Usare l'API Livy per inviare ed eseguire processi batch Livy
Nota
L'API Livy per fabric Ingegneria dei dati è in anteprima.
Si applica a:✅ ingegneria dei dati e data science in Microsoft Fabric
Inviare processi batch Spark usando l'API Livy per fabric Ingegneria dei dati.
Prerequisiti
Infrastruttura Premium o Capacità di valutazione con lakehouse.
Un client remoto, ad esempio Visual Studio Code con Jupyter Notebooks, PySpark e Microsoft Authentication Library (MSAL) per Python.
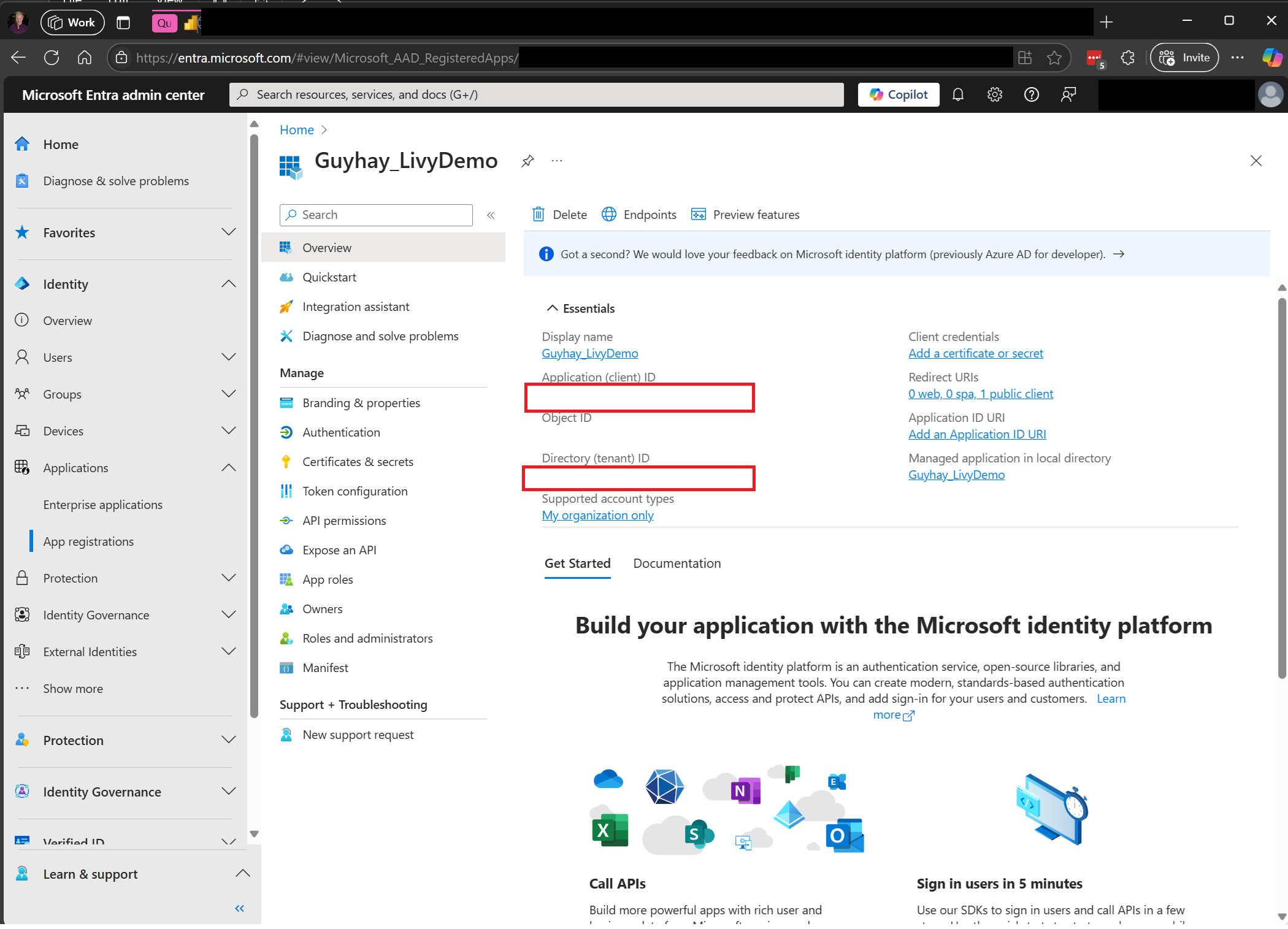
Per accedere all'API REST di Fabric è necessario un token dell'app Microsoft Entra. Registrare un'applicazione con Microsoft Identity Platform.
