Che cos'è il generatore di modelli e come funziona?
Il generatore di modelli di ML.NET è un'estensione grafica intuitiva di Visual Studio che consente di compilare, eseguire il training e distribuire modelli di Machine Learning personalizzati. Usa il Machine Learning automatizzato (AutoML) per esplorare diversi algoritmi di apprendimento automatico e le impostazioni per individuare quelli più adatti allo scenario.
Non è necessario avere competenze di Machine Learning per usare il generatore di modelli. Servono solo alcuni dati e un problema da risolvere. Il generatore di modelli genera il codice per aggiungere il modello all'applicazione .NET.

Creare un progetto di Model Builder
Quando avvierai Model Builder per la prima volta, ti verrà chiesto di denominare il progetto e quindi di creare un file di configurazione mbconfig all'interno del progetto. Il file mbconfig tiene traccia di tutto ciò che si esegue in Generatore modelli per consentire di riaprire la sessione.
Dopo il training, vengono generati tre file nel file *.mbconfig:
- Model.consumption.cs: Questo file contiene gli schemi
ModelInputeModelOutputnonché la funzionePredictgenerata per l'utilizzo del modello. - Model.training.cs: questo file contiene la pipeline di training (trasformazioni di dati, algoritmo, iperparametri degli algoritmi) scelta da Generatore modelli per eseguire il training del modello. È possibile usare questa pipeline per ripetere il training del modello.
- Model.zip: si tratta di un file ZIP serializzato che rappresenta il modello di ML.NET sottoposto a training.
Quando si crea il file mbconfig, viene richiesto un nome. Questo nome viene applicato ai file di utilizzo, training e modello. In questo caso, il nome usato è Model.
Scenario
È possibile trasferire molti scenari diversi nel generatore di modelli per generare un modello di Machine Learning per l'applicazione.
Uno scenario è una descrizione del tipo di previsione che si vuole eseguire usando i dati. Ad esempio:
- Prevedi il volume di vendita futuro dei prodotti in base ai dati storici di vendita.
- Classifica le valutazioni come positive o negative in base alle recensioni dei clienti.
- Rileva se una transazione bancaria è fraudolenta.
- Indirizza i problemi dei feedback dei clienti al team corretto nell'azienda.
Ogni scenario è mappato a un'attività di apprendimento automatico diversa, tra cui:
| Attività | Scenario |
|---|---|
| Classificazione binaria | Classificazione dei dati |
| Classificazione multi-classe | Classificazione dei dati |
| Classificazione immagini | Classificazione immagini |
| Classificazione testo | Classificazione testo |
| Regressione | Previsione di valori |
| Elemento consigliato | Elemento consigliato |
| Previsioni | Previsioni |
Ad esempio, lo scenario di classificazione dei sentimenti come positivi o negativi rientra nell'attività di classificazione binaria.
Per altre informazioni sulle diverse attività di Machine Learning supportate da ML.NET vedere Attività di Machine Learning in ML.NET.
Quale scenario di Machine Learning è adatto alle mie esigenze?
In Generatore modelli è necessario selezionare uno scenario. Il tipo di scenario dipende dal tipo di stima che stai cercando di eseguire.
tabulare
Classificazione dei dati
La classificazione viene usata per classificare i dati in categorie.
Input di esempio
Output di esempio
| SepalLength | SepalWidth | Lunghezza petalo | Larghezza petalo | Specie |
|---|---|---|---|---|
| 5.1 | 3.5 | 1.4 | 0,2 | setosa |
| Specie stimate |
|---|
| setosa |
Previsione di valori
La stima del valore, che rientra nell'attività di regressione, viene usata per stimare i numeri.
Input di esempio
Output di esempio
| vendor_id | rate_code | passenger_count | trip_time_in_secs | trip_distance | payment_type | fare_amount |
|---|---|---|---|---|---|---|
| CMT | 1 | 1 | 1271 | 3.8 | CRD | 17.5 |
| Tariffa stimata |
|---|
| 4.5 |
Elemento consigliato
Lo scenario di raccomandazione prevede un elenco di elementi suggeriti per un determinato utente, in base a quanto i suoi gusti e le sue preferenze siano simili a quelli di altri utenti.
È possibile usare lo scenario di raccomandazione quando si dispone di un set di utenti e di un set di "prodotti", ad esempio articoli da acquistare, film, libri o programmi TV, insieme a un set di "valutazioni" degli utenti di tali prodotti.
