Provisioning in ingresso basato su API con App per la logica di Azure
Questa esercitazione descrive come usare il flusso di lavoro di App per la logica di Azure per implementare il provisioning in ingresso basato su API di Microsoft Entra ID. Usando la procedura descritta in questa esercitazione, è possibile convertire un file CSV contenente i dati HR in un payload della richiesta in blocco e inviarlo all'endpoint API di provisioning /bulkUpload di Microsoft Entra. L'articolo fornisce anche indicazioni su come usare lo stesso modello di integrazione con qualsiasi sistema di registrazione.
Scenario di integrazione
Requisito di business
Il sistema di registrazione in uso genera periodicamente esportazioni di file CSV contenenti dati sui dipendenti. Si vuole implementare un'integrazione che legge i dati dal file CSV ed effettua automaticamente il provisioning degli account utente nella directory di destinazione (Active Directory locale per utenti ibridi e Microsoft Entra ID per gli utenti solo cloud).
Requisito per l'implementazione
Dal punto di vista dell'implementazione:
- Si vuole usare un flusso di lavoro App per la logica di Azure per leggere i dati delle esportazioni di file CSV disponibili in una condivisione file di Azure e inviarli all'endpoint API di provisioning in ingresso.
- Nel flusso di lavoro di App per la logica di Azure non si vuole implementare la logica complessa del confronto dei dati di identità tra il sistema di registrazione e la directory di destinazione.
- Si vuole usare il servizio di provisioning di Microsoft Entra per applicare le regole di provisioning gestito dall'IT per creare/aggiornare/abilitare/disabilitare automaticamente gli account nella directory di destinazione (Active Directory locale o Microsoft Entra ID).

Varianti dello scenario di integrazione
Anche se questa esercitazione usa un file CSV come sistema di registrazione, è possibile personalizzare il flusso di lavoro di App per la logica di Azure di esempio per leggere i dati da qualsiasi sistema di registrazione. App per la logica di Azure offre un'ampia gamma di connettori predefiniti e connettori gestiti con azioni e trigger predefiniti che è possibile usare nel flusso di lavoro di integrazione.
Ecco un elenco delle varianti dello scenario di integrazione aziendale, in cui è possibile implementare il provisioning in ingresso basato su API con un flusso di lavoro di App per la logica.
| # | Sistema di registrazione | Indicazioni sull'integrazione relative all'uso di App per la logica per leggere i dati di origine |
|---|---|---|
| 1 | File archiviati nel server SFTP | Usare il connettore SFTP predefinito o il connettore SSH SFTP gestito per leggere i dati dai file archiviati nel server SFTP. |
| 2 | Tabella di database | Se si usa un server SQL di Azure o un'istanza locale di SQL Server, usare il connettore SQL Server per leggere i dati della tabella. Se si usa un database Oracle, usare il connettore Database Oracle per leggere i dati della tabella. |
| 3 | Sistemi SAP S/4 HANA locali e ospitati nel cloud o sistemi SAP locali classici, ad esempio R/3 ed ECC |
Usare il connettore SAP per recuperare i dati di identità dal sistema SAP. Per esempi su come configurare questo connettore, vedere gli scenari comuni di integrazione SAP con App per la logica di Azure e il connettore SAP. |
| 4 | IBM MQ | Usare il connettore IBM MQ per ricevere i messaggi del provisioning dalla coda. |
| 5 | Dynamics 365 Human Resources | Usare il connettore Dataverse per leggere i dati dalle tabelle Dataverse usate da Microsoft Dynamics 365 Human Resources. |
| 6 | Qualsiasi sistema che esponga API REST | Se non si trova un connettore per il sistema di registrazione nella libreria del connettore di App per la logica, è possibile creare un connettore personalizzato per leggere i dati dal sistema di registrazione. |
Dopo aver letto i dati di origine, applicare le regole di pre-elaborazione e convertire l'output del sistema di registrazione in una richiesta in blocco che può essere inviata all'endpoint API di provisioning bulkUpload di Microsoft Entra.
Importante
Se si vuole condividere con la community il flusso di lavoro di integrazione di provisioning in ingresso basato su API e App per la logica, creare un modello App per la logica, documentare i passaggi su come usarlo e inviare una richiesta pull per l'inclusione nel repository GitHub entra-id-inbound-provisioning.
Come usare questa esercitazione
Il modello di distribuzione App per la logica pubblicato nel repository GitHub del provisioning in ingresso di Microsoft Entra automatizza diverse attività. Include anche la logica per la gestione di file CSV di grandi dimensioni e la suddivisione in blocchi della richiesta in blocco per inviare 50 record in ogni richiesta. Ecco come testarlo e personalizzarlo in base ai requisiti di integrazione.