Alcuni dati nel lakehouse, questo esempio usa NYC Taxi & Limousine Commission green_tripdata_2022_08 un file parquet caricato nella lakehouse.
L'API Livy definisce un endpoint unificato per le operazioni. Sostituire i segnaposto {Entra_TenantID}, {Entra_ClientID}, {Fabric_WorkspaceID}e {Fabric_LakehouseID} con i valori appropriati quando si seguono gli esempi in questo articolo.
Configurare Visual Studio Code per l'API Livy Batch
Selezionare Lakehouse Settings (Impostazioni lakehouse) in Fabric Lakehouse.

Passare alla sezione Endpoint Livy.

Copiare il processo batch stringa di connessione (seconda casella rossa nell'immagine) nel codice.
Passare all'interfaccia di amministrazione di Microsoft Entra e copiare sia l'ID applicazione (client) che l'ID directory (tenant) nel codice.



Creare un payload Spark e caricarlo in Lakehouse
Creare un
.ipynbnotebook in Visual Studio Code e inserire il codice seguenteimport sys import os from pyspark.sql import SparkSession from pyspark.conf import SparkConf from pyspark.sql.functions import col if __name__ == "__main__": #Spark session builder spark_session = (SparkSession .builder .appName("livybatchdemo") .getOrCreate()) spark_context = spark_session.sparkContext spark_context.setLogLevel("DEBUG") targetLakehouse = spark_context.getConf().get("spark.targetLakehouse") if targetLakehouse is not None: print("targetLakehouse: " + str(targetLakehouse)) else: print("targetLakehouse is None") df_valid_totalPrice = spark_session.sql("SELECT * FROM <YourLakeHouseDataTableName>.transactions where TotalPrice > 0") df_valid_totalPrice_plus_year = df_valid_totalPrice.withColumn("transaction_year", col("TransactionDate").substr(1, 4)) deltaTablePath = "abfss:<YourABFSSpath>"+str(targetLakehouse)+".Lakehouse/Tables/CleanedTransactions" df_valid_totalPrice_plus_year.write.mode('overwrite').format('delta').save(deltaTablePath)Salvare il file Python in locale. Questo payload di codice Python contiene due istruzioni Spark che funzionano sui dati in un Lakehouse e devono essere caricate in Lakehouse. È necessario il percorso ABFS del payload a cui fare riferimento nel processo batch dell'API Livy in Visual Studio Code e il nome della tabella Lakehouse nell'istruzione Select SQL.

Caricare il payload Python nella sezione dei file di Lakehouse. >Recupera i file di caricamento > dei dati > fare clic nella casella File/input.
