile nella modalità di concorrenza elevata per le impostazioni di Spark nelle impostazioni dell'area di lavoro

Salvare ed eseguire o pianificare la pipeline
Passare alla scheda Home nella parte superiore dell'editor della pipeline e selezionare il pulsante Salva per salvare la pipeline. Selezionare Esegui per eseguirla direttamente, o Pianifica per pianificarla. È anche possibile visualizzare la cronologia di esecuzione qui o configurare altre impostazioni.
