Configurare Azure Synapse Analytics in un'attività di copia
Questo articolo descrive come utilizzare l'attività di copia nella pipeline di dati per copiare dati da e verso Azure Synapse Analytics.
Configurazione supportata
Per la configurazione di ogni scheda nell'attività di copia, consultare rispettivamente le sezioni seguenti.
Generali
Consultare la guida sulle Impostazioni generali per configurare la scheda Impostazioni generali.
Origine
Le proprietà seguenti sono supportate per Azure Synapse Analytics nella scheda Origine di un'attività di copia.

Sono richieste le seguenti proprietà:
Tipo di archivio dati: selezionare Esterno.
Connessione: selezionare una connessione di Azure Synapse Analytics dall'elenco delle connessioni. Se la connessione non esiste, creare una nuova connessione di Azure Synapse Analytics selezionando Nuovo.
Tipo di connessione: selezionare Azure Synapse Analytics.
Usa query: è possibile scegliere Tabella, Query o Stored procedure per leggere i dati di origine. L'elenco seguente descrive la configurazione di ciascuna impostazione:
Tabella: se si seleziona questo pulsante, i dati vengono letti dalla tabella specificata in Tabella. Selezionare la tabella dall'elenco a discesa o selezionare Modifica per immettere manualmente lo schema e il nome della tabella.

Query: specificare la query SQL personalizzata per leggere i dati. Un esempio è
select * from MyTable. In alternativa, selezionare l'icona a forma di matita da modificare nell'editor di codice.
Stored procedure: usare la stored procedure che legge i dati dalla tabella di origine. L'ultima istruzione SQL deve essere un'istruzione SELECT nella stored procedure.

- Nome della stored procedure: selezionare la stored procedure o specificare manualmente il nome della stored procedure quando si seleziona Modifica.
- Parametri della stored procedure: selezionare Importa parametri per importare il parametro nella stored procedure specificata oppure aggiungere parametri per la stored procedure selezionando + Nuovo. I valori consentiti sono coppie nome-valore. I nomi e le maiuscole e minuscole dei parametri devono corrispondere ai nomi e alle maiuscole e minuscole dei parametri della stored procedure.

In Avanzato è possibile specificare i seguenti campi:
Timeout query (minuti): specificare il timeout per l'esecuzione del comando di query, il valore predefinito è 120 minuti. Se per questa proprietà è impostato un parametro, i valori consentiti sono intervalli di tempo, ad esempio "02:00:00" (120 minuti).
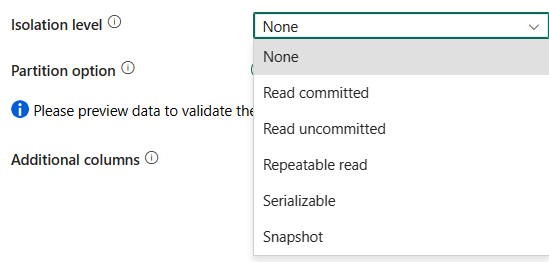
Livello di isolamento: specificare il comportamento di blocco delle transazioni per l'origine SQL. I valori consentiti sono: None, Read committed, Read uncommitted, Repeatable read, Serializable o Snapshot. Se non specificato, viene utilizzato il livello di isolamento Nessuno. Per altri dettagli, vedere enumerazione IsolationLevel.
Opzione di partizione: specificare le opzioni di partizionamento dei dati utilizzate per caricare i dati da Azure Synapse Analytics. I valori consentiti sono: Nessuna (impostazione predefinita), Partizioni fisiche della tabella e Intervallo dinamico. Quando è abilitata un'opzione di partizione (ovvero diversa da Nessuna), il grado di parallelismo per caricare contemporaneamente i dati da Azure Synapse Analytics è controllato dall'impostazione di copia parallela nell'attività di copia.
Nessuna: scegliere questa impostazione per non usare una partizione.
Partizioni fisiche della tabella: scegliere questa impostazione se si vuole usare una partizione fisica. La colonna di partizione e il meccanismo vengono determinati automaticamente in base alla definizione della tabella fisica.