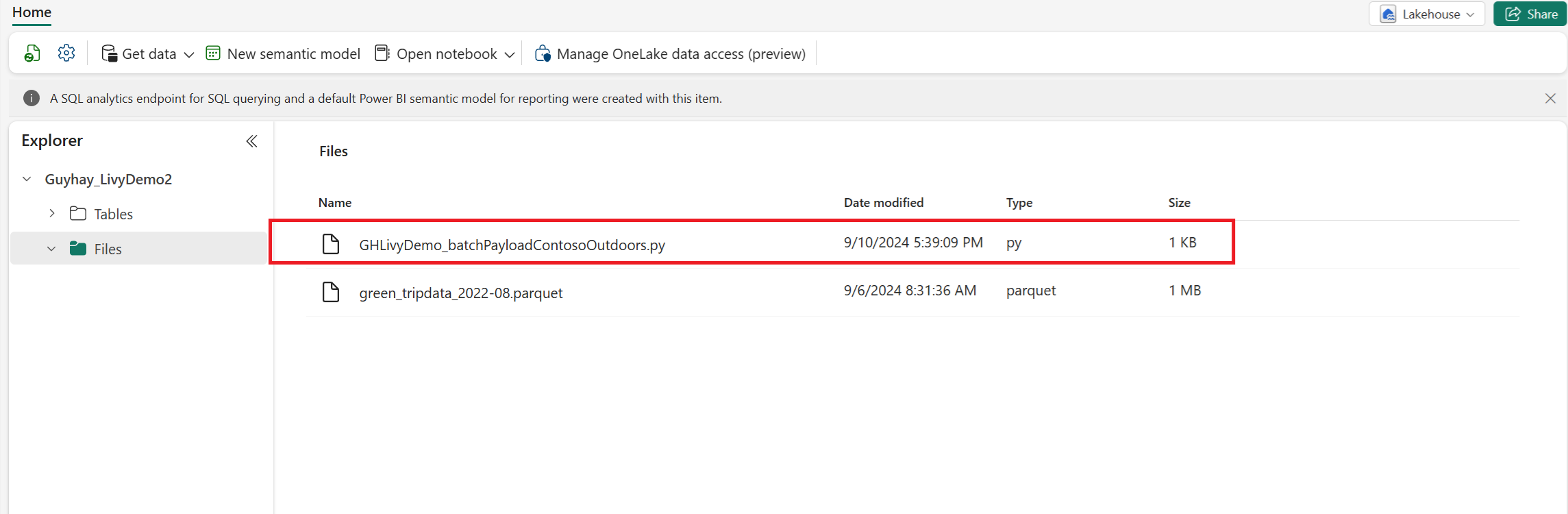
Dopo che il file si trova nella sezione File di Lakehouse, fare clic sui tre puntini a destra del nome file del payload e selezionare Proprietà.
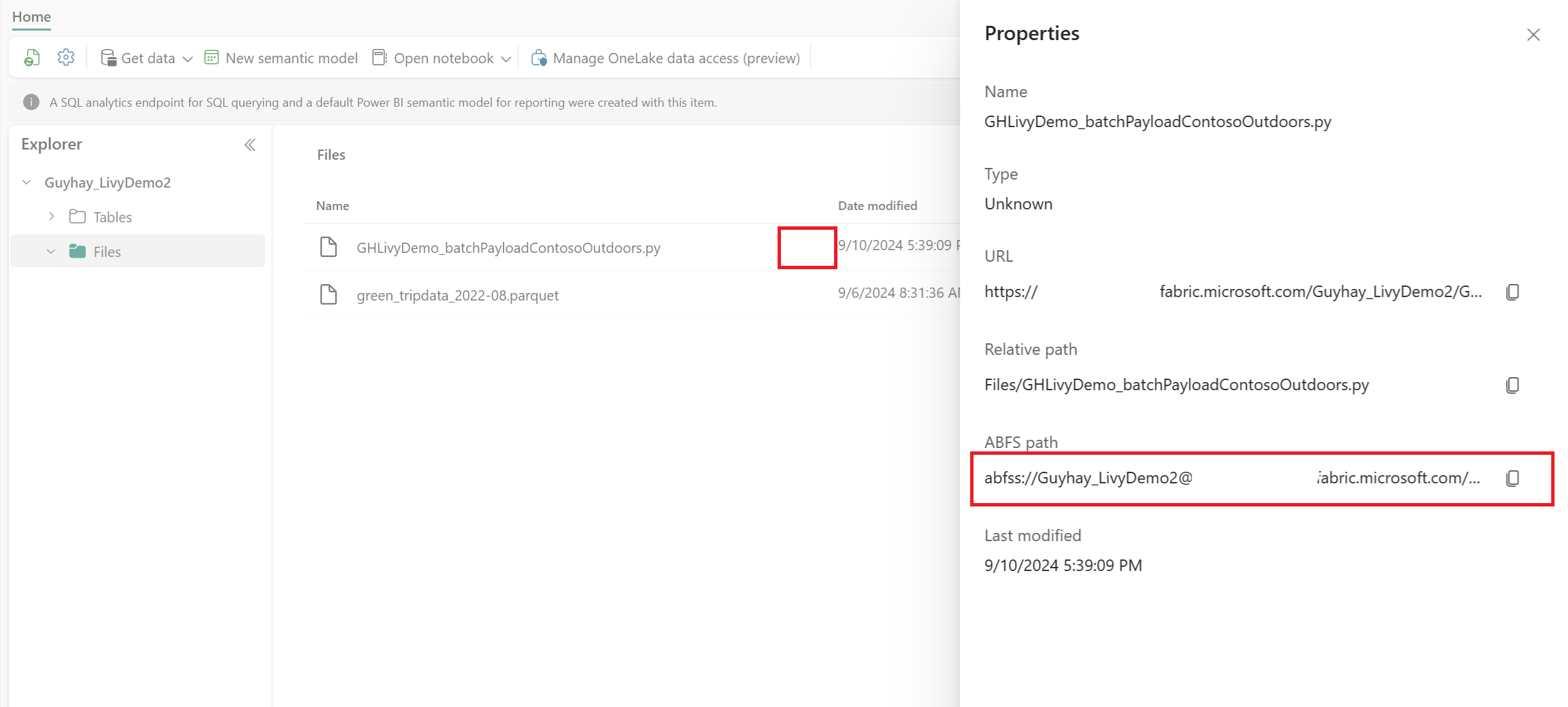
Copiare questo percorso ABFS nella cella Notebook nel passaggio 1.



