Aggiornamento incrementale in Dataflow Gen2 (anteprima)
In questo articolo viene introdotto l'aggiornamento incrementale dei dati in Dataflow Gen2 per Data Factory di Microsoft Fabric. Quando si usano flussi di dati per l'inserimento e la trasformazione dei dati, esistono scenari in cui è necessario aggiornare in modo specifico solo i dati nuovi o aggiornati, in particolare quando i dati continuano a crescere. La funzionalità di aggiornamento incrementale soddisfa questa esigenza consentendo di ridurre i tempi di aggiornamento, migliorare l'affidabilità evitando operazioni a esecuzione prolungata e ridurre al minimo l'utilizzo delle risorse.
Prerequisiti
Per usare l'aggiornamento incrementale in Dataflow Gen2, è necessario soddisfare i prerequisiti seguenti:
- È necessario avere una capacità Fabric.
- L'origine dati supporta la riduzione (scelta consigliata) e deve contenere una colonna Date/DateTime che può essere usata per filtrare i dati.
- È necessario disporre di una destinazione dati che supporta l'aggiornamento incrementale. Per altre informazioni, vedere Supporto di destinazione.
- Prima di iniziare, assicurarsi di aver esaminato le limitazioni dell'aggiornamento incrementale. Per altre informazioni, vedere Limitazioni.
Supporto di destinazione
Per l'aggiornamento incrementale sono supportate le destinazioni dati seguenti:
- Warehouse di Fabric
- database SQL di Azure
- Azure Synapse Analytics
Altre destinazioni come Lakehouse possono essere usate in combinazione con l'aggiornamento incrementale usando una seconda query che fa riferimento ai dati di staging per aggiornare la destinazione dei dati. In questo modo è comunque possibile usare l'aggiornamento incrementale per ridurre la quantità di dati da elaborare e recuperare dal sistema di origine. È tuttavia necessario eseguire un aggiornamento completo dai dati di staging alla destinazione dati.
Come usare l'aggiornamento incrementale
Creare un nuovo flusso di dati Gen2 o aprire un flusso di dati esistente Gen2.
Nell'editor del flusso di dati creare una nuova query che recupera i dati da aggiornare in modo incrementale.
Controllare l'anteprima dei dati per assicurarsi che la query restituisca dati contenenti una colonna DateTime, Date o DateTimeZone che è possibile usare per filtrare i dati.
Assicurarsi che la query si ripieghi completamente, il che significa che la query viene completamente inserita nel sistema di origine. Se la query non si riduce completamente, è necessario modificare la query in modo che venga completamente piegata. È possibile assicurarsi che la query si ripieghi completamente controllando i passaggi della query nell'editor di query.
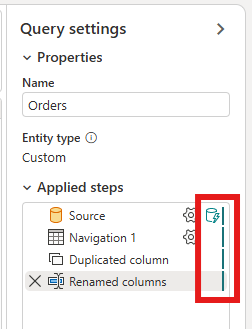
Fare clic con il pulsante destro del mouse sulla query e scegliere Aggiornamento incrementale.
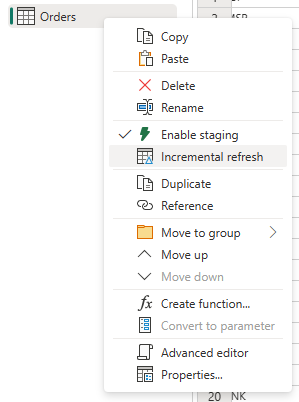
Specificare le impostazioni necessarie per l'aggiornamento incrementale.
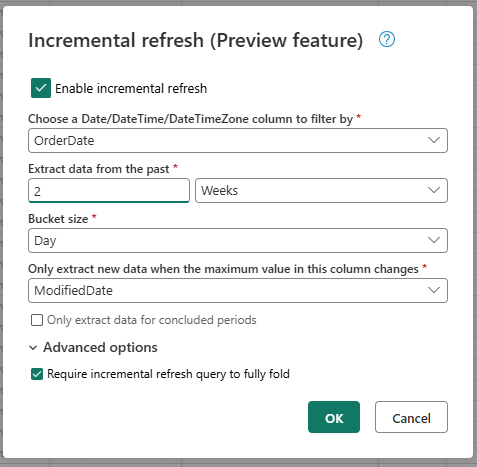
- Scegliere una colonna DateTime per cui filtrare.
