Trasformare i dati eseguendo un'attività Azure Databricks
L'attività di Azure Databricks in Data Factory per Microsoft Fabric consente di orchestrare i processi di Azure Databricks seguenti:
- Notebook
- Jar
- Python
Questo articolo fornisce una procedura dettagliata che descrive come creare un'attività di Azure Databricks usando l'interfaccia Data Factory.
Prerequisiti
Per iniziare, è necessario soddisfare i prerequisiti seguenti:
- Un account tenant con una sottoscrizione attiva. Creare un account gratuito.
- Viene creata un'area di lavoro.
Configurazione di un'attività di Azure Databricks
Per usare un'attività di Azure Databricks in una pipeline, completare la procedura seguente:
Configurazione delle connessioni
Creare una nuova pipeline nell'area di lavoro.
Fare clic su Aggiungi un'attività della pipeline e cercare Azure Databricks.
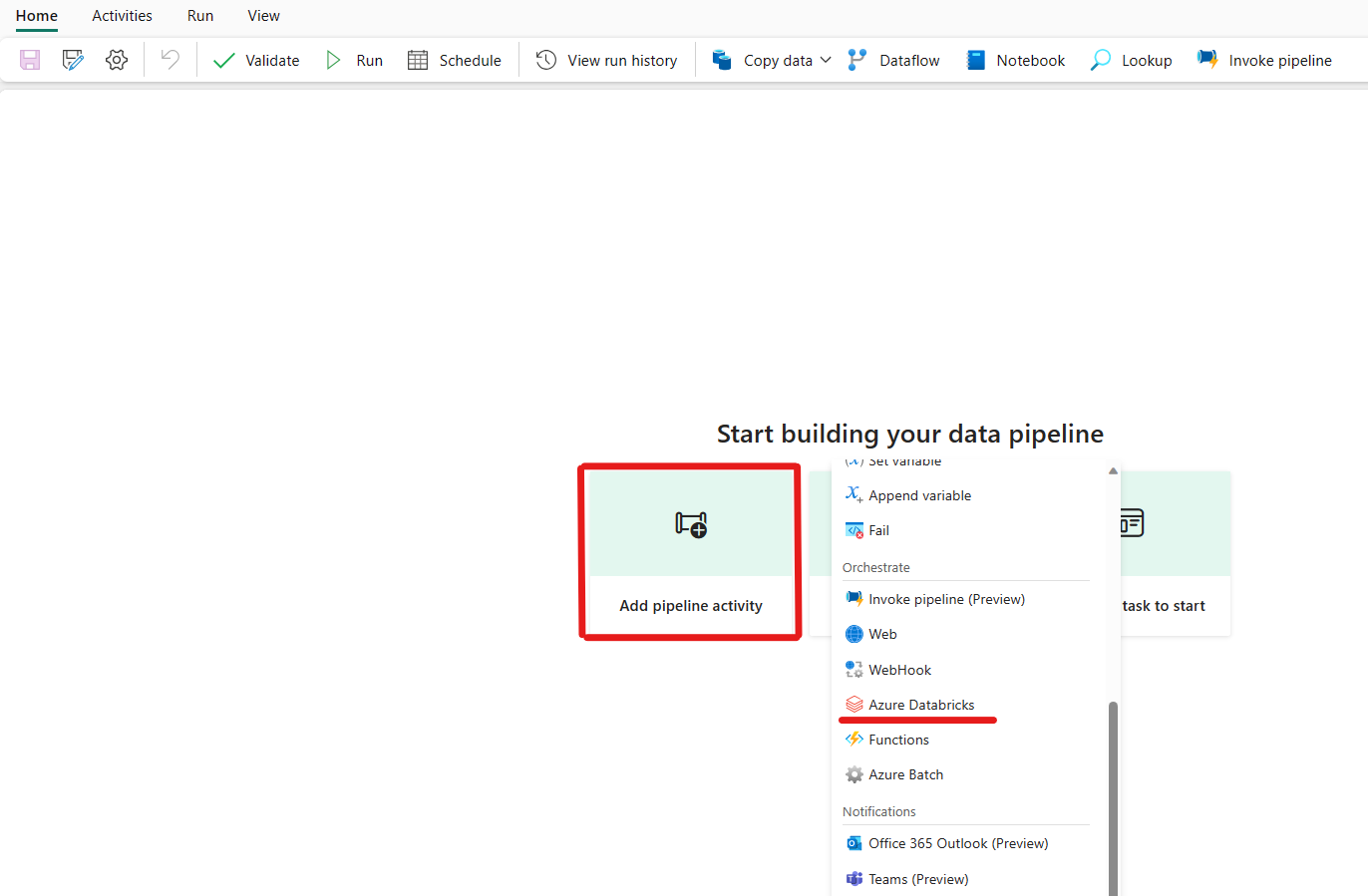
In alternativa, è possibile cercare Azure Databricks nel riquadro Attività della pipeline e selezionarlo per aggiungerlo all'area di lavoro della pipeline.