Intervallo dinamico: scegliere questa impostazione se si vuole usare il partizionamento per intervalli dinamico. Quando si usa la query con la copia parallela abilitata, è necessario il parametro di partizione a intervalli(
?DfDynamicRangePartitionCondition). Query di esempio:SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition.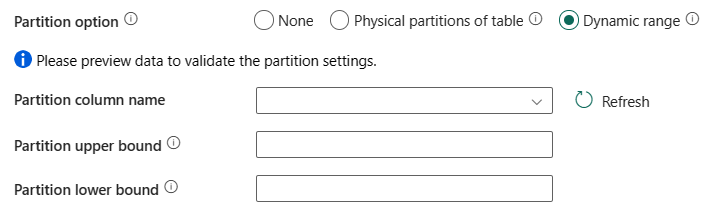
- Nome della colonna di partizione: specificare il nome della colonna di origine in formato intero o di tipo data/datetime (
int,smallint,bigint,date,smalldatetime,datetime,datetime2odatetimeoffset) utilizzata dal partizionamento per intervalli per la copia parallela. Se non è specificato, l’indice o la chiave primaria della tabella vengono rilevati automaticamente e usati come colonna di partizione. - Limite massimo della partizione: specificare il valore massimo della colonna di partizione per la suddivisione dell'intervallo di partizioni. Questo valore viene usato per decidere lo stride di partizione, non per filtrare le righe nella tabella. Tutte le righe nella tabella o nel risultato della query vengono partizionate e copiate.
- Limite minimo della partizione: specificare il valore minimo della colonna di partizione per la suddivisione dell'intervallo di partizioni. Questo valore viene usato per decidere lo stride di partizione, non per filtrare le righe nella tabella. Tutte le righe nella tabella o nel risultato della query vengono partizionate e copiate.
- Nome della colonna di partizione: specificare il nome della colonna di origine in formato intero o di tipo data/datetime (
Colonne aggiuntive: aggiungere altre colonne di dati per archiviare il percorso relativo o il valore statico dei file di origine. Per quest'ultimo è supportata l'espressione. Per altre informazioni, vedere Aggiungere altre colonne durante la copia.
Destinazione
Le proprietà seguenti sono supportate per Azure Synapse Analytics nella scheda Destinazione di un'attività di copia.
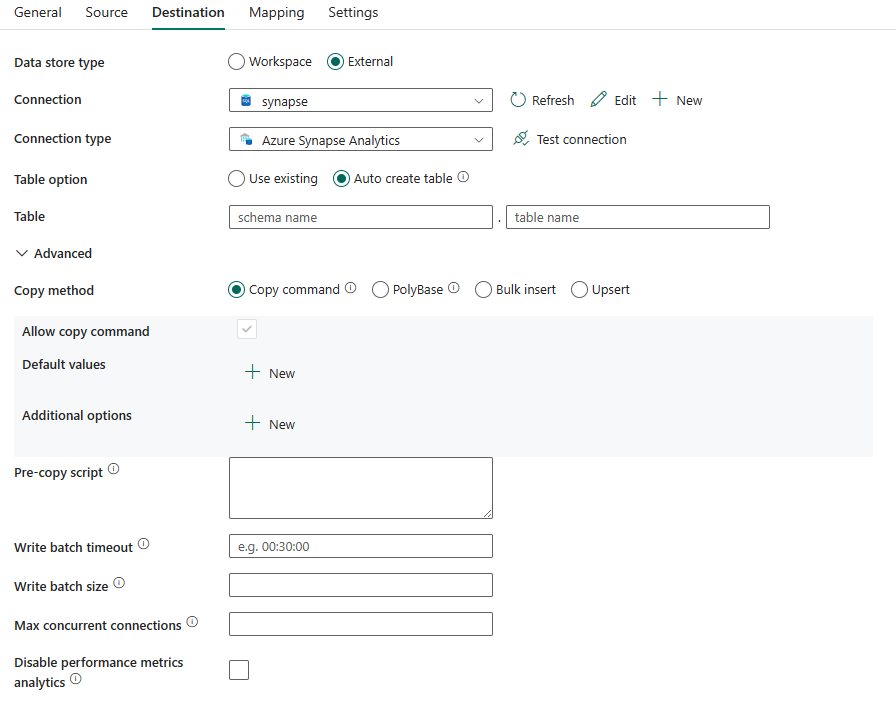
Sono richieste le seguenti proprietà:
- Tipo di archivio dati: selezionare Esterno.
- Connessione: selezionare una connessione di Azure Synapse Analytics dall'elenco delle connessioni. Se la connessione non esiste, creare una nuova connessione di Azure Synapse Analytics selezionando Nuovo.
- Tipo di connessione: selezionare Azure Synapse Analytics.
- Opzione tabella: è possibile scegliere Usa esistente o Crea tabella automaticamente. L'elenco seguente descrive la configurazione di ciascuna impostazione:
- Usa esistente: selezionare la tabella nel database dall'elenco a discesa. In alternativa, selezionare Modifica per immettere manualmente lo schema e il nome della tabella.
