Trasformare i dati con dbt
Nota
Il processo Apache Airflow è alimentato da Apache Airflow.
dbt(Data Build Tool) è un'interfaccia della riga di comando open source che semplifica la trasformazione e la modellazione dei dati all'interno dei data warehouse gestendo codice SQL complesso in modo strutturato e gestibile. Consente ai team di dati di creare trasformazioni affidabili e testabili al centro delle pipeline analitiche.
In combinazione con Apache Airflow, le funzionalità di trasformazione di dbt vengono migliorate dalle funzionalità di pianificazione, orchestrazione e gestione delle attività di Airflow. Questo approccio combinato, usando l'esperienza di trasformazione di dbt insieme alla gestione del flusso di lavoro di Airflow, offre pipeline di dati efficienti e affidabili, portando infine a decisioni più rapide e dettagliate basate sui dati.
Questa esercitazione illustra come creare un daG Apache Airflow che usa dbt per trasformare i dati archiviati in Microsoft Fabric Data Warehouse.
Prerequisiti
Per iniziare, è necessario soddisfare i prerequisiti seguenti:
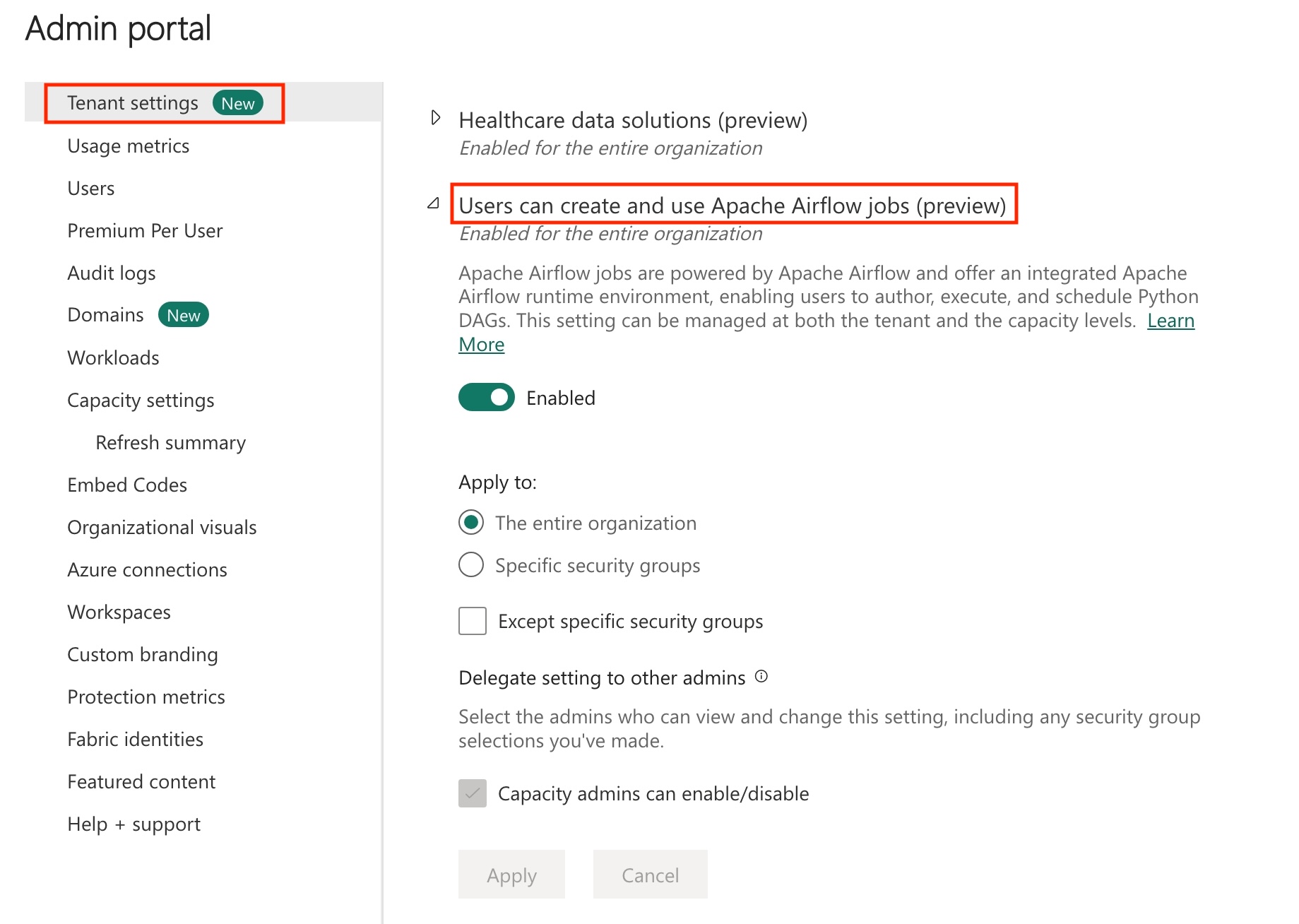
Abilitare il processo Apache Airflow nel tenant.
