Supporto T-SQL nei notebook di Microsoft Fabric
La funzionalità notebook T-SQL in Microsoft Fabric consente di scrivere ed eseguire codice T-SQL all'interno di un notebook. È possibile usare i notebook T-SQL per gestire query complesse e scrivere una documentazione markdown migliore. Consente anche l'esecuzione diretta di T-SQL nel warehouse connesso o nell'endpoint di analisi SQL. Aggiungendo un endpoint di analisi SQL o data warehouse a un notebook, gli sviluppatori T-SQL possono eseguire query direttamente nell'endpoint connesso. Gli analisti bi possono anche eseguire query tra database per raccogliere informazioni dettagliate da più warehouse ed endpoint di analisi SQL.
La maggior parte delle funzionalità dei notebook esistenti è disponibile per i notebook T-SQL. Tra cui la creazione di grafici dei risultati delle query, la creazione condivisa di notebook, la pianificazione di esecuzioni regolari e l'attivazione dell'esecuzione all'interno di Integrazione dei dati pipeline.
Importante
Questa funzionalità si trova in anteprima.
In questo articolo vengono illustrate le operazioni seguenti:
- Creare un notebook T-SQL
- Aggiungere un endpoint di analisi SQL o data warehouse a un notebook
- Creare ed eseguire codice T-SQL in un notebook
- Usare le funzionalità di creazione di grafici per rappresentare graficamente i risultati delle query
- Salvare la query come vista o tabella
- Eseguire query tra warehouse
- Ignorare l'esecuzione di codice non T-SQL
Creare un notebook T-SQL
Per iniziare a usare questa esperienza, è possibile creare un notebook T-SQL nei modi seguenti:
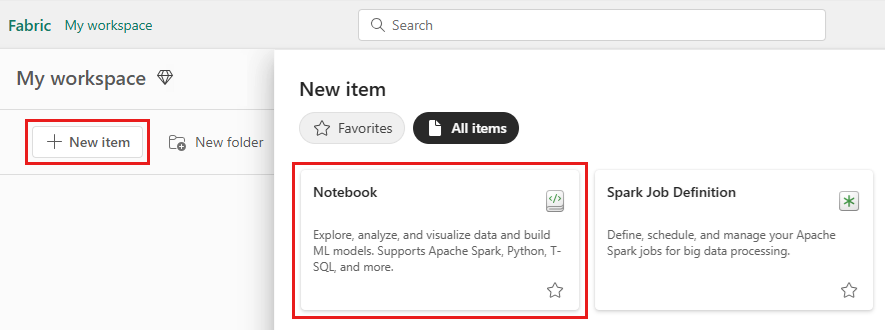
Creare un notebook T-SQL dall'area di lavoro Fabric: selezionare Nuovo elemento, quindi scegliere Notebook dal pannello che si apre.
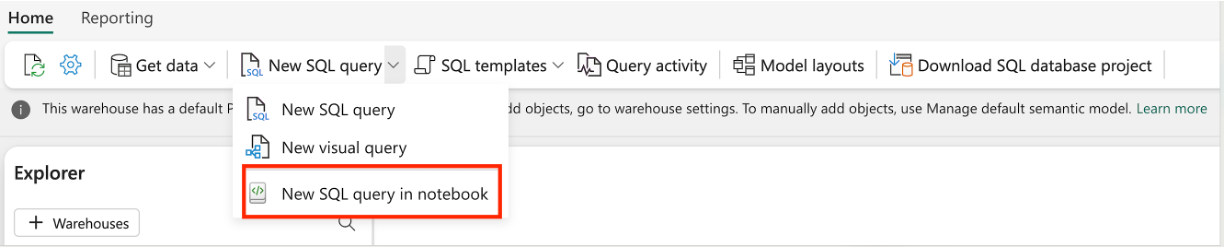
Creare un notebook T-SQL da un editor del magazzino esistente: passare a un magazzino esistente e, nella barra di navigazione superiore, selezionare Nuova query SQL, quindi Nuovo notebook di query T-SQL.
