Visualizzazione dei notebook in Microsoft Fabric
Microsoft Fabric è un servizio di analisi integrato che riduce il tempo necessario per estrarre informazioni dettagliate da data warehouse e sistemi di analisi Big Data. La visualizzazione dei dati nei notebook è un componente chiave per ottenere informazioni dettagliate sui dati. Consente di semplificare la comprensione dei dati di grandi dimensioni e di piccole dimensioni per gli esseri umani. Semplifica anche il rilevamento di modelli, tendenze e outlier in gruppi di dati.
Quando si usa Apache Spark in Fabric, sono disponibili varie opzioni predefinite per visualizzare i dati, tra cui le opzioni del grafico dei notebook Fabric e l'accesso alle librerie open source più diffuse.
Quando si usa un notebook Fabric, è possibile trasformare la visualizzazione di risultati tabulari in un grafico personalizzato usando le opzioni del grafico. Qui è possibile visualizzare i dati senza dover scrivere alcun codice.
Comando di visualizzazione predefinito - funzione display()
La funzione di visualizzazione predefinita fabric consente di trasformare i dataframe Apache Spark, i dataframe Pandas e i risultati delle query SQL in visualizzazioni di dati in formato avanzato.
È possibile usare la funzione display nei DataFrame creati in PySpark e Scala in DataFrame Spark o funzioni RDD (Resilient Distributed Datasets) per produrre la visualizzazione tabella DataFrame e la visualizzazione grafico avanzate.