Nota
Poiché il processo Apache Airflow è in stato di anteprima, è necessario abilitarlo tramite l'amministratore del tenant. Se il processo Apache Airflow è già visualizzato, l'amministratore del tenant potrebbe averla già abilitata.
Passare al portale di amministrazione -> Impostazioni tenant -> In Microsoft Fabric> - Espandere la sezione "Gli utenti possono creare e usare il processo Apache Airflow (anteprima)".
Selezionare Applica.
Creare l'entità servizio. Aggiungere l'entità servizio come
Contributornell'area di lavoro in cui si crea il data warehouse.Se non ne è disponibile uno, creare un warehouse Fabric. Inserire i dati di esempio nel warehouse usando la pipeline di dati. Per questa esercitazione si userà l'esempio NYC Taxi-Green.

Trasformare i dati archiviati in Fabric Warehouse usando dbt
La sezione guida l'utente nell'esecuzione dei passaggi seguenti:
- Specificare i requisiti.
- Creare un progetto dbt nell'archiviazione gestita di Fabric fornita dal processo Apache Airflow.
- Creare un DAG Apache Airflow per orchestrare i processi dbt
Specificare i requisiti
Creare un file requirements.txt nella cartella dags. Aggiungere i pacchetti seguenti come requisiti di Apache Airflow.
astronomer-cosmos: questo pacchetto viene usato per eseguire i progetti di base dbt come DAG Apache Airflow e gruppi di attività.
dbt-fabric: questo pacchetto viene usato per creare un progetto dbt, che può quindi essere distribuito in un data warehouse di Fabric
astronomer-cosmos==1.0.3 dbt-fabric==1.5.0
Creare un progetto dbt nell'archiviazione gestita di Fabric fornita dal processo Apache Airflow.