Dopo aver creato il notebook, T-SQL viene impostato come linguaggio predefinito. È possibile aggiungere endpoint di analisi SQL o data warehouse dall'area di lavoro corrente al notebook.
Aggiungere un endpoint di analisi SQL o data warehouse in un notebook
Per aggiungere un endpoint di analisi SQL o data warehouse in un notebook, dall'editor di notebook selezionare + Pulsante Origini dati e selezionare Warehouse. Nel pannello dell'hub dati selezionare l'endpoint di analisi SQL o data warehouse a cui connettersi.

Impostare un magazzino primario
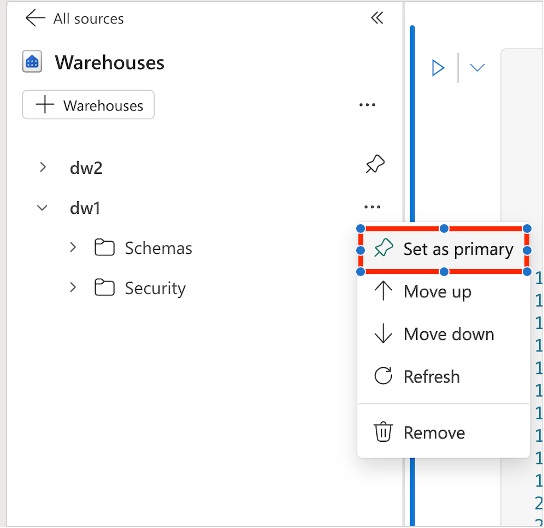
È possibile aggiungere più warehouse o endpoint di analisi SQL nel notebook, con uno di essi è impostato come primario. Il warehouse primario esegue il codice T-SQL. Per impostarlo, passare a Esplora oggetti, selezionare ... accanto al magazzino e scegliere Imposta come primario.
Per qualsiasi comando T-SQL che supporta la denominazione in tre parti, il warehouse primario viene usato come warehouse predefinito se non è specificato alcun warehouse.
Creare ed eseguire codice T-SQL in un notebook
Per creare ed eseguire codice T-SQL in un notebook, aggiungere una nuova cella e impostare T-SQL come linguaggio di cella.

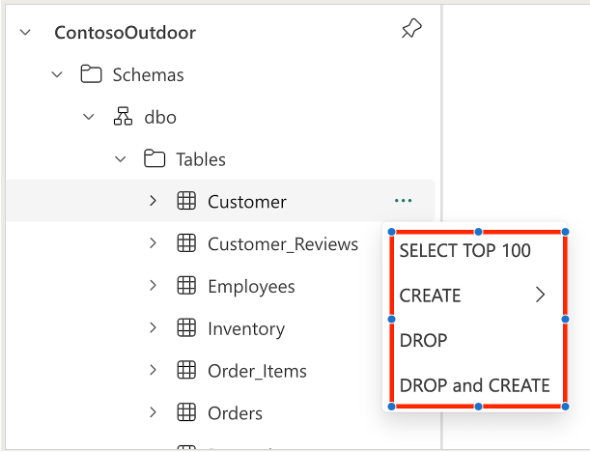
È possibile generare automaticamente il codice T-SQL usando il modello di codice dal menu di scelta rapida di Esplora oggetti. Per i notebook T-SQL sono disponibili i modelli seguenti:
- Selezione dei primi 100
- Crea tabella
- Crea come selezione
- Goccia
- Rilasciare e creare
È possibile eseguire una cella di codice T-SQL selezionando il pulsante Esegui sulla barra degli strumenti delle celle oppure eseguendo tutte le celle selezionando il pulsante Esegui tutto sulla barra degli strumenti.
Nota
Ogni cella di codice viene eseguita in una sessione separata, quindi le variabili definite in una cella non sono disponibili in un'altra cella.
All'interno della stessa cella di codice, potrebbe contenere più righe di codice. L'utente può selezionare parte di questo codice ed eseguire solo quelli selezionati. Ogni esecuzione genera anche una nuova sessione.
