Usare la funzionalità di manutenzione delle tabelle per gestire tabelle Delta in Fabric
Lakehouse in Microsoft Fabric offre la funzionalità Manutenzione tabelle per gestire in modo efficiente le tabelle Delta e mantenerle sempre pronte per l'analisi. Questa guida descrive la funzionalità di manutenzione tabelle in Lakehouse e le relative funzionalità.
Capacità principali della funzionalità di manutenzione delle tabelle lakehouse:
- Eseguire la manutenzione delle tabelle ad hoc usando azioni contestuali di clic con il pulsante destro del mouse in una tabella Delta all'interno di Esplora lakehouse.
- Applicare bin-compaction, VOrder e pulizia dei vecchi file senza riferimenti.
Nota
Per le attività di manutenzione avanzate, ad esempio il raggruppamento di più comandi di manutenzione tabelle, l'orchestrazione in base a una pianificazione, la scelta consigliata è un approccio incentrato sul codice. Per altre informazioni, vedere l’articolo Ottimizzazione delle tabelle Delta Lake e V-Order. È anche possibile usare l'API Lakehouse per automatizzare le operazioni di manutenzione delle tabelle; per altre informazioni, vedere Gestire il lakehouse con l'API REST di Microsoft Fabric.
Tipi di file supportati
La manutenzione delle tabelle lakehouse si applica solo alle tabelle Delta Lake. Le tabelle Hive legacy che usano PARQUET, ORC, AVRO, CSV e altri formati non sono supportate.
Operazioni di manutenzione delle tabelle
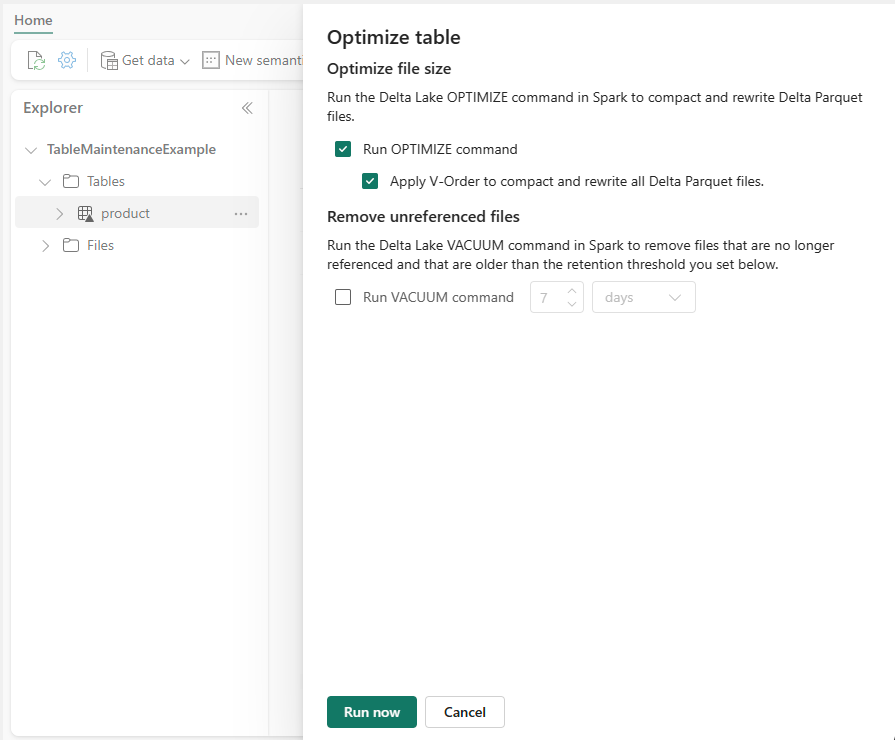
La funzionalità di manutenzione delle tabelle offre tre operazioni.
- Ottimizzazione: consolida più file Parquet di piccole dimensioni in file di grandi dimensioni. I motori di elaborazione di Big Data e tutti i motori di Fabric traggono vantaggio dalla presenza di file di dimensioni maggiori. Avere file di dimensioni superiori a 128 MB e, in modo ottimale, prossime a 1 GB migliora la compressione e la distribuzione dei dati nei nodi del cluster. Riduce la necessità di analizzare numerosi file di piccole dimensioni per operazioni di lettura efficienti. Come procedura consigliata generale, eseguire strategie di ottimizzazione dopo il caricamento di tabelle di grandi dimensioni.
- V-Order: applica l'ordinamento, la codifica e la compressione ottimizzati ai file Parquet Delta per abilitare operazioni di lettura veloci in tutti i motori di Fabric. V-Order viene eseguito durante il comando di ottimizzazione e viene presentato come opzione al gruppo di comandi nell'esperienza utente. Per altre informazioni su V-Order, vedere Ottimizzazione delle tabelle Delta Lake e V-Order.
- Vacuum: rimuove i vecchi file a cui non fa riferimento un log di tabella Delta. I file devono essere più vecchi della soglia di conservazione e la soglia di conservazione predefinita dei file è di sette giorni. Tutte le tabelle Delta in OneLake hanno lo stesso periodo di conservazione. Il periodo di conservazione dei file è lo stesso, indipendentemente dal motore di calcolo di Fabric in uso. Questa manutenzione è importante per ottimizzare i costi di archiviazione. L'impostazione di un periodo di conservazione più breve influisce sulle capacit del tempo per spostamento fisico Delta. Come procedura consigliata generale, impostare un intervallo di conservazione su almeno 7 giorni, perché i vecchi snapshot e i file non sottoposti a commit possono comunque essere usati da lettori o writer di tabelle simultanei. La pulizia dei file attivi con il comando VACUUM può causare errori di lettura o persino danneggiare la tabella se vengono rimossi i file non sottoposti a commit.
Eseguire la manutenzione delle tabelle ad hoc in una tabella Delta usando Lakehouse
Quando usare la funzionalità:
Dall'account di Microsoft ,Fabric passare al lakehouse desiderato.
Nella sezione Tabelle di Esplora lakehouse, fare clic con il pulsante destro del mouse sulla tabella oppure usare i puntini di sospensione per accedere al menu contestuale.
Selezionare la voce del menu Manutenzione.
Controllare le opzioni di manutenzione nella finestra di dialogo in base ai propri requisiti. Per ulteriori informazioni, vedere la sezione Operazioni di manutenzione delle tabelle in questo articolo.
Selezionare Esegui ora per eseguire il processo di manutenzione delle tabelle.
Tenere traccia dell'esecuzione del processo di manutenzione tramite il riquadro delle notifiche o dall'hub di monitoraggio.

Come funziona la manutenzione delle tabelle?
Dopo aver selezionato Esegui ora, viene inviato un processo di manutenzione Spark per l'esecuzione.
- Il processo Spark viene inviato usando l'identità utente e i privilegi tabella.
- Il processo Spark usa capacità di Fabric dell'area di lavoro/utente che ha inviato il processo.
- Se in una tabella è in esecuzione un altro processo di manutenzione, un nuovo processo viene rifiutato.
- I processi in tabelle diverse possono essere eseguiti in parallelo.
- I processi di manutenzione delle tabelle possono essere facilmente tracciati nell'hub di monitoraggio. Cercare il testo "TableMaintenance" all'interno della colonna del nome dell'attività nella pagina principale dell'hub di monitoraggio.