Creare una sessione batch di Spark per l'API Livy
Creare un
.ipynbnotebook in Visual Studio Code e inserire il codice seguente.from msal import PublicClientApplication import requests import time tenant_id = "<Entra_TenantID>" client_id = "<Entra_ClientID>" workspace_id = "<Fabric_WorkspaceID>" lakehouse_id = "<Fabric_LakehouseID>" app = PublicClientApplication( client_id, authority="https://login.microsoftonline.com/43a26159-4e8e-442a-9f9c-cb7a13481d48" ) result = None # If no cached tokens or user interaction needed, acquire tokens interactively if not result: result = app.acquire_token_interactive(scopes=["https://api.fabric.microsoft.com/Lakehouse.Execute.All", "https://api.fabric.microsoft.com/Lakehouse.Read.All", "https://api.fabric.microsoft.com/Item.ReadWrite.All", "https://api.fabric.microsoft.com/Workspace.ReadWrite.All", "https://api.fabric.microsoft.com/Code.AccessStorage.All", "https://api.fabric.microsoft.com/Code.AccessAzureKeyvault.All", "https://api.fabric.microsoft.com/Code.AccessAzureDataExplorer.All", "https://api.fabric.microsoft.com/Code.AccessAzureDataLake.All", "https://api.fabric.microsoft.com/Code.AccessFabric.All"]) # Print the access token (you can use it to call APIs) if "access_token" in result: print(f"Access token: {result['access_token']}") else: print("Authentication failed or no access token obtained.") if "access_token" in result: access_token = result['access_token'] api_base_url_mist='https://api.fabric.microsoft.com/v1' livy_base_url = api_base_url_mist + "/workspaces/"+workspace_id+"/lakehouses/"+lakehouse_id +"/livyApi/versions/2023-12-01/batches" headers = {"Authorization": "Bearer " + access_token}Eseguire la cella del notebook, nel browser dovrebbe essere visualizzata una finestra popup che consente di scegliere l'identità con cui eseguire l'accesso.
Dopo aver scelto l'identità con cui eseguire l'accesso, verrà chiesto anche di approvare le autorizzazioni dell'API di registrazione dell'app Microsoft Entra.
