Uso dei dati nelle app ASP.NET Core
Suggerimento
Questo contenuto è un estratto dell'eBook Progettare applicazioni Web moderne con ASP.NET Core e Azure, disponibile in .NET Docs o come PDF scaricabile gratuitamente che può essere letto offline.

"I dati sono un elemento prezioso che dura più a lungo dei sistemi"
Tim Berners-Lee
L'accesso ai dati è una questione importante in quasi tutte le applicazioni software. ASP.NET Core supporta svariate opzioni di accesso ai dati, tra cui Entity Framework Core (e anche Entity Framework 6) e può usare qualsiasi framework di accesso ai dati .NET. La scelta del tipo di framework di accesso ai dati da usare dipende dalle esigenze dell'applicazione. Scegliere in base ai progetti ApplicationCore e UI e incapsulare i dettagli di implementazione in Infrastructure per creare un software testabile e poco accoppiato.
Entity Framework Core (per database relazionali)
Se si scrive una nuova applicazione ASP.NET ASP.NET Core che deve usare dati relazionali, è consigliabile che l'applicazione usi Entity Framework Core (EF Core) per accedere ai dati. EF Core è un mapper relazionale a oggetti che consente agli sviluppatori .NET di salvare in modo permanente gli oggetti in/da un'origine dati. In questo modo la maggior parte del codice per l'accesso ai dati che in genere gli sviluppatori devono scrivere non è più necessaria. Come ASP.NET Core, EF Core è stato completamente riscritto per poter supportare le applicazioni multipiattaforma modulari. Viene aggiunto all'applicazione come pacchetto NuGet, configurato durante l'avvio dell'app e richiesto tramite l'inserimento di dipendenze ovunque sia necessario.
Per usare EF Core con un database di SQL Server, eseguire il comando dell'interfaccia della riga di comando dotnet seguente:
dotnet add package Microsoft.EntityFrameworkCore.SqlServer
Per aggiungere il supporto per un'origine dati InMemory per il test:
dotnet add package Microsoft.EntityFrameworkCore.InMemory
DbContext
Per usare EF Core è necessaria una sottoclasse di DbContext. Questa classe contiene le proprietà che rappresentano raccolte di entità che l'applicazione userà. L'esