Configurare il data warehouse in un'attività di copia
Questo articolo descrive come utilizzare l'attività di copia nella pipeline di dati per copiare dati da e verso un data warehouse.
Configurazione supportata
Per la configurazione di ogni scheda nell'attività Copy, leggere le rispettive sezioni seguenti.
Generali
Per configurazione della scheda Generale, passare a Generale.
Origine
Le seguenti proprietà sono supportate per Data Warehouse come Origine in un'attività di copia.
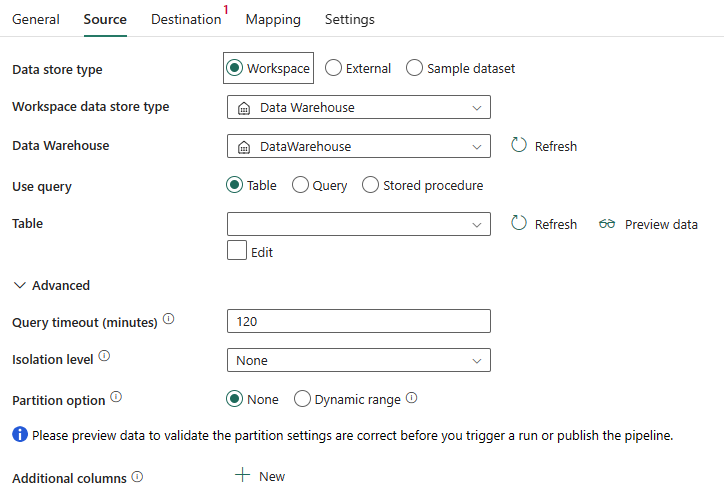
Per ogni oggetto sono necessarie le proprietà seguenti:
Tipo di archivio dati: selezionare Area di lavoro.
Tipo di archivio dati dell'area di lavoro: selezionare Data Warehouse dall'elenco dei tipi di archivio dati.
Data Warehouse: selezionare un data warehouse esistente dall'area di lavoro.
Usa query: selezionare Tabella, Query o Stored procedure.
Se si seleziona Tabella, scegliere una tabella esistente dall'elenco di tabelle o specificare manualmente un nome di tabella selezionando la casella Modifica.

Se si seleziona Query, usare l'editor di query SQL personalizzato per scrivere una query SQL che recupera i dati di origine.

Se si seleziona Stored procedure, scegliere una stored procedure esistente dall'elenco a discesa oppure specificare un nome di stored procedure come origine selezionando la casella Modifica.

In Avanzato è possibile specificare i seguenti campi:
Timeout query (minuti): timeout per l'esecuzione del comando di query, con un valore predefinito di 120 minuti. Se questa proprietà è impostata, i valori consentiti sono nel formato di un intervallo di tempo, ad esempio "02:00:00" (120 minuti).
Livello di isolamento: specificare il comportamento di blocco della transazione per l'origine SQL.
Opzione di partizione: specificare le opzioni di partizionamento dei dati usate per caricare i dati dal data warehouse. È possibile selezionare Nessuno o Intervallo dinamico.
Se si seleziona Intervallo dinamico, è necessario il parametro di partizione a intervalli(
?AdfDynamicRangePartitionCondition) quando si usa la query con la copia parallela abilitata. Query di esempio:SELECT * FROM <TableName> WHERE ?AdfDynamicRangePartitionCondition.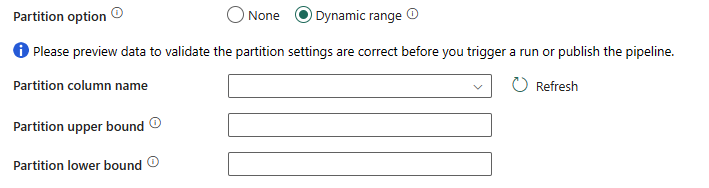
- Nome della colonna di partizione: specificare il nome della colonna di origine in formato intero o di tipo data/datetime (
int,smallint,bigint,date,smalldatetime,datetime,datetime2odatetimeoffset) utilizzata dal partizionamento per intervalli per la copia parallela. Se non specificato, l'indice o la chiave primaria della tabella vengono rilevati automaticamente e usati come colonna di partizione. - Limite massimo della partizione: valore massimo della colonna di partizione per la suddivisione dell'intervallo di partizioni. Questo valore viene usato per decidere lo stride di partizione, non per filtrare le righe nella tabella. Tutte le righe nella tabella o nel risultato della query vengono partizionate e copiate.
- Limite minimo della partizione: valore minimo della colonna di partizione per la suddivisione dell'intervallo di partizioni. Questo valore viene usato per decidere lo stride di partizione, non per filtrare le righe nella tabella. Tutte le righe nella tabella o nel risultato della query vengono partizionate e copiate.
- Nome della colonna di partizione: specificare il nome della colonna di origine in formato intero o di tipo data/datetime (
Colonne aggiuntive: aggiungere altre colonne di dati per archiviare il percorso relativo o il valore statico dei file di origine. L'espressione è supportata per la seconda opzione.


Destinazione
Le proprietà seguenti sono supportate per Data Warehouse come Destinazione in un'attività di copia.
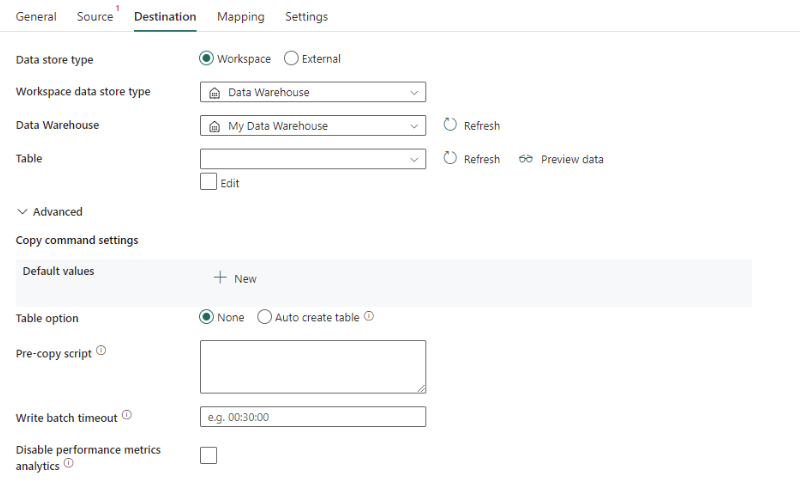
Sono richieste le seguenti proprietà:
- Tipo di archivio dati: selezionare Area di lavoro.
- Tipo di archivio dati dell'area di lavoro: selezionare Data Warehouse dall'elenco dei tipi di archivio dati.
- Data Warehouse: selezionare un data warehouse esistente dall'area di lavoro.
- Tabella: scegliere una tabella esistente dall'elenco di tabelle o specificare un nome di tabella come destinazione.
In Avanzato è possibile specificare i seguenti campi:
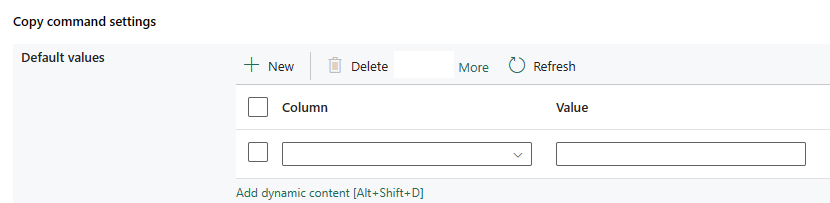
Impostazioni del comando COPY: specificare le proprietà del comando COPY.
Opzioni tabella: specificare se creare automaticamente la tabella di destinazione, se non esiste, in base allo schema di origine. È possibile selezionare Nessuna o Crea tabella automaticamente.
Script di pre-copia: specificare una query SQL da eseguire prima di scrivere i dati nel data warehouse a ogni esecuzione. Usare questa proprietà per pulire i dati precaricati.
Timeout batch di scrittura: il tempo di attesa per il completamento dell'operazione di inserimento batch prima del timeout. I valori consentiti sono nel formato di un intervallo di tempo. Il valore predefinito è "00:30:00" (30 minuti).
Disattiva l'analisi delle metriche delle prestazioni: il servizio raccoglie metriche per ottimizzare le prestazioni di copia e i relativi consigli. Se questo comportamento suscita preoccupazione, disattivare questa funzionalità.
copia diretta
L'istruzione COPY è il modo principale per inserire i dati nelle tabelle warehouse. Il comando COPY del data warehouse supporta direttamente Archiviazione BLOB di Azure e Azure Data Lake Storage Gen2 come archivi dati di origine. Se i dati di origine soddisfano i criteri descritti in questa sezione, utilizzare il comando COPY per copiarli direttamente dall'archivio dati di origine al data warehouse.
I dati di origine e il formato contengono i seguenti tipi e metodi di autenticazione:
Tipo di archivio dati di origine supportato Formato supportato Tipo di autenticazione di origine supportato Archiviazione BLOB di Azure Testo delimitato
ParquetAutenticazione anonima
Autenticazione basata sulla chiave dell'account
Autenticazione con firma di accesso condivisoAzure Data Lake Storage Gen2 Testo delimitato
ParquetAutenticazione basata sulla chiave dell'account
Autenticazione con firma di accesso condivisoÈ possibile impostare le seguenti impostazioni del formato:
- Per Parquet: il tipo di compressione può essere Nessuna, Snappy o Gzip.
- Per DelimitedText:
- Delimitatore di riga: quando si copia testo delimitato nel data warehouse tramite il comando COPY diretto, specificare il delimitatore di riga in modo esplicito (\r; \n; o \r\n). Il valore predefinito (\r, \n o \r\n) funziona solo quando il delimitatore di riga del file di origine è \r\n. In caso contrario, abilitare la gestione temporanea per lo scenario.
- Il valore null viene lasciato come predefinito o impostato su una stringa vuota ("").
- La codifica viene mantenuta come predefinita o impostata su UTF-8 o UTF-16.
- Il conteggio delle righe ignorate viene lasciato come predefinito o impostato su 0.
- Il tipo di compressione può essere Nessuno o gzip.
Se l'origine è una cartella, è necessario selezionare la casella di controllo In modo ricorsivo.
L'ora di inizio (UTC) e l'ora di fine (UTC) in Filtra in base all'ultima modifica, Prefisso, Abilita l'individuazione della partizione e Colonne aggiuntive non sono specificate.
Per informazioni su come inserire dati nel data warehouse usando il comando COPY, vedere questo articolo.
Se l'archivio dati di origine e il formato non sono originariamente supportati da un comando COPY, usare invece la copia a fasi tramite la funzionalità del comando COPY. Converte automaticamente i dati in un formato compatibile con i comandi COPY, quindi chiama un comando COPY per caricare i dati nel data warehouse.
copia di staging
Quando i dati di origine non sono compatibili in modo nativo con il comando COPY, abilitare la copia dei dati tramite un archivio di gestione temporanea provvisorio. In questo caso, il servizio converte automaticamente i dati in modo da soddisfare i requisiti di formato dei dati del comando COPY. Quindi richiama il comando COPY per caricare i dati nel data warehouse. Infine, pulisce i dati temporanei dall'archiviazione.