- Crea tabella automaticamente: crea automaticamente la tabella (se inesistente) nello schema di origine.
In Avanzato è possibile specificare i seguenti campi:
Metodo di copia: scegliere il metodo da usare per copiare i dati. È possibile scegliere Comando COPY, PolyBase, Inserimento in blocco o Upsert. L'elenco seguente descrive la configurazione di ciascuna impostazione:
Comando COPY: usare l'istruzione COPY per caricare dati da Archiviazione di Azure in Azure Synapse Analytics o nel pool SQL.
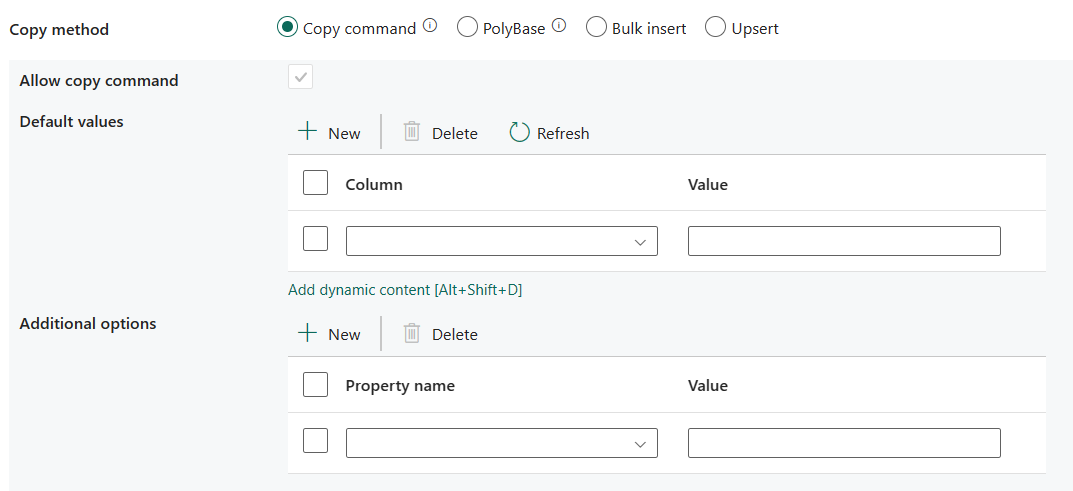
- Consenti comando COPY: è obbligatorio selezionarlo quando si sceglie Comando copia.
- Valori predefiniti: specificare i valori predefiniti per ogni colonna di destinazione in Azure Synapse Analytics. I valori predefiniti nella proprietà sovrascrivono il vincolo DEFAULT impostato nel data warehouse e la colonna Identity non può avere un valore predefinito.
- Opzioni aggiuntive: opzioni aggiuntive che verranno passate a un'istruzione COPY di Azure Synapse Analytics direttamente nella clausola "With" nell'istruzione COPY. Racchiudere il valore tra virgolette come previsto dai requisiti dell'istruzione COPY.
PolyBase: PolyBase è un meccanismo ad alta produttività. Consente di caricare grandi quantità di dati in Azure Synapse Analytics o in un pool SQL.
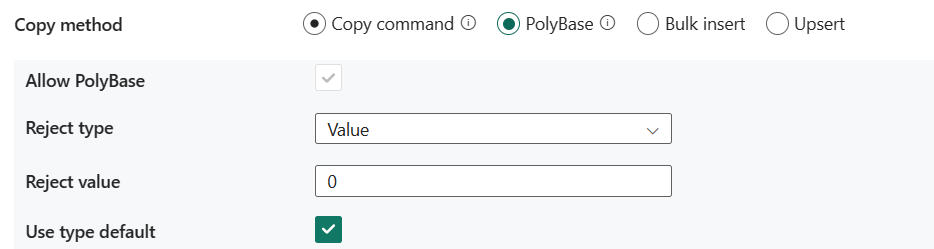
- Consenti PolyBase: è obbligatorio selezionarlo quando si sceglie PolyBase.
- Tipo di rifiuto: specificare se l'opzione rejectValue è un valore letterale o una percentuale. I valori consentiti sono Value (predefinito) e Percentage.
- Valore di rifiuto: specificare il numero o la percentuale di righe che possono essere rifiutate prima che la query abbia esito negativo. Per altre informazioni sulle opzioni di rifiuto di PolyBase, vedere la sezione Argomenti in CREATE EXTERNAL TABLE (Transact-SQL). I valori consentiti sono 0 (predefinito), 1, 2 e così via.