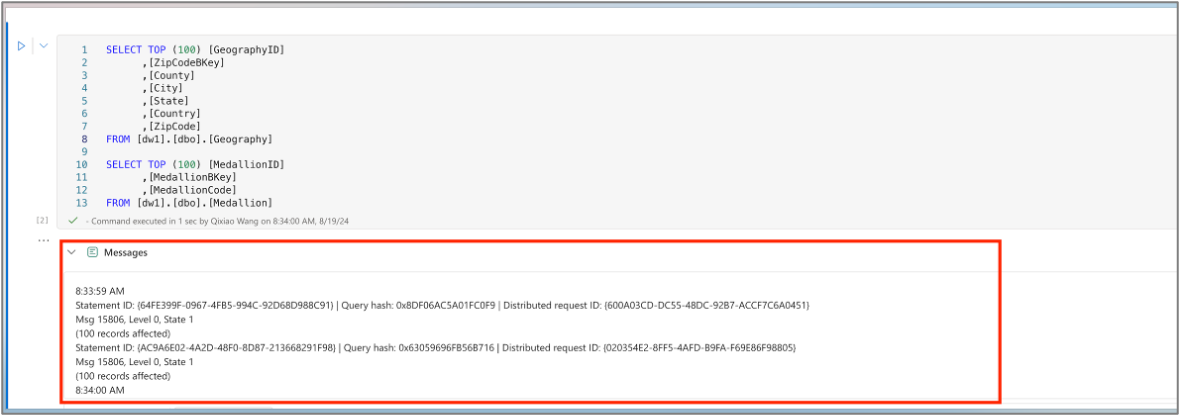
Dopo l'esecuzione del codice, espandere il pannello dei messaggi per controllare il riepilogo dell'esecuzione.
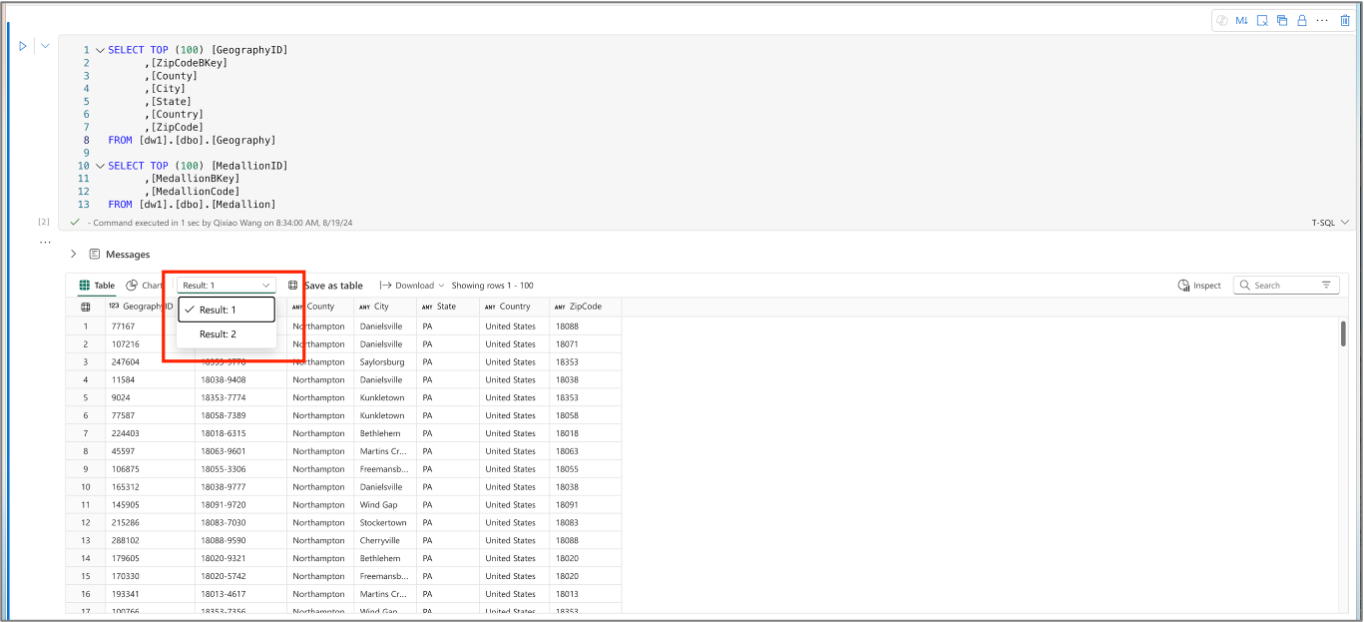
Nella scheda Tabella sono elencati i record del set di risultati restituito. Se l'esecuzione contiene più set di risultati, è possibile passare da una all'altra tramite il menu a discesa.
