Configurare Lakehouse in un'attività di copia
Questo articolo illustra come usare l'attività di copia in Azure Data Factory per copiare dati da e in Azure Data Lake Store. Per impostazione predefinita, i dati vengono scritti nella tabella Lakehouse in V-Order ed è possibile andare a Ottimizzazione delle tabella Delta Lake e V-Order per altre informazioni.
Formato supportato
Lakehouse supporta i formati di file seguenti. Per impostazioni basate sui formati, fare riferimento ai singoli articoli.
- Formato Avro
- Formato binario
- Formato di testo delimitato
- Formato Excel
- Formato JSON
- Formato ORC
- Formato Parquet
- Formato XML
Configurazione supportata
Per la configurazione di ogni scheda nell'attività Copy, leggere le rispettive sezioni seguenti.
Generali
Per configurazione della scheda Generale, passare a Generale.
Origine
Le proprietà seguenti sono supportate per Lakehouse nella scheda Origine di un'attività di copia.

Per ogni oggetto sono necessarie le proprietà seguenti:
Connessione: selezionare una connessione Lakehouse dall'elenco di connessioni. Se non esiste alcuna connessione, creare una nuova connessione Lakehouse selezionando Altro nella parte inferiore dell'elenco di connessioni. Se si applica Usa contenuto dinamico per specificare lakehouse, aggiungere un parametro e specificare l'ID oggetto Lakehouse come valore del parametro. Per ottenere l'ID oggetto Lakehouse, aprire lakehouse nell'area di lavoro e l'ID è dopo
/lakehouses/nell'URL.
Cartella radice: selezionare Tabelle o file, che indica la visualizzazione virtuale dell'area gestita o non gestita nel lago. Per altre informazioni, vedere Introduzione a Lakehouse.
Se si seleziona Tabelle:
Nome tabella: scegliere una tabella esistente dall'elenco di tabelle o specificare un nome di tabella come origine. In alternativa, è possibile selezionare Nuovo per creare una nuova tabella.

Tabella: quando si applica Lakehouse con schemi nella connessione, scegliere una tabella esistente con uno schema dall'elenco di tabelle o specificare una tabella con uno schema come origine. In alternativa, è possibile selezionare Nuovo per creare una nuova tabella con uno schema. Se non si specifica un nome di schema, il servizio userà dbo come schema predefinito.

Sotto Avanzate, è possibile specificare i campi seguenti:
- Timestamp: specificare per eseguire una query su uno snapshot precedente in base al timestamp.
- Versione: specificare per eseguire una query su uno snapshot precedente in base alla versione.
- Colonne aggiuntive: aggiungere altre colonne di dati al percorso relativo o al valore statico dei file di origine dell'archivio. L'espressione è supportata per quest'ultima.
È supportata la versione 1 del lettore. In questo articolo sono disponibili le funzionalità delta Lake supportate corrispondenti.
Se si seleziona File:
Tipo di percorso file: è possibile scegliere Percorso file, Percorso file con caratteri jolly o Elenco di file come tipo di percorso del file. L'elenco seguente descrive ogni parte della convenzione di denominazione:

Percorso file: selezionare Sfoglia per scegliere il file che si vuole copiare o compilare manualmente il percorso.
Percorso del file con caratteri jolly: specificare la cartella o il percorso del file con caratteri jolly nell'area non gestita di Lakehouse specificata (in File) per filtrare le cartelle o i file di origine. I caratteri jolly consentiti sono:
*(corrispondenza di zero o più caratteri) e?(corrispondenza di zero caratteri o di un carattere singolo). Usare^per applicare una sequenza di escape se il nome della cartella include caratteri jolly o tale carattere di escape.Percorso cartella con caratteri jolly: Percorso della cartella nel contenitore specificato. Se si intende usare un carattere jolly per filtrare la cartella, ignorare questa impostazione e specificarla nelle impostazioni di origine dell'attività.
Nome file con caratteri jolly: nome del file nell'area non gestita specificata di Lakehouse (in File) e nel percorso della cartella.

Elenco di file: Indica di copiare un determinato set di file.
- Percorso cartella: punta a una cartella che include i file da copiare.
- Percorso per la lista di file: Puntare a un file di testo che include un elenco di file da copiare, un file per riga, che rappresenta il percorso relativo del percorso configurato nel set di dati.

Ricorsivo: Indica se i dati vengono letti in modo ricorsivo dalle cartelle secondarie o solo dalla cartella specificata. Se abilitata, tutti i file nella cartella di input e le relative sottocartelle vengono elaborati in modo ricorsivo. Questa proprietà non si applica quando si configura il tipo di percorso del file come elenco di file.
Formato file: selezionare il formato di file dall'elenco a discesa. Selezionare il pulsante Configura per salvare l'impostazione. Per le impostazioni di formati di file diversi, vedere articoli in Formato supportato per informazioni dettagliate.
Sotto Avanzate, è possibile specificare i campi seguenti:
- Filtro in base all'ultima modifica: i file vengono filtrati in base alle date dell'ultima modifica. Questa proprietà non si applica quando si configura il tipo di percorso del file come elenco di file.
- Ora di inizio: i file vengono selezionati se l'ora dell'ultima modifica è maggiore o uguale all'ora configurata.
- Ora di fine: i file vengono selezionati se l'ora dell'ultima modifica è inferiore all'ora configurata.
- Abilitare l'individuazione delle partizioni: Per i file partizionati, specificare se analizzare le partizioni dal percorso del file e aggiungerle come colonne di origine aggiuntive.
- Percorso radice della partizione: quando l'individuazione delle partizioni è abilitata, specificare il percorso radice assoluto per leggere le cartelle partizionate come colonne di dati.
- Connessioni massime simultanee: il limite massimo di connessioni simultanee stabilite all'archivio dati durante l'esecuzione dell'attività. Specificare un valore solo quando si desidera limitare le connessioni simultanee.
- Filtro in base all'ultima modifica: i file vengono filtrati in base alle date dell'ultima modifica. Questa proprietà non si applica quando si configura il tipo di percorso del file come elenco di file.



Destinazione
Le proprietà seguenti sono supportate per Lakehouse nella scheda Destinazione di un'attività di copia.

Per ogni oggetto sono necessarie le proprietà seguenti:
Connessione: selezionare una connessione Lakehouse dall'elenco di connessioni. Se non esiste alcuna connessione, creare una nuova connessione Lakehouse selezionando Altro nella parte inferiore dell'elenco di connessioni. Se si applica Usa contenuto dinamico per specificare lakehouse, aggiungere un parametro e specificare l'ID oggetto Lakehouse come valore del parametro. Per ottenere l'ID oggetto Lakehouse, aprire lakehouse nell'area di lavoro e l'ID è dopo
/lakehouses/nell'URL.
Cartella radice: selezionare Tabelle o file, che indica la visualizzazione virtuale dell'area gestita o non gestita nel lago. Per altre informazioni, vedere Introduzione a Lakehouse.
Se si seleziona Tabelle:
Nome tabella: scegliere una tabella esistente dall'elenco di tabelle o specificare un nome di tabella come origine. In alternativa, è possibile selezionare Nuovo per creare una nuova tabella.
Tabella: quando si applica Lakehouse con schemi nella connessione, scegliere una tabella esistente con uno schema dall'elenco di tabelle o specificare una tabella con uno schema come destinazione. In alternativa, è possibile selezionare Nuovo per creare una nuova tabella con uno schema. Se non si specifica un nome di schema, il servizio userà dbo come schema predefinito.
Sotto Avanzate, è possibile specificare i campi seguenti:
Azioni tabella: specificare l'operazione sulla tabella selezionata.
Accoda: accoda nuovi valori alla tabella esistente.
- Abilita partizione: questa selezione consente di creare partizioni in una struttura di cartelle in base a una o più colonne. Ogni valore di colonna distinto (coppia) è una nuova partizione. Ad esempio, "year=2000/month=01/file".
- Nome colonna partizione: selezionare tra le colonne di destinazione nel mapping degli schemi quando si aggiungono dati a una nuova tabella. Quando si aggiungono dati a una tabella esistente che dispone già di partizioni, le colonne di partizione vengono derivate automaticamente dalla tabella esistente. I tipi supportati sono stringa, intero e booleano. Il formato rispetta le impostazioni di conversione dei tipi nella scheda Mapping.
- Abilita partizione: questa selezione consente di creare partizioni in una struttura di cartelle in base a una o più colonne. Ogni valore di colonna distinto (coppia) è una nuova partizione. Ad esempio, "year=2000/month=01/file".
Sovrascrittura: sovrascrivere i dati e lo schema esistenti nella tabella usando i nuovi valori. Se questa operazione è selezionata, è possibile abilitare la partizione nella tabella di destinazione:
- Abilita partizione: questa selezione consente di creare partizioni in una struttura di cartelle in base a una o più colonne. Ogni valore di colonna distinto (coppia) è una nuova partizione. Ad esempio, "year=2000/month=01/file".
- Nome colonna partizione: selezionare tra le colonne di destinazione nel mapping degli schemi quando si aggiungono dati a una nuova tabella. I tipi supportati sono stringa, intero e booleano. Il formato rispetta le impostazioni di conversione dei tipi nella scheda Mapping.
Supporto dello spostamento cronologico di Delta Lake. La tabella sovrascritta include log differenziali per le versioni precedenti, a cui è possibile accedere in Lakehouse. È anche possibile copiare la tabella della versione precedente da Lakehouse specificando Version nell'origine dell'attività di copia.
- Abilita partizione: questa selezione consente di creare partizioni in una struttura di cartelle in base a una o più colonne. Ogni valore di colonna distinto (coppia) è una nuova partizione. Ad esempio, "year=2000/month=01/file".
Connessioni massime simultanee: il limite massimo di connessioni simultanee stabilite all'archivio dati durante l'esecuzione dell'attività. Specificare un valore solo quando si desidera limitare le connessioni simultanee.
È supportata la versione 2 del writer. In questo articolo sono disponibili le funzionalità delta Lake supportate corrispondenti.
Se si seleziona File:
Percorso file: selezionare Sfoglia per scegliere il file che si vuole copiare o compilare manualmente il percorso.

Formato file: selezionare il formato di file dall'elenco a discesa. Selezionare Impostazioni per configurare il formato di file. Per le impostazioni di formati di file diversi, vedere gli articoli in Formato supportato per informazioni dettagliate.
Sotto Avanzate, è possibile specificare i campi seguenti:
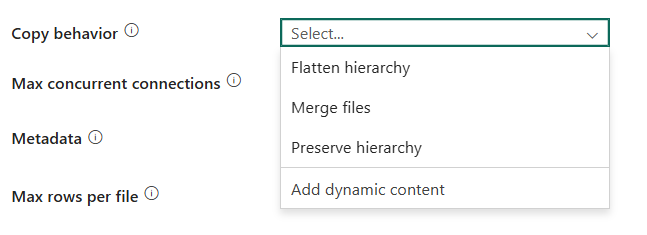
Comportamento di copia: si definisce comportamento di copia quando l'origine è costituita da file di un archivio dati basato su file. È possibile scegliere Appiattire la gerarchia, Unione dei file, Mantieni gerarchia o Aggiungi contenuto dinamico come comportamento di copia. La configurazione di ogni impostazione è:
- FlattenHierarchy: tutti i file della cartella di origine si trovano nel primo livello della cartella di destinazione. I nomi dei file di destinazione vengono generati automaticamente.
Unire i file: unisce tutti i file della cartella di origine in un solo file. Se si specifica il nome di file, il nome del file unito sarà il nome specificato. In caso contrario, verrà usato un nome di file generato automaticamente.
PreserveHierarchy: mantiene la gerarchia dei file nella cartella di destinazione. Il percorso relativo del file di origine nella cartella di origine è identico al percorso relativo del file di destinazione nella cartella di destinazione.
Aggiungi contenuto dinamico: per specificare un'espressione per un valore della proprietà, selezionare Aggiungi contenuto dinamico. Viene visualizzato il Generatore di espressioni di Data Factory in cui è possibile generare espressioni dalle variabili di sistema supportate, dall'output delle attività, dalle funzioni e da variabili o parametri specificati dall'utente. Per informazioni sulla lingua delle espressioni, vedere Espressioni e funzioni in Azure Data Factory.
Connessioni massime simultanee: il limite massimo di connessioni simultanee stabilite all'archivio dati durante l'esecuzione dell'attività. Specificare un valore solo quando si desidera limitare le connessioni simultanee.
Dimensioni blocco (MB): specificare le dimensioni del blocco in MB durante la scrittura di dati in Lakehouse. Il valore consentito è compreso tra 4 e 100 MB.
Metadati: impostare metadati personalizzati durante la copia nell'archivio dati di destinazione. Ogni oggetto nella matrice
metadatarappresenta una colonna aggiuntiva.namedefinisce il nome della chiave di metadati mentrevalueindica il valore dei dati di tale chiave. Se viene usata la funzionalità per mantenere gli attributi, i metadati specificati verranno uniti/sovrascritti con i metadati del file di origine. I valori dei dati consentiti sono:$$LASTMODIFIED: una variabile riservata indica di archiviare data/ora dell'ultima modifica dei file di origine. Si applica all'origine basata su file solo con formato binario.Espressione
Valore statico




Mapping
Per la configurazione della scheda Mapping , se non si applica la tabella Lakehouse come archivio dati di destinazione, passare a Mapping.
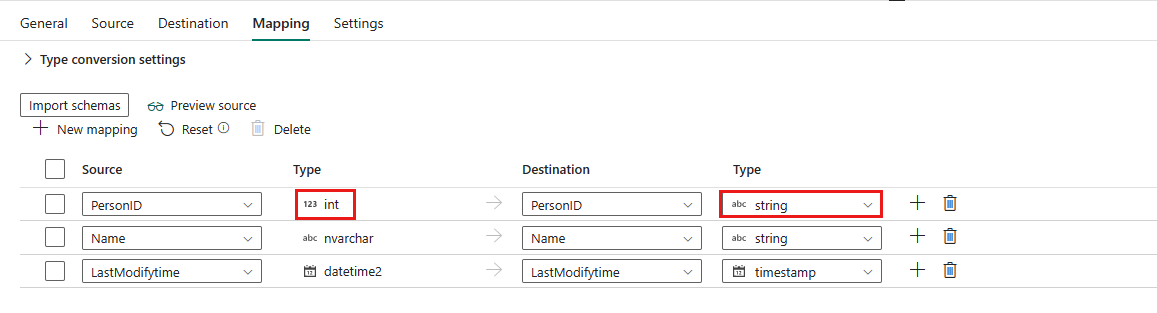
Se si applica la tabella Lakehouse come archivio dati di destinazione, ad eccezione della configurazione in Mapping, è possibile modificare il tipo per le colonne di destinazione. Dopo aver selezionato Importa schemi, è possibile specificare il tipo di colonna nella destinazione.
Ad esempio, il tipo per la colonna PersonID nell'origine è int ed è possibile modificarlo in tipo stringa quando si esegue il mapping alla colonna di destinazione.
Nota
La modifica del tipo di destinazione non è attualmente supportata quando l'origine è di tipo decimale.
Se si sceglie Binary come formato di file, il mapping non è supportato.
Impostazione
Per la configurazione della scheda Impostazioni, passare a Impostazioni.