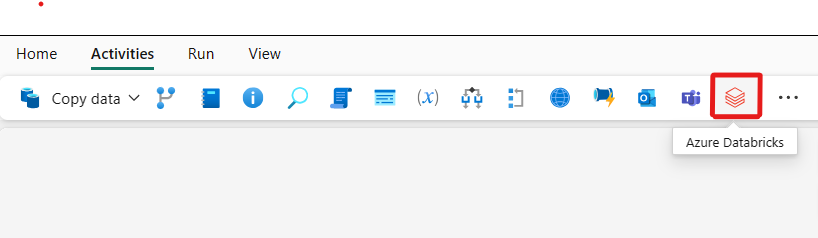
Selezionare la nuova attività di Azure Databricks nell'area di lavoro, se non è già selezionata.
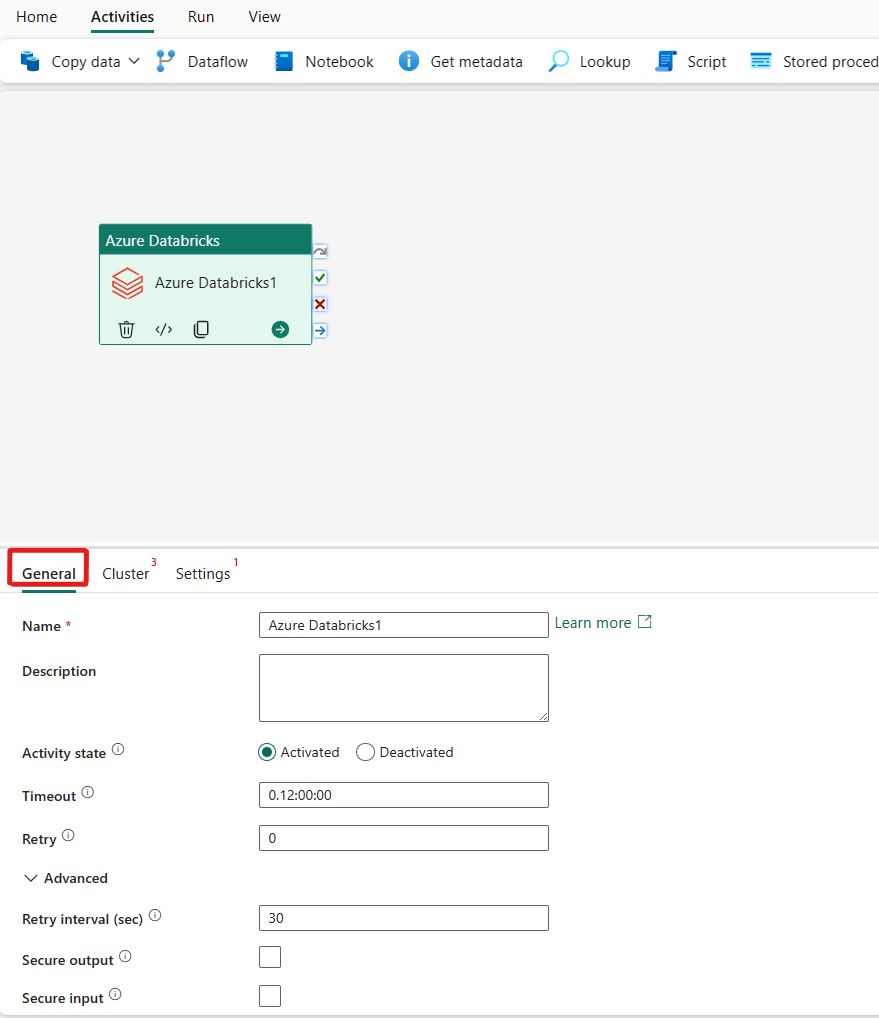
Consultare la guida sulle Impostazioni generali per configurare la scheda Impostazioni generali.