Input di esempio
Output di esempio
| ID utente | ProductId | Valutazione |
|---|---|---|
| 1 | 2 | 4.2 |
| Valutazione stimata |
|---|
| 4.5 |
Previsioni
Lo scenario di previsione usa dati cronologici con una serie temporale o un componente stagionale.
È possibile usare lo scenario di previsione per prevedere la domanda o la vendita di un prodotto.
Input di esempio
Output di esempio
| Data | SaleQty |
|---|---|
| 1/1/1970 | 1000 |
| Previsione di 3 giorni |
|---|
| [1000,1001,1002] |
Visione artificiale
Classificazione immagini
La classificazione delle immagini viene usata per identificare le immagini di categorie diverse. Ad esempio, tipi diversi di terreno o animali o difetti di produzione.
È possibile usare lo scenario di classificazione delle immagini se si dispone di un set di immagini e si vuole classificare le immagini in categorie diverse.
Input di esempio
Output di esempio

| Etichetta prevista |
|---|
| Dog |
Rilevamento oggetti
Il rilevamento degli oggetti viene usato per individuare e classificare le entità all'interno delle immagini. Ad esempio, l'individuazione e l'identificazione di automobili e persone in un'immagine.
È possibile usare il rilevamento degli oggetti quando le immagini contengono più oggetti di tipi diversi.
Input di esempio
Output di esempio

Elaborazione del linguaggio naturale
Classificazione testo
La classificazione del testo classifica l'input di testo non elaborato.
È possibile usare lo scenario di classificazione del testo se si dispone di un set di documenti o commenti e si vuole classificarli in categorie diverse.
Input di esempio
Output esempio
| Revisione |
|---|
| Mi piace davvero questa bistecca! |
| Valutazione |
|---|
| Positiva |
Ambiente
È possibile eseguire il training del modello di Machine Learning in locale nel computer o nel cloud in Azure, a seconda dello scenario.
Quando si esegue il training in locale, si lavora entro i vincoli delle risorse del computer (CPU, memoria e disco). Quando si esegue il training nel cloud, è possibile aumentare le risorse per soddisfare le esigenze dello scenario, in particolare per set di dati di grandi dimensioni.
| Scenario | CPU locale | GPU locale | Azure |
|---|---|---|---|
| Classificazione dei dati | ✔️ | ❌ | ❌ |
| Previsione di valori | ✔️ | ❌ | ❌ |
| Elemento consigliato | ✔️ | ❌ | ❌ |
| Previsioni | ✔️ | ❌ | ❌ |
| Classificazione immagini | ✔️ | ✔️ | ✔️ |
| Rilevamento oggetti | ❌ | ❌ | ✔️ |
| Classificazione testo | ✔️ | ✔️ | ❌ |
Dati
Dopo aver scelto lo scenario, Model Builder richiede di specificare un set di dati. I dati vengono usati per il training, la valutazione e la scelta del modello più adatto per lo scenario.
Model Builder supporta i set di dati in formato tsv, .csv, .txt e database SQL. Se hai un file .txt, le colonne devono essere separate con ,, ; o \t.
Se il set di dati è costituito da immagini, i tipi di file supportati sono .jpg e .png.
Per altre informazioni, vedere Caricare i dati di training in Generatore modelli.
Scegliere l'output da prevedere (etichetta)
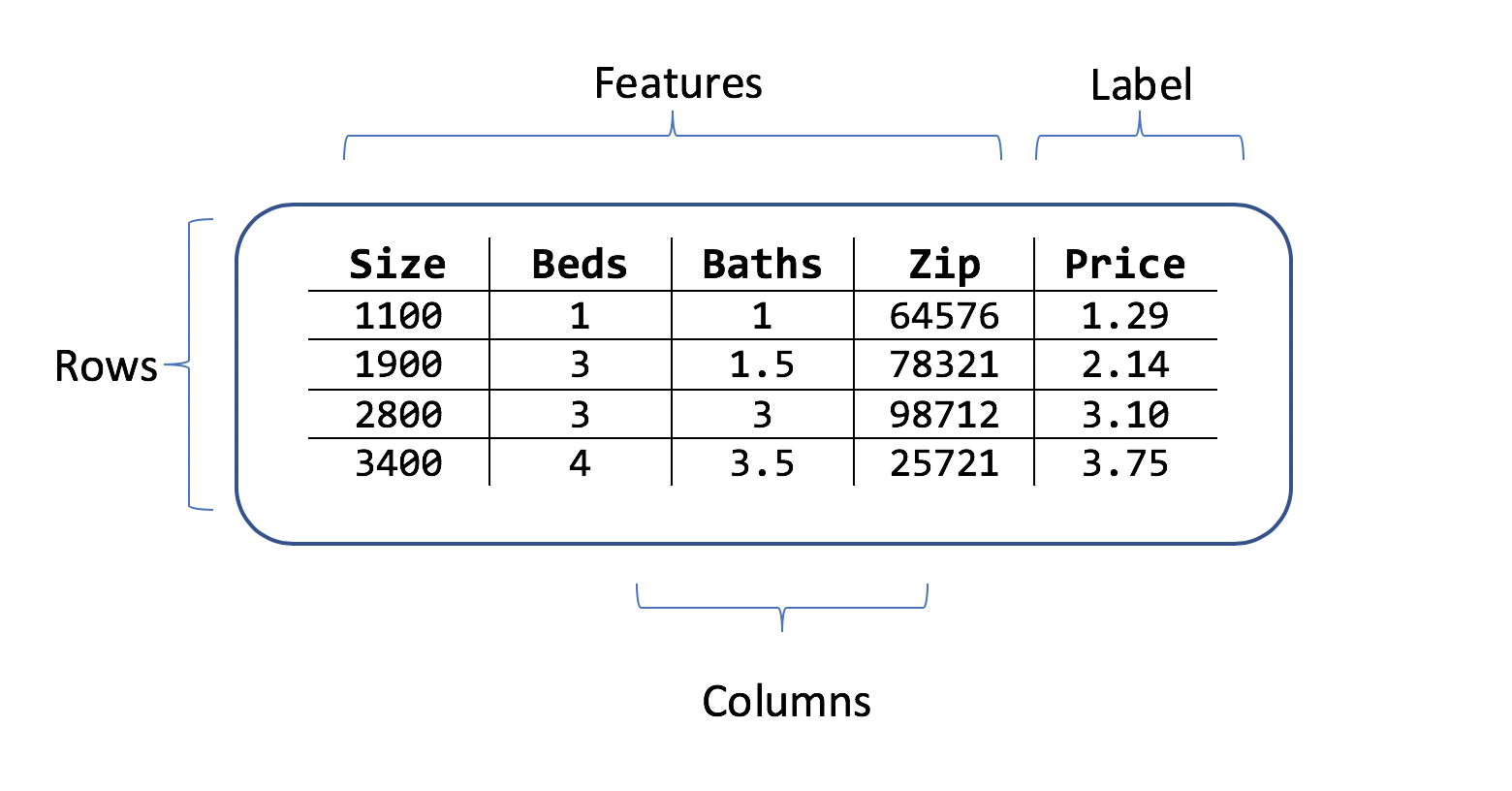
Un set di dati è una tabella di righe di esempi di training e di colonne di attributi. Ogni riga include:
- un'etichetta (l'attributo da prevedere)
- le caratteristiche (gli attributi usati come input per la previsione dell'etichetta)
Per lo scenario di stima del prezzo della casa, è possibile usare le caratteristiche seguenti:
- I metri quadrati della casa.
- Il numero di camere da letto e bagni.
- Il codice postale.
L'etichetta è il prezzo storico della casa per la riga dei valori dei metri quadrati, delle camere da letto e dei bagni e il codice postale.
Set di dati di esempio
Se non sono ancora disponibili dati, provare uno dei set di dati seguenti:
| Scenario | Esempio | Dati | Etichetta | Funzionalità |
|---|---|---|---|---|
| Classificazione | Prevedere le anomalie delle vendite | dati di vendita dei prodotti | Vendite prodotto | Mese |
| Prevedere il sentiment dei commenti del sito Web | dati dei commenti del sito Web | Etichetta (1 in caso di sentiment negativo, 0 quando positivo) | Commento, anno | |
| Prevedere transazioni di carte di credito fraudolente | dati della carta di credito | Classe (1 quando fraudolento, 0 in caso contrario) | Quantità, V1-V28 (caratteristiche anonime) | |
| Prevedere il tipo di problema in un repository GitHub | dati del problema di GitHub | Area | Titolo, descrizione | |
| Previsione di valori | Prevedere il prezzo della tariffa dei taxi | dati delle tariffe dei taxi | Tariffe | Tempo della corsa, distanza |
| Classificazione immagini | Prevedere la categoria di un fiore | immagini di fiori | Il tipo di fiore: margherita, dente di leone, rose, girasoli, tulipani | I dati dell'immagine stessi |
| Elemento consigliato | Prevedere i film che piaceranno a qualcuno | classificazioni di film | Utenti, film | Valutazioni |
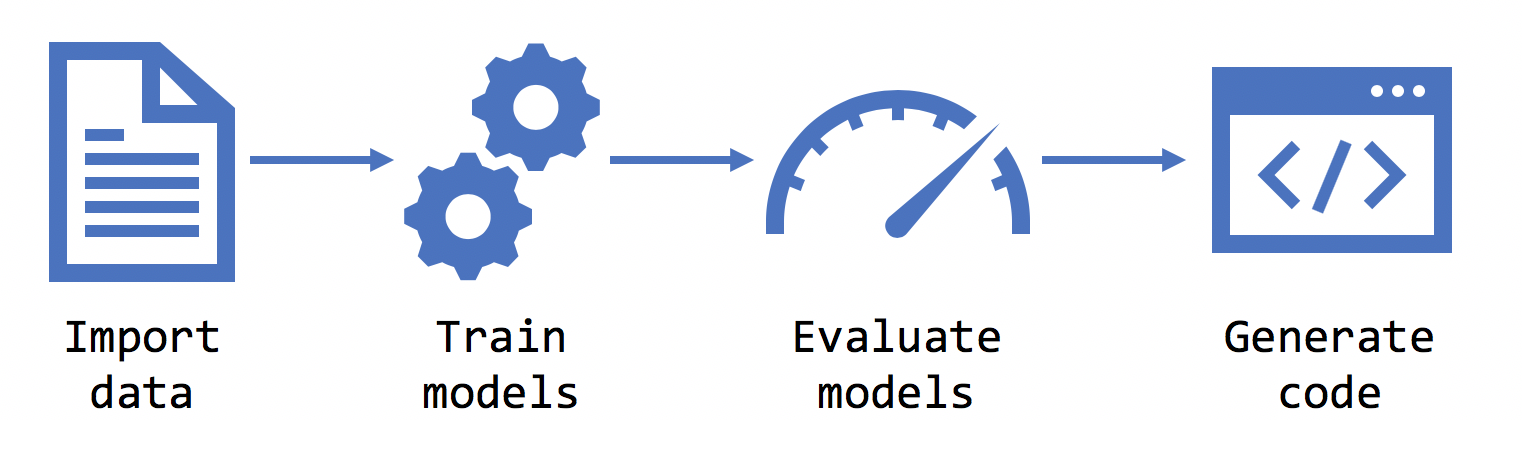
Esecuzione del training
Dopo aver selezionato lo scenario, l’ambiente, i dati e l'etichetta, il generatore di modelli esegue il training del modello.
Cos'è il training?
Il training è un processo automatico tramite il quale il generatore di modelli indica al modello come rispondere alle domande per lo scenario. Dopo aver eseguito il training, il modello può effettuare previsioni con dati di input completamente nuovi. Ad esempio, se si sta eseguendo la stima dei prezzi e viene immessa sul mercato una nuova casa, è possibile prevederne il prezzo di vendita.
Poiché il generatore di modelli usa Il Machine Learning automatico (AutoML), non viene richiesto alcun input o ottimizzazione durante il training.
Per quanto tempo è consigliabile eseguire il training?
Model Builder usa AutoML per esplorare più modelli per trovare il modello con le prestazioni migliori.
I periodi di training più lunghi consentono a AutoML di esplorare più modelli con una gamma più ampia di impostazioni.
La tabella seguente riepiloga il tempo medio impiegato per ottenere prestazioni ottimali per una suite di set di dati di esempio, in un computer locale.
| Dimensioni del set di dati | Tempo medio per il training |
|---|---|
| 0 - 10 MB | 10 sec |
| 10 - 100 MB | 10 min |
| 100 - 500 MB | 30 min |
| 500 - 1 GB | 60 min |
| Oltre 1 GB | Più di 3 ore |
Questi numeri sono solo una guida. La lunghezza esatta del training dipende da:
- Il numero di funzionalità (colonne) usate come input per il modello.
- Tipo di colonne.
- Attività di Machine Learning.
- Le prestazioni di CPU, disco e memoria del computer usato per il training.
È in genere consigliabile usare più di 100 righe, poiché i set di dati con meno di 100 righe potrebbero non produrre alcun risultato.
Evaluate
La valutazione è il processo di misurazione della qualità del modello. Model Builder usa il modello sottoposto a training per eseguire stime con nuovi dati di test e quindi misura la qualità delle stime.
Il generatore di modelli suddivide i dati di training in un set di training e un set di test. I dati di training (80%) vengono usati per eseguire il training del modello, mentre i dati di test (20%) vengono usati per la valutazione del modello.
Come si ottengono informazioni sulle prestazioni del modello?
Uno scenario è mappato a un'attività di Machine Learning. Ogni attività di Machine Learning ha un proprio set di metriche di valutazione.
Previsione di valori
La metrica predefinita per i problemi di stima del valore è RSquared, il valore RSquared è compreso tra 0 e 1. 1 è il miglior valore possibile o, in altre parole, più il valore di RSquared è vicino a 1, migliore è la performance del modello.
Altre metriche segnalate, ad esempio la perdita assoluta, la perdita quadrata e la perdita di RMS sono metriche aggiuntive, che possono essere usate per comprendere le prestazioni e il confronto del modello con altri modelli di stima dei valori.
Classificazione (2 categorie)
La metrica predefinita per i problemi di classificazione è l'accuratezza. L'accuratezza definisce la percentuale di previsioni corrette eseguite dal modello sul set di dati di test. Quanto più vicina a 100% o 1.0, tanto meglio.
Le altre metriche indicate come AUC (Area Under the Curve), che misurano il tasso di veri positivi rispetto al tasso di falsi positivi, devono essere maggiori di 0,50 nei modelli accettabili.
È possibile usare metriche aggiuntive come il punteggio F1 per controllare il bilanciamento tra precisione e richiamo.
Classificazione (3+ categorie)
La metrica predefinita per la classificazione multiclasse è Micro Accuracy. Più la micro accuratezza è vicina al 100% o 1,0, meglio è.
Un'altra metrica importante per la classificazione multiclasse è la Macro-accuratezza, simile alla Micro-accuratezza, quanto più è vicina a 1,0 tanto meglio. Un buon modo per considerare questi due tipi di accuratezza è:
- Micro-accuratezza: con quale frequenza un ticket in ingresso viene classificato per il team corretto?
- Macro-accuratezza: con quale frequenza un ticket in ingresso è corretto per un tipico team?
Altre informazioni sulle metriche di valutazione
Per altre informazioni, vedere Metriche di valutazione dei modelli.
Miglioramento
Se il punteggio delle prestazioni del modello non è quello desiderato, è possibile:
Eseguire il training per un periodo di tempo più lungo. Con più tempo, il motore di Machine Learning automatizzato sperimenta più algoritmi e impostazioni.
Aggiungere altri dati. A volte la quantità di dati non è sufficiente per eseguire il training di un modello di Machine Learning di alta qualità. Ciò vale soprattutto per i set di dati con un numero ridotto di esempi.
Bilanciare i dati. Per le attività di classificazione, assicurarsi che il set di training sia bilanciato tra le categorie. Ad esempio, se sono presenti quattro classi per 100 esempi di training e le prime due classi (tag1 e tag2) vengono usate per 90 record mentre le altre due classi (tag3 e tag4) vengono usate solo per i rimanenti 10 record, la mancanza di dati bilanciati può rendere più difficile per il modello prevedere correttamente tag3 o tag4.
Utilizzo
Dopo la fase di valutazione, il generatore di modelli restituisce un file di modello e il codice che è possibile usare per aggiungere il modello all'applicazione. I modelli di ML.NET vengono salvati come file con estensione zip. Il codice per caricare e usare il modello viene aggiunto come nuovo progetto nella soluzione. Il generatore di modelli aggiunge anche un'app console di esempio che è possibile eseguire per visualizzare il modello in azione.
Inoltre, Model Builder offre la possibilità di creare progetti che utilizzano il modello. Attualmente, Model Builder creerà i progetti seguenti:
- App console: crea un’applicazione per console .NET per eseguire stime dal modello.
- API Web: crea un'API Web ASP.NET Core che consente di usare il modello tramite Internet.
Passaggi successivi
Installa l'estensione di Visual Studio per Model Builder.