Tabella di riepilogo
Le tabelle seguenti contengono altre informazioni su un'attività di copia in Lakehouse.
Informazioni sull'origine
| Nome | Descrizione | valore | Richiesto | Proprietà script JSON |
|---|---|---|---|---|
| Connessione | Selezionare Seleziona per creare la connessione. | < connessione lakehouse> | Sì | workspaceId artifactId |
| Cartella radice | Tipo della radice. | • Tabelle • File |
No | rootFolder: Tabella o file |
| Nome tabella | Immettere il nome della tabella che si desidera utilizzare come set di dati. | <nome alla tua tabella> | Sì quando si seleziona Tabelle nella cartella radice | table |
| Tabella | Nome della tabella con uno schema che si desidera leggere i dati quando si applica Lakehouse con schemi come connessione. | <tabella con uno schema> | Sì quando si seleziona Tabelle nella cartella radice | / |
| Per le tabelle | ||||
| Nome schema | Nome dello schema. | <nome dello schema> (Lo schema è dbo) |
No | (in source ->datasetSettings ->typeProperties)schema |
| Nome tabella | Nome della tabella. | <nome alla tua tabella> | Sì | table |
| Timestamp: | Timestamp per eseguire una query su uno snapshot precedente. | <timestamp> | No | timestampAsOf |
| Versione | Versione per eseguire una query su uno snapshot precedente. | <version> | No | versionAsOf |
| Colonne aggiuntive | Colonne di dati aggiuntive per archiviare il percorso relativo o il valore statico dei file di origine. L'espressione è supportata per quest'ultima. | • Name • Valore |
No | additionalColumns: • name • Valore |
| Tipo percorso file | Tipo del percorso del file utilizzato. | • Percorso di file • Percorso file con caratteri jolly • Elenco di file |
Sì quando si seleziona File nella cartella radice | / |
| Percorso file | Copiare dal percorso a una cartella o un file nell'archivio dati di origine. | <Percorso file> | Sì quando si sceglie Percorso file | folderPath :r nome file |
| Percorsi con caratteri jolly | Percorso della cartella con caratteri jolly nel bucket specificato configurato nel set di dati per filtrare le cartelle di origine. | <Percorsi con caratteri jolly> | Sì quando si sceglie il percorso del file con caratteri jolly | • wildcardFolderPath • wildcardFileName |
| Percorso cartella | Punta a una cartella che include i file da copiare. | <Percorso cartella> | No | folderPath |
| Percorso dell’elenco di file | Indica di copiare un determinato set di file. Puntare a un file di testo che include un elenco di file da copiare, un file per riga, che rappresenta il percorso relativo del percorso configurato nel set di dati. | <Percorso dell'elenco di file> | No | fileListPath |
| Ricorsivo | Elaborare tutti i file nella cartella di input e nelle relative sottocartelle in modo ricorsivo o solo quelli nella cartella selezionata. Questa impostazione è disabilitata quando viene selezionato un singolo file. | Selezionare o deselezionare | No | recursive: true o false |
| Formato di file | Formato di file per i dati di origine. Per informazioni sui diversi formati di file, vedere articoli in Formato supportato per informazioni dettagliate. | / | Sì quando si seleziona File nella cartella radice | / |
| Filtra per data ultima modifica | I file con ora dell'ultima modifica nell'intervallo (Ora di inizio, Ora di fine) verranno filtrati per un'ulteriore elaborazione. L'ora viene applicata con il fuso orario UTC e il formato yyyy-mm-ddThh:mm:ss.fffZ.Queste proprietà possono essere ignorate, a indicare che non viene applicato alcun filtro di attributo di file. Questa proprietà non si applica quando si configura il tipo di percorso del file come elenco di file. |
• Ora di avvio • Ora di fine |
No | modifiedDatetimeStart modifiedDatetimeEnd |