È possibile specificare il numero di righe del dataframe di cui viene eseguito il rendering. Il valore predefinito è 1000. Notebook visualizzare widget di output supporta la visualizzazione e il profilo 10000 righe di un dataframe al massimo.

È possibile usare la funzione di filtro sulla barra degli strumenti globale per filtrare in modo efficiente i dati che corrispondono con la tua regola personalizzata; la condizione viene applicata alla colonna specificata, e il risultato del filtro si riflette sia nella visualizzazione tabella che in quella grafico.

L'output dell'istruzione SQL adotta lo stesso widget di output con display() per impostazione predefinita.
Visualizzazione tabella DataFrame avanzata
Supporto per la selezione libera nella visualizzazione della tabella
La visualizzazione Tabella viene sottoposta a rendering per impostazione predefinita quando si usa il comando display(). L'anteprima avanzata dei dataframe nel notebook offre una funzione di selezione gratuita progettata per migliorare l'esperienza di analisi dei dati tramite funzionalità di selezione flessibili e intuitive. Questa funzionalità consente agli utenti di interagire con i dataframe in modo più efficiente e ottenere informazioni più approfondite con facilità.
Selezione colonna
- colonna unica: fare clic sull'intestazione della colonna per selezionare l'intera colonna.
- Più colonne: Dopo aver selezionato una singola colonna, tenere premuto il tasto 'MAIUSC', quindi cliccare su un'altra intestazione di colonna per selezionare più colonne.