Usare le funzionalità di creazione di grafici per rappresentare graficamente i risultati delle query
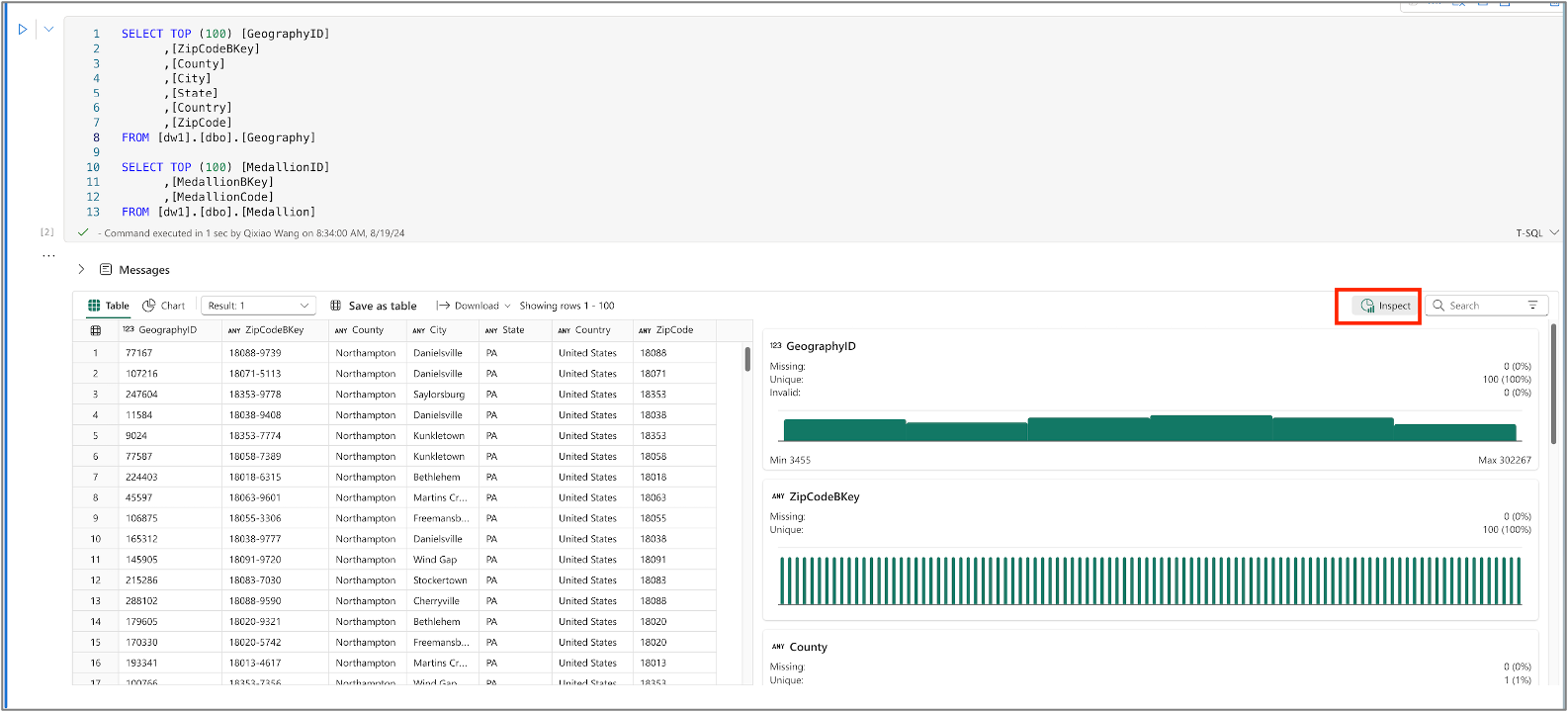
Facendo clic su Inspect è possibile visualizzare i grafici che rappresentano la qualità dei dati e la distribuzione di ogni colonna
Salvare la query come vista o tabella
È possibile usare il menu Salva come tabella per salvare i risultati della query nella tabella usando il comando CTAS . Per usare questo menu, selezionare il testo della query dalla cella di codice e selezionare Salva come tabella menu.