In questa sezione viene creato un progetto dbt di esempio nel processo Apache Airflow per il set di dati
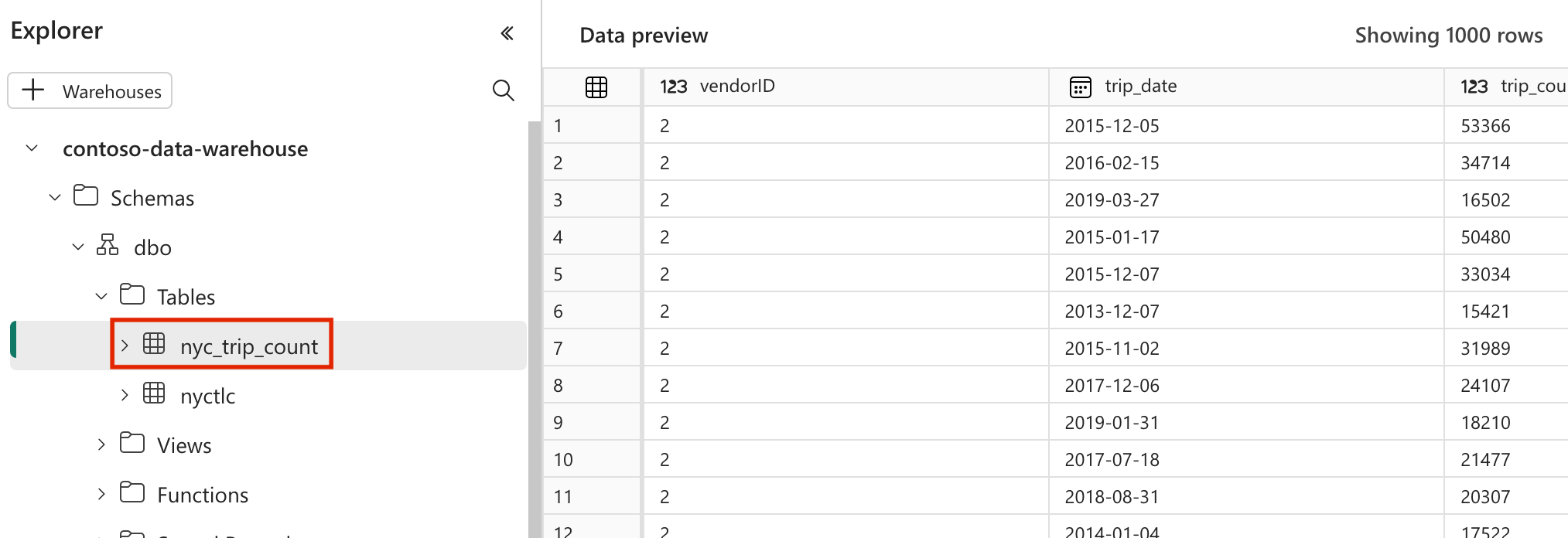
nyc_taxi_greencon la struttura di directory seguente.dags |-- my_cosmos_dag.py |-- nyc_taxi_green | |-- profiles.yml | |-- dbt_project.yml | |-- models | | |-- nyc_trip_count.sql | |-- targetCreare la cartella denominata
nyc_taxi_greennella cartelladagscon il fileprofiles.yml. Questa cartella contiene tutti i file necessari per il progetto dbt.
Copiare i contenuti seguenti in
profiles.yml. Questo file di configurazione contiene i dettagli e i profili di connessione del database usati da dbt. Aggiornare i valori segnaposto e salvare il file.config: partial_parse: true nyc_taxi_green: target: fabric-dev outputs: fabric-dev: type: fabric driver: "ODBC Driver 18 for SQL Server" server: <sql connection string of your data warehouse> port: 1433 database: "<name of the database>" schema: dbo threads: 4 authentication: ServicePrincipal tenant_id: <Tenant ID of your service principal> client_id: <Client ID of your service principal> client_secret: <Client Secret of your service principal>Creare il file
dbt_project.ymle copiare il contenuto seguente nel file. Questo file specifica la configurazione a livello di progetto.name: "nyc_taxi_green" config-version: 2 version: "0.1" profile: "nyc_taxi_green" model-paths: ["models"] seed-paths: ["seeds"] test-paths: ["tests"] analysis-paths: ["analysis"] macro-paths: ["macros"] target-path: "target" clean-targets: - "target" - "dbt_modules" - "logs" require-dbt-version: [">=1.0.0", "<2.0.0"] models: nyc_taxi_green: materialized: tableCreare la cartella