selezione della riga
- riga singola: fare clic su un'intestazione di riga per selezionare l'intera riga.
- Più righe: Dopo aver selezionato una singola riga, tenere premuto il tasto 'Shift', quindi fare clic su un'altra Intestazione di riga per selezionare più righe.
Anteprima contenuto cella: visualizzare in anteprima il contenuto delle singole celle per ottenere un'analisi rapida e dettagliata dei dati senza la necessità di scrivere codice aggiuntivo.
Riepilogo colonne: Ottenere un riepilogo di ogni colonna, inclusa la distribuzione dei dati e le statistiche principali, per capire rapidamente le caratteristiche dei dati.
selezione dell'area libera: selezionare qualsiasi segmento continuo della tabella per ottenere una panoramica delle celle selezionate totali e dei valori numerici nell'area selezionata.
Copiare il contenuto selezionato: In tutti i casi di selezione, puoi copiare rapidamente il contenuto selezionato usando la scorciatoia da tastiera "Ctrl + C". I dati selezionati vengono copiati in formato CSV, semplificando l'elaborazione in altre applicazioni.
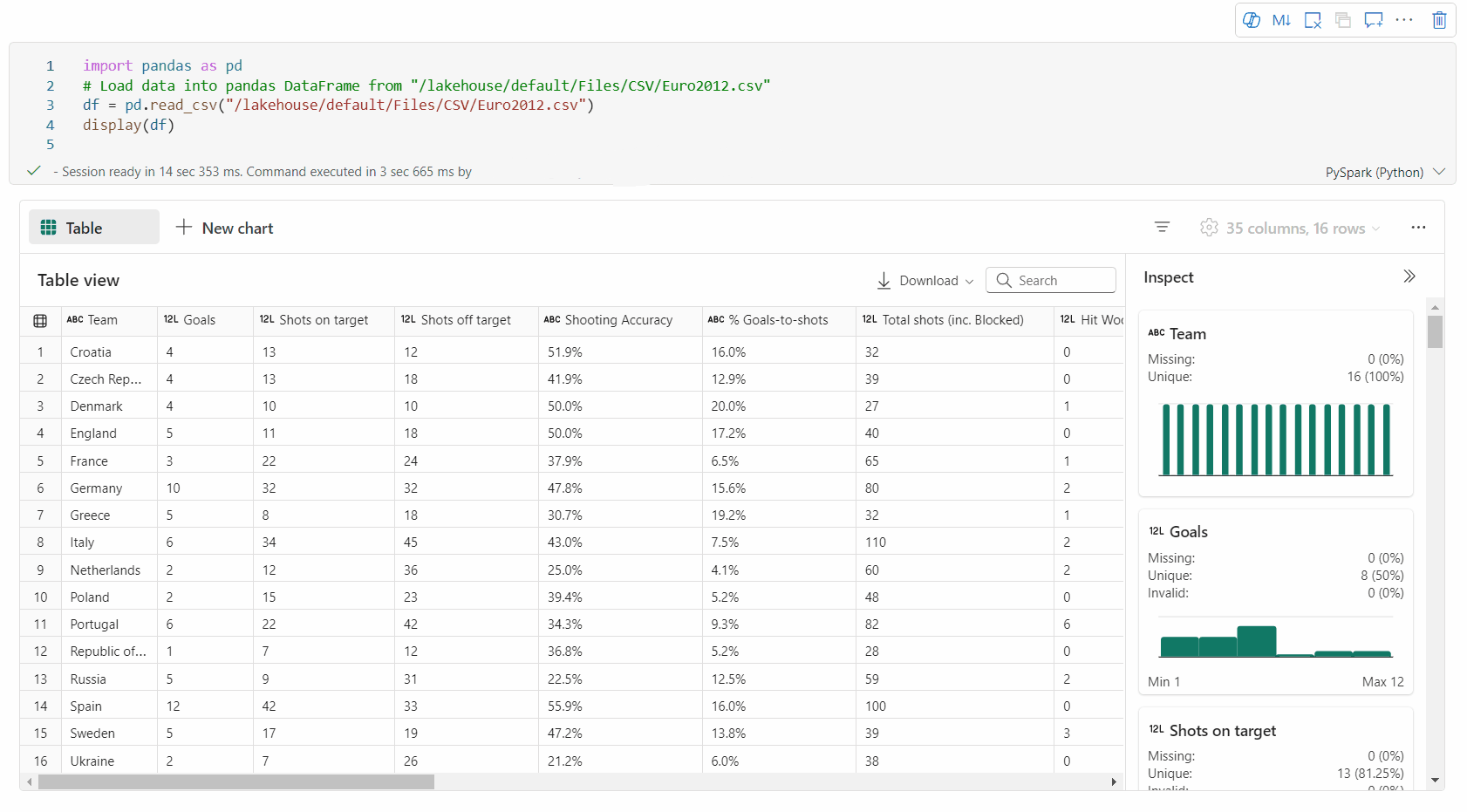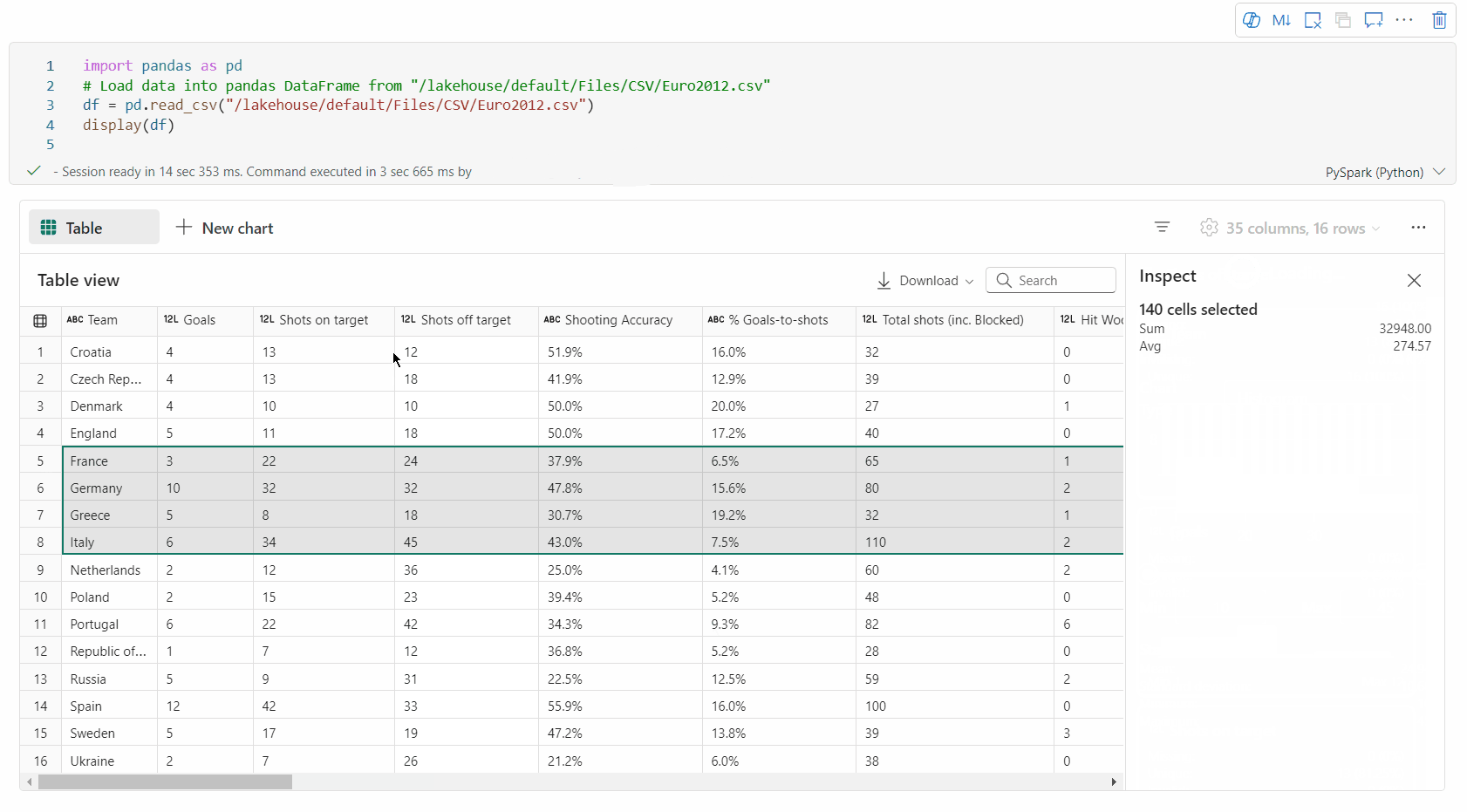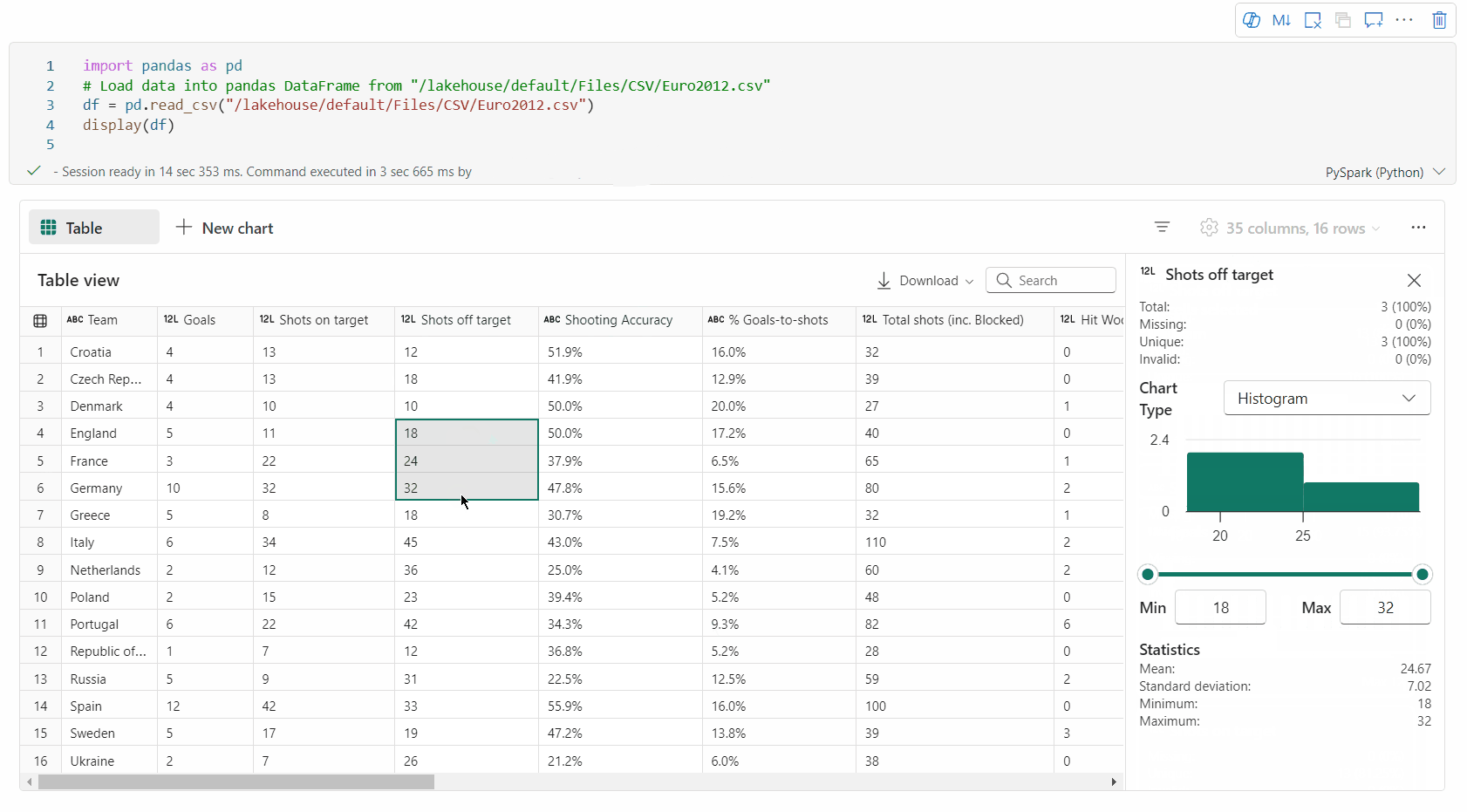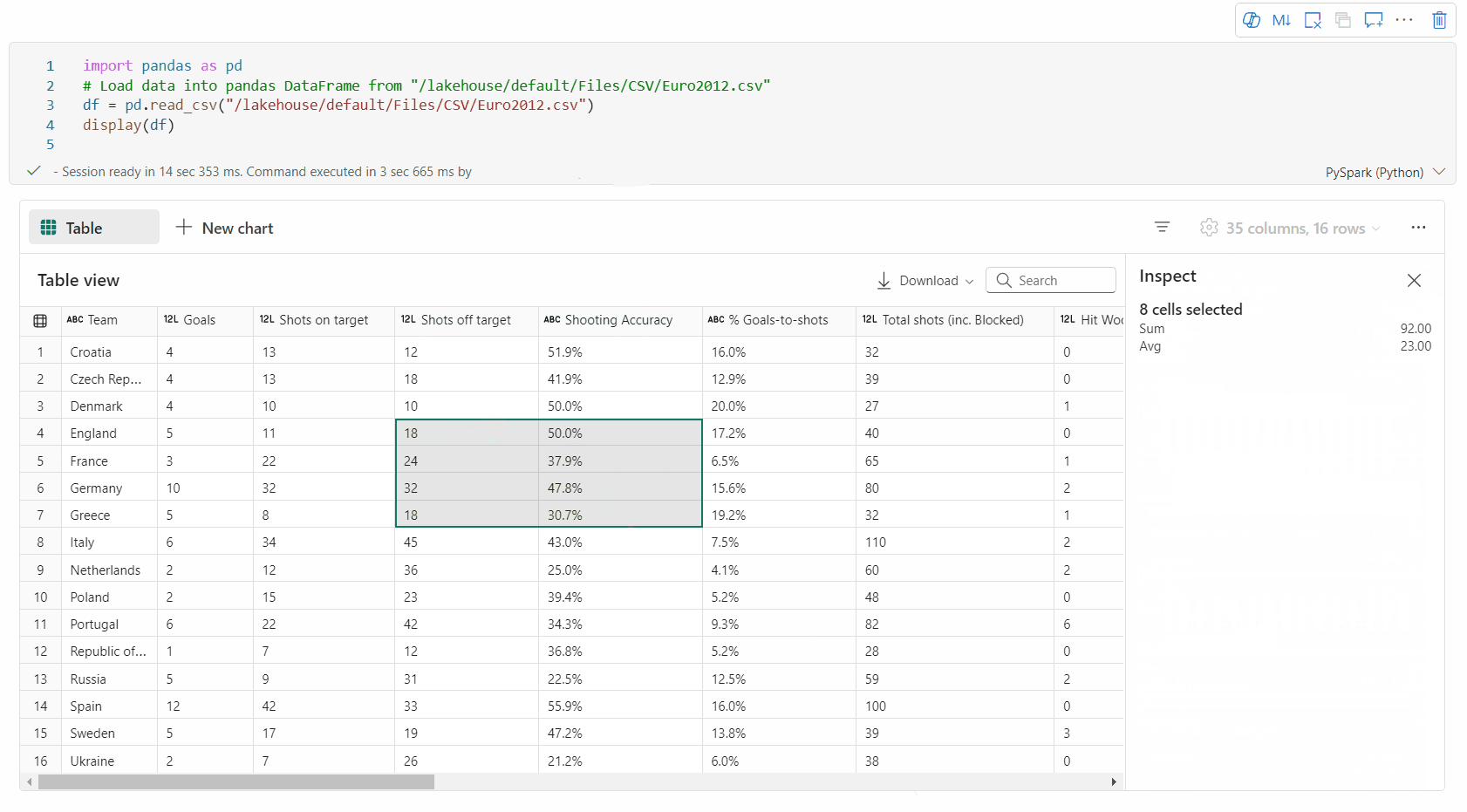
Supporto per la profilatura dei dati tramite il riquadro Ispeziona
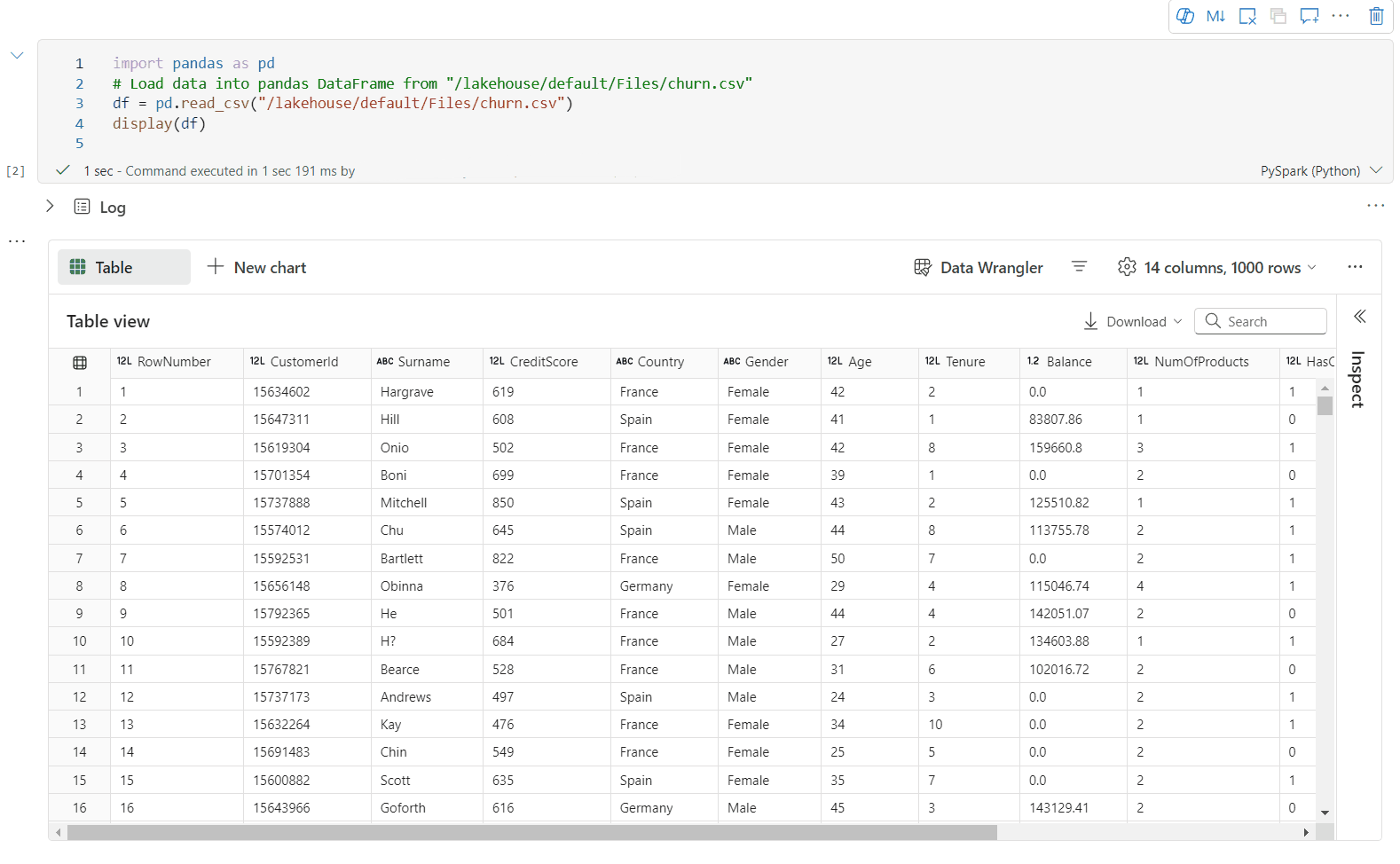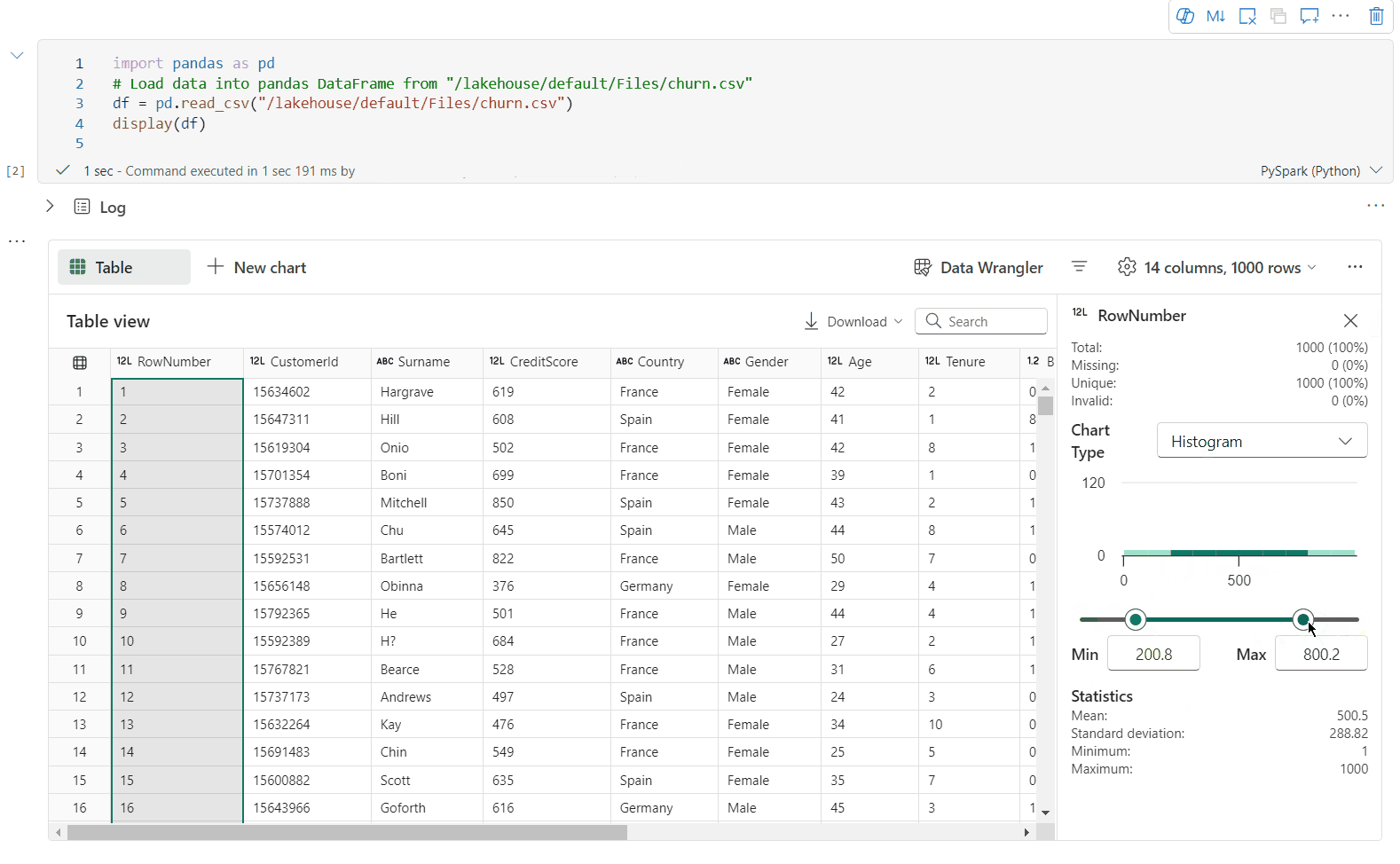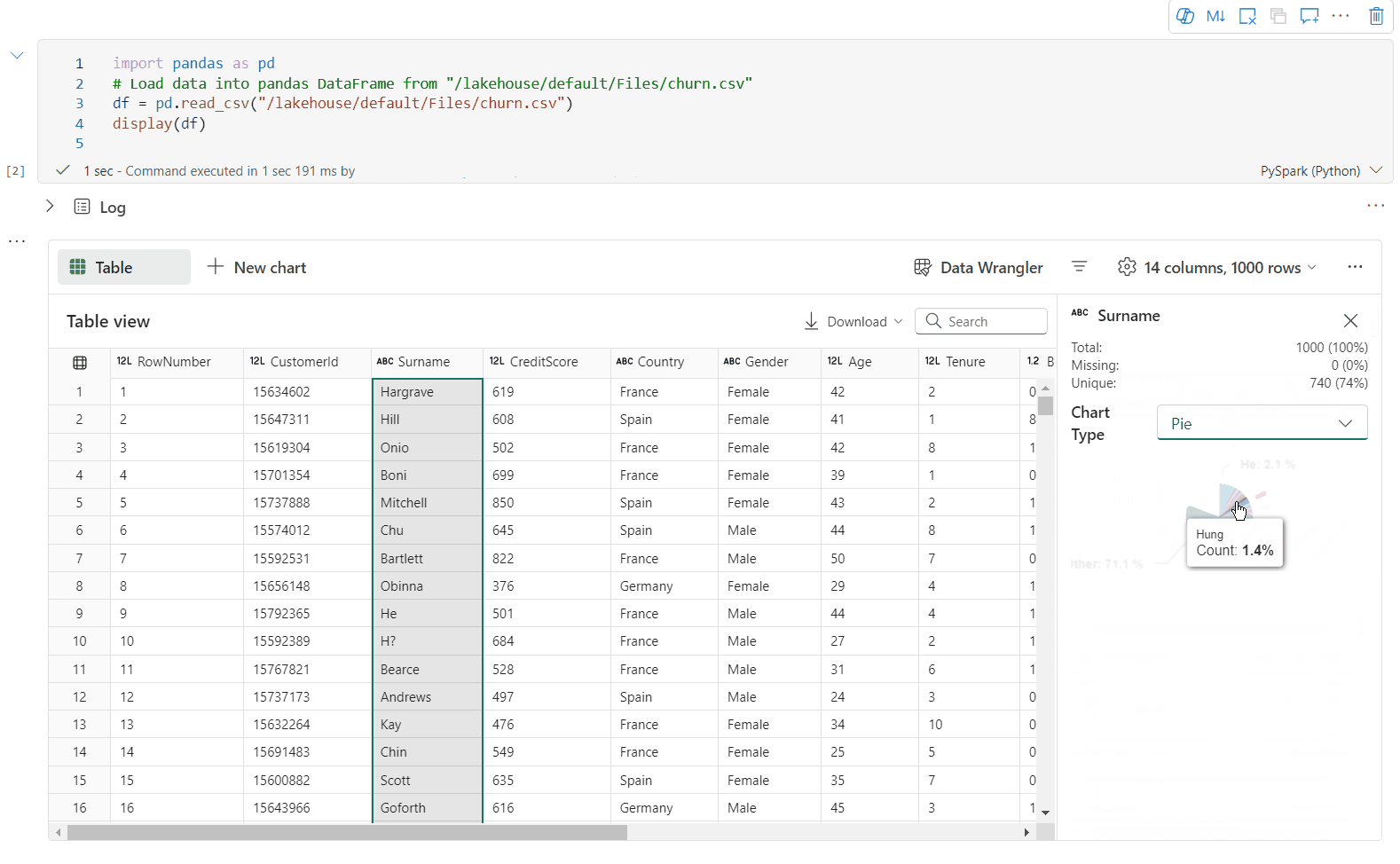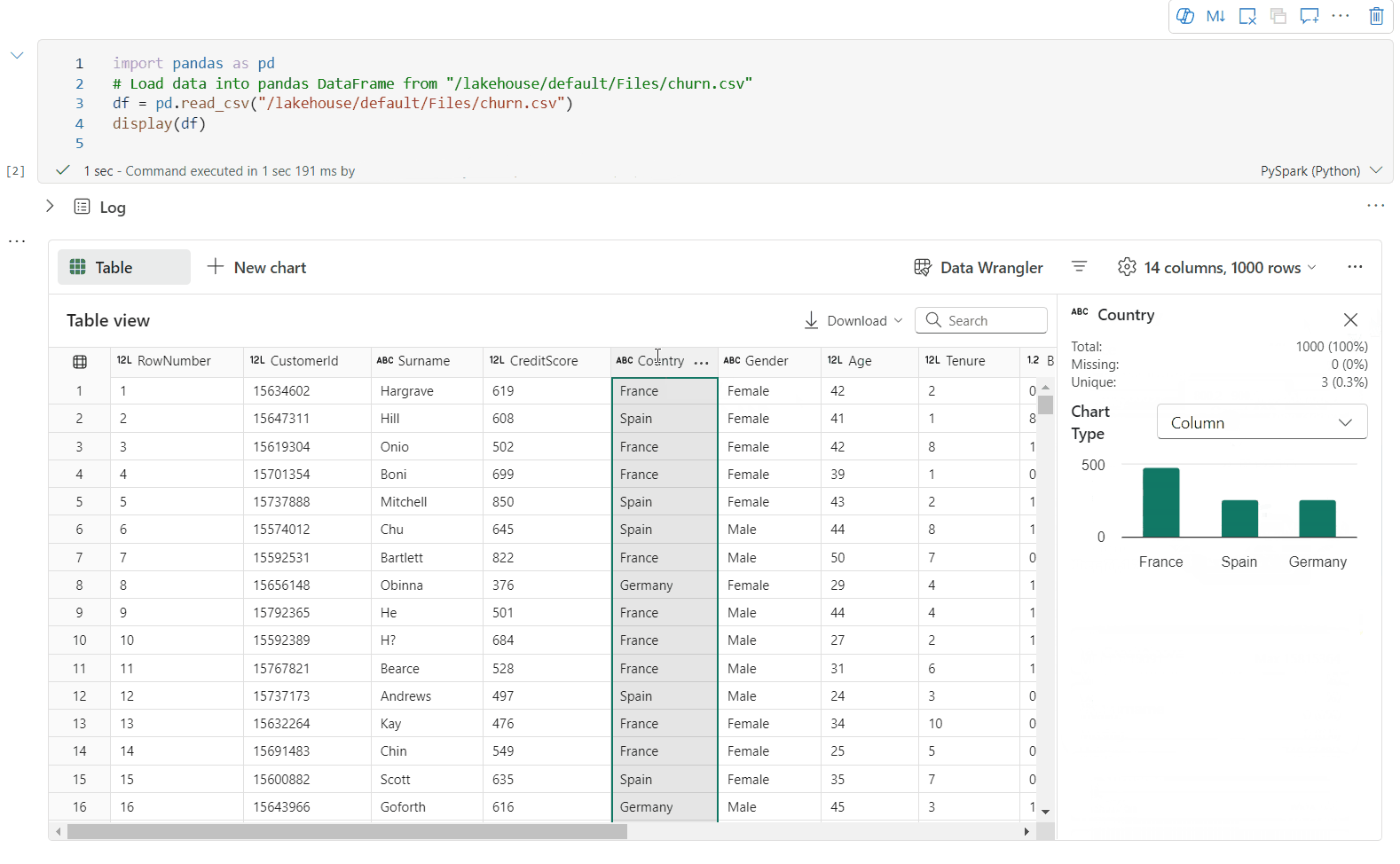