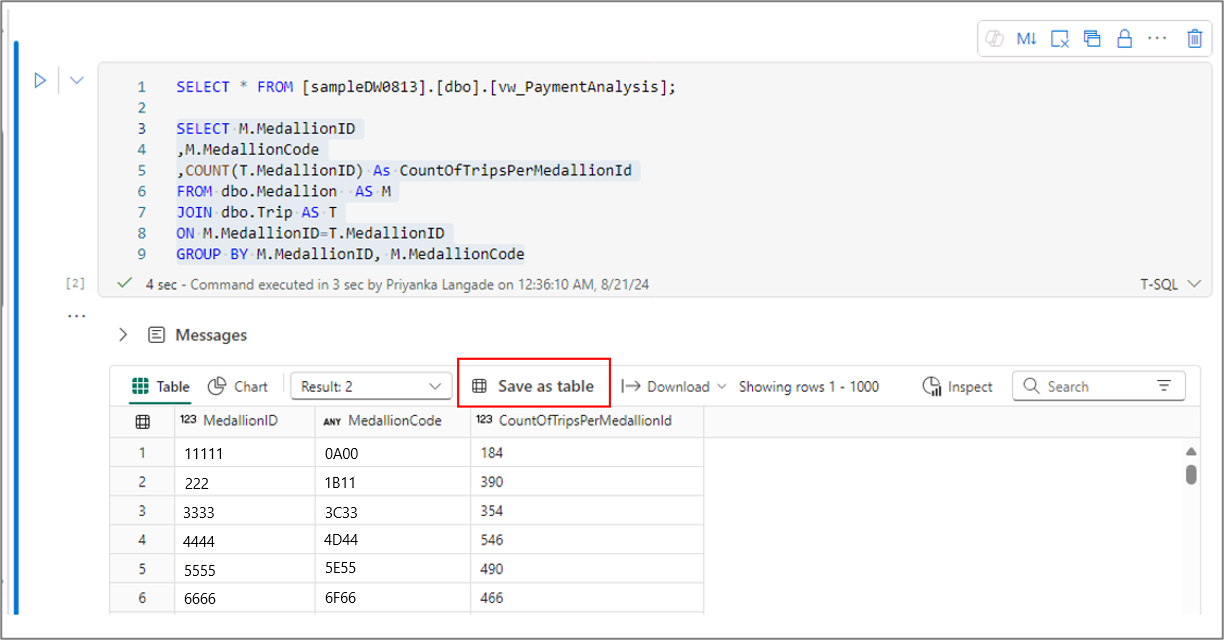
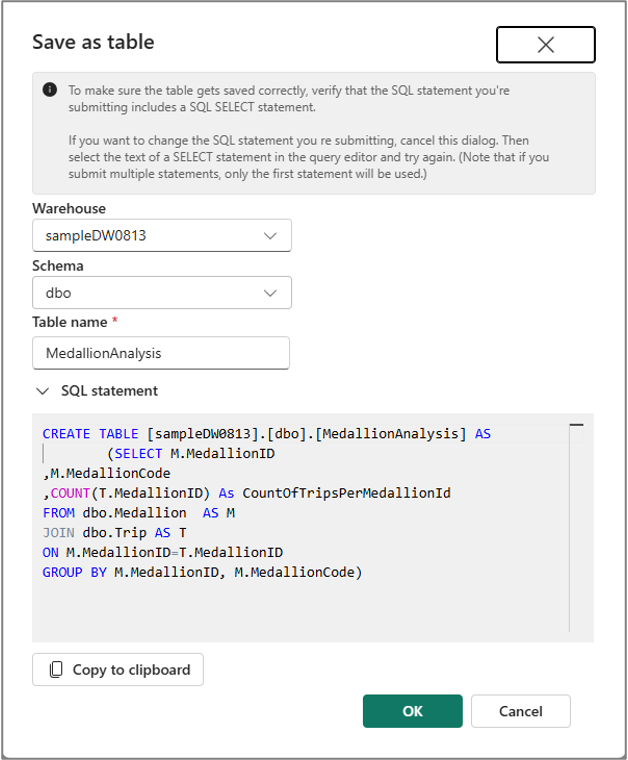
Analogamente, è possibile creare una vista dal testo della query selezionato usando il menu Salva come visualizzazione nella barra dei comandi della cella.