Nota
Il flusso di lavoro di App per la logica di Azure di esempio viene fornito "così come è" come riferimento per l'implementazione. In caso di domande correlate o per migliorarlo, usare il repository del progetto GitHub.
| # | Attività di automazione | Linee guida per l'implementazione | Personalizzazione avanzata |
|---|---|---|---|
| 1 | Leggere i dati sui dipendenti dal file CSV. | Il flusso di lavoro di App per la logica usa una funzione di Azure per leggere il file CSV archiviato in una condivisione file di Azure. La funzione di Azure converte i dati CSV in formato JSON. Se il formato del proprio file CSV è diverso, aggiornare il passaggio del flusso di lavoro "Analizza JSON" e "Costruisci SCIMUser". | Se il sistema di registrazione è diverso, vedere le indicazioni fornite nella sezione Varianti dello scenario di integrazione su come personalizzare il flusso di lavoro di App per la logica usando un connettore appropriato. |
| 2 | Pre-elaborare e convertire i dati in formato SCIM. | Per impostazione predefinita, il flusso di lavoro di App per la logica converte ogni record nel file CSV in una rappresentazione che combina utente di base e utente aziendale SCIM. Se si prevede di usare estensioni dello schema SCIM personalizzate, aggiornare il passaggio "Costruisci SCIMUser" per includere tali estensioni. | Se si vuole eseguire codice C# per la formattazione avanzata e la convalida dei dati, usare funzioni di Azure personalizzate. |
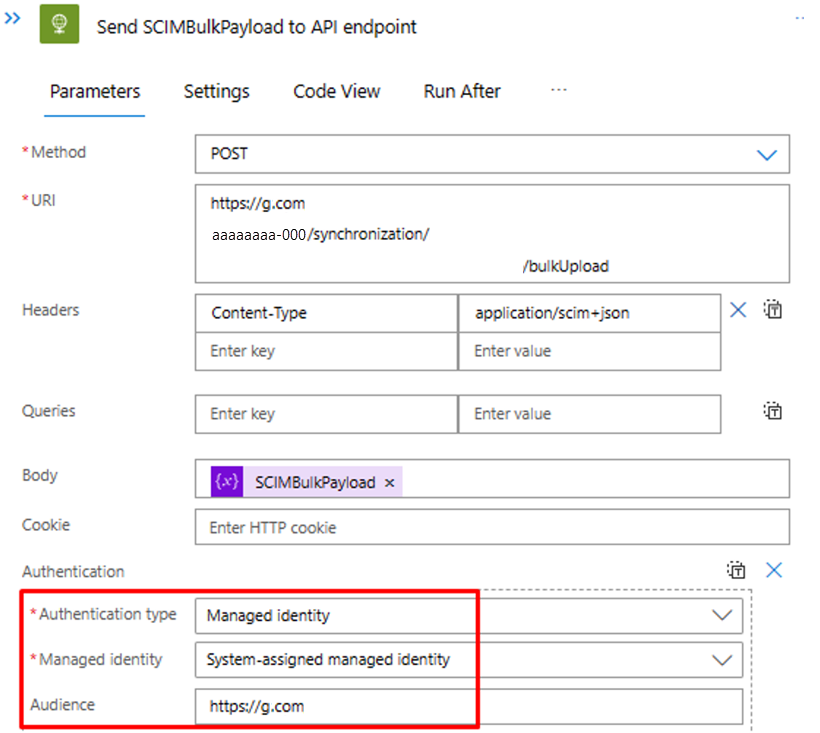
| 3 | Usare il metodo di autenticazione corretto | È possibile usare un'entità servizio o l'identità gestita per accedere all'API di provisioning in ingresso. Aggiornare il passaggio "Invia SCIMBulkPayload all'endpoint API" con il metodo di autenticazione corretto. | - |
| 4 | Effettuare il provisioning degli account in Active Directory locale o in Microsoft Entra ID. | Configurare l'app di provisioning in ingresso basato su API. In questo modo viene generato un endpoint API /bulkUpload univoco. Aggiornare il passaggio "Invia SCIMBulkPayload all'endpoint API" per usare l'endpoint API bulkUpload corretto. | Se si prevede di usare la richiesta in blocco con lo schema SCIM personalizzato, estendere lo schema dell'app di provisioning per includere gli attributi dello schema SCIM personalizzato. |
| 5 | Analizzare i log di provisioning e ripetere il provisioning per i record in errore. | Questa automazione non è ancora implementata nel flusso di lavoro di App per la logica di esempio. Per implementarla, fare riferimento all'API Graph dei log di provisioning. | - |
| 6 | Distribuire l'automazione basata su App per la logica nell'ambiente di produzione. | Dopo aver verificato il flusso di provisioning basato su API e aver personalizzato il flusso di lavoro di App per la logica per soddisfare i propri requisiti, distribuire l'automazione nell'ambiente. | - |
Passaggio 1: Creare un account di archiviazione di Azure per ospitare il file CSV
I passaggi documentati in questa sezione sono facoltativi. Se si ha già un account di archiviazione esistente o si vuole leggere il file CSV da un'altra origine, ad esempio il sito di SharePoint o l'archiviazione BLOB, aggiornare l'app per la logica per usare il connettore preferito.
- Accedere al portale di Azure come almeno un amministratore dell'applicazione.
- Cercare "Account di archiviazione" e crearne un nuovo account di archiviazione.
- Assegnare un gruppo di risorse e assegnargli un nome.
- Dopo aver creato l'account di archiviazione, passare alla risorsa.
- Fare clic sull'opzione di menu "Condivisione file" e creare una nuova condivisione file.
- Verificare che la creazione della condivisione file sia riuscita.