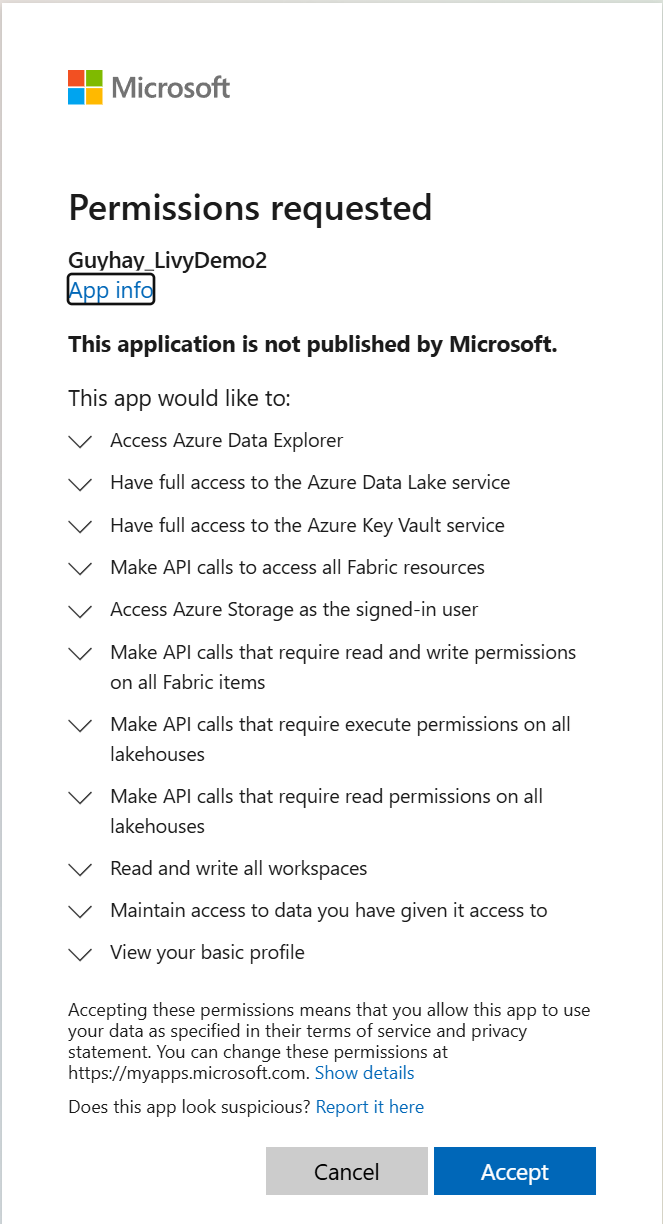
Chiudere la finestra del browser dopo aver completato l'autenticazione.

In Visual Studio Code dovrebbe essere visualizzato il token Microsoft Entra restituito.
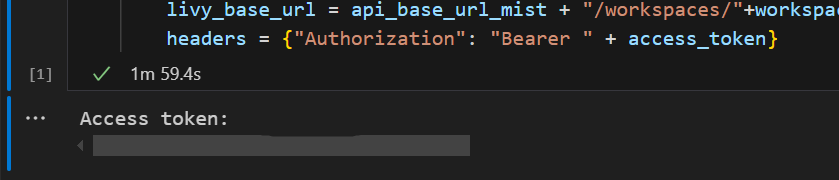
Aggiungere un'altra cella del notebook e inserire questo codice.
# call get batch API get_livy_get_batch = livy_base_url get_batch_response = requests.get(get_livy_get_batch, headers=headers) if get_batch_response.status_code == 200: print("API call successful") print(get_batch_response.json()) else: print(f"API call failed with status code: {get_batch_response.status_code}") print(get_batch_response.text)Eseguire la cella del notebook. Verranno visualizzate due righe stampate quando viene creato il processo batch Livy.
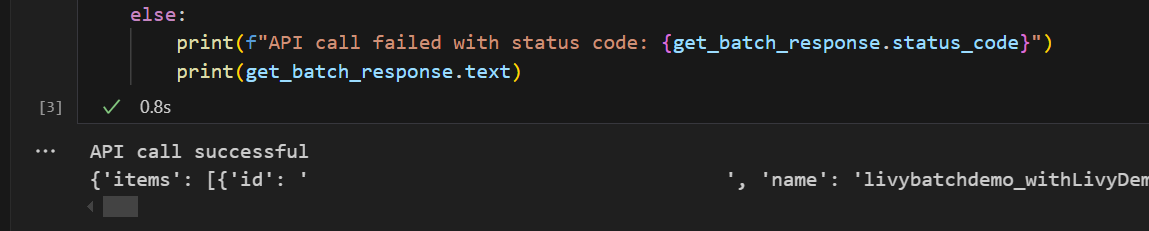





Inviare un'istruzione spark.sql usando la sessione batch dell'API Livy
Aggiungere un'altra cella del notebook e inserire questo codice.