Configurazione dei cluster
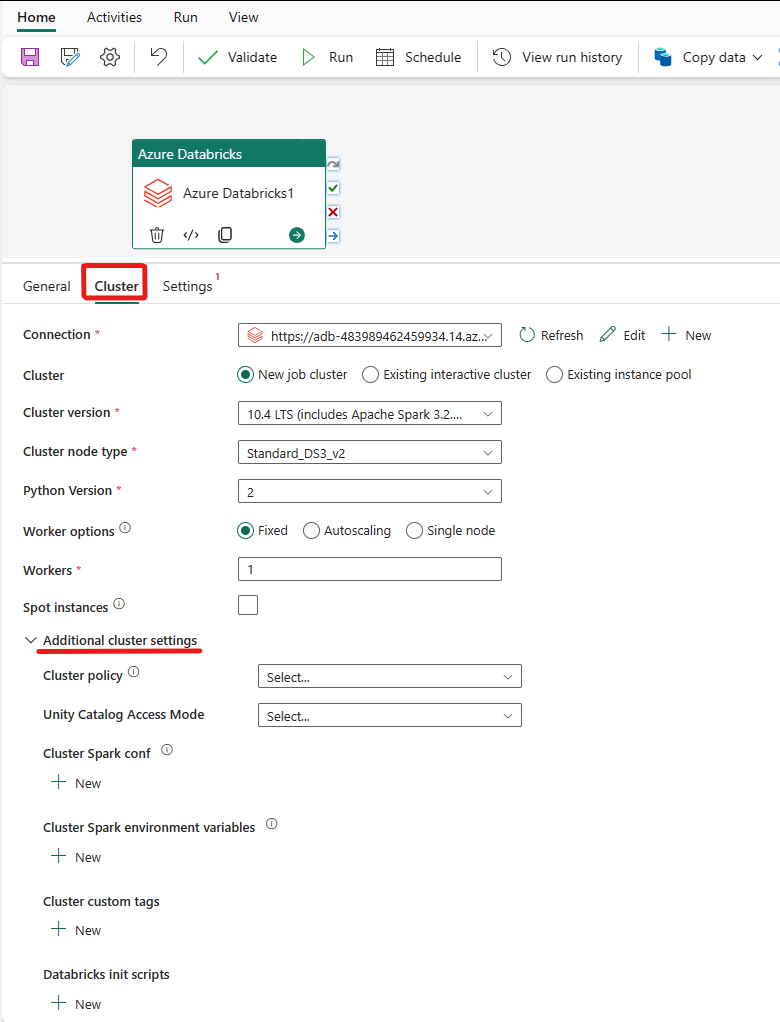
Selezionare la scheda Cluster. Quindi scegliere una connessione esistente o creare una nuova connessione di Azure Databricks e poi selezionare un nuovo cluster di processi, un cluster interattivo esistente o un pool di istanze esistente.
A seconda di ciò che si sceglie per il cluster, compilare i campi corrispondenti come mostrato.
- Nel nuovo cluster di processi e nel pool di istanze esistente è anche possibile configurare il numero di ruoli di lavoro e abilitare istanze spot.
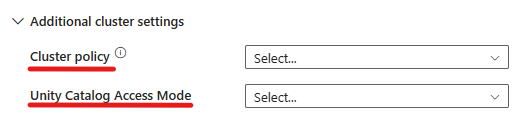
È anche possibile specificare impostazioni del cluster aggiuntive, ad esempio Criteri del cluster, configurazione Spark, variabili di ambiente Spark e tag personalizzati, in base alle esigenze del cluster a cui ci si connette. È inoltre possibile aggiungere gli script init di Databricks e il percorso di destinazione del registro cluster nelle impostazioni aggiuntive del cluster.
Nota
Tutte le proprietà avanzate del cluster e le espressioni dinamiche supportate nel servizio collegato Azure Databricks di Azure Data Factory sono ora supportate anche nell'attività Azure Databricks in Microsoft Fabric nella sezione "Configurazione cluster aggiuntiva" nell'interfaccia utente. Poiché queste proprietà sono ora incluse nell'interfaccia utente dell'attività, possono essere facilmente utilizzate con un'espressione (contenuto dinamico) senza la necessità della specifica JSON avanzata nel servizio collegato Azure Databricks di Azure Data Factory.