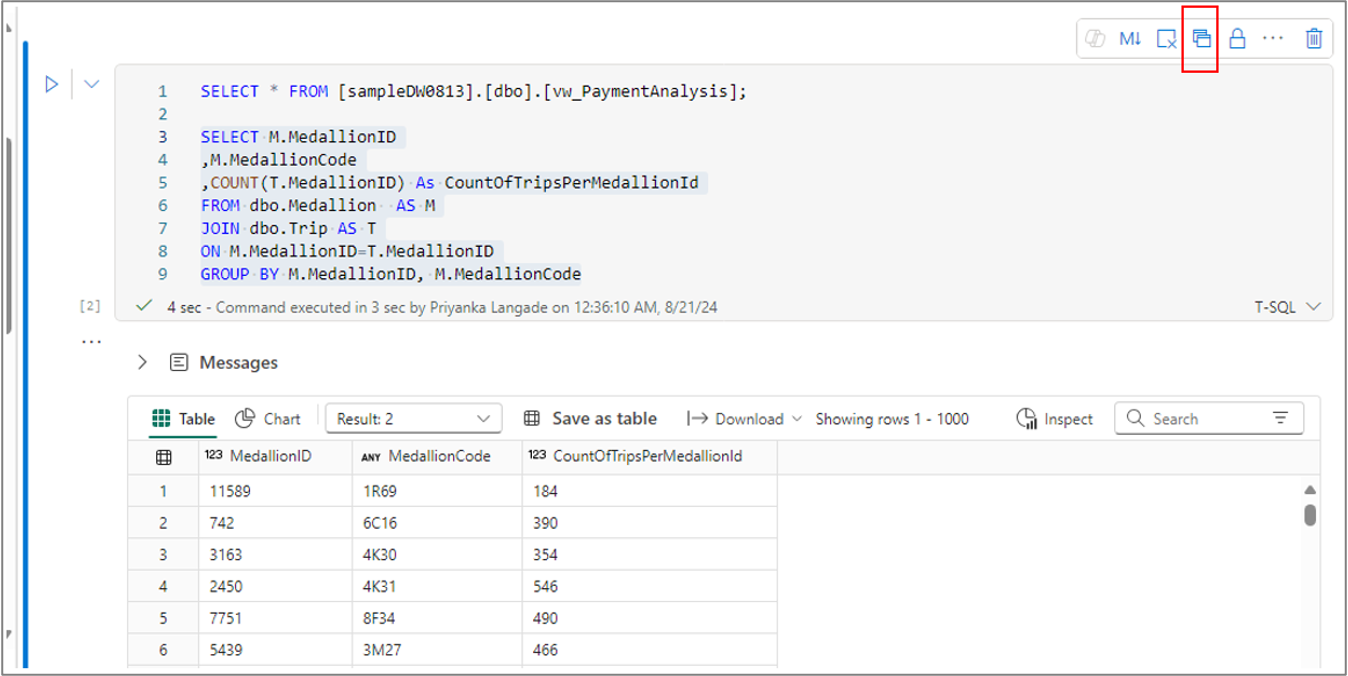
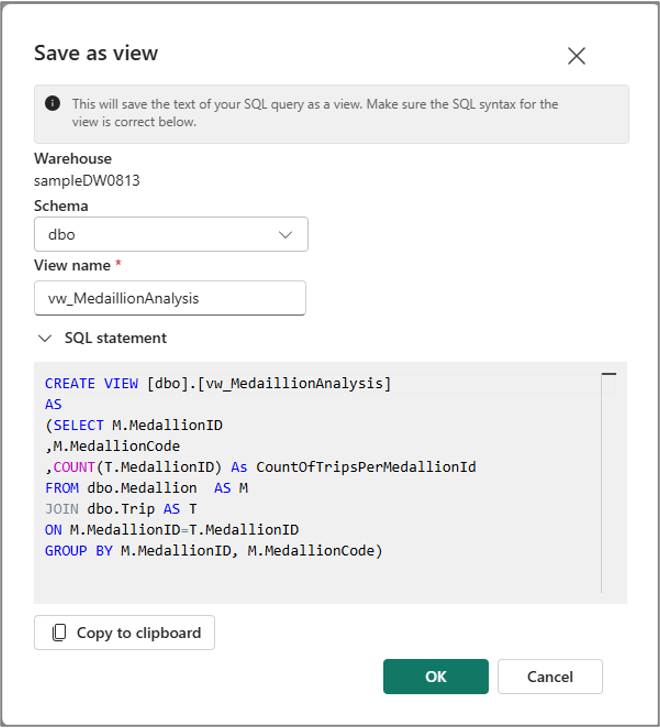
Nota
Poiché il menu Salva come tabella e Salva con nome sono disponibili solo per il testo della query selezionato, è necessario selezionare il testo della query prima di usare questi menu.
Crea vista non supporta la denominazione in tre parti, quindi la vista viene sempre creata nel magazzino primario impostando il magazzino come magazzino primario.