Per usare la copia a fasi, passare alla scheda Impostazioni e selezionare Abilita gestione temporanea. È possibile scegliere Area di lavoro per usare l'archiviazione temporanea creata automaticamente all'interno di Fabric. Per Esterno, Archiviazione BLOB di Azure e Azure Data Lake Storage Gen2 sono supportati come risorsa di archiviazione temporanea esterna. È necessario creare prima una connessione Archiviazione BLOB di Azure o Azure Data Lake Storage Gen2 e quindi selezionare la connessione dall'elenco a discesa per usare l'archiviazione temporanea.
Si noti che è necessario assicurarsi che l'intervallo IP del data warehouse sia stato consentito correttamente dall'archiviazione temporanea.
Mapping
Per la configurazione della scheda Mapping, se non si applica data warehouse con la creazione automatica della tabella come destinazione, vedere Mapping.
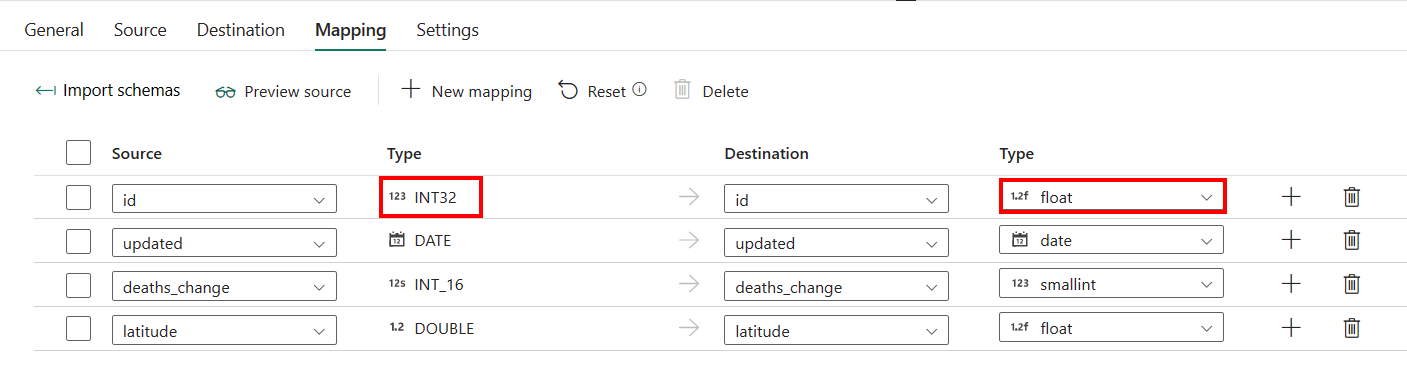
Se si applica Data Warehouse con la creazione automatica della tabella come destinazione, ad eccezione della configurazione in Mapping, è possibile modificare il tipo per le colonne di destinazione. Dopo aver selezionato Importa schemi, è possibile specificare il tipo di colonna nella destinazione.
Ad esempio, il tipo per la colonna ID nell'origine è int ed è possibile modificarlo in tipo float quando si esegue il mapping alla colonna di destinazione.
Impostazione
Per la configurazione della scheda Impostazioni, passare a Impostazioni.
Riepilogo della tabella
Le tabelle seguenti contengono altre informazioni su un'attività di copia in Data Warehouse.