- Estrarre dati dal passato.
- Dimensioni del bucket.
- Estrarre nuovi dati solo quando cambia il valore massimo in questa colonna.
Configurare le impostazioni avanzate, se necessario.
- Richiedere la riduzione completa della query di aggiornamento incrementale.
Scegliere OK per salvare le impostazioni.
Se si vuole, è ora possibile configurare una destinazione dati per la query. Assicurarsi di eseguire questa configurazione prima del primo aggiornamento incrementale, in caso contrario la destinazione dei dati contiene solo i dati modificati in modo incrementale dopo l'ultimo aggiornamento.
Pubblicare Dataflow Gen2.
Dopo aver configurato l'aggiornamento incrementale, il flusso di dati aggiorna automaticamente i dati in modo incrementale in base alle impostazioni specificate. Il flusso di dati recupera solo i dati modificati dall'ultimo aggiornamento. Il flusso di dati viene quindi eseguito più velocemente e utilizza meno risorse.
Funzionamento dell'aggiornamento incrementale in background
L'aggiornamento incrementale funziona dividendo i dati in bucket in base alla colonna DateTime. Ogni bucket contiene i dati modificati dopo l'ultimo aggiornamento. Il flusso di dati sa cosa è cambiato controllando il valore massimo nella colonna specificata. Se il valore massimo è stato modificato per tale bucket, il flusso di dati recupera l'intero bucket e sostituisce i dati nella destinazione. Se il valore massimo non è stato modificato, il flusso di dati non recupera dati. Le sezioni seguenti contengono una panoramica generale del funzionamento dettagliato dell'aggiornamento incrementale.
Primo passaggio: Valutare le modifiche
Quando il flusso di dati viene eseguito, valuta prima le modifiche nell'origine dati. Esegue questa valutazione confrontando il valore massimo nella colonna DateTime con il valore massimo nell'aggiornamento precedente. Se il valore massimo è stato modificato o se è il primo aggiornamento, il flusso di dati contrassegna il bucket come modificato e lo elenca per l'elaborazione. Se il valore massimo non è stato modificato, il flusso di dati ignora il bucket e non lo elabora.
Secondo passaggio: Recuperare i dati
Il flusso di dati è ora pronto per recuperare i dati. Recupera i dati per ogni bucket modificato. Il flusso di dati esegue questo recupero in parallelo per migliorare le prestazioni. Il flusso di dati recupera i dati dal sistema di origine e lo carica nell'area di gestione temporanea. Il flusso di dati recupera solo i dati inclusi nell'intervallo di bucket. In altre parole, il flusso di dati recupera solo i dati modificati dopo l'ultimo aggiornamento.
Ultimo passaggio: Sostituire i dati nella destinazione dati
Il flusso di dati sostituisce i dati nella destinazione con i nuovi dati. Il flusso di dati usa il replace metodo per sostituire i dati nella destinazione. Ovvero, il flusso di dati elimina prima i dati nella destinazione per tale bucket e quindi inserisce i nuovi dati. Il flusso di dati non influisce sui dati esterni all'intervallo di bucket. Pertanto, se si dispone di dati nella destinazione precedente al primo bucket, l'aggiornamento incrementale non influisce in alcun modo su questi dati.
Spiegazione delle impostazioni di aggiornamento incrementale
Per configurare l'aggiornamento incrementale, è necessario specificare le impostazioni seguenti.
Impostazioni generali
Le impostazioni generali sono necessarie e specificano la configurazione di base per l'aggiornamento incrementale.
Scegliere una colonna DateTime per cui filtrare
Questa impostazione è obbligatoria e specifica la colonna usata dai flussi di dati per filtrare i dati. Questa colonna deve essere una colonna DateTime, Date o DateTimeZone. Il flusso di dati usa questa colonna per filtrare i dati e recupera solo i dati modificati dopo l'ultimo aggiornamento.
Estrarre dati dal passato
Questa impostazione è obbligatoria e specifica il tempo in cui il flusso di dati deve estrarre i dati. Questa impostazione viene utilizzata per recuperare il caricamento iniziale dei dati. Il flusso di dati recupera tutti i dati dal sistema di origine compreso nell'intervallo di tempo specificato. I valori possibili sono:
- x giorni
- x settimane
- x mesi
- x trimestri
- x anni
Ad esempio, se si specifica 1 mese, il flusso di dati recupera tutti i nuovi dati dal sistema di origine compreso nell'ultimo mese.