È possibile profilare il DataFrame facendo clic sul pulsante Controlla. Fornisce la distribuzione dei dati riepilogata e mostra le statistiche di ogni colonna.
Ogni scheda nel riquadro laterale "Controlla" esegue il mapping a una colonna del DataFrame; è possibile visualizzare altri dettagli facendo clic sulla scheda o selezionando una colonna nella tabella.
È possibile visualizzare i dettagli della cella facendo clic sulla cella della tabella. Questa funzionalità è utile quando il dataframe contiene un tipo di contenuto stringa lungo.
Nuova visualizzazione grafico con frame di dati avanzati
Nota
Attualmente, la funzionalità è in anteprima.
La visualizzazione grafico migliorata è disponibile nel comando display(). Offre un'esperienza più intuitiva e potente per la visualizzazione dei dati tramite il comando display().
È ora possibile aggiungere fino a 5 grafici in un widget di output display() facendo clic su Nuovo grafico, consentendo di creare più grafici in base a colonne diverse e confrontare facilmente i grafici.
È possibile ottenere un elenco di raccomandazioni per i grafici in base al dataframe di destinazione durante la creazione di nuovi grafici. È possibile scegliere di modificare un grafico consigliato o di creare un grafico personalizzato da zero.
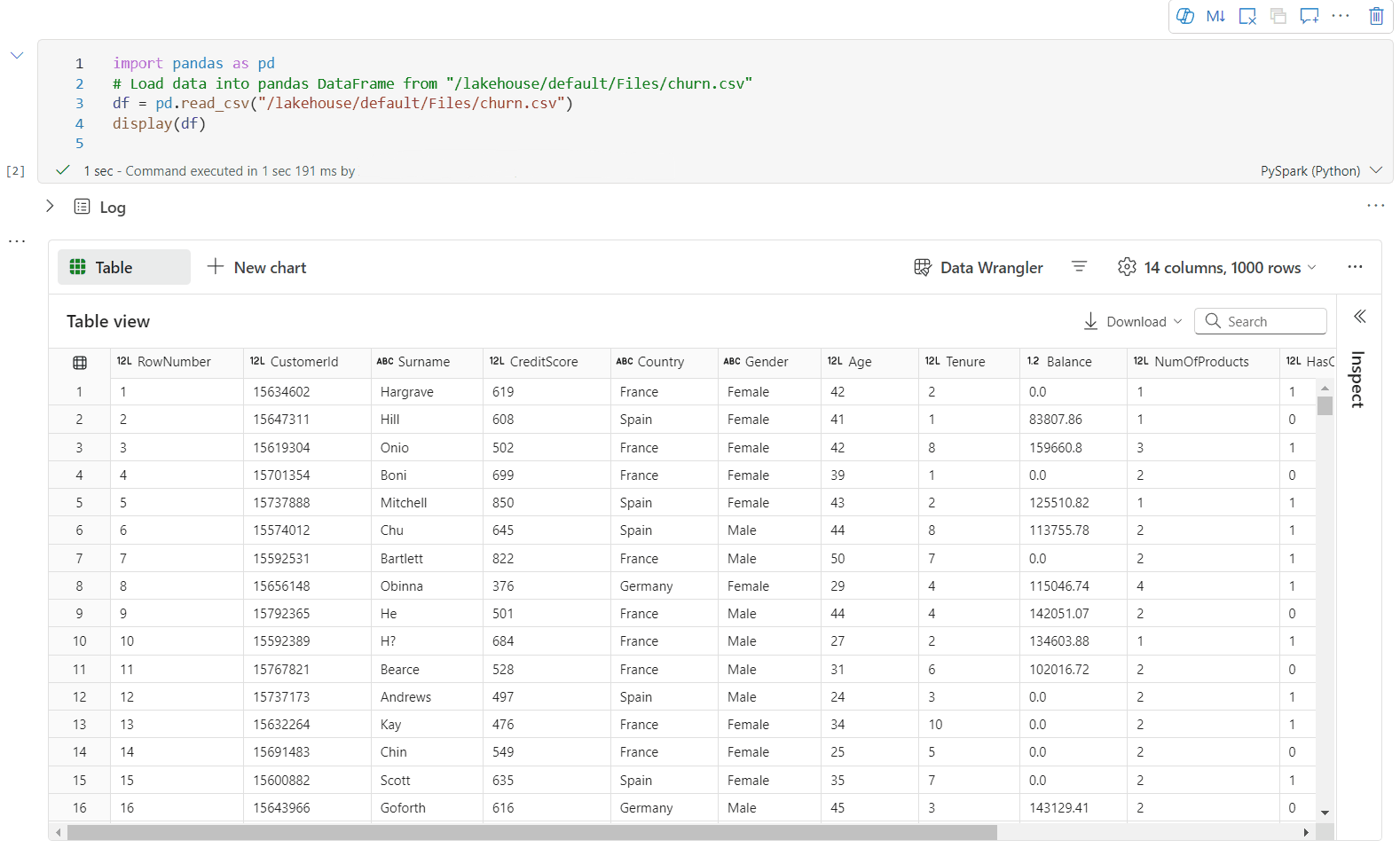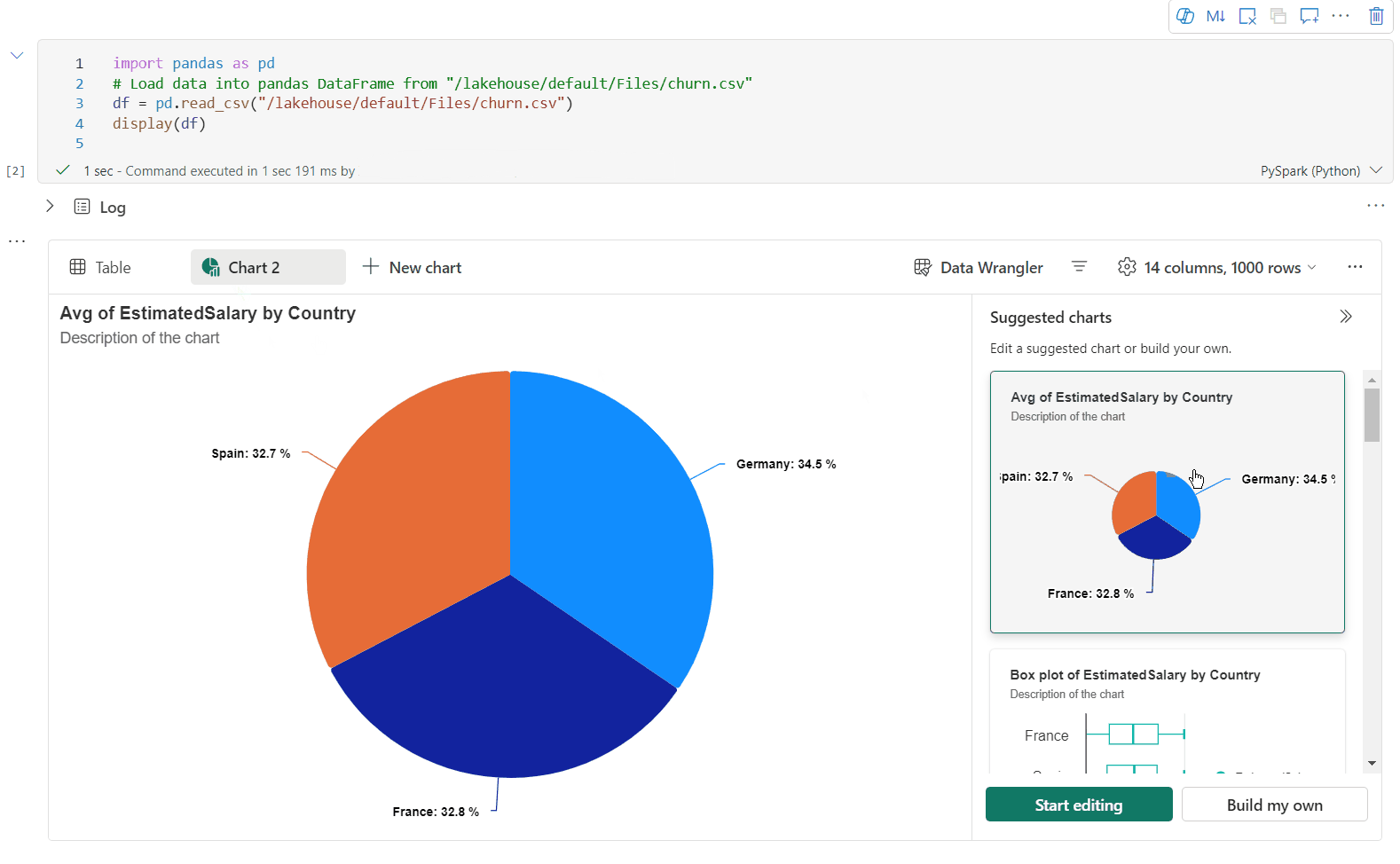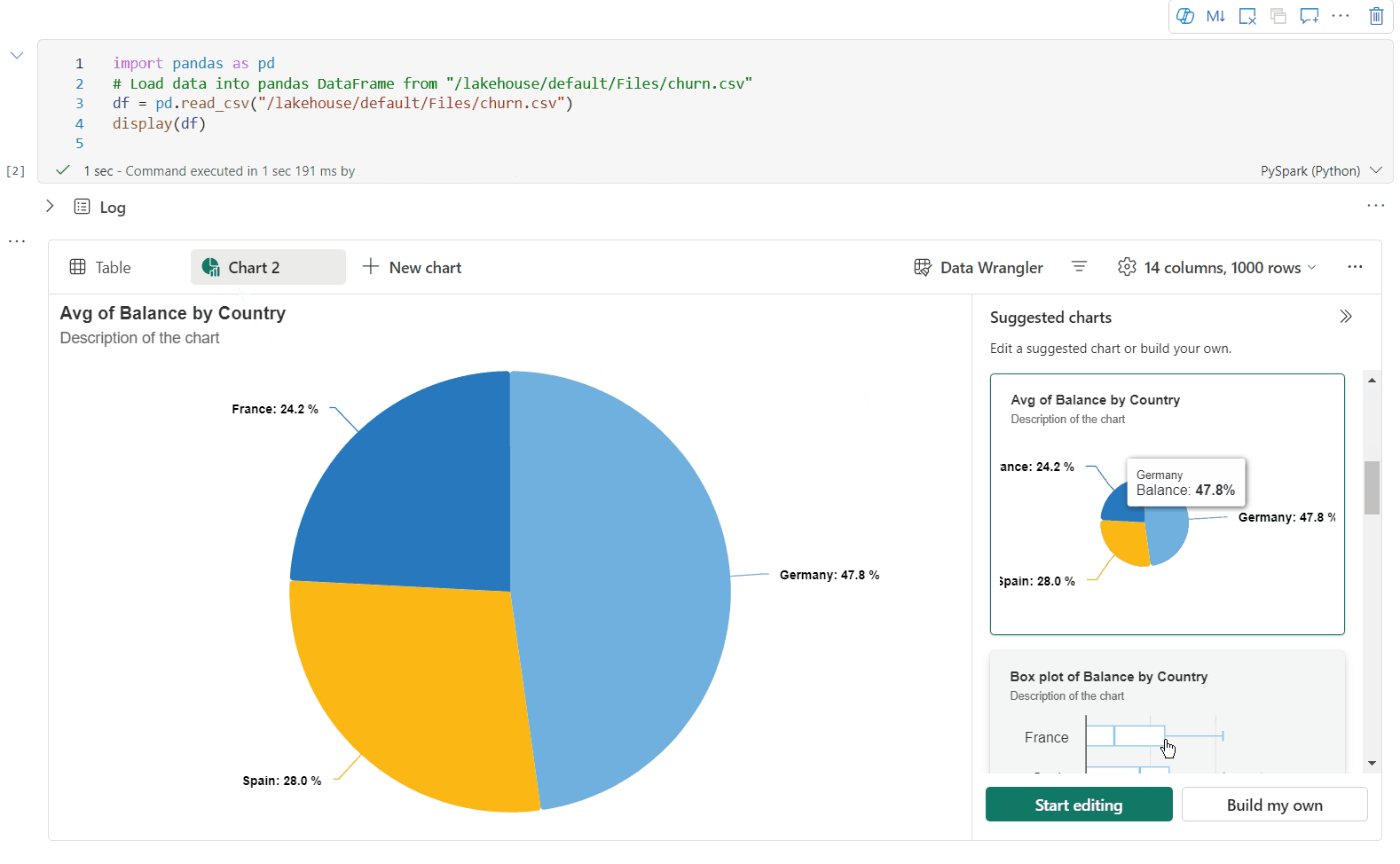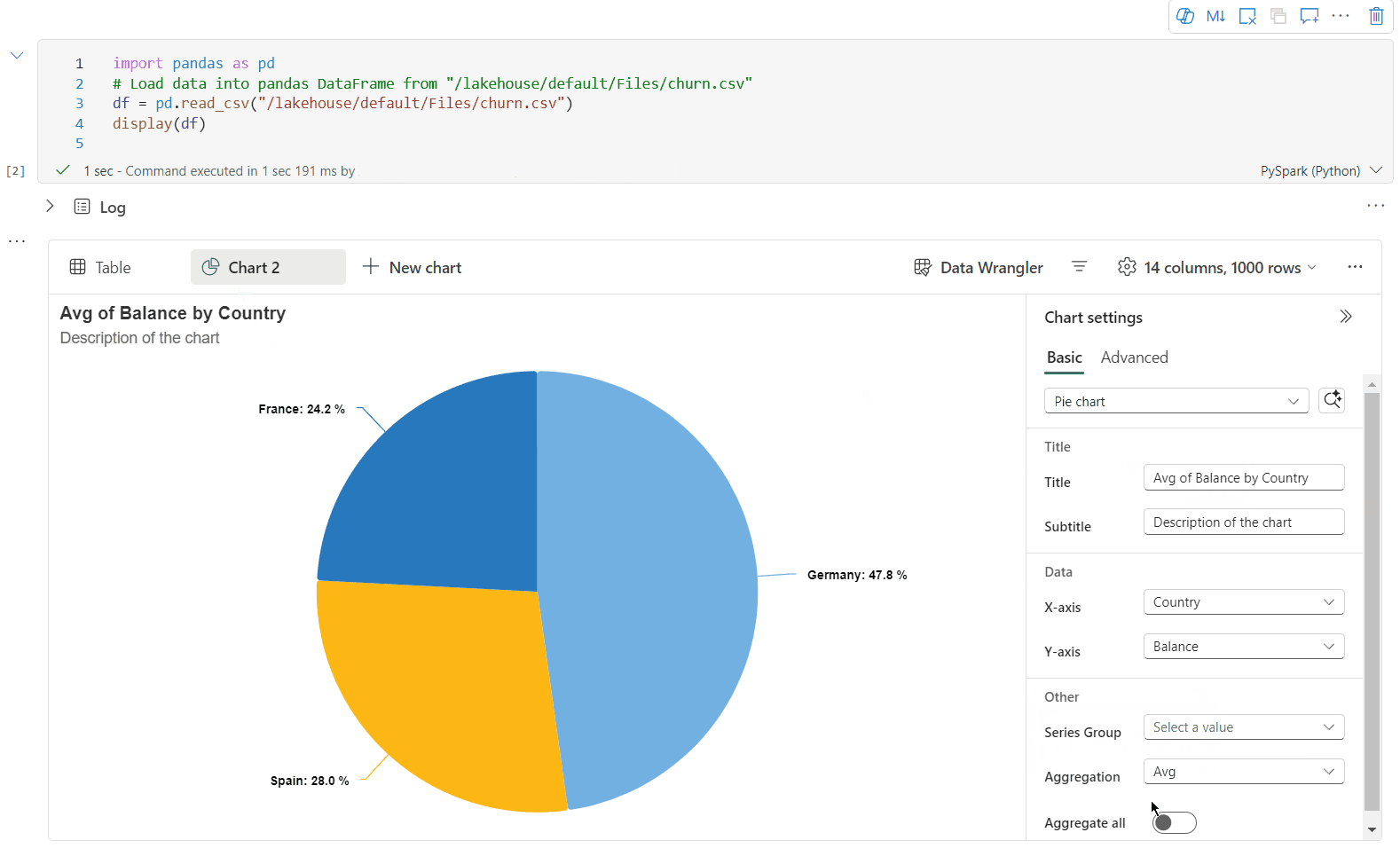