Informazioni sull'origine
| Nome | Descrizione | valore | Richiesto | Proprietà script JSON |
|---|---|---|---|---|
| Tipo di archivio dati | Tipo di archivio dati. | Area di lavoro | Sì | / |
| Tipo di archivio dati dell'area di lavoro | Sezione per selezionare il tipo di archivio dati dell'area di lavoro. | Data warehouse | Sì | type |
| Data warehouse | Data warehouse che si vuole usare. | <data warehouse personale> | Sì | endpoint artifactId |
| Usa query | Modalità di lettura dei dati dal data warehouse. | • Tabelle • Query • Stored procedure |
No | (in typeProperties ->source)• typeProperties: schema table • sqlReaderQuery • sqlReaderStoredProcedureName |
| Timeout della query (minuti) | Timeout per l'esecuzione del comando di query, con un valore predefinito di 120 minuti. Se questa proprietà è impostata, i valori consentiti sono nel formato di un intervallo di tempo, ad esempio "02:00:00" (120 minuti). | timespan | No | queryTimeout |
| Livello di isolamento | Comportamento di blocco della transazione per l'origine. | • Nessuno • Snapshot |
No | isolationLevel |
| Opzione di partizione | Opzioni di partizionamento dei dati usate per caricare i dati dal data warehouse. | • Nessuno • Intervallo dinamico |
No | partitionOption |
| Nome della colonna di partizione | Nome della colonna di origine in formato intero o di tipo data/datetime (int, smallint, bigint, date, smalldatetime, datetime, datetime2 o datetimeoffset) utilizzata dal partizionamento per intervalli per la copia parallela. Se non specificato, l'indice o la chiave primaria della tabella vengono rilevati automaticamente e usati come colonna di partizione. |
<nome della colonna di partizione> | No | partitionColumnName |
| Limite superiore partizione | Valore massimo della colonna di partizione per la suddivisione dell'intervallo di partizioni. Questo valore viene usato per decidere lo stride di partizione, non per filtrare le righe nella tabella. Tutte le righe nella tabella o nel risultato della query vengono partizionate e copiate. | <limite massimo della partizione> | No | partitionUpperBound |
| Limite inferiore partizione | Valore minimo della colonna di partizione per la suddivisione dell'intervallo di partizioni. Questo valore viene usato per decidere lo stride di partizione, non per filtrare le righe nella tabella. Tutte le righe nella tabella o nel risultato della query vengono partizionate e copiate. | <limite minimo della partizione> | No | partitionLowerBound |
| Colonne aggiuntive | Aggiungere altre colonne di dati per archiviare il percorso relativo o il valore statico dei file di origine. | • Name • Valore |
No | additionalColumns: • name • value |
Informazioni sulla destinazione
| Nome | Descrizione | valore | Richiesto | Proprietà script JSON |
|---|---|---|---|---|
| Tipo di archivio dati | Tipo di archivio dati. | Area di lavoro | Sì | / |
| Tipo di archivio dati dell'area di lavoro | Sezione per selezionare il tipo di archivio dati dell'area di lavoro. | Data warehouse | Sì | type |
| Data warehouse | Data warehouse che si vuole usare. | <data warehouse personale> | Sì | endpoint artifactId |
| Tabella | La tabella di destinazione in cui scrivere i dati. | <nome della tabella di destinazione> | Sì | schema table |
| Impostazioni del comando COPY | Impostazioni delle proprietà del comando COPY. Contiene le impostazioni dei valori predefiniti. | Valore predefinito: • Colonna • Valore |
No | copyCommandSettings: defaultValues: • columnName • defaultValue |
| Opzione tabella | Specifica se creare automaticamente la tabella di destinazione, se non esistente, in base allo schema di origine. | • Nessuno • Crea tabella automaticamente |
No | tableOption: • autoCreate |
| Script di pre-copia | Una query SQL da eseguire prima di scrivere i dati nel Data Warehouse a ogni esecuzione. Usare questa proprietà per pulire i dati precaricati. | <script di pre-copia> | No | preCopyScript |
| Timeout del batch di scrittura | Tempo di attesa per il completamento dell'operazione di inserimento batch prima del timeout. I valori consentiti sono nel formato di un intervallo di tempo. Il valore predefinito è "00:30:00" (30 minuti). | timespan | No | writeBatchTimeout |
| Disattiva l'analisi delle metriche delle prestazioni | Il servizio raccoglie le metriche per l'ottimizzazione delle prestazioni di copia e le raccomandazioni, che introducono l'accesso al database master aggiuntivo. | selezionare o deselezionare | No | disableMetricsCollection: true o false |