modelsnella cartellanyc_taxi_green. Per questa esercitazione viene creato il modello di esempio nel file denominatonyc_trip_count.sqlche crea la tabella che mostra il numero di corse al giorno per fornitore. Copiare il contenuto seguente nel file.with new_york_taxis as ( select * from nyctlc ), final as ( SELECT vendorID, CAST(lpepPickupDatetime AS DATE) AS trip_date, COUNT(*) AS trip_count FROM [contoso-data-warehouse].[dbo].[nyctlc] GROUP BY vendorID, CAST(lpepPickupDatetime AS DATE) ORDER BY vendorID, trip_date; ) select * from final


Creare un DAG Apache Airflow per orchestrare i processi dbt
Creare il file denominato
my_cosmos_dag.pynelladagscartella e incollarvi il contenuto seguente.import os from pathlib import Path from datetime import datetime from cosmos import DbtDag, ProjectConfig, ProfileConfig, ExecutionConfig DEFAULT_DBT_ROOT_PATH = Path(__file__).parent.parent / "dags" / "nyc_taxi_green" DBT_ROOT_PATH = Path(os.getenv("DBT_ROOT_PATH", DEFAULT_DBT_ROOT_PATH)) profile_config = ProfileConfig( profile_name="nyc_taxi_green", target_name="fabric-dev", profiles_yml_filepath=DBT_ROOT_PATH / "profiles.yml", ) dbt_fabric_dag = DbtDag( project_config=ProjectConfig(DBT_ROOT_PATH,), operator_args={"install_deps": True}, profile_config=profile_config, schedule_interval="@daily", start_date=datetime(2023, 9, 10), catchup=False, dag_id="dbt_fabric_dag", )
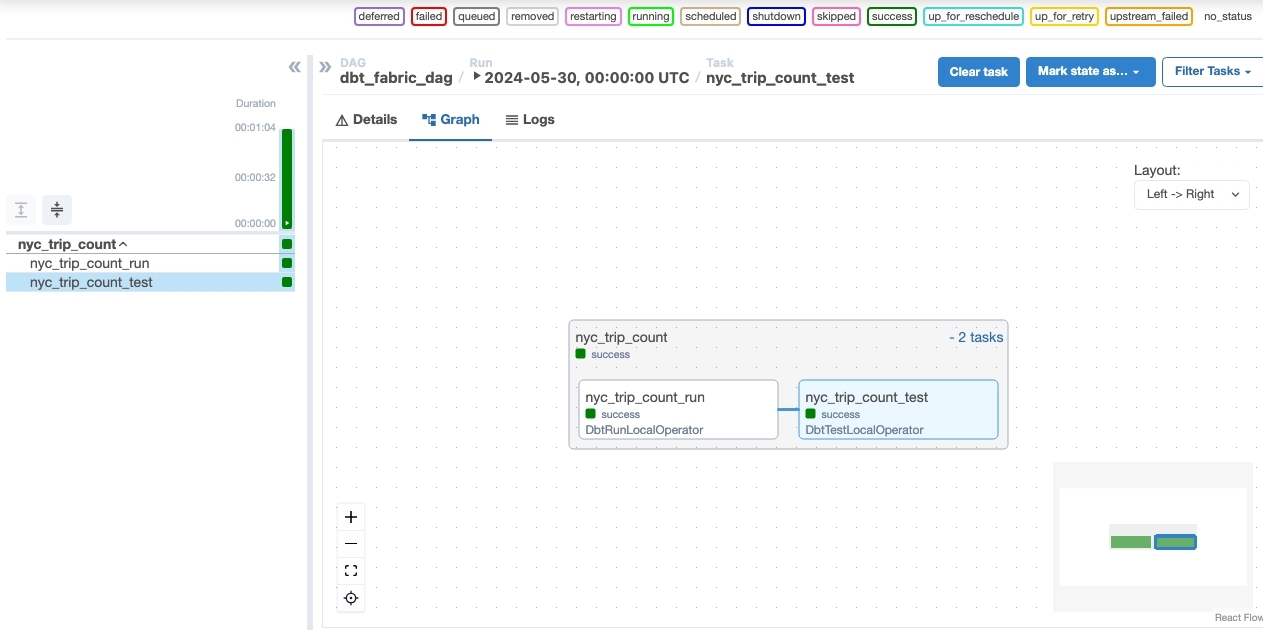
Eseguire il DAG
Eseguire il DAG all'interno del processo Apache Airflow.