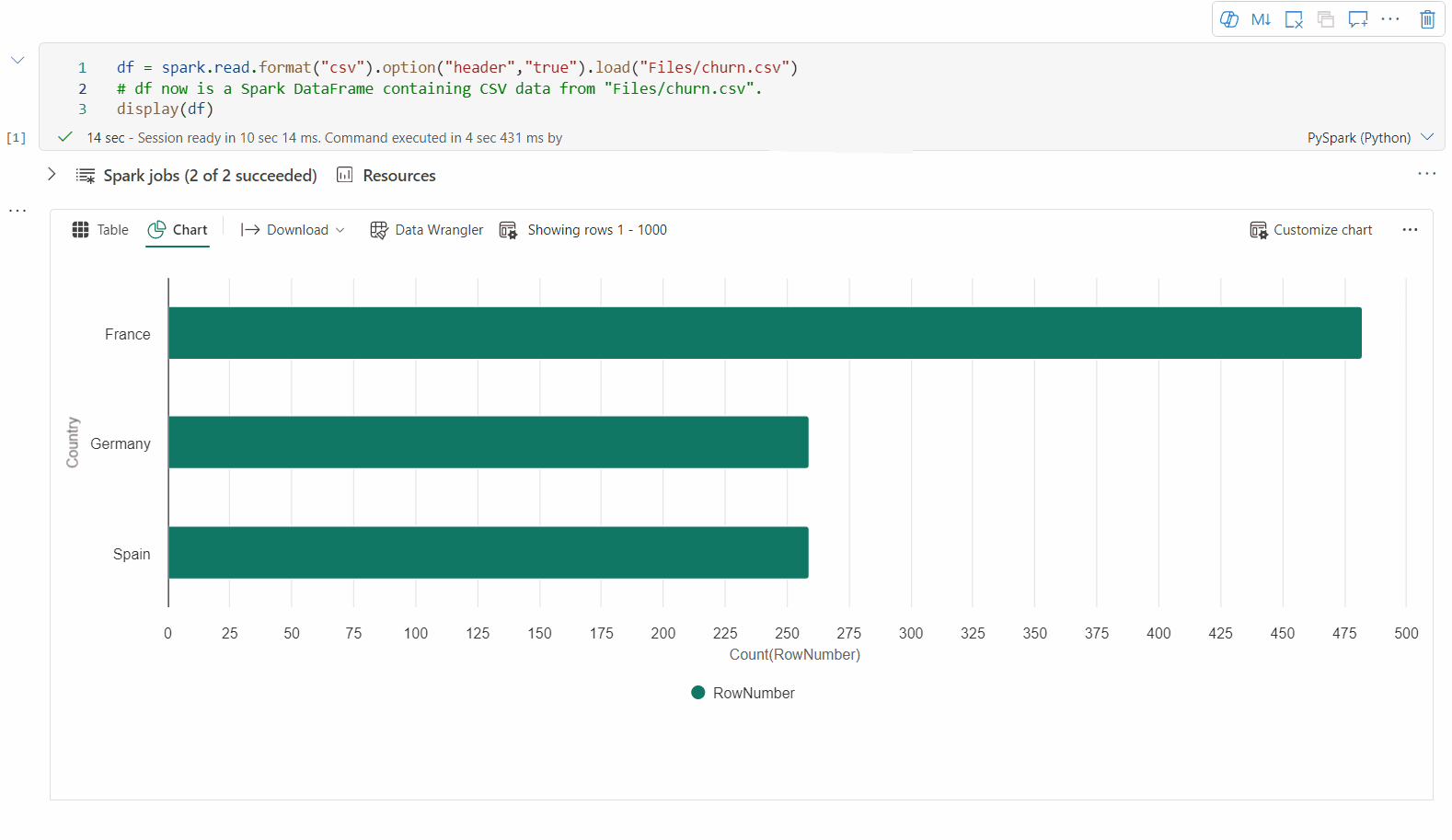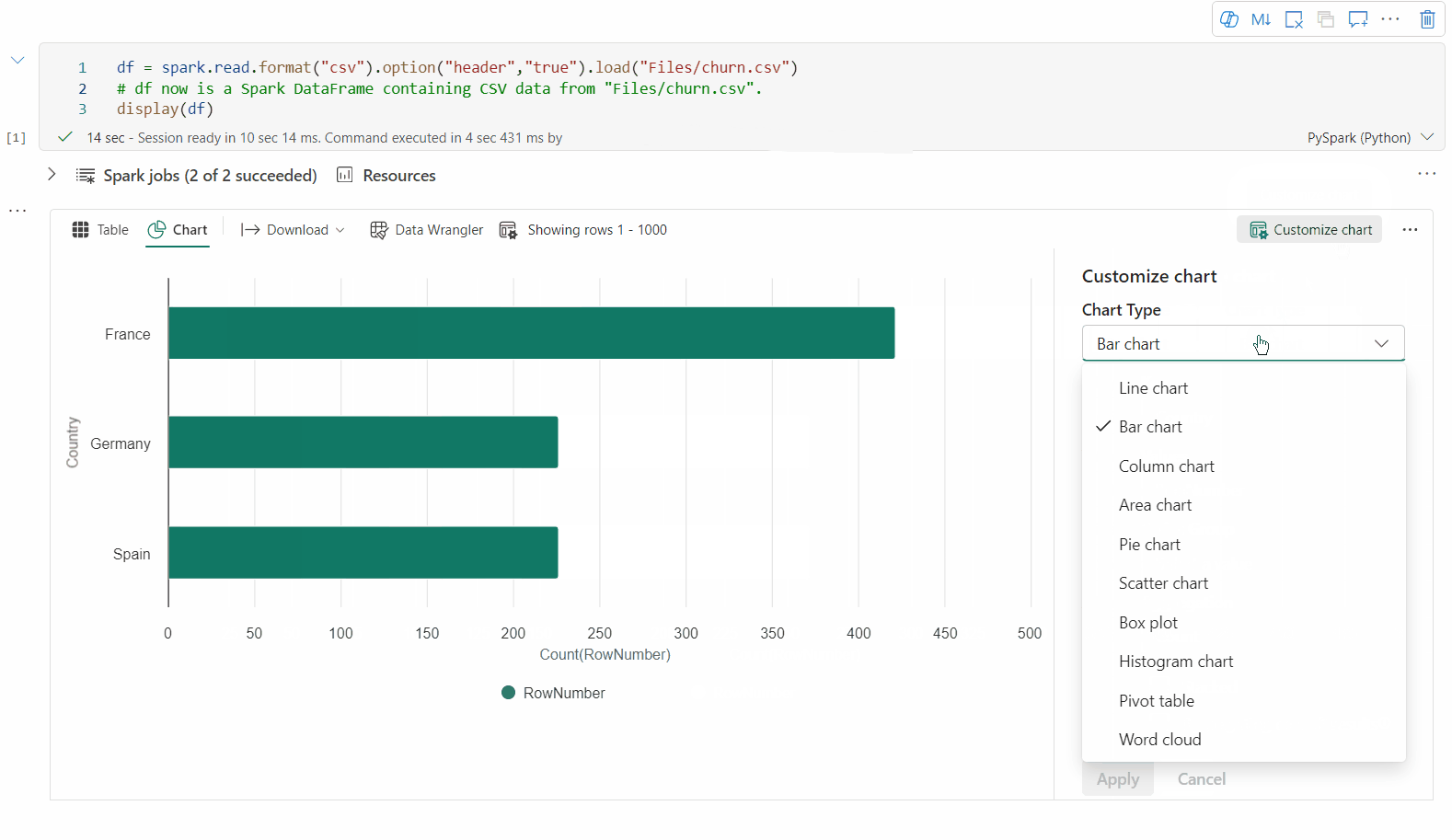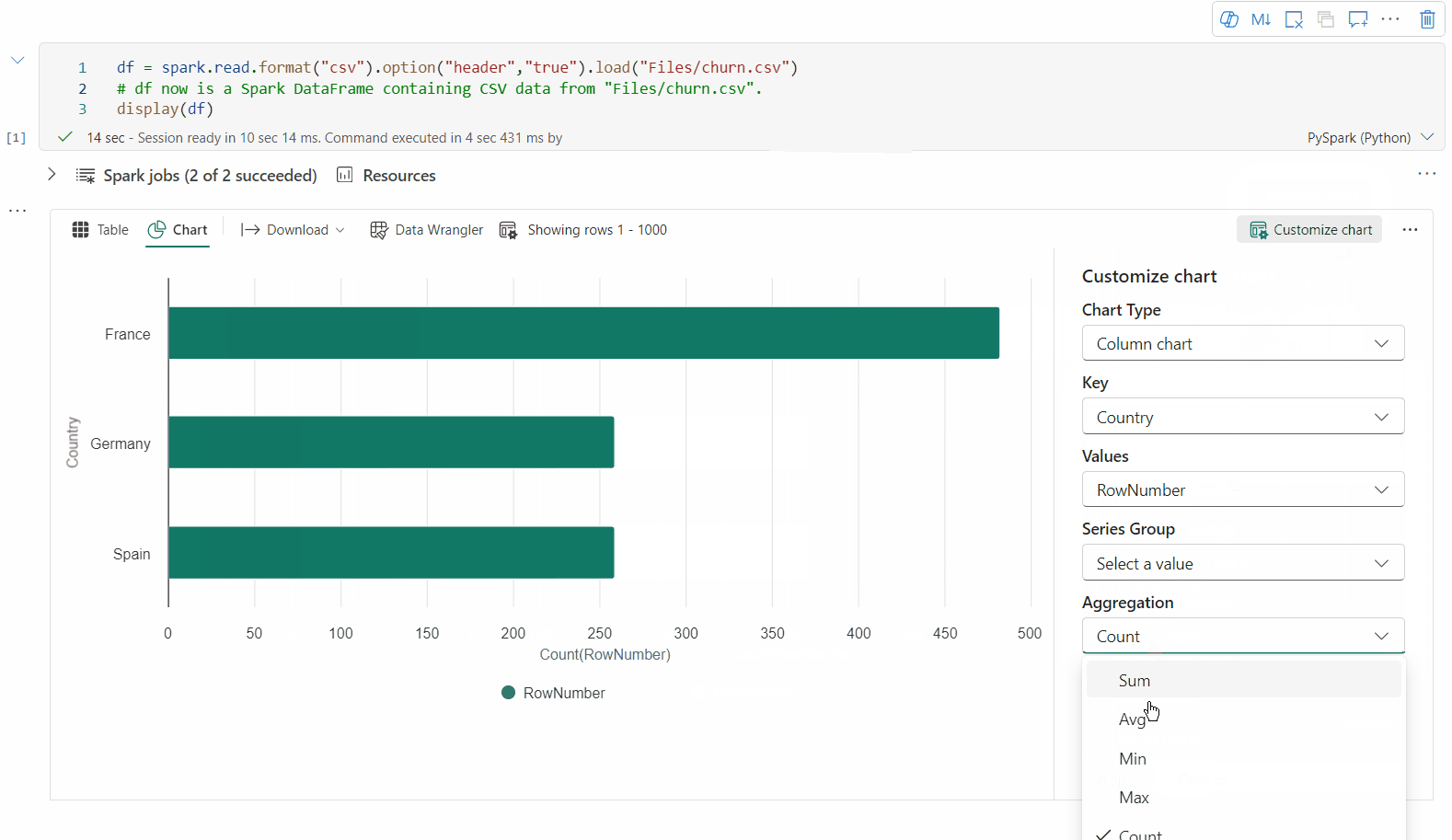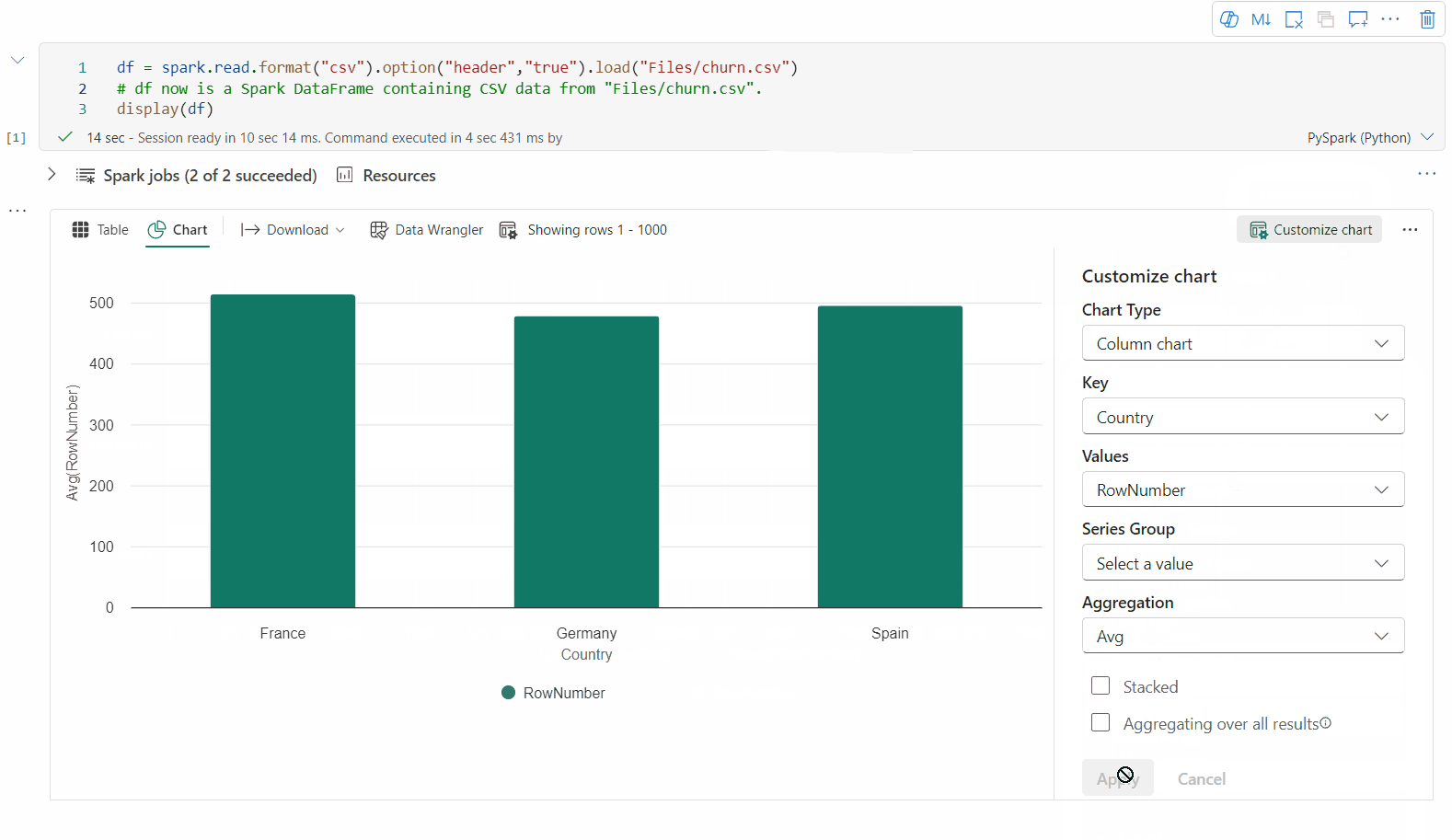
È ora possibile personalizzare la visualizzazione specificando le impostazioni seguenti. Le opzioni di impostazione possono cambiare in base al tipo di grafico selezionato:
Categoria Impostazioni di base Descrizione Tipo di grafico La funzione di visualizzazione supporta un'ampia gamma di tipi di grafico, tra cui grafici a barre, grafici a dispersione, grafici a linee, tabella pivot e altro ancora. Title Title Titolo del grafico. Title Sottotitolo Sottotitolo del grafico con altre descrizioni. Dati Asse X Specificare la chiave del grafico. Dati Asse Y Specificare i valori del grafico. Legenda Mostra legenda Abilitare/disabilitare la legenda. Legenda Posizione Personalizzare la posizione della legenda. Altro Gruppo Serie Usare questa configurazione per determinare i gruppi per l'aggregazione. Altro Aggregazione usare questo metodo per aggregare i dati nella visualizzazione. Altro In pila Configurare lo stile di visualizzazione del risultato. Nota
Per impostazione predefinita, la funzione display(df) accetta solo le prime 1.000 righe dei dati per il rendering dei grafici. Selezionare Aggregazione su tutti i risultati e quindi selezionare Applica per applicare la generazione del grafico dall'intero dataframe. Un processo Spark viene attivato quando cambia l'impostazione del grafico. Potrebbero essere necessari alcuni minuti per completare il calcolo ed eseguire il rendering del grafico.