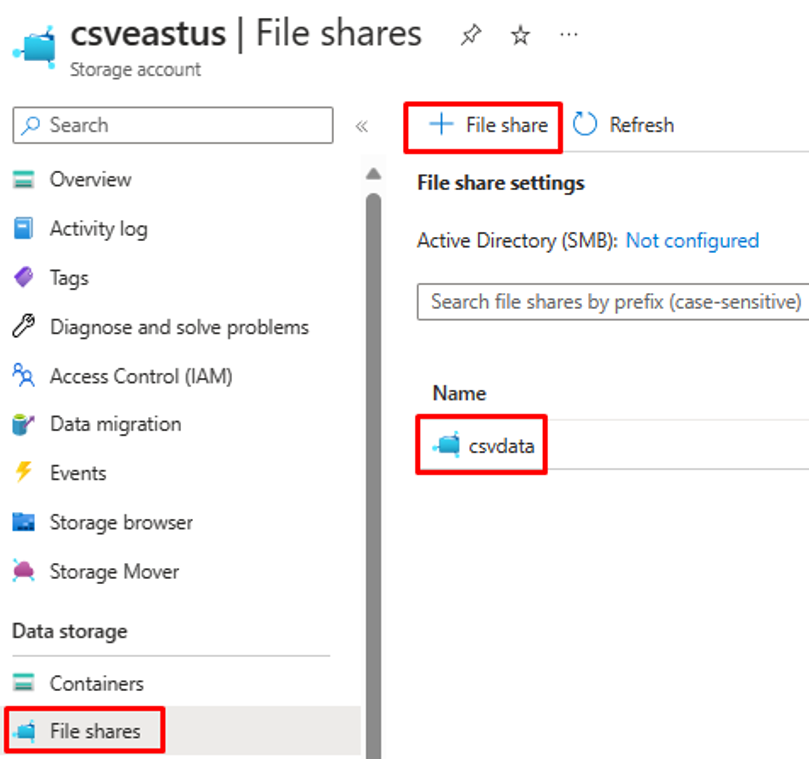
- Caricare un file CSV di esempio nella condivisione file usando l'opzione di caricamento.
- Ecco uno screenshot delle colonne nel file CSV.






Passaggio 2: Configurare il convertitore CSV2JSON della funzione di Azure
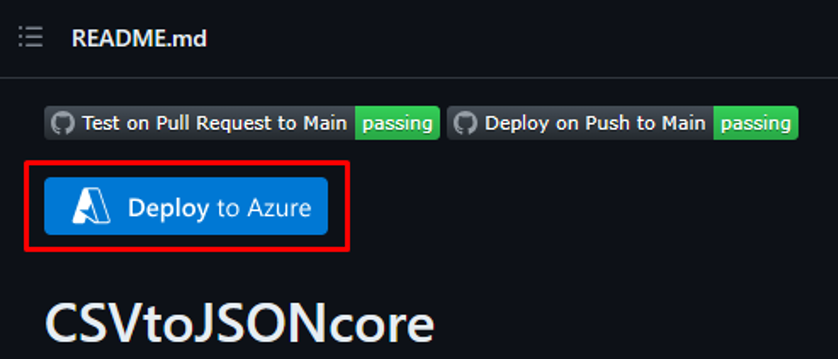
Nel browser associato al portale di Azure aprire l'URL del repository GitHub https://github.com/joelbyford/CSVtoJSONcore.
Fare clic sul collegamento "Distribuisci in Azure" per distribuire questa funzione di Azure nel tenant di Azure.
Specificare il gruppo di risorse in cui distribuire questa funzione di Azure.
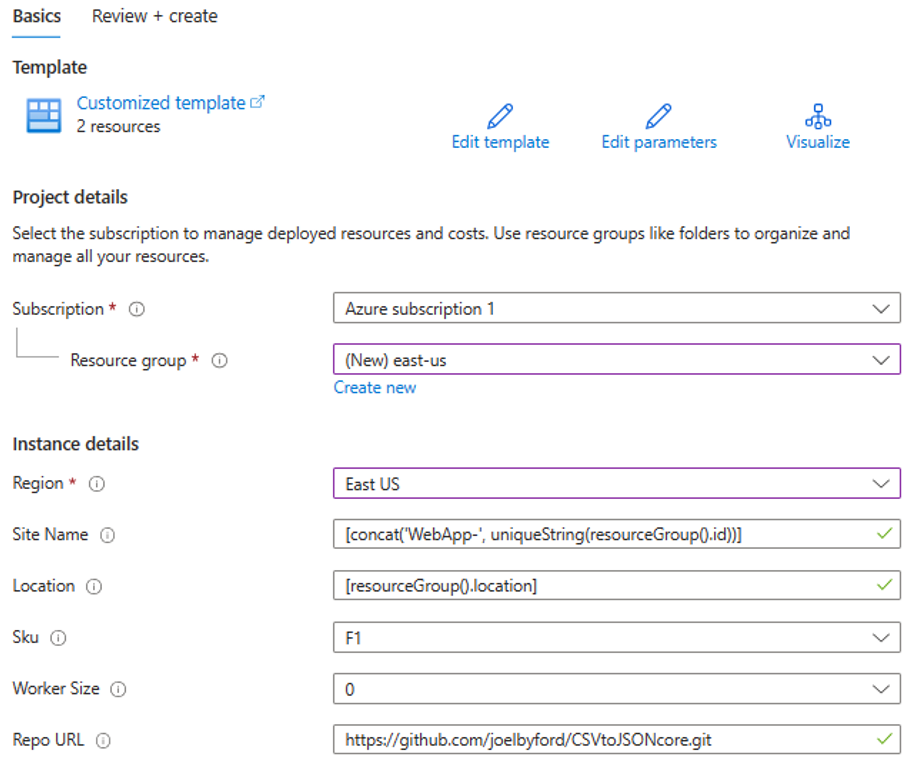
Se viene visualizzato l'errore "Questa area ha una quota di 0 istanze per la sottoscrizione", provare a selezionare un'area diversa.