- Valore campione di rifiuto: determina il numero di righe da recuperare prima che PolyBase ricalcoli la percentuale di righe rifiutate. I valori consentiti sono 1, 2 e così via. Se si sceglie Percentuale come tipo di rifiuto, questa proprietà è obbligatoria.
- Usa tipo predefinito: specificare come gestire i valori mancanti nei file di testo delimitato quando PolyBase recupera i dati dal file di testo. Per altre informazioni su questa proprietà, vedere la sezione Arguments (Argomenti) in CREATE EXTERNAL FILE FORMAT (Transact-SQL). I valori consentiti sono selezionati (impostazione predefinita) o non selezionati.
Inserimento in blocco: usare Inserimento in blocco per inserire dati nella destinazione in blocco.

- Blocco tabella inserimento in blocco: usare questa opzione per migliorare le prestazioni di copia durante operazioni di inserimento in blocco su tabelle senza indici da più client. Per altre informazioni, vedere BULK INSERT (Transact-SQL).
Upsert: specificare il gruppo di impostazioni per il comportamento di scrittura quando si desidera eseguire l'upsert dei dati nella destinazione.
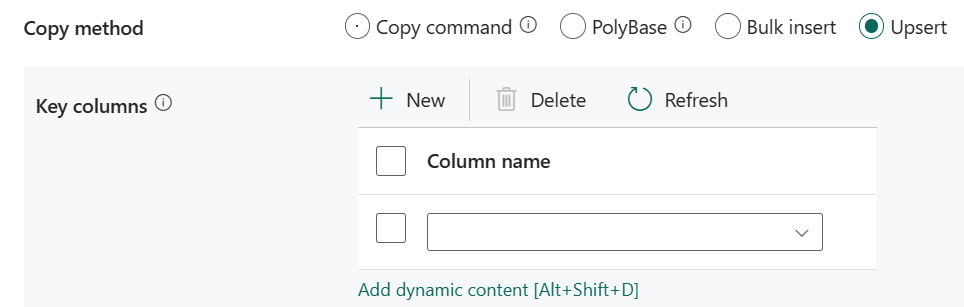
Colonne chiave: scegliere la colonna usata per determinare se una riga dell'origine corrisponde a una riga della destinazione.
Blocco tabella inserimento in blocco: usare questa opzione per migliorare le prestazioni di copia durante operazioni di inserimento in blocco su tabelle senza indici da più client. Per altre informazioni, vedere BULK INSERT (Transact-SQL).
Script di pre-copia: specificare uno script che l'attività di copia deve eseguire prima di scrivere i dati in una tabella di destinazione a ogni esecuzione. È possibile usare questa proprietà per pulire i dati precaricati.
Timeout batch di scrittura: specificare il tempo di attesa per il completamento dell'operazione di inserimento batch prima del timeout. I valori consentiti sono intervalli di tempo. Il valore predefinito è "00:30:00" (30 minuti).
Dimensione batch di scrittura: specificare il numero di righe da inserire nella tabella SQL per batch. Il valore consentito è integer (numero di righe). Per impostazione predefinita, il servizio determina in modo dinamico le dimensioni appropriate del batch in base alle dimensioni della riga.
Numero massimo di connessioni simultanee: specificare il limite massimo di connessioni simultanee stabilite all'archivio dati durante l'esecuzione dell'attività. Specificare un valore solo quando si desidera limitare le connessioni simultanee.
Disattiva l'analisi delle metriche delle prestazioni: questa impostazione viene usata per raccogliere metriche, ad esempio DTU, DWU, UR e così via, al fine di ottimizzare le prestazioni di copia e i relativi consigli. Se si è interessati a questo comportamento, selezionare questa casella di controllo. È non selezionata per impostazione predefinita.
Copia diretta con il comando COPY
Il comando COPY di Azure Synapse Analytics supporta direttamente Archiviazione BLOB di Azure e Azure Data Lake Storage Gen2 come archivi dati di origine. Se i dati di origine soddisfano i criteri descritti in questa sezione, utilizzare il comando COPY per copiarli direttamente dall'archivio dati di origine ad Azure Synapse Analytics.