Categoria Impostazioni avanzate Descrizione Color Tema Definire il set di colori del tema del grafico. Asse X Etichetta Specificare un'etichetta sull'asse X. Asse X Ridimensiona Specificare la funzione di scala dell'asse X. Asse X Intervallo Specificare l'asse X dell'intervallo di valori. Asse Y Etichetta Specificare un'etichetta sull'asse Y. Asse Y Ridimensiona Specificare la funzione di scala dell'asse Y. Asse Y Intervallo Specificare l'asse Y dell'intervallo di valori. Schermo Mostra etichette Mostra/nascondi le etichette dei risultati nel grafico. Le modifiche delle configurazioni diventano effettive immediatamente e tutte le configurazioni vengono salvate automaticamente nel contenuto del notebook.
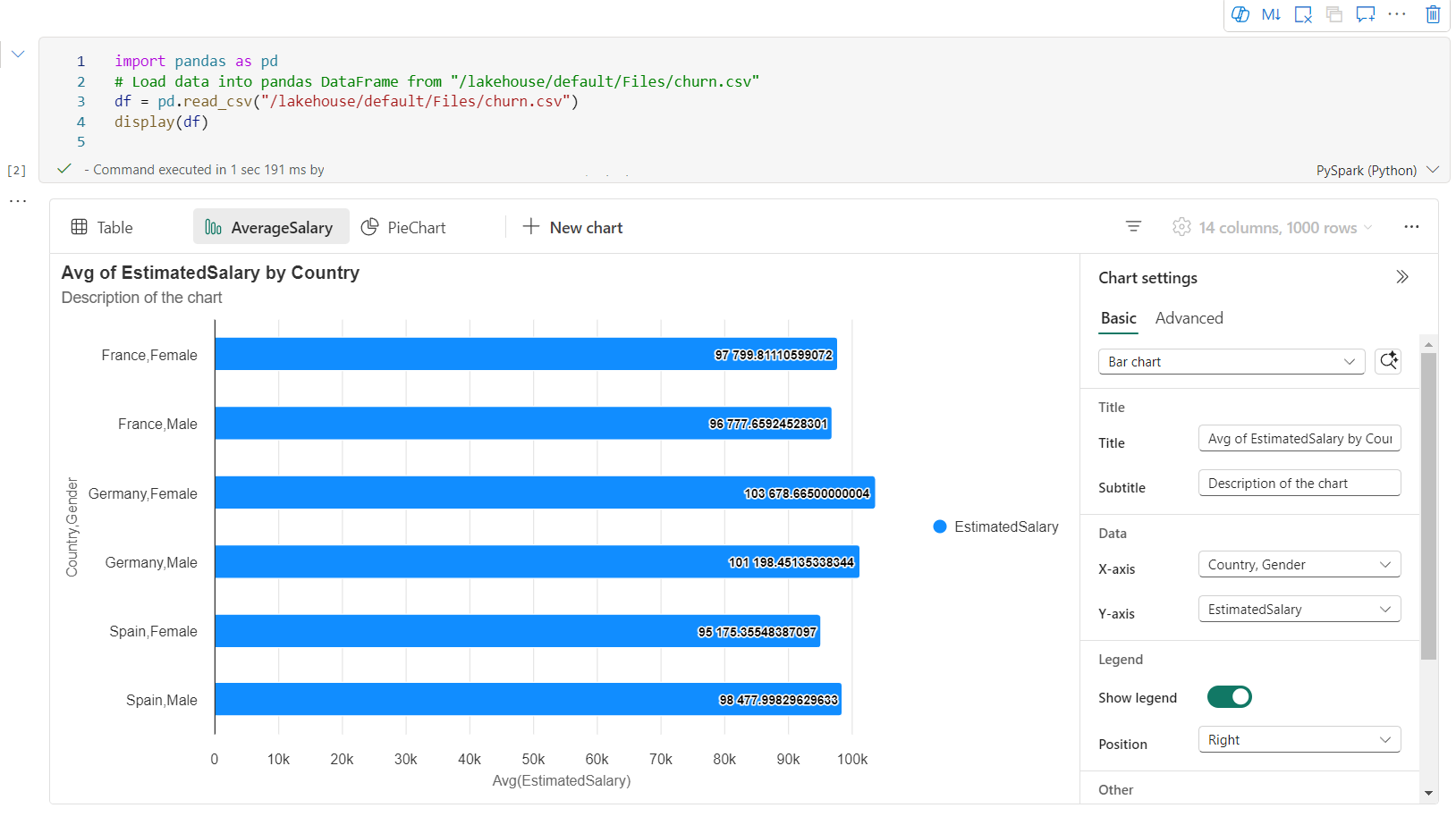
È possibile rinominare, duplicare o eliminare facilmente grafici nel menu a schede del grafico.
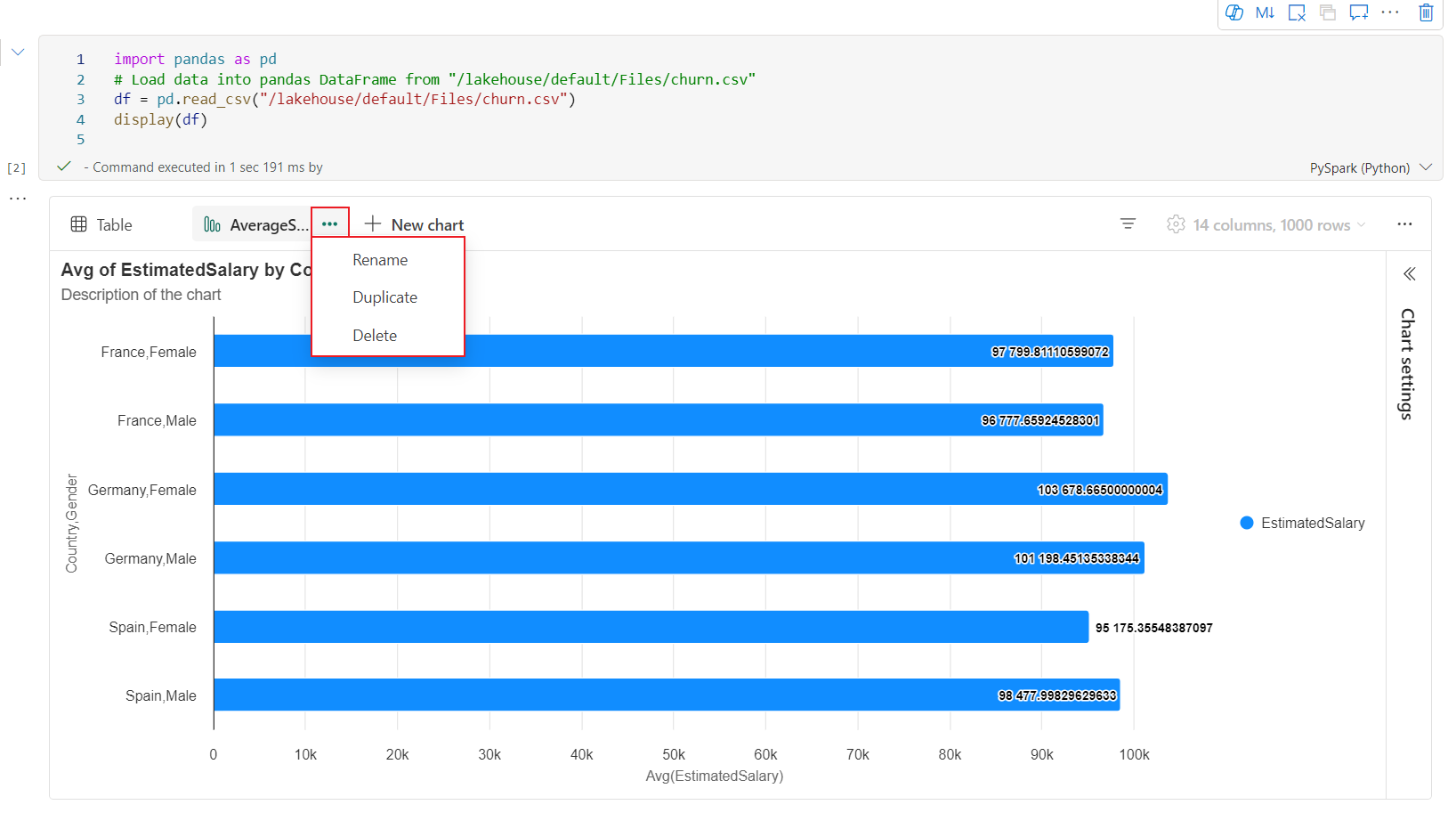
Una barra degli strumenti interattiva è disponibile nella nuova esperienza del grafico quando l'utente passa il mouse su un grafico. Supportare operazioni come zoom avanti, zoom indietro, selezionare zoom indietro, reimpostare, panoramica e così via.
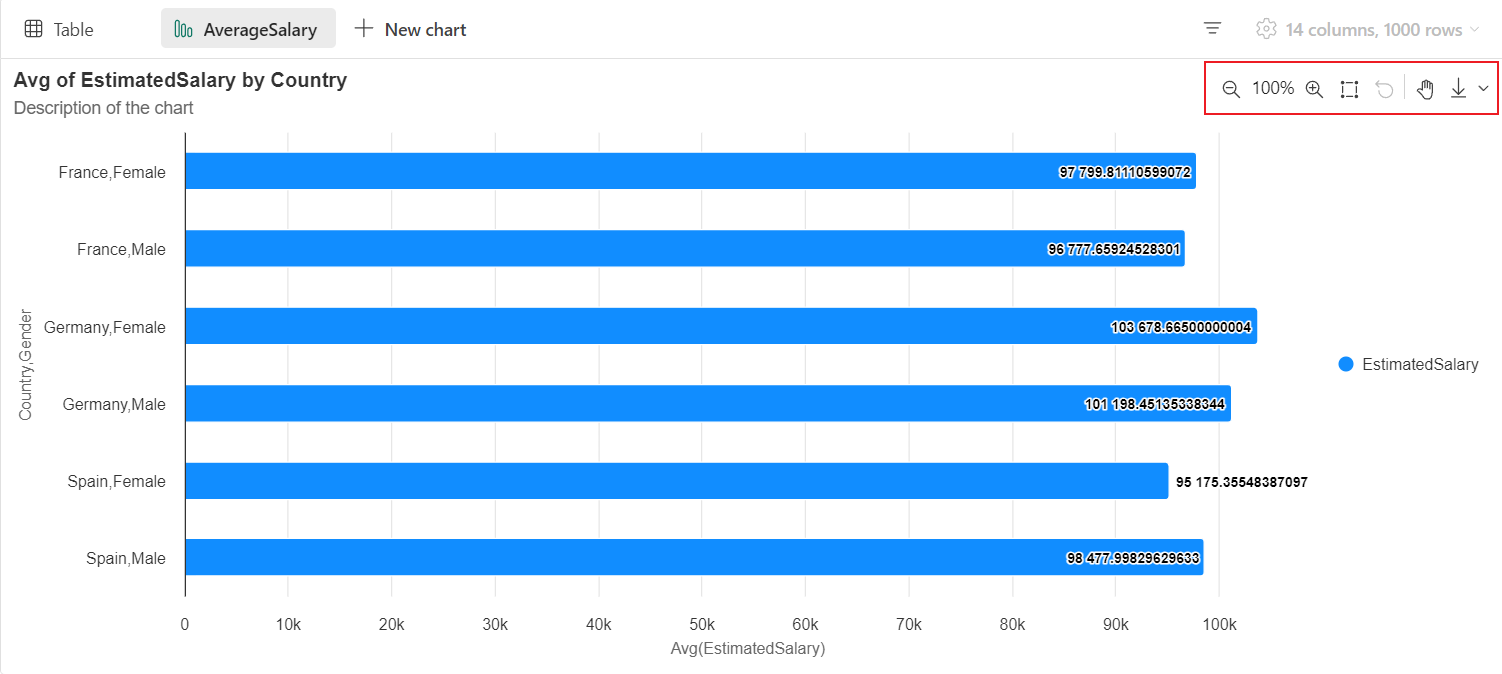



Visualizzazione grafico legacy
Nota
La visualizzazione grafico legacy verrà deprecata al termine dell'anteprima della nuova visualizzazione grafico.