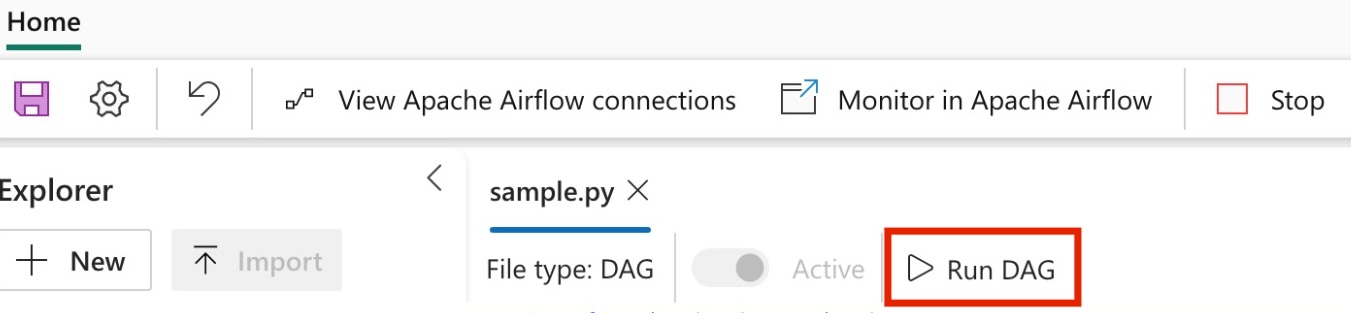
Per visualizzare il DAG caricato nell'interfaccia utente di Apache Airflow, fare clic su
Monitor in Apache Airflow.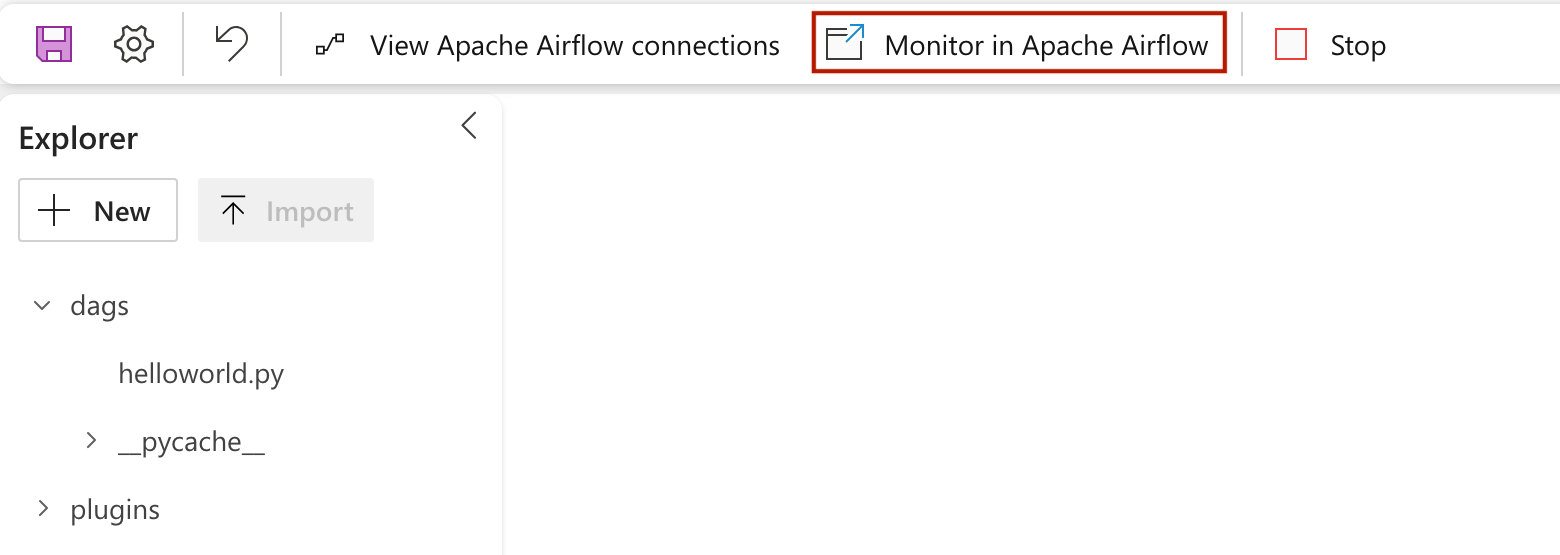



Convalidare l'app
- Dopo un'esecuzione corretta, per convalidare i dati, è possibile visualizzare la nuova tabella denominata "nyc_trip_count.sql" creata nel data warehouse di Fabric.