Dimensioni del bucket
Questa impostazione è obbligatoria e specifica le dimensioni dei bucket usati dal flusso di dati per filtrare i dati. Il flusso di dati divide i dati in bucket in base alla colonna DateTime. Ogni bucket contiene i dati modificati dopo l'ultimo aggiornamento. Le dimensioni del bucket determinano la quantità di dati elaborati in ogni iterazione. Una dimensione del bucket più piccola significa che il flusso di dati elabora meno dati in ogni iterazione, ma significa anche che sono necessarie più iterazioni per elaborare tutti i dati. Una dimensione del bucket maggiore significa che il flusso di dati elabora più dati in ogni iterazione, ma significa anche che per elaborare tutti i dati sono necessarie meno iterazioni.
Estrarre nuovi dati solo quando cambia il valore massimo in questa colonna
Questa impostazione è obbligatoria e specifica la colonna usata dal flusso di dati per determinare se i dati sono stati modificati. Il flusso di dati confronta il valore massimo in questa colonna con il valore massimo nell'aggiornamento precedente. Se il valore massimo viene modificato, il flusso di dati recupera i dati modificati dopo l'ultimo aggiornamento. Se il valore massimo non viene modificato, il flusso di dati non recupera dati.
Estrarre solo i dati per i periodi conclusi
Questa impostazione è facoltativa e specifica se il flusso di dati deve estrarre solo i dati per i periodi conclusi. Se questa impostazione è abilitata, il flusso di dati estrae solo i dati per i periodi che hanno concluso. Il flusso di dati estrae quindi solo i dati per i periodi completati e non contengono dati futuri. Se questa impostazione è disabilitata, il flusso di dati estrae i dati per tutti i periodi, inclusi i periodi che non sono stati completati e contengono dati futuri.
Ad esempio, se si dispone di una colonna DateTime che contiene la data della transazione e si desidera aggiornare solo i mesi completi, è possibile abilitare questa impostazione in combinazioni con le dimensioni del bucket di month. Di conseguenza, il flusso di dati estrae solo i dati per mesi completi e non estrae i dati per mesi incompleti.
Impostazioni avanzate
Alcune impostazioni sono considerate avanzate e non sono necessarie per la maggior parte degli scenari.
Richiedere la riduzione completa della query di aggiornamento incrementale
Questa impostazione è facoltativa e specifica se la query usata per l'aggiornamento incrementale deve essere completamente piegata. Se questa impostazione è abilitata, la query usata per l'aggiornamento incrementale deve essere completamente piegata. In altre parole, la query deve essere completamente inserita nel sistema di origine. Se questa impostazione è disabilitata, la query usata per l'aggiornamento incrementale non deve essere completamente piegata. In questo caso, la query può essere parzialmente inserita nel sistema di origine. È consigliabile abilitare questa impostazione per migliorare le prestazioni per evitare il recupero di dati non necessari e non filtrati.
Limiti
Sono supportate solo le destinazioni dati basate su SQL
Attualmente, solo le destinazioni dati basate su SQL sono supportate per l'aggiornamento incrementale. È quindi possibile usare Fabric Warehouse, database SQL di Azure o Azure Synapse Analytics solo come destinazione dati per l'aggiornamento incrementale. Il motivo di questa limitazione è che queste destinazioni dati supportano le operazioni basate su SQL necessarie per l'aggiornamento incrementale. Si usano le operazioni Elimina e Inserisci per sostituire i dati nella destinazione dei dati, che non possono essere eseguiti in parallelo su altre destinazioni dati.
La destinazione dei dati deve essere impostata su uno schema fisso
La destinazione dei dati deve essere impostata su uno schema fisso, il che significa che lo schema della tabella nella destinazione dati deve essere corretto e non può cambiare. Se lo schema della tabella nella destinazione dati è impostato sullo schema dinamico, è necessario modificarlo in uno schema fisso prima di configurare l'aggiornamento incrementale.