| Abilitare l'individuazione delle partizioni | Per i file partizionati, specificare se analizzare le partizioni dal percorso del file e aggiungerle come colonne di origine aggiuntive. | Selezionato o non selezionato | No | enablePartitionDiscovery: true o false (valore predefinito) |
| Partition Root Path (Percorso radice partizione) | Quando l'individuazione delle partizioni è abilitata, specificare il percorso radice assoluto per leggere le cartelle partizionate come colonne di dati. | <Partizione Percorso radice> | No | partitionRootPath |
| Numero massimo di connessioni simultanee | Limite massimo di connessioni simultanee stabilite all'archivio dati durante l'esecuzione dell'attività. Specificare un valore solo quando si desidera limitare le connessioni simultanee. | <Numero massimo di connessioni simultanee> | No | maxConcurrentConnections |
Informazioni sulla destinazione
| Nome | Descrizione | valore | Richiesto | Proprietà script JSON |
|---|---|---|---|---|
| Connessione | Selezionare Seleziona per creare la connessione. | < connessione lakehouse> | Sì | workspaceId artifactId |
| Cartella radice | Tipo della radice. | • Tabelle • File |
Sì | rootFolder: Tabella o file |
| Nome tabella | Nome della tabella in cui si desidera scrivere i dati. | <nome alla tua tabella> | Sì quando si seleziona Tabelle nella cartella radice | table |
| Tabella | Nome della tabella con uno schema in cui si desidera scrivere dati quando si applica Lakehouse con schemi come connessione. | <tabella con uno schema> | Sì quando si seleziona Tabelle nella cartella radice | / |
| Per le tabelle | ||||
| Nome schema | Nome dello schema. | <nome dello schema> (Lo schema è dbo) |
No | (in sink ->datasetSettings ->typeProperties)schema |
| Nome tabella | Nome della tabella. | <nome alla tua tabella> | Sì | table |
| Azione Tabella | Aggiungere nuovi valori a una tabella esistente o sovrascrivere i dati e lo schema esistenti nella tabella usando i nuovi valori. | • Accodamento • Sovrascrivi |
No | tableActionOption: Accodare o sovrascrivereSchema |
| Abilitare le partizioni | Questa selezione consente di creare partizioni in una struttura di cartelle in base a una o più colonne. Ogni valore di colonna distinto (coppia) è una nuova partizione. Ad esempio, "year=2000/month=01/file". | Selezionato o non selezionato | No | partitionOptions: PartitionByKey o Nessuno |
| Colonne di partizione | Colonne di destinazione nel mapping degli schemi. | <Le tue colonne di partizione> | No | partitionNameList |
| Percorso file | Scrivere dati nel percorso di una cartella o di un file nell'archivio dati di destinazione. | <Percorso file> | No | folderPath :r nome file |
| Formato di file | Formato di file per i dati di destinazione. Per informazioni sui diversi formati di file, vedere articoli in Formato supportato per informazioni dettagliate. | / | Sì quando si seleziona File nella cartella radice | / |
| Comportamento di copia | Definisce il comportamento di copia quando l'origine è costituita da file di un archivio dati basato su file. | • Appiattire la gerarchia • Unire i file • Preserve hierarchy • Aggiungi contenuto dinamico |
No | copyBehavior: flattenHierarchy mergeFiles preserveHierarchy |
| Numero massimo di connessioni simultanee | Limite massimo di connessioni simultanee stabilite all'archivio dati durante l'esecuzione dell'attività. Specificare un valore solo quando si desidera limitare le connessioni simultanee. | <Numero massimo di connessioni simultanee> | No | maxConcurrentConnections |
| Dimensioni blocco (in MB) | Specificare le dimensioni del blocco in MB usate per scrivere dati in Microsoft Fabric Lakehouse. Il valore consentito è compreso tra 4 e 100 MB. | <Dimensioni blocco> | No | blockSizeInMB |
| Metadati UFX | Set di metadati personalizzati durante la copia in una destinazione. | • $$LASTMODIFIEDEspressioni Valore statico |
No | metadata |