Assicurarsi che la distribuzione della funzione di Azure come servizio app sia riuscita.
Passare al gruppo di risorse e aprire la configurazione dell'app Web. Assicurarsi che lo stato sia "In esecuzione". Copiare il nome di dominio predefinito associato all'app Web.
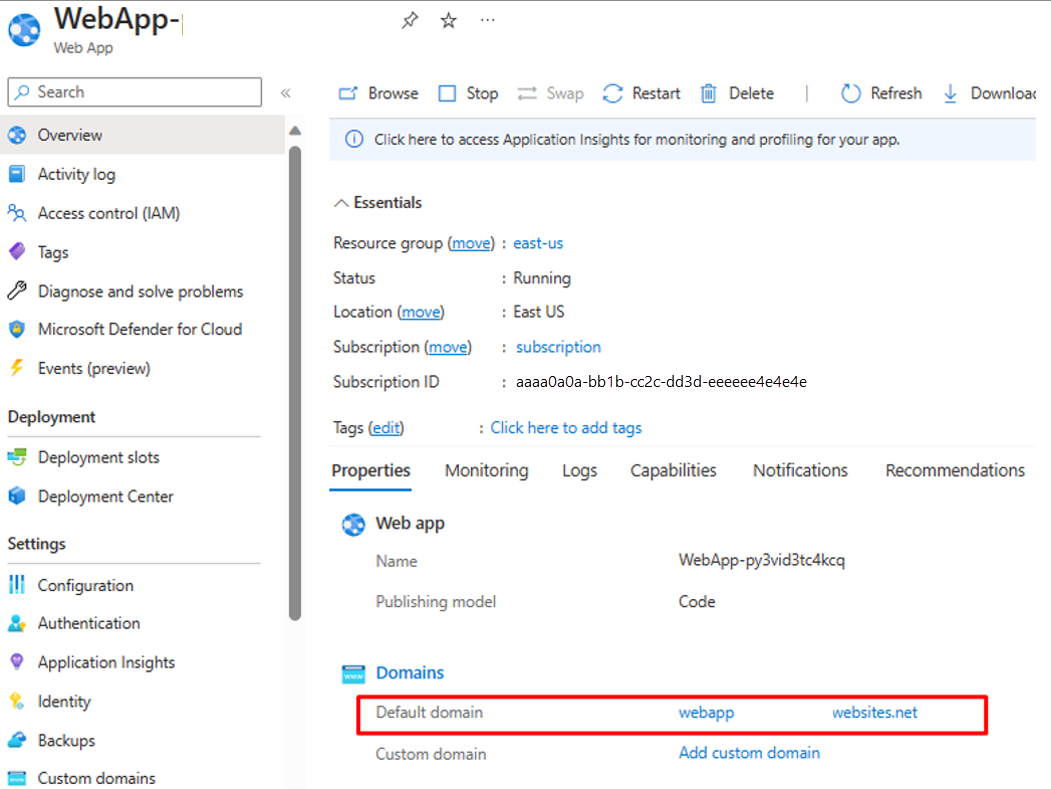
Eseguire lo script di PowerShell seguente per verificare se l'endpoint CSVtoJSON funziona come previsto. Impostare i valori corretti per le variabili
$csvFilePathe$urinello script.# Step 1: Read the CSV file $csvFilePath = "C:\Path-to-CSV-file\hr-user-data.csv" $csvContent = Get-Content -Path $csvFilePath # Step 2: Set up the request $uri = "https://az-function-webapp-your-domain/csvtojson" $headers = @{ "Content-Type" = "text/csv" } $body = $csvContent -join "`n" # Join the CSV lines into a single string # Step 3: Send the POST request $response = Invoke-WebRequest -Uri $uri -Method POST -Headers $headers -Body $body # Output and format the JSON response $response.Content | ConvertFrom-JSON | ConvertTo-JSONSe la distribuzione della funzione di Azure ha esito positivo, l'ultima riga dello script restituisce la versione JSON del file CSV.