I dati di origine e il formato contengono i seguenti tipi e metodi di autenticazione:
Tipo di archivio dati di origine supportato Formato supportato Tipo di autenticazione di origine supportato Archiviazione BLOB di Azure Testo delimitato
ParquetAutenticazione anonima
Autenticazione basata sulla chiave dell'account
Autenticazione con firma di accesso condivisoAzure Data Lake Storage Gen2 Testo delimitato
ParquetAutenticazione basata sulla chiave dell'account
Autenticazione con firma di accesso condivisoÈ possibile impostare le seguenti impostazioni del formato:
- Per Parquet: il tipo di compressione può essere Nessuna, Snappy o Gzip.
- Per DelimitedText:
- Delimitatore di riga: quando si copia testo delimitato in Azure Synapse Analytics tramite il comando COPY diretto, specificare il delimitatore di riga in modo esplicito (\r; \n; o \r\n). Il valore predefinito (\r, \n o \r\n) funziona solo quando il delimitatore di riga del file di origine è \r\n. In caso contrario, abilitare la gestione temporanea per lo scenario.
- Il valore null viene lasciato come predefinito o impostato su una stringa vuota ("").
- La codifica viene mantenuta come predefinita o impostata su UTF-8 o UTF-16.
- Il conteggio delle righe ignorate viene lasciato come predefinito o impostato su 0.
- Il tipo di compressione può essere Nessuno o gzip.
Se l'origine è una cartella, è necessario selezionare la casella di controllo In modo ricorsivo.
L'ora di inizio (UTC) e l'ora di fine (UTC) in Filtra in base all'ultima modifica, Prefisso, Abilita l'individuazione della partizione e Colonne aggiuntive non sono specificate.
Per informazioni su come inserire dati in Azure Synapse Analytics usando il comando COPY, vedere questo articolo.
Se l'archivio dati di origine e il formato non sono originariamente supportati da un comando COPY, usare invece la copia a fasi tramite la funzionalità del comando COPY. Converte automaticamente i dati in un formato compatibile con i comandi COPY, quindi chiama un comando COPY per caricare i dati in Azure Synapse Analytics.
Mapping
Per la configurazione della scheda Mapping, se non si applica Azure Synapse Analytics con la creazione automatica della tabella come destinazione, vedere Mapping.
Se si applica Azure Synapse Analytics con la creazione automatica della tabella come destinazione, ad eccezione della configurazione in Mapping, è possibile modificare il tipo per le colonne di destinazione. Dopo aver selezionato Importa schemi, è possibile specificare il tipo di colonna nella destinazione.
Ad esempio, il tipo per la colonna ID nell'origine è int ed è possibile modificarlo in tipo float quando si esegue il mapping sulla colonna di destinazione.
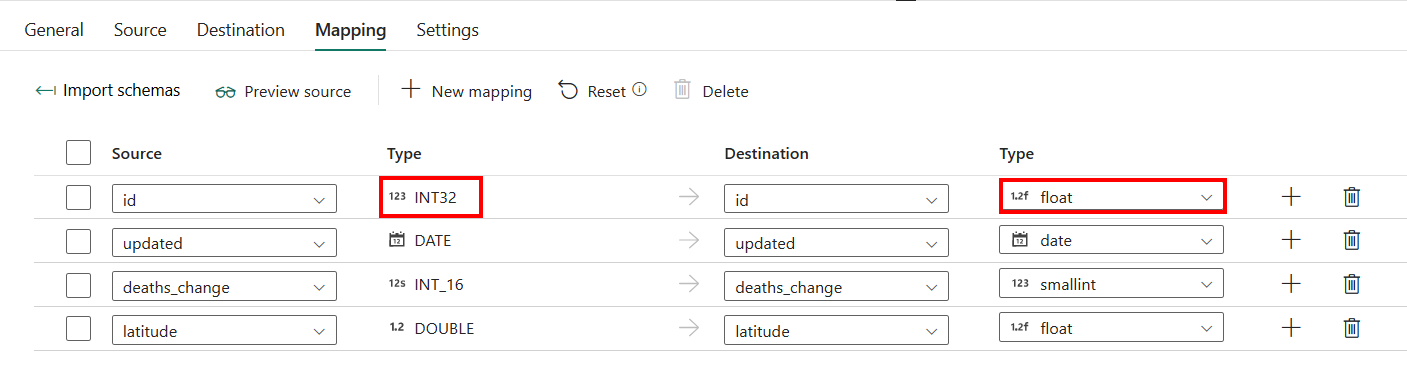
Impostazione
Per la configurazione della scheda Impostazioni, vedere Configurare le altre impostazioni nella scheda Impostazioni.