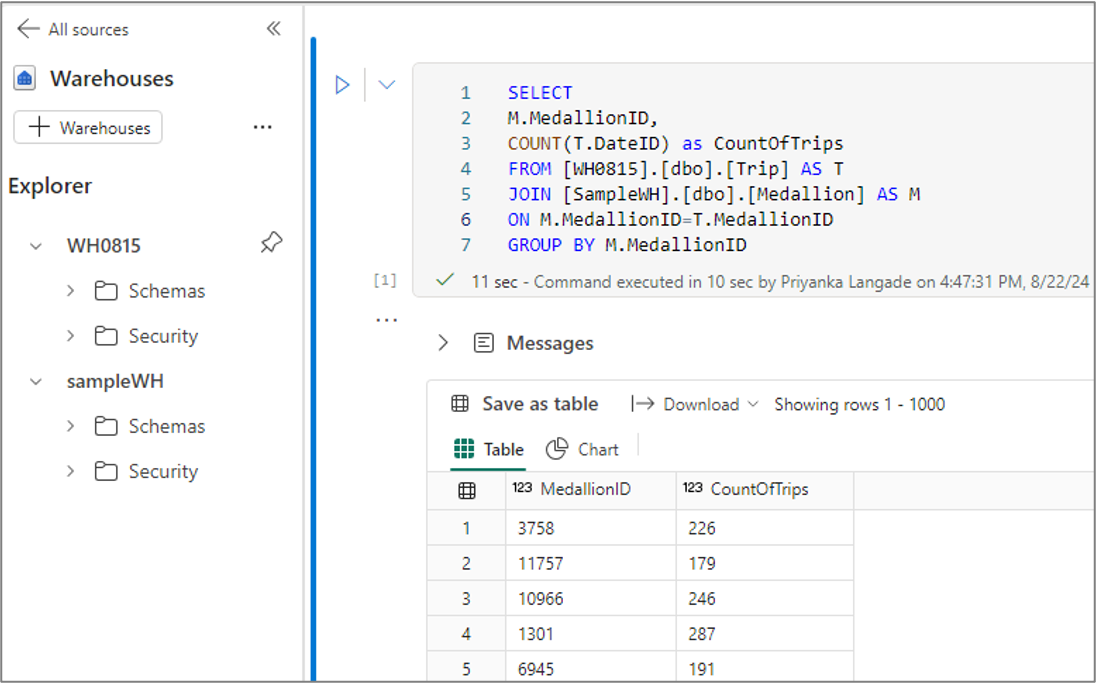
Query tra warehouse
È possibile eseguire query tra warehouse usando la denominazione in tre parti. La denominazione in tre parti è costituita dal nome del database, dal nome dello schema e dal nome della tabella. Il nome del database è il nome del warehouse o dell'endpoint di analisi SQL, il nome dello schema è il nome dello schema e il nome della tabella è il nome della tabella.