L'attività di Azure Databricks garantisce ora anche i criteri dei cluster e il supporto di Unity Catalog.
- In Impostazioni avanzate è possibile scegliere i criteri del cluster in modo da specificare le configurazioni del cluster consentite.
- Inoltre, in Impostazioni avanzate è possibile configurare la modalità di accesso a Unity Catalog per una maggiore sicurezza. I tipi di modalità di accesso disponibili sono:
- Modalità accesso utente singolo Questa modalità è progettata per scenari in cui ogni cluster viene usato da un singolo utente. Garantisce che l'accesso ai dati all'interno del cluster sia limitato solo all'utente. Questa modalità è utile per le attività che richiedono isolamento e gestione individuale dei dati.
- Modalità di accesso condiviso In questa modalità, più utenti possono accedere allo stesso cluster. Combina la governance dei dati di Unity Catalog con gli elenchi di controllo degli accessi (ACL) delle tabelle legacy. Questa modalità consente l'accesso collaborativo ai dati mantenendo al contempo protocolli di governance e sicurezza. Tuttavia, presenta alcune limitazioni, come il mancato supporto per Databricks Runtime ML, per i processi di invio di Spark e per specifiche API e funzioni definite dall'utente di Spark.
- Nessuna modalità di accesso Questa modalità disabilita l'interazione con Unity Catalog, il che significa che i cluster non hanno accesso ai dati gestiti da Unity Catalog. Questa modalità è utile per i carichi di lavoro che non richiedono le funzionalità di governance di Unity Catalog.
Configurazione delle impostazioni
Selezionando la scheda Impostazioni, è possibile scegliere tra 3 opzioni di tipo Azure Databricks da orchestrare.
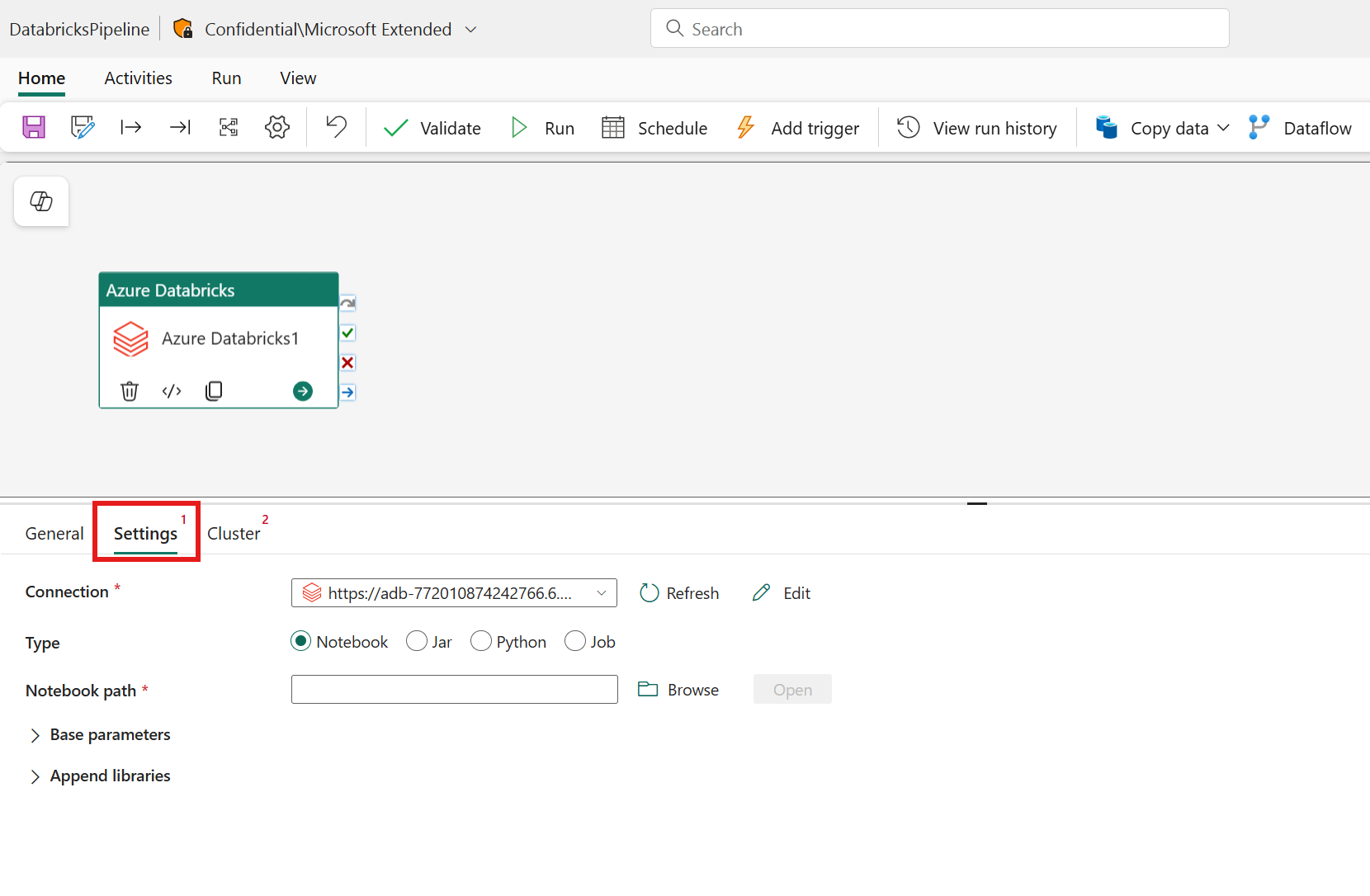
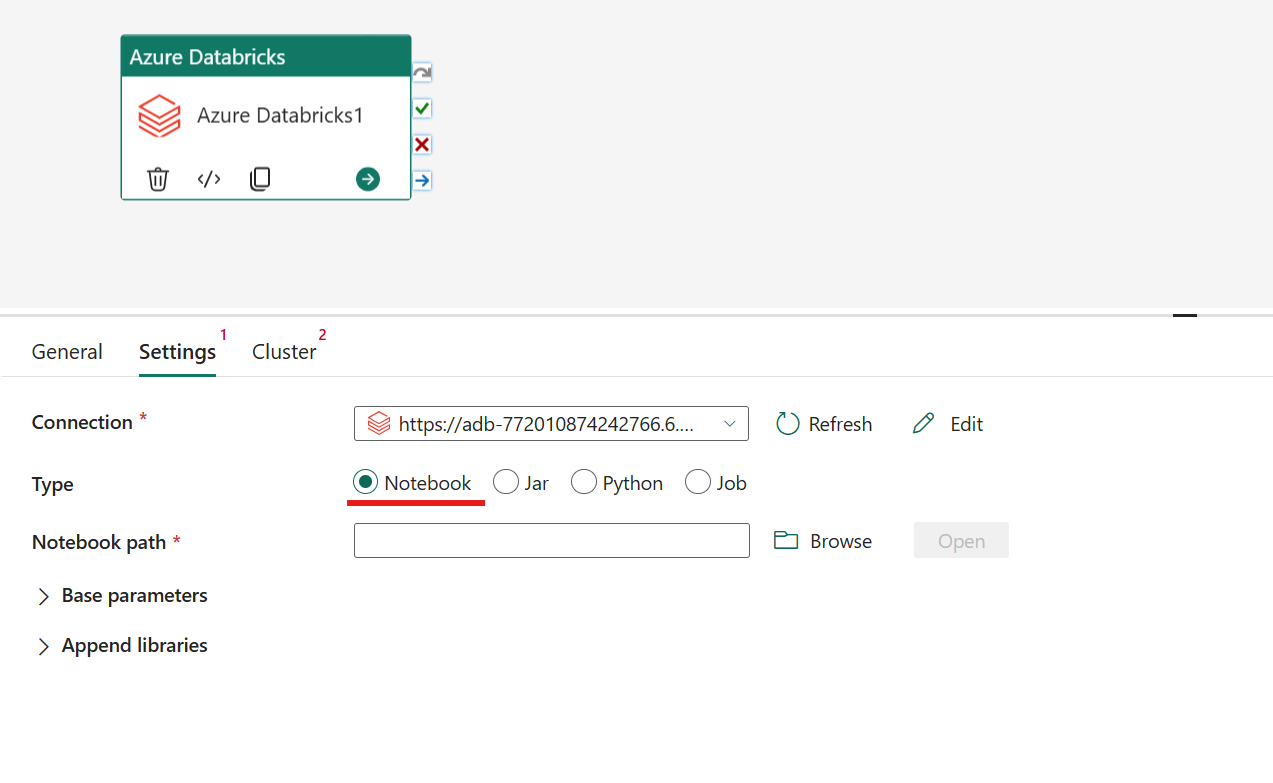
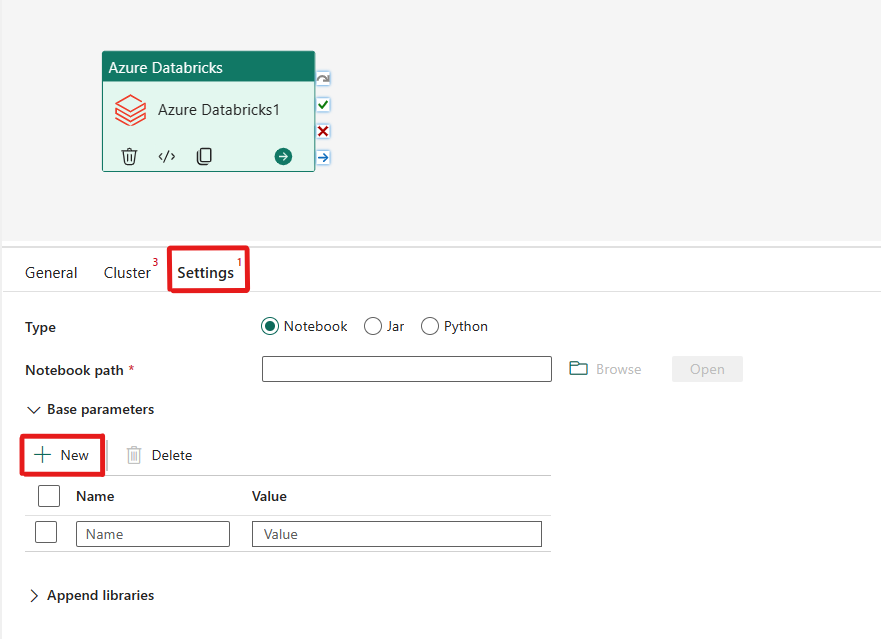
Orchestrazione del tipo Notebook nell'attività di Azure Databricks:
Nella scheda Impostazioni è possibile scegliere il pulsante di opzione Notebook per eseguire un notebook. Sarà necessario specificare il percorso del notebook da eseguire in Azure Databricks, i parametri di base facoltativi da passare al notebook e le eventuali librerie aggiuntive da installare nel cluster per eseguire il processo.
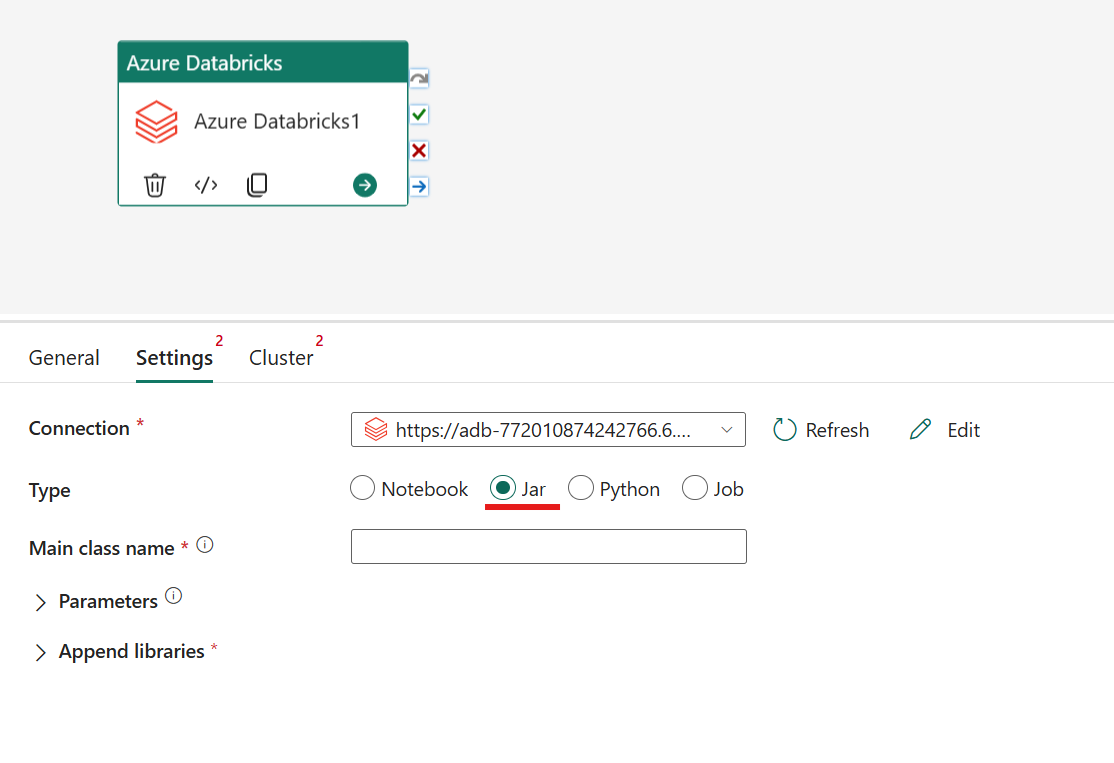