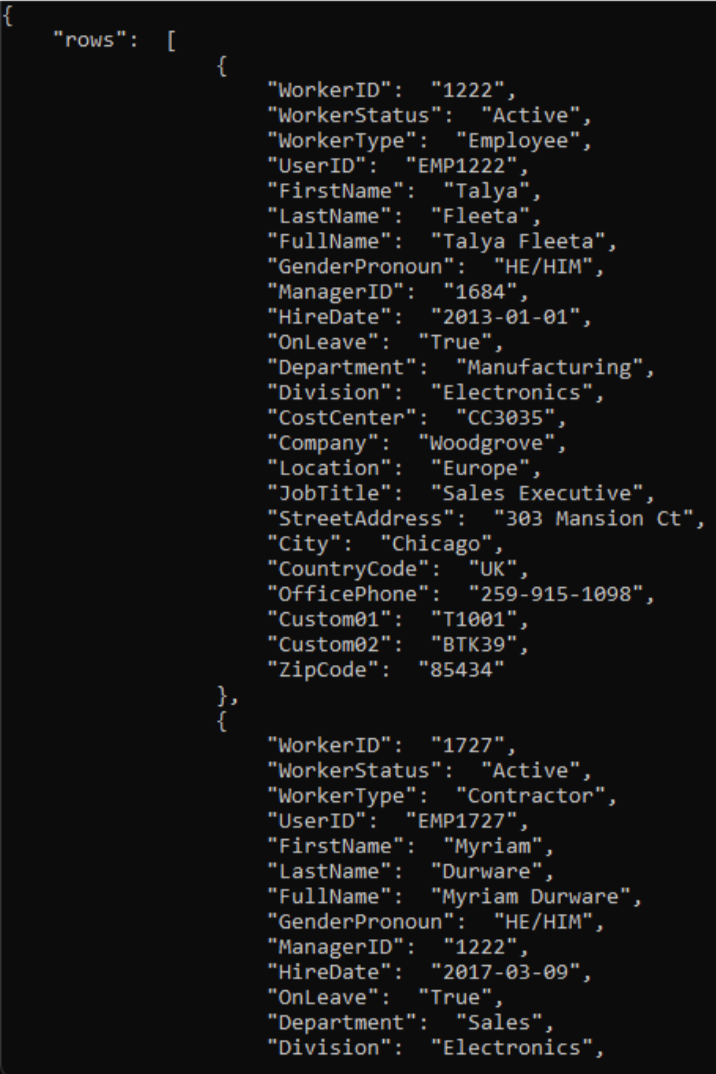 .
.Per consentire ad App per la logica di richiamare questa funzione di Azure, nell'impostazione CORS per l'app Web immettere un asterisco (*) e fare clic su "Salva" per salvare la configurazione.
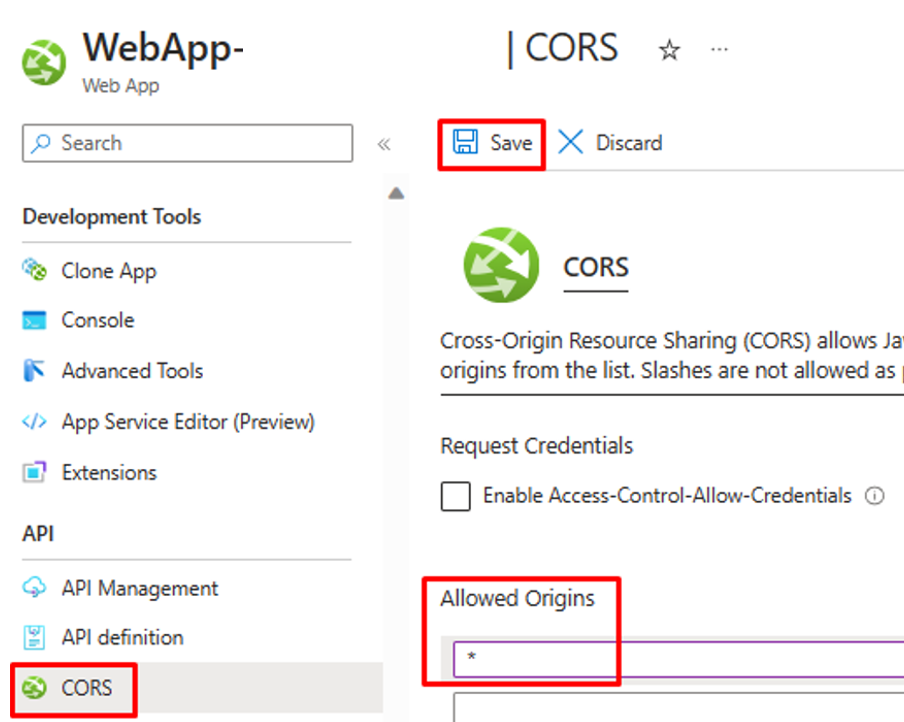





Passaggio 3: Configurare il provisioning utenti in ingresso basato su API
- Configurare il provisioning utenti in ingresso basato su API.
Passaggio 4: Configurare il flusso di lavoro di App per la logica di Azure
Fare clic sul pulsante seguente per distribuire il modello di ARM per il flusso di lavoro CSV2SCIMBulkUpload di App per la logica.
Nei dettagli dell'istanza aggiornare gli elementi evidenziati, copiando e incollando i valori dei passaggi precedenti.
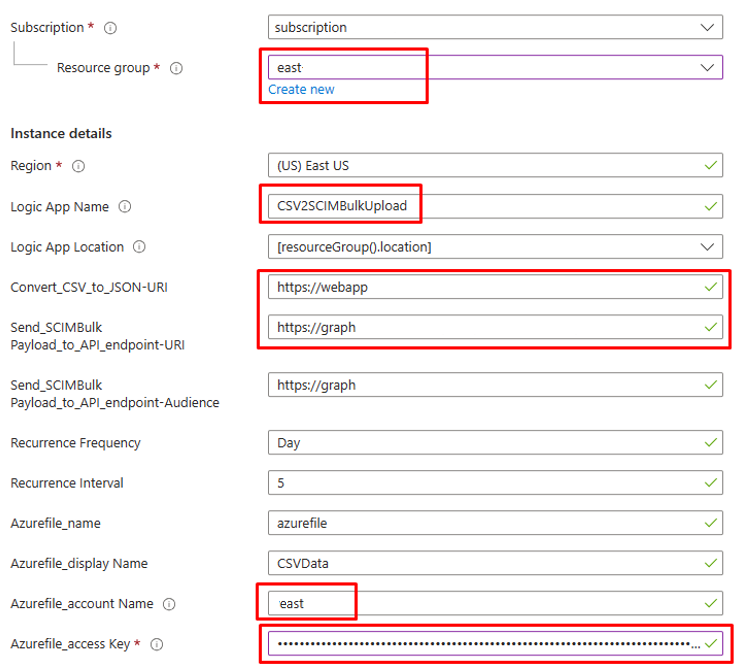
Per il parametro
Azurefile_access Key, aprire l'account di archiviazione file di Azure e copiare la chiave di accesso presente in "Sicurezza e rete".