L'unico metodo di aggiornamento supportato nella destinazione dati è replace
L'unico metodo di aggiornamento supportato nella destinazione dati è replace, il che significa che il flusso di dati sostituisce i dati per ogni bucket nella destinazione dati con i nuovi dati. Tuttavia, i dati esterni all'intervallo di bucket non sono interessati. Pertanto, se si dispone di dati nella destinazione dati precedente al primo bucket, l'aggiornamento incrementale non influisce in alcun modo su questi dati.
Il numero massimo di bucket è 50 per una singola query e 150 per l'intero flusso di dati
Il numero massimo di bucket per query supportati dal flusso di dati è 50. Se sono presenti più di 50 bucket, è necessario aumentare le dimensioni del bucket o ridurre l'intervallo di bucket per ridurre il numero di bucket. Per l'intero flusso di dati, il numero massimo di bucket è 150. Se nel flusso di dati sono presenti più di 150 bucket, è necessario ridurre il numero di query di aggiornamento incrementale o aumentare le dimensioni del bucket per ridurre il numero di bucket.
Differenze tra l'aggiornamento incrementale in Dataflow Gen1 e Dataflow Gen2
Tra Dataflow Gen1 e Dataflow Gen2, esistono alcune differenze nel funzionamento dell'aggiornamento incrementale. L'elenco seguente illustra le principali differenze tra l'aggiornamento incrementale in Dataflow Gen1 e Dataflow Gen2.
- L'aggiornamento incrementale è ora una funzionalità di prima classe in Dataflow Gen2. In Dataflow Gen1 è stato necessario configurare l'aggiornamento incrementale dopo aver pubblicato il flusso di dati. In Dataflow Gen2 l'aggiornamento incrementale è ora una funzionalità di prima classe che è possibile configurare direttamente nell'editor del flusso di dati. Questa funzionalità semplifica la configurazione dell'aggiornamento incrementale e riduce il rischio di errori.
- In Dataflow Gen1 è necessario specificare l'intervallo di dati cronologici quando è stato configurato l'aggiornamento incrementale. In Dataflow Gen2 non è necessario specificare l'intervallo di dati cronologici. Il flusso di dati non rimuove dati dalla destinazione esterna all'intervallo di bucket. Pertanto, se si dispone di dati nella destinazione precedente al primo bucket, l'aggiornamento incrementale non influisce in alcun modo su questi dati.
- In Dataflow Gen1 è necessario specificare i parametri per l'aggiornamento incrementale quando è stato configurato l'aggiornamento incrementale. In Dataflow Gen2 non è necessario specificare i parametri per l'aggiornamento incrementale. Il flusso di dati aggiunge automaticamente i filtri e i parametri come ultimo passaggio della query. Non è quindi necessario specificare manualmente i parametri per l'aggiornamento incrementale.
Domande frequenti
È stato visualizzato un avviso che indica che è stata usata la stessa colonna per rilevare modifiche e filtri. Che cosa significa?
Se viene visualizzato un avviso che indica che è stata usata la stessa colonna per rilevare modifiche e filtri, significa che la colonna specificata per rilevare le modifiche viene usata anche per filtrare i dati. Questo utilizzo non è consigliato perché può causare risultati imprevisti. È invece consigliabile usare una colonna diversa per rilevare le modifiche e filtrare i dati. Se i dati si spostano tra bucket, il flusso di dati potrebbe non essere in grado di rilevare correttamente le modifiche e potrebbe creare dati duplicati nella destinazione. È possibile risolvere questo avviso usando una colonna diversa per rilevare le modifiche e filtrare i dati. In alternativa, è possibile ignorare l'avviso se si è certi che i dati non cambino tra gli aggiornamenti per la colonna specificata.
Si vuole usare l'aggiornamento incrementale con una destinazione dati non supportata. Cosa posso fare?
Se si vuole usare l'aggiornamento incrementale con una destinazione dati non supportata, è possibile abilitare l'aggiornamento incrementale nella query e usare una seconda query che fa riferimento ai dati di staging per aggiornare la destinazione dei dati. In questo modo, è comunque possibile usare l'aggiornamento incrementale per ridurre la quantità di dati che devono essere elaborati e recuperati dal sistema di origine, ma è necessario eseguire un aggiornamento completo dai dati di staging alla destinazione dati. Assicurarsi di configurare correttamente la finestra e le dimensioni del bucket perché non si garantisce che i dati nella gestione temporanea vengano conservati al di fuori dell'intervallo di bucket.
Ricerca per categorie sapere se l'aggiornamento incrementale della query è abilitato?
È possibile verificare se l'aggiornamento incrementale della query è abilitato selezionando l'icona accanto alla query nell'editor del flusso di dati. Se l'icona contiene un triangolo blu, l'aggiornamento incrementale è abilitato. Se l'icona non contiene un triangolo blu, l'aggiornamento incrementale non è abilitato.
L'origine ottiene troppe richieste quando si usa l'aggiornamento incrementale. Cosa posso fare?
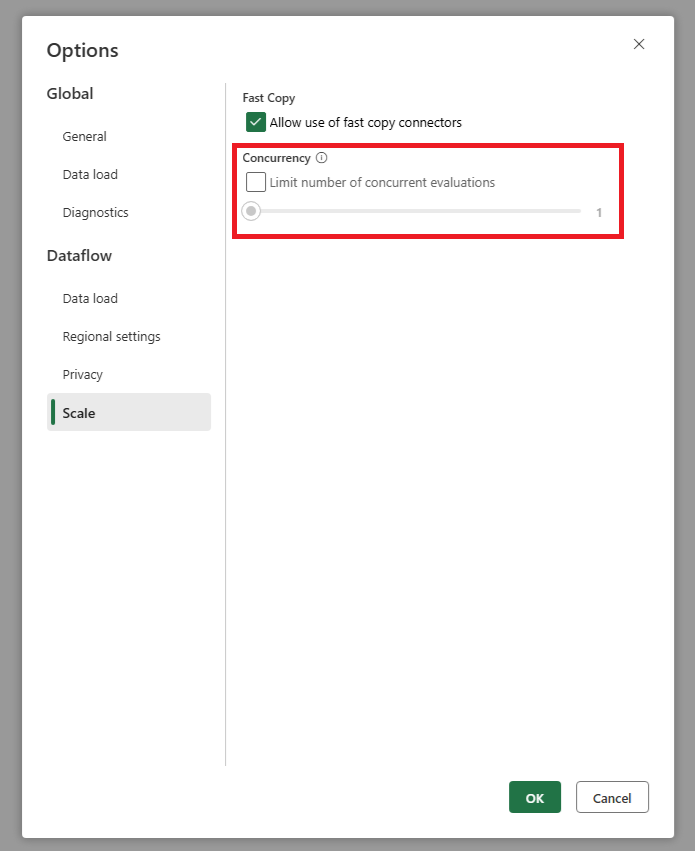
È stata aggiunta un'impostazione che consente di impostare il numero massimo di valutazioni di query parallele. Questa impostazione è disponibile nelle impostazioni globali del flusso di dati. Impostando questo valore su un numero inferiore, è possibile ridurre il numero di richieste inviate al sistema di origine. Questa impostazione consente di ridurre il numero di richieste simultanee e migliorare le prestazioni del sistema di origine. Per impostare il numero massimo di esecuzioni di query parallele, passare alle impostazioni globali del flusso di dati, passare alla scheda Scala e impostare il numero massimo di valutazioni di query parallele. È consigliabile non abilitare questo limite a meno che non si verifichino problemi con il sistema di origine.
Si vuole usare l'aggiornamento incrementale, ma si noterà che, dopo l'abilitazione, il flusso di dati richiede più tempo per l'aggiornamento. Cosa posso fare?
L'aggiornamento incrementale, come descritto in questo articolo, è progettato per ridurre la quantità di dati che devono essere elaborati e recuperati dal sistema di origine. Tuttavia, se il flusso di dati richiede più tempo per l'aggiornamento dopo l'abilitazione dell'aggiornamento incrementale, potrebbe essere dovuto al sovraccarico aggiuntivo di controllare se i dati sono cambiati e l'elaborazione dei bucket, che può essere superiore al tempo risparmiato elaborando meno dati. In questo caso, è consigliabile esaminare le impostazioni per l'aggiornamento incrementale e modificarle in base allo scenario in uso. Ad esempio, è possibile aumentare le dimensioni del bucket per ridurre il numero di bucket e il carico di elaborazione. In alternativa, è possibile ridurre il numero di bucket aumentando le dimensioni del bucket. Se si verificano ancora prestazioni ridotte dopo aver modificato le impostazioni, è possibile disabilitare l'aggiornamento incrementale e usare invece un aggiornamento completo, in quanto potrebbe essere più efficiente nello scenario.