Orchestrazione del tipo Jar nell'attività di Azure Databricks:
Nella scheda Impostazioni è possibile scegliere il pulsante di opzione Jar per eseguire un file Jar. Sarà necessario specificare il nome della classe da eseguire in Azure Databricks, i parametri di base facoltativi da passare al file Jar e le eventuali librerie aggiuntive da installare nel cluster per eseguire il processo.
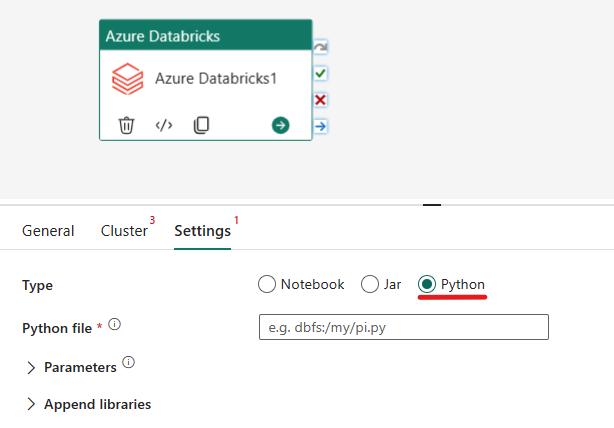
Orchestrazione del tipo Python nell'attività di Azure Databricks:
Nella scheda Impostazioni è possibile scegliere il pulsante di opzione Python per eseguire un file Python. Sarà necessario specificare il percorso all'interno di Azure Databricks verso un file Python da eseguire, i parametri di base facoltativi da passare e le eventuali librerie aggiuntive da installare nel cluster per eseguire il processo.
Librerie supportate per le attività di Azure Databricks
Nella definizione dell'attività di Databricks sopra riportata, è possibile specificare i seguenti tipi di libreria: jar, egg, whl, maven, pypi e cran.
Per altre informazioni, consultare la documentazione di Databricks sui tipi di libreria.
Passaggio di parametri tra attività e pipeline di Azure Databricks
È possibile passare parametri ai notebook usando la proprietà baseParameters nell'attività Databricks.
In alcuni casi, potrebbe essere necessario trasferire alcuni valori dal notebook al servizio, che possono essere utilizzati per il flusso di controllo (controlli condizionali) nel servizio o essere utilizzati da attività a valle (il limite di dimensione è di 2 MB).
Nel notebook, ad esempio, è possibile chiamare dbutils.notebook.exit("returnValue") e il corrispondente "returnValue" verrà restituito al servizio.
È possibile utilizzare l'output nel servizio tramite espressioni come
@{activity('databricks activity name').output.runOutput}.
Salvare ed eseguire o pianificare la pipeline
Dopo aver configurato tutte le altre attività necessarie per la pipeline, passare alla scheda Home nella parte superiore dell’editor della pipeline e selezionare il pulsante Salva per salvare la pipeline. Selezionare Esegui per eseguirla direttamente o Pianificare per pianificarla. Qui è anche possibile visualizzare la cronologia delle esecuzioni o configurare altre impostazioni.