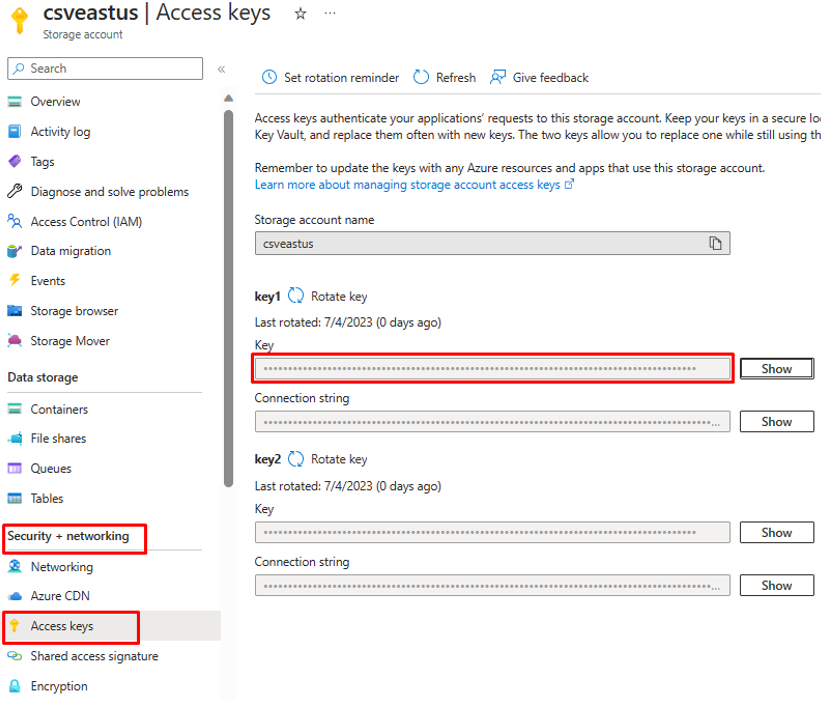
Fare clic sull'opzione "Rivedi e crea" per avviare la distribuzione.
Al termine della distribuzione, verrà visualizzato il messaggio seguente.
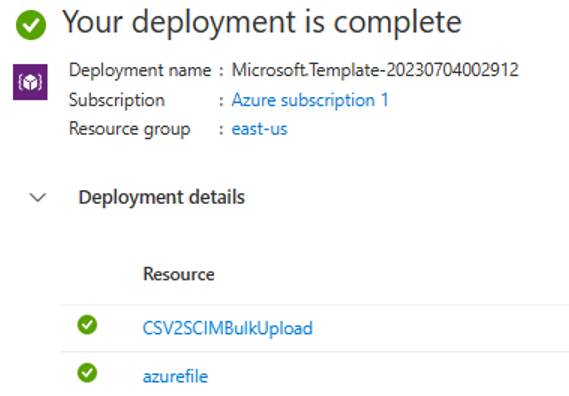



Passaggio 5: Configurare l'identità gestita assegnata dal sistema
- Aprire il riquadro Impostazioni -> Identità del flusso di lavoro di App per la logica.
- Abilitare Identità gestita assegnata dal sistema.
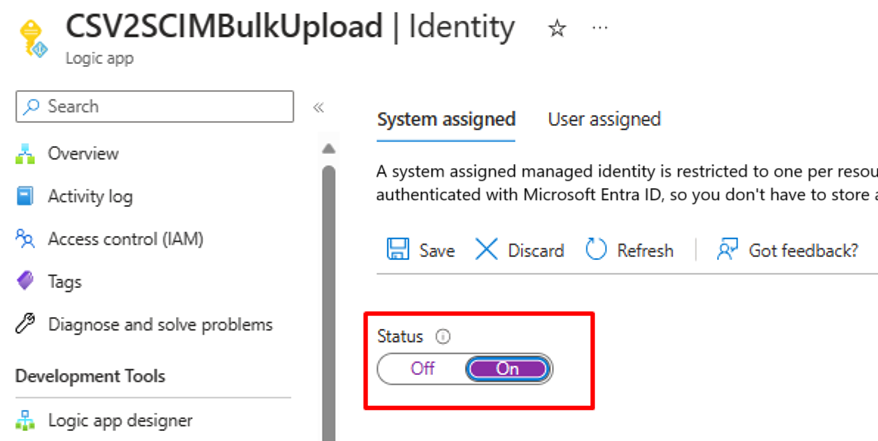
- Verrà visualizzato un prompt per confermare l'uso dell'identità gestita. Fare clic su Sì.
- Concedere all'identità gestita le autorizzazioni per eseguire il caricamento in blocco.