Copia parallela da Azure Synapse Analytics
Il connettore Azure Synapse Analytics nell'attività di copia fornisce il partizionamento dei dati predefinito per copiare i dati in parallelo. È possibile trovare le opzioni di partizionamento dei dati nella tabella Origine dell'attività di copia.
Quando si abilita la copia partizionata, l'attività di copia esegue query parallele sull'origine di Azure Synapse Analytics per caricare i dati in base alle partizioni. Il grado di parallelismo è controllato dal Grado di parallelismo della copia nella scheda delle impostazioni dell'attività di copia. Ad esempio, se si imposta il Grado di parallelismo della copia su quattro, il servizio genera ed esegue contemporaneamente quattro query in base all'opzione di partizione e alle impostazioni specificate e ogni query recupera una porzione di dati da Azure Synapse Analytics.
Si consiglia di abilitare la copia parallela con il partizionamento dei dati, specialmente quando si caricano grandi quantità di dati da Azure Synapse Analytics. Di seguito sono riportate le configurazioni consigliate per i diversi scenari: Quando si copiano dati in un archivio dati basato su file, è consigliabile scrivere in una cartella come file multipli (specificare solo il nome della cartella); in tal caso, le prestazioni risultano migliori rispetto alla scrittura in un singolo file.
| Scenario | Impostazioni consigliate |
|---|---|
| Caricamento completo da una tabella di grandi dimensioni, con partizioni fisiche. | Opzione di partizione: partizioni fisiche della tabella. Durante l'esecuzione, il servizio rileva automaticamente le partizioni fisiche e copia i dati in base alle partizioni. Per controllare se la tabella contenga o meno una partizione fisica, è possibile fare riferimento a questa query. |
| Caricamento completo da una tabella di grandi dimensioni, senza partizioni fisiche, con una colonna integer o datetime per il partizionamento dei dati. | Opzioni di partizione: partizione a intervalli dinamici. Colonna partizione (facoltativo): specificare la colonna usata per il partizionamento dei dati. Se non specificato, viene utilizzata la colonna di indice o chiave primaria. Limite superiore partizione e limite inferiore partizione (facoltativo): specificare se si desidera determinare lo stride della partizione. Non si tratta di filtrare le righe nella tabella; tutte le righe della tabella verranno partizionate e copiate. Se non è specificato, l'attività di copia rileva automaticamente i valori. Ad esempio, se “ID” della colonna partizione include valori compresi tra 1 e 100 e si imposta come limite inferiore 20 e come limite superiore 80, con copia parallela 4, il servizio recupera i dati in base a 4 partizioni - ID nell'intervallo < = 20, [21, 50], [51, 80] e > = 81 rispettivamente. |
| Caricamento di notevoli quantità di dati utilizzando una query personalizzata, senza partizioni fisiche, con una colonna integer o date/datetime per il partizionamento dei dati. | Opzioni di partizione: partizione a intervalli dinamici. Query: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>.Colonna di partizione: specificare la colonna usata per il partizionamento dei dati. Limite superiore partizione e limite inferiore partizione (facoltativo): specificare se si desidera determinare lo stride della partizione. Ciò non è utile a filtrare le righe nella tabella; tutte le righe del risultato della query verranno partizionate e copiate. Se non specificato, l'attività Copy rileva automaticamente il valore. Ad esempio, se la colonna di partizione "ID" include valori compresi tra 1 e 100 e si imposta il limite inferiore su 20 e il limite superiore su 80, con copia parallela come 4 il servizio recupera i dati per 4 partizioni - ID nell'intervallo <=20, [21, 50], [51, 80], e >=81, rispettivamente. Di seguito sono riportate altre query di esempio per diversi scenari: • Eseguire una query sull'intera tabella: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition• Eseguire una query da una tabella con selezione colonne e filtri aggiuntivi per la clausola where: SELECT <column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>• Query con sottoquery: SELECT <column_list> FROM (<your_sub_query>) AS T WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>• Query con partizione nella sottoquery: SELECT <column_list> FROM (SELECT <your_sub_query_column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition) AS T |
Procedure consigliate per il caricamento di dati con opzione partizione:
- Scegliere una colonna distintiva come colonna partizione (ad esempio, chiave primaria o chiave univoca) per evitare l'asimmetria dei dati.
- Se la tabella include una partizione predefinita, usare l'opzione di partizione Partizioni fisiche della tabella per ottenere prestazioni migliori.
- Azure Synapse Analytics può eseguire un massimo di 32 query alla volta; un'impostazione di un Grado di parallelismo della copia troppo elevato potrebbe causare un problema di limitazione di Synapse.