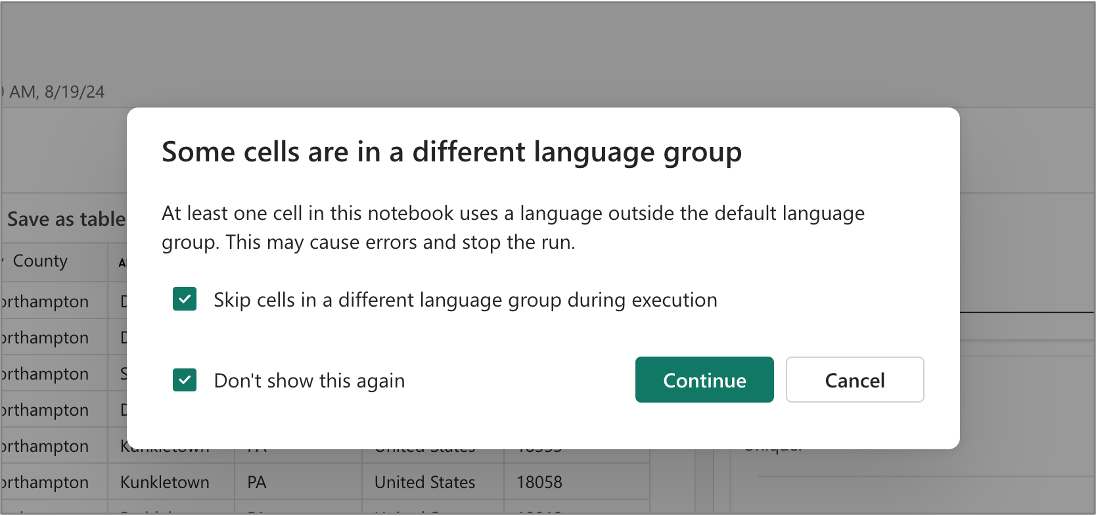
Ignorare l'esecuzione di codice non T-SQL
All'interno dello stesso notebook è possibile creare celle di codice che usano linguaggi diversi. Ad esempio, una cella di codice PySpark può precedere una cella di codice T-SQL. In questo caso, l'utente può scegliere di ignorare l'esecuzione di qualsiasi codice PySpark per il notebook T-SQL. Questa finestra di dialogo viene visualizzata quando si eseguono tutte le celle di codice facendo clic sul pulsante Esegui tutto sulla barra degli strumenti.
Limiti dell'anteprima pubblica
- La cella del parametro non è ancora supportata nel notebook T-SQL. Il parametro passato dalla pipeline o dall'utilità di pianificazione non sarà in grado di essere usato nel notebook T-SQL.
- La funzionalità Esecuzione recente non è ancora supportata nel notebook T-SQL. È necessario usare la funzionalità di monitoraggio del data warehouse corrente per controllare la cronologia di esecuzione del notebook T-SQL. Per altre informazioni, vedere l'articolo Monitorare il data warehouse .
- L'URL di monitoraggio all'interno dell'esecuzione della pipeline non è ancora supportato nel notebook T-SQL.
- La funzionalità snapshot non è ancora supportata nel notebook T-SQL.
- Il supporto per Git e per la pipeline di distribuzione non è ancora disponibile nel notebook T-SQL.
Contenuto correlato
Per altre informazioni sui notebook di Fabric, vedere i seguenti articoli:
- Che cos'è il data warehousing in Microsoft Fabric?
- Domande? Provare a chiedere alla Community di Fabric.
- inviare suggerimenti, Contribuire con idee per migliorare Fabric.