È possibile tornare alla visualizzazione grafico legacy disattivando "Nuova visualizzazione". La nuova esperienza è abilitata per impostazione predefinita.
Dopo aver eseguito il rendering di una visualizzazione tabella, passare alla visualizzazione Grafico.
Il notebook di Fabric consiglia automaticamente grafici basati sul dataframe di destinazione, per rendere significativo il grafico con informazioni dettagliate sui dati.
È ora possibile personalizzare la visualizzazione specificando i valori seguenti:
Configurazione Descrizione Tipo di grafico La funzione supporta un'ampia gamma di tipi di grafico, tra cui grafici a barre, grafici a dispersione, grafici a linee e altro. Chiave Specificare l'intervallo di valori per l'asse x. Valore Specificare l'intervallo di valori per i valori dell'asse y. Gruppo Serie Usare questa configurazione per determinare i gruppi per l'aggregazione. Aggregazione usare questo metodo per aggregare i dati nella visualizzazione. Le configurazioni vengono salvate automaticamente nel contenuto dell'output del notebook.
Nota
Per impostazione predefinita, la funzione display(df)
accetta solo le prime 1.000 righe dei dati per creare i grafici. Selezionare Aggregazione su tutti i risultati e quindi selezionare Applica per applicare la generazione del grafico dall'intero dataframe. Un processo Spark viene attivato quando cambia l'impostazione del grafico. Potrebbero essere necessari alcuni minuti per completare il calcolo ed eseguire il rendering del grafico. Al termine del processo, è possibile visualizzare e interagire con la visualizzazione finale.

visualizzazione di riepilogo display()
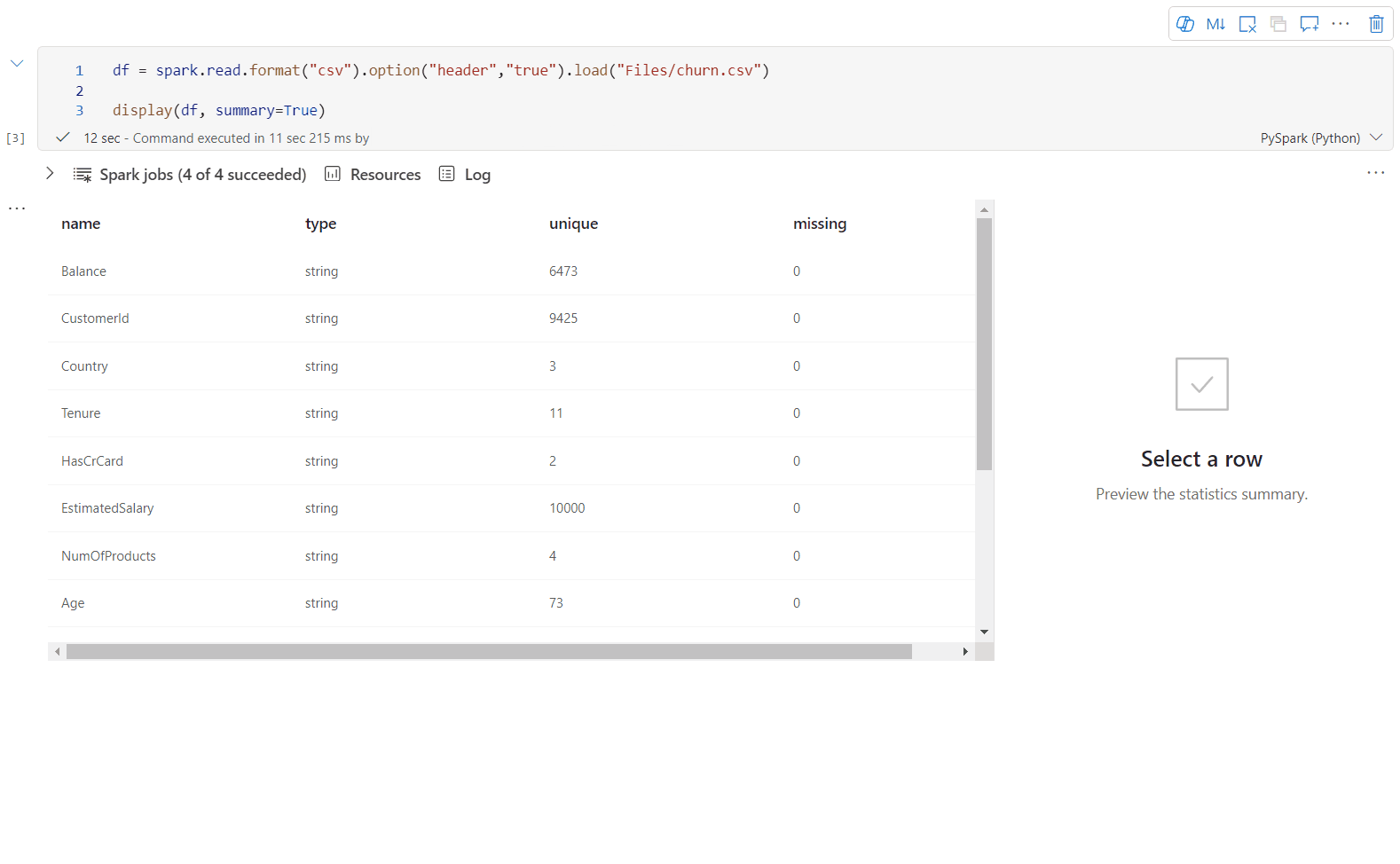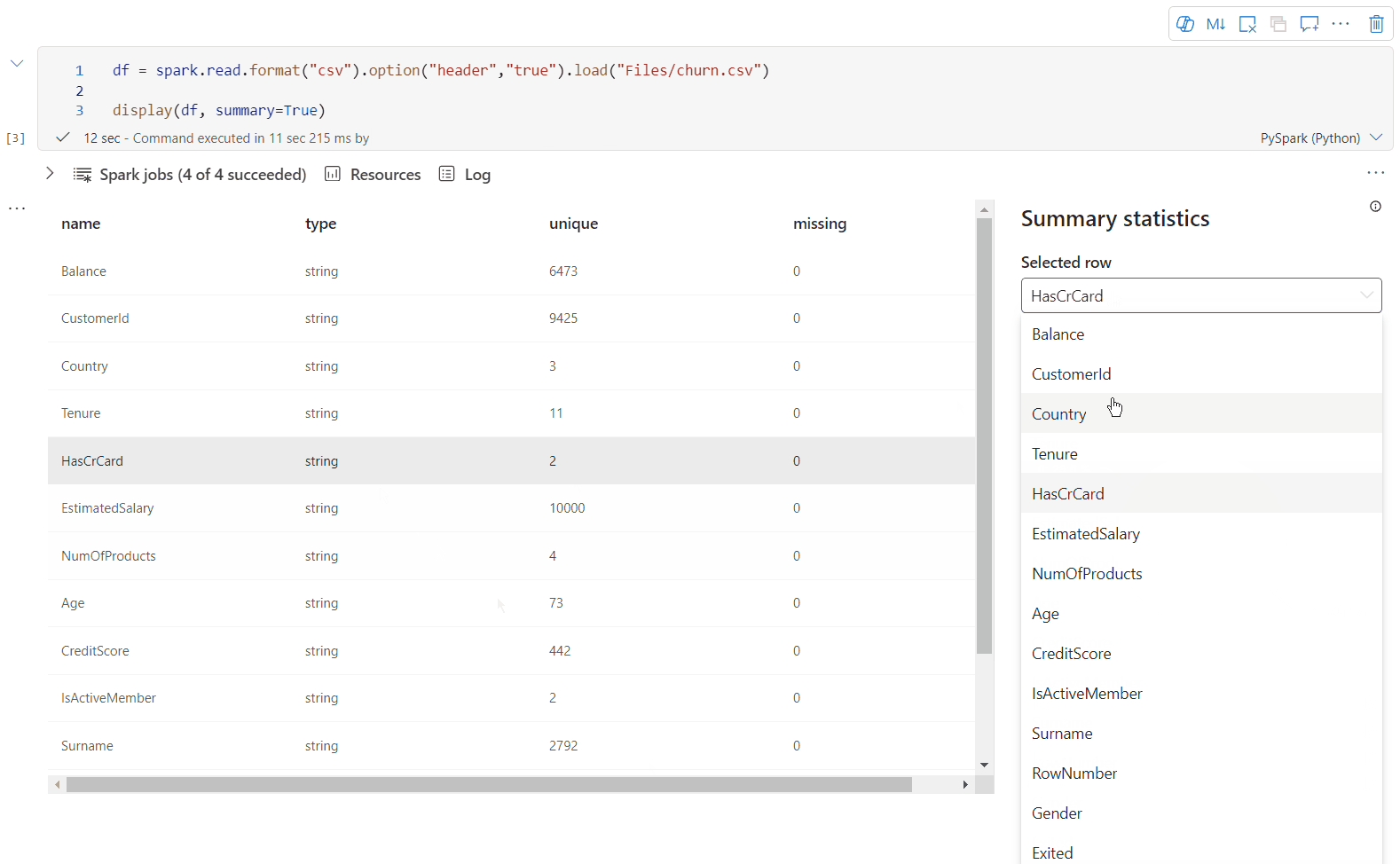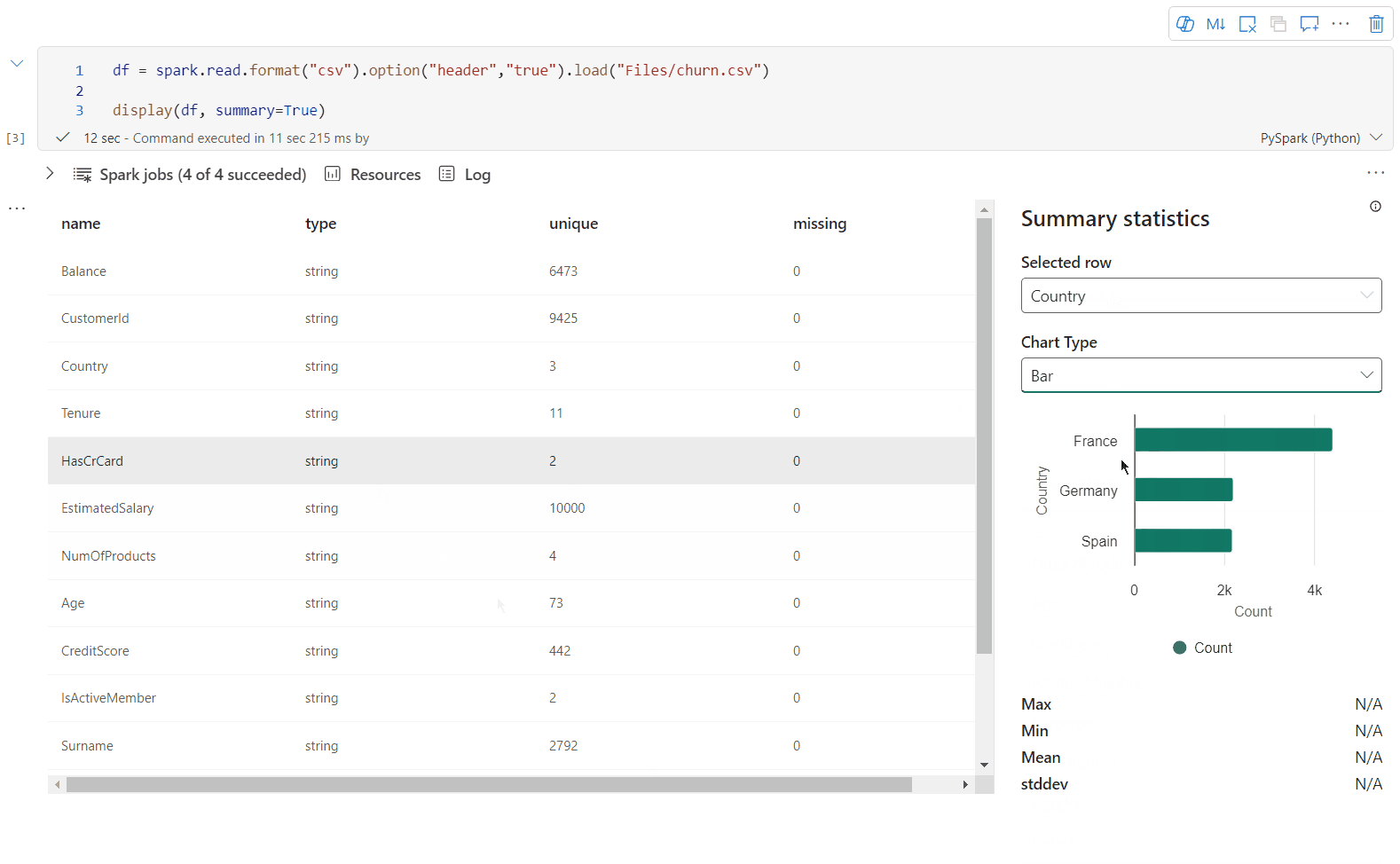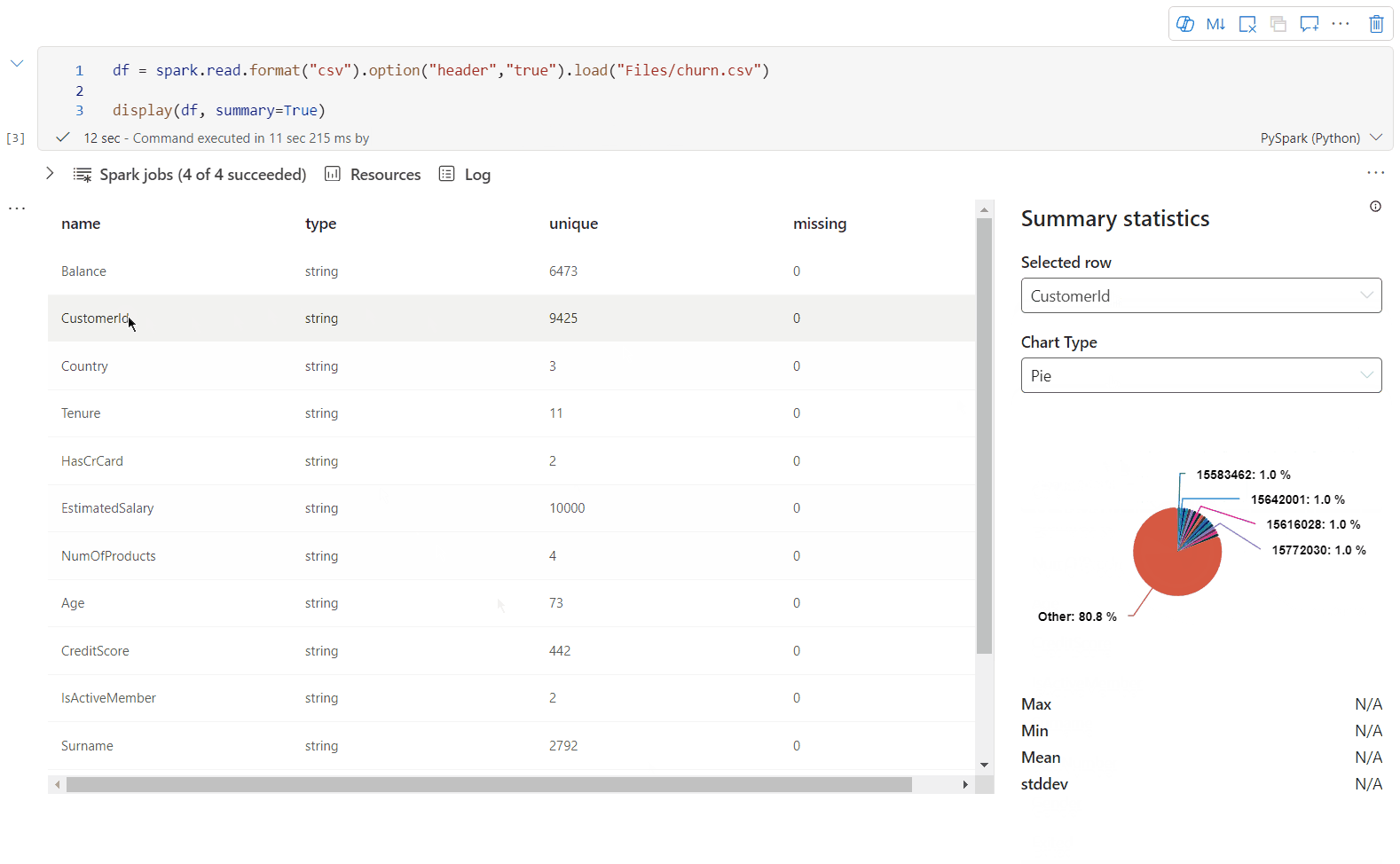
Usare display(df, summary = true) per controllare il riepilogo delle statistiche di un determianto DataFrame Apache Spark. Il riepilogo include il nome della colonna, il tipo di colonna, i valori univoci e i valori mancanti per ogni colonna. È anche possibile selezionare una colonna specifica per visualizzare il relativo valore minimo, massimo e medio, e la deviazione standard.
opzione displayHTML()
I notebook Fabric supportano la grafica HTML usando la funzione displayHTML.
L'immagine seguente è un esempio di creazione di visualizzazioni usando D3.js.

Per creare questa visualizzazione, usare il codice seguente.
displayHTML("""<!DOCTYPE html>
<meta charset="utf-8">
<!-- Load d3.js -->
<script src="https://d3js.org/d3.v4.js"></script>
<!-- Create a div where the graph will take place -->
<div id="my_dataviz"></div>
<script>
// set the dimensions and margins of the graph
var margin = {top: 10, right: 30, bottom: 30, left: 40},
width = 400 - margin.left - margin.right,
height = 400 - margin.top - margin.bottom;
// append the svg object to the body of the page
var svg = d3.select("#my_dataviz")
.append("svg")
.attr("width", width + margin.left + margin.right)
.attr("height", height + margin.top + margin.bottom)
.append("g")
.attr("transform",
"translate(" + margin.left + "," + margin.top + ")");
// Create Data
var data = [12,19,11,13,12,22,13,4,15,16,18,19,20,12,11,9]
// Compute summary statistics used for the box:
var data_sorted = data.sort(d3.ascending)
var q1 = d3.quantile(data_sorted, .25)
var median = d3.quantile(data_sorted, .5)
var q3 = d3.quantile(data_sorted, .75)
var interQuantileRange = q3 - q1
var min = q1 - 1.5 * interQuantileRange
var max = q1 + 1.5 * interQuantileRange
// Show the Y scale
var y = d3.scaleLinear()
.domain([0,24])
.range([height, 0]);
svg.call(d3.axisLeft(y))
// a few features for the box
var center = 200
var width = 100
// Show the main vertical line
svg
.append("line")
.attr("x1", center)
.attr("x2", center)
.attr("y1", y(min) )
.attr("y2", y(max) )
.attr("stroke", "black")
// Show the box
svg
.append("rect")
.attr("x", center - width/2)
.attr("y", y(q3) )
.attr("height", (y(q1)-y(q3)) )
.attr("width", width )
.attr("stroke", "black")
.style("fill", "#69b3a2")
// show median, min and max horizontal lines
svg
.selectAll("toto")
.data([min, median, max])
.enter()
.append("line")
.attr("x1", center-width/2)
.attr("x2", center+width/2)
.attr("y1", function(d){ return(y(d))} )
.attr("y2", function(d){ return(y(d))} )
.attr("stroke", "black")
</script>
"""
)
Incorporare un report di Power BI in un notebook
Importante
La funzionalità è attualmente disponibile in ANTEPRIMA. Queste informazioni si riferiscono a un prodotto in versione preliminare che potrebbe essere modificato in modo sostanziale prima che abbia raggiunto la disponibilità generale. Microsoft non fornisce alcuna garanzia, esplicita o implicita, in relazione alle informazioni contenute in questo documento.
Il pacchetto Python Powerbiclient ora è supportato in modo nativo nei notebook Fabric. Non è necessario eseguire alcuna configurazione aggiuntiva (ad esempio il processo di autenticazione) nel runtime Spark 3.4 del notebook Fabric. Basta importare powerbiclient e quindi continuare l'esplorazione. Per altre informazioni su come usare il pacchetto powerbiclient, vedere la documentazione di powerbiclient.
Powerbiclient supporta le funzionalità chiave seguenti.
Eseguire il rendering di un report di Power BI esistente
È possibile incorporare e interagire facilmente con i report di Power BI nei notebook con poche righe di codice.
L'immagine seguente è un esempio di rendering di un report di Power BI esistente.

Usare il codice seguente per eseguire il rendering di un report di Power BI esistente.
from powerbiclient import Report
report_id="Your report id"
report = Report(group_id=None, report_id=report_id)
report
Creare oggetti visivi del report da un DataFrame Spark
È possibile usare un DataFrame Spark nel notebook per generare rapidamente visualizzazioni dettagliate. È anche possibile selezionare Salva nel report incorporato per creare un elemento del report in un'area di lavoro di destinazione.
L'immagine seguente è un esempio di QuickVisualize() da un DataFrame Spark.

Usare il codice seguente per eseguire il rendering di un report da un DataFrame Spark.
# Create a spark dataframe from a Lakehouse parquet table
sdf = spark.sql("SELECT * FROM testlakehouse.table LIMIT 1000")
# Create a Power BI report object from spark data frame
from powerbiclient import QuickVisualize, get_dataset_config
PBI_visualize = QuickVisualize(get_dataset_config(sdf))
# Render new report
PBI_visualize
Creare oggetti visivi del report da un DataFrame Pandas
È anche possibile creare report basati su un DataFrame Pandas nel notebook.
L'immagine seguente è un esempio di QuickVisualize() da un DataFrame Pandas.

Usare il codice seguente per eseguire il rendering di un report da un DataFrame Spark.
import pandas as pd
# Create a pandas dataframe from a URL
df = pd.read_csv("https://raw.githubusercontent.com/plotly/datasets/master/fips-unemp-16.csv")
# Create a pandas dataframe from a Lakehouse csv file
from powerbiclient import QuickVisualize, get_dataset_config
# Create a Power BI report object from your data
PBI_visualize = QuickVisualize(get_dataset_config(df))
# Render new report
PBI_visualize
Librerie più diffuse
Quando si tratta di visualizzazione dei dati, Python offre più librerie di grafi dotate di molte funzionalità diverse. Per impostazione predefinita, ogni pool di Apache Spark in Fabric contiene un set di librerie open source curate e diffuse.
Matplotlib
È possibile eseguire il rendering delle librerie di tracciatura standard, ad esempio Matplotlib, usando le funzioni di rendering predefinite per ogni libreria.
L'immagine seguente è un esempio di creazione di un grafico a barre con Matplotlib.


Usare il codice di esempio seguente per disegnare questo grafico a barre.
# Bar chart
import matplotlib.pyplot as plt
x1 = [1, 3, 4, 5, 6, 7, 9]
y1 = [4, 7, 2, 4, 7, 8, 3]
x2 = [2, 4, 6, 8, 10]
y2 = [5, 6, 2, 6, 2]
plt.bar(x1, y1, label="Blue Bar", color='b')
plt.bar(x2, y2, label="Green Bar", color='g')
plt.plot()
plt.xlabel("bar number")
plt.ylabel("bar height")
plt.title("Bar Chart Example")
plt.legend()
plt.show()
Bokeh
È possibile eseguire il rendering di librerie HTML o interattive, ad esempio bokeh, usando displayHTML().
L'immagine seguente è un esempio di glifi tracciati su una mappa che usa bokeh.

Per disegnare questa immagine, usare il codice di esempio seguente.
from bokeh.plotting import figure, output_file
from bokeh.tile_providers import get_provider, Vendors
from bokeh.embed import file_html
from bokeh.resources import CDN
from bokeh.models import ColumnDataSource
tile_provider = get_provider(Vendors.CARTODBPOSITRON)
# range bounds supplied in web mercator coordinates
p = figure(x_range=(-9000000,-8000000), y_range=(4000000,5000000),
x_axis_type="mercator", y_axis_type="mercator")
p.add_tile(tile_provider)
# plot datapoints on the map
source = ColumnDataSource(
data=dict(x=[ -8800000, -8500000 , -8800000],
y=[4200000, 4500000, 4900000])
)
p.circle(x="x", y="y", size=15, fill_color="blue", fill_alpha=0.8, source=source)
# create an html document that embeds the Bokeh plot
html = file_html(p, CDN, "my plot1")
# display this html
displayHTML(html)
Plotly
È possibile eseguire il rendering di librerie HTML o interattive, ad esempio Plotly, usando displayHTML().
Per disegnare questa immagine, usare il codice di esempio seguente.

from urllib.request import urlopen
import json
with urlopen('https://raw.githubusercontent.com/plotly/datasets/master/geojson-counties-fips.json') as response:
counties = json.load(response)
import pandas as pd
df = pd.read_csv("https://raw.githubusercontent.com/plotly/datasets/master/fips-unemp-16.csv",
dtype={"fips": str})
import plotly
import plotly.express as px
fig = px.choropleth(df, geojson=counties, locations='fips', color='unemp',
color_continuous_scale="Viridis",
range_color=(0, 12),
scope="usa",
labels={'unemp':'unemployment rate'}
)
fig.update_layout(margin={"r":0,"t":0,"l":0,"b":0})
# create an html document that embeds the Plotly plot
h = plotly.offline.plot(fig, output_type='div')
# display this html
displayHTML(h)
Pandas
È possibile visualizzare l'output HTML dei DataFrame Pandas come output predefinito. I notebook Fabric mostrano automaticamente il contenuto HTML con uno stile.

import pandas as pd
import numpy as np
df = pd.DataFrame([[38.0, 2.0, 18.0, 22.0, 21, np.nan],[19, 439, 6, 452, 226,232]],
index=pd.Index(['Tumour (Positive)', 'Non-Tumour (Negative)'], name='Actual Label:'),
columns=pd.MultiIndex.from_product([['Decision Tree', 'Regression', 'Random'],['Tumour', 'Non-Tumour']], names=['Model:', 'Predicted:']))
df