Query di esempio per controllare la partizione fisica
SELECT DISTINCT s.name AS SchemaName, t.name AS TableName, c.name AS ColumnName, CASE WHEN c.name IS NULL THEN 'no' ELSE 'yes' END AS HasPartition
FROM sys.tables AS t
LEFT JOIN sys.objects AS o ON t.object_id = o.object_id
LEFT JOIN sys.schemas AS s ON o.schema_id = s.schema_id
LEFT JOIN sys.indexes AS i ON t.object_id = i.object_id
LEFT JOIN sys.index_columns AS ic ON ic.partition_ordinal > 0 AND ic.index_id = i.index_id AND ic.object_id = t.object_id
LEFT JOIN sys.columns AS c ON c.object_id = ic.object_id AND c.column_id = ic.column_id
LEFT JOIN sys.types AS y ON c.system_type_id = y.system_type_id
WHERE s.name='[your schema]' AND t.name = '[your table name]'
Se la tabella ha una partizione fisica, viene visualizzato "HasPartition" come "sì".
Riepilogo della tabella
Le tabelle seguenti contengono altre informazioni sull'attività di copia in Azure Synapse Analytics.
Origine
| Nome | Descrizione | valore | Richiesto | Proprietà dello script JSON |
|---|---|---|---|---|
| Tipo di archivio dati | Tipo di archivio dati. | Esterno | Sì | / |
| Connessione | Connessione all'archivio dati di origine. | < connessione personale > | Sì | connection |
| Tipo di connessione | Tipo di connessione di origine. | Azure Synapse Analytics | Sì | / |
| Usa query | Modalità di lettura dei dati. | • Tabella • Query • Stored procedure |
Sì | • typeProperties (in typeProperties ->source)- schema - tabella • sqlReaderQuery • sqlReaderStoredProcedureName storedProcedureParameters - nome - valore |
| Timeout della query | Il timeout per l'esecuzione del comando di query, il valore predefinito è 120 minuti. | timespan | No | queryTimeout |
| Livello di isolamento | Comportamento di blocco della transazione per l'origine SQL. | • Nessuno • Read committed • Read uncommitted • Repeatable read • Serializable • Snapshot |
No | isolationLevel: • ReadCommitted • ReadUncommitted • RepeatableRead • Serializable • Snapshot |
| Opzione di partizione | Opzioni di partizionamento dei dati usate per caricare dati dal database SQL di Azure. | • Nessuno • Partizioni fisiche della tabella • Intervallo dinamico - Nome della colonna di partizione - Limite massimo della partizione - Limite minimo della partizione |
No | partitionOption: • PhysicalPartitionsOfTable • DynamicRange partitionSettings: - partitionColumnName - partitionUpperBound - partitionLowerBound |
| Colonne aggiuntive | Aggiungere altre colonne di dati per archiviare il percorso relativo o il valore statico dei file di origine. Per quest'ultimo è supportata l'espressione. | • Name • Valore |
No | additionalColumns: • nome • valore |
Destinazione
| Nome | Descrizione | valore | Richiesto | Proprietà dello script JSON |
|---|---|---|---|---|
| Tipo di archivio dati | Tipo di archivio dati. | Esterno | Sì | / |
| Connessione | Connessione all'archivio dati di destinazione. | < connessione personale > | Sì | connection |
| Tipo di connessione | Tipo di connessione di destinazione. | Azure Synapse Analytics | Sì | / |
| Opzione tabella | Opzione della tabella dati di destinazione. | • Usa esistente • Crea tabella automaticamente |
Sì | • typeProperties (in typeProperties ->sink)- schema - tabella • tableOption: - autoCreate typeProperties (in typeProperties ->sink)- schema - tabella |
| Metodo di copia | Metodo utilizzato per copiare i dati. | • Comando copy • PolyBase • Inserimento in blocco • Upsert |
No | / |
| Quando si seleziona il Comando COPY | Usare l'istruzione COPY per caricare i dati dall'archiviazione di Azure in Azure Synapse Analytics o in un pool SQL. | / | No. Applicare quando si usa COPY. |
allowCopyCommand: true copyCommandSettings |
| Valori predefiniti | Specificare i valori predefiniti per ogni colonna di destinazione in Azure Synapse Analytics. I valori predefiniti nella proprietà sovrascrivono il vincolo DEFAULT impostato nel data warehouse e la colonna Identity non può avere un valore predefinito. | < valori predefiniti > | No | defaultValues: - columnName - defaultValue |