Passaggio 6: Esaminare e modificare i passaggi del flusso di lavoro
Aprire l'app per la logica nella visualizzazione di progettazione.
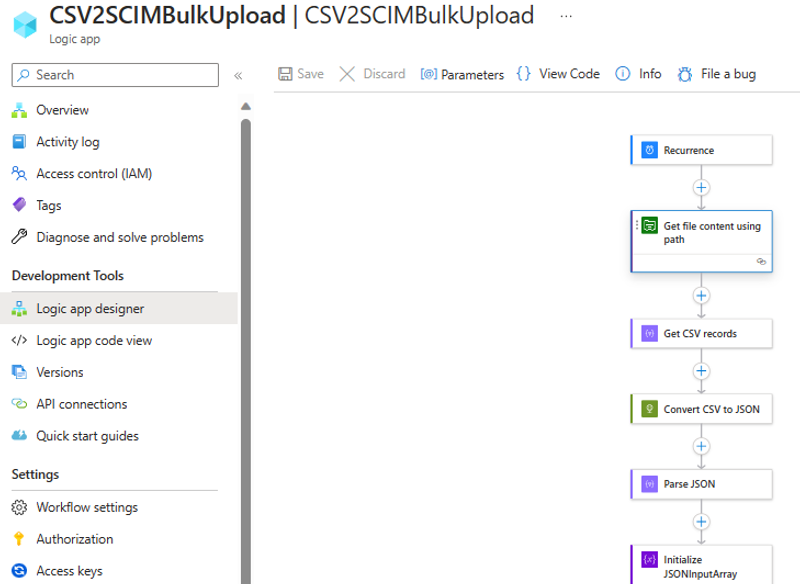
Esaminare la configurazione di ogni passaggio del flusso di lavoro per assicurarsi che sia corretta.
Aprire il passaggio "Ottieni contenuto file in base al percorso" e correggerlo per passare ad Archiviazione file di Azure nel tenant.
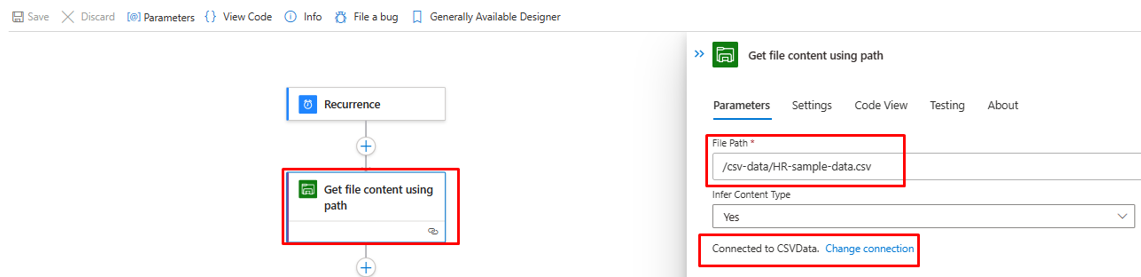
Aggiornare la connessione, se necessario.
Assicurarsi che il passaggio "Converti CSV in JSON" punti all'istanza corretta dell'app Web per la funzione di Azure.
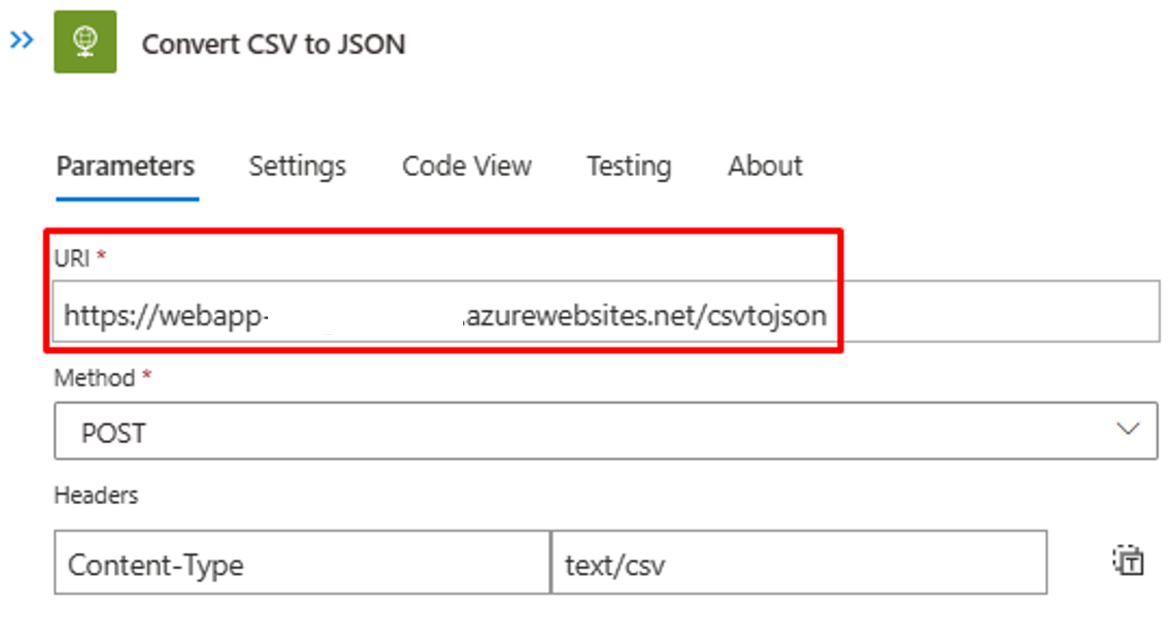
Se il contenuto/intestazione del file CSV è diverso, aggiornare il passaggio "Analizza JSON" con l'output JSON che è possibile recuperare dalla chiamata API alla funzione di Azure. Usare l'output di PowerShell del passaggio 2.