# submit payload to existing batch session print('Submit a spark job via the livy batch API to ') newlakehouseName = "YourNewLakehouseName" create_lakehouse = api_base_url_mist + "/workspaces/" + workspace_id + "/items" create_lakehouse_payload = { "displayName": newlakehouseName, "type": 'Lakehouse' } create_lakehouse_response = requests.post(create_lakehouse, headers=headers, json=create_lakehouse_payload) print(create_lakehouse_response.json()) payload_data = { "name":"livybatchdemo_with"+ newlakehouseName, "file":"abfss://YourABFSPathToYourPayload.py", "conf": { "spark.targetLakehouse": "Fabric_LakehouseID" } } get_batch_response = requests.post(get_livy_get_batch, headers=headers, json=payload_data) print("The Livy batch job submitted successful") print(get_batch_response.json())Eseguire la cella del notebook. Verranno visualizzate diverse righe stampate durante la creazione e l'esecuzione del processo Livy Batch.

Tornare a Lakehouse per visualizzare le modifiche.

Visualizzare i processi nell'hub di monitoraggio
È possibile accedere all'hub di monitoraggio per visualizzare varie attività di Apache Spark selezionando Monitoraggio nei collegamenti di spostamento a sinistra.
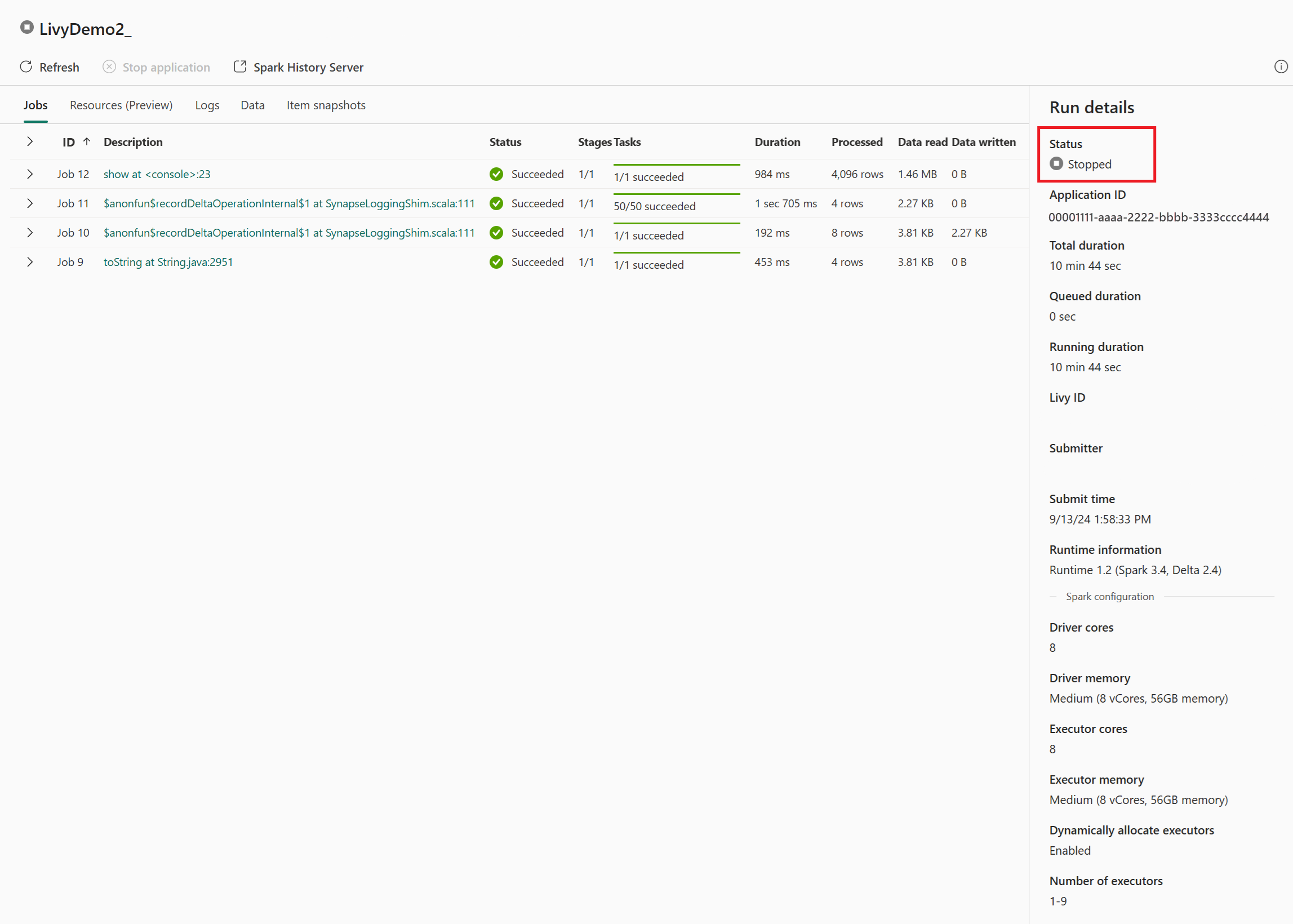
Quando lo stato del processo batch è completato, è possibile visualizzare lo stato della sessione passando a Monitoraggio.