| Opzioni aggiuntive | Opzioni aggiuntive che verranno passate a un'istruzione COPY di Azure Synapse Analytics direttamente nella clausola "With" in istruzione COPY. Racchiudere il valore tra virgolette come previsto dai requisiti dell'istruzione COPY. | < opzioni aggiuntive > | No | additionalOptions: - <nome proprietà>: <valore> |
| Quando si seleziona PolyBase | PolyBase è un meccanismo ad alta produttività. Consente di caricare grandi quantità di dati in Azure Synapse Analytics o in un pool SQL. | / | No. Applicare quando si usa PolyBase. |
allowPolyBase: true polyBaseSettings |
| Tipo di rifiuto | Il tipo di valore di rifiuto. | • Valore • Percentuale |
No | rejectType: - valore - percentuale |
| Valore di rifiuto | Il numero o la percentuale di righe che è possibile rifiutare prima che la query abbia esito negativo. | 0 (impostazione predefinita), 1, 2 e così via. | No | rejectValue |
| Valore campione di rifiuto | Determina il numero di righe da recuperare prima che PolyBase ricalcoli la percentuale di righe rifiutate. | 1, 2 e così via | Sì quando si specifica Percentuale come tipo di rifiuto | rejectSampleValue |
| Usa tipo predefinito | Specificare come gestire i valori mancanti nei file di testo delimitato quando PolyBase recupera i dati dal file di testo. Per altre informazioni su questa proprietà, vedere la sezione Argomenti in CREATE EXTERNAL FILE FORMAT (Transact-SQL) | selezionato (impostazione predefinita) o non selezionato. | No | useTypeDefault: true (valore predefinito) o false |
| Quando si seleziona Inserimento in blocco | Inserire i dati nella destinazione in blocco. | / | No | writeBehavior: Insert |
| Blocco tabella inserimento in blocco | Usare questa opzione per migliorare le prestazioni di copia durante operazioni di inserimento in blocco su tabelle senza indici da più client. Per altre informazioni, vedere BULK INSERT (Transact-SQL). | selezionato o non selezionato (impostazione predefinita) | No | sqlWriterUseTableLock: true o false (valore predefinito) |
| Quando si seleziona Upsert | Specificare il gruppo di impostazioni per il comportamento di scrittura quando si desidera eseguire l'upsert dei dati nella destinazione. | / | No | writeBehavior: Upsert |
| Colonne chiave | Indica la colonna utilizzata per determinare se una riga dell'origine corrisponde a una riga della destinazione. | < nome colonna> | No | upsertSettings: - chiavi: < nome colonna > - interimSchemaName |
| Blocco tabella inserimento in blocco | Usare questa opzione per migliorare le prestazioni di copia durante operazioni di inserimento in blocco su tabelle senza indici da più client. Per altre informazioni, vedere BULK INSERT (Transact-SQL). | selezionato o non selezionato (impostazione predefinita) | No | sqlWriterUseTableLock: true o false (valore predefinito) |
| Script di pre-copia | Uno script che l'attività di copia deve eseguire prima di scrivere i dati in una tabella di destinazione a ogni esecuzione. È possibile usare questa proprietà per pulire i dati precaricati. | < script di pre-copia > (string) |
No | preCopyScript |
| Timeout del batch di scrittura | Tempo di attesa per il completamento dell'operazione di inserimento batch prima del timeout. Il valore consentito è timespan. Il valore predefinito è "00:30:00" (30 minuti). | timespan | No | writeBatchTimeout |
| Dimensione del batch di scrittura | Numero di righe da inserire nella tabella SQL per batch. Per impostazione predefinita, il servizio determina in modo dinamico le dimensioni appropriate del batch in base alle dimensioni della riga. | < numero di righe > (intero) |
No | writeBatchSize |
| Numero massimo di connessioni simultanee | Limite massimo di connessioni simultanee stabilite all'archivio dati durante l'esecuzione dell'attività. Specificare un valore solo quando si desidera limitare le connessioni simultanee. | < limite massimo di connessioni simultanee > (intero) |
No | maxConcurrentConnections |
| Disattiva l'analisi delle metriche delle prestazioni | Questa impostazione viene usata per raccogliere metriche, ad esempio DTU, DWU, UR e così via, per ottimizzare le prestazioni di copia e i relativi consigli. Se si è interessati a questo comportamento, selezionare questa casella di controllo. | selezionare o deselezionare (impostazione predefinita) | No | disableMetricsCollection: true o false (valore predefinito) |