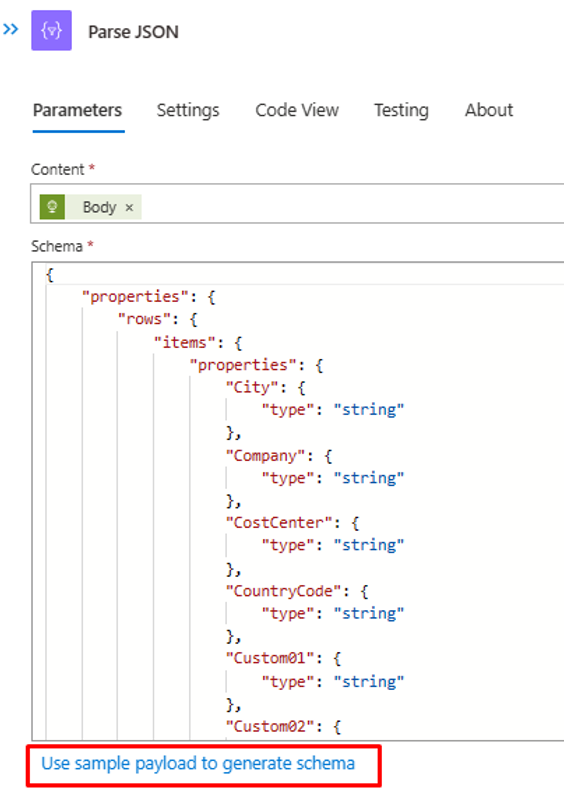
Nel passaggio "Costruisci SCIMUser" assicurarsi che i campi del file CSV vengano abbinati correttamente agli attributi SCIM che verranno usati per l'elaborazione.

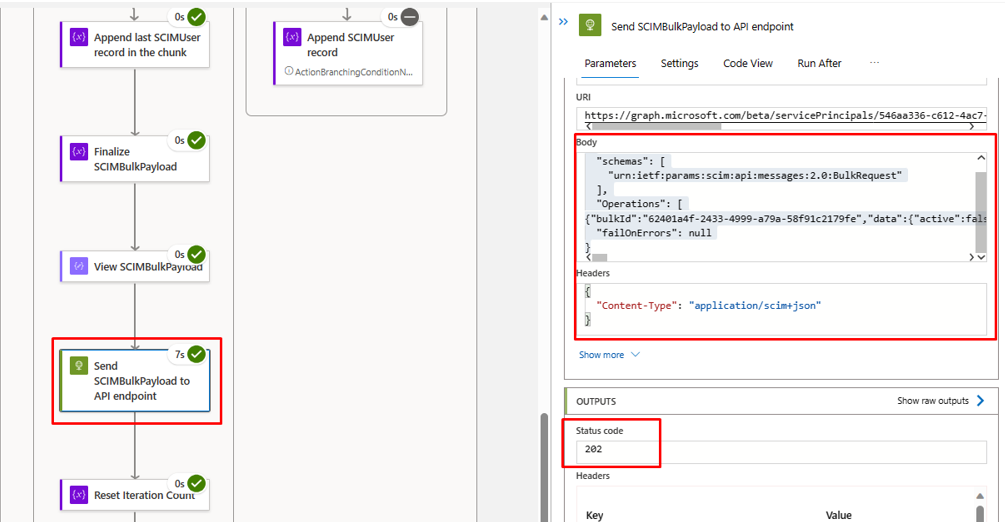
Nel passaggio "Invia SCIMBulkPayload all'endpoint API" assicurarsi di usare il meccanismo di autenticazione e l'endpoint API corretti.






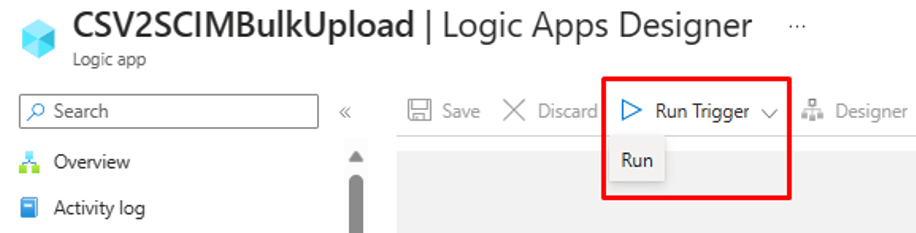
Passaggio 7: Eseguire il trigger e testare il flusso di lavoro di App per la logica
- Nella versione "Disponibile a livello generale" della finestra di progettazione di App per la logica fare clic su Esegui trigger per eseguire manualmente il flusso di lavoro.
- Al termine dell'esecuzione, esaminare l'azione eseguita da App per la logica in ogni iterazione.
- Nell'iterazione finale i dati di caricamento di App per la logica dovrebbero essere visualizzati nell'endpoint API di provisioning in ingresso. Cercare il codice di stato
202 Accept. È possibile copiare e incollare la richiesta di caricamento in blocco e quindi verificarla.