Selezionare e aprire il nome dell'attività più recente.
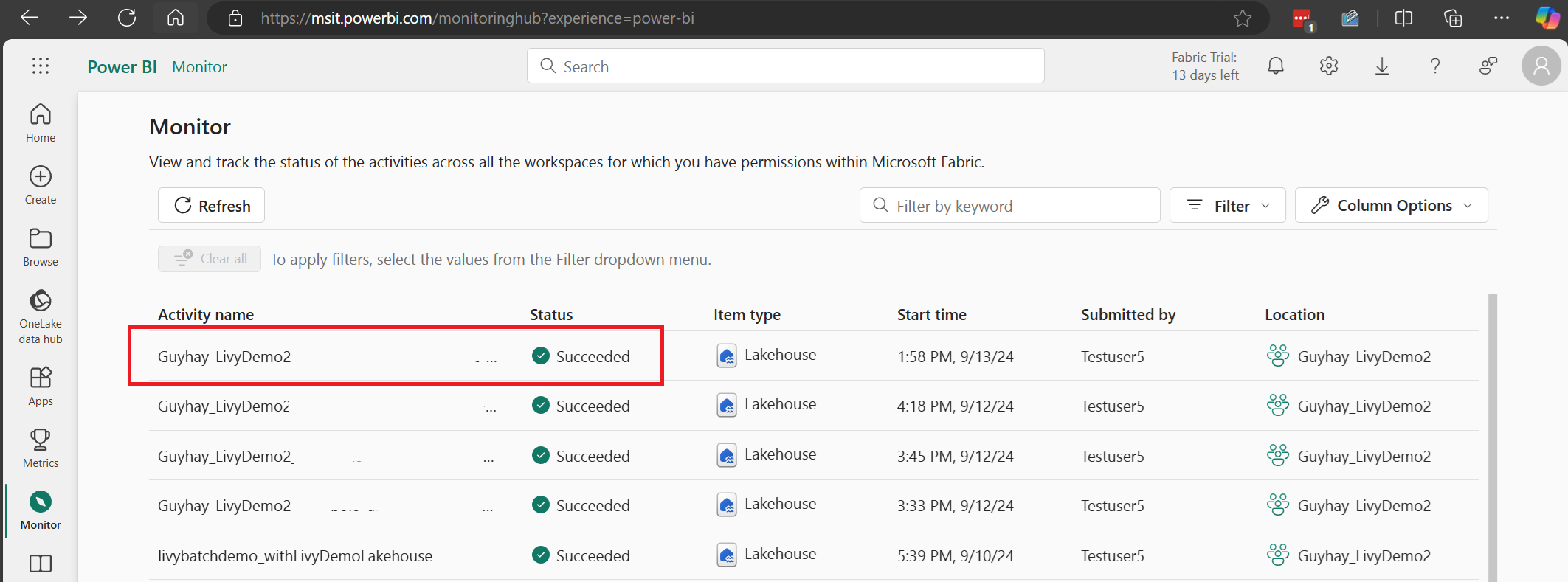
In questo caso di sessione dell'API Livy è possibile visualizzare l'invio in batch precedente, i dettagli dell'esecuzione, le versioni di Spark e la configurazione. Si noti lo stato arrestato in alto a destra.



Per riepilogare l'intero processo, è necessario un client remoto, ad esempio Visual Studio Code, un token dell'app Microsoft Entra, l'URL dell'endpoint dell'API Livy, l'autenticazione in Lakehouse, un payload Spark nella lakehouse e infine una sessione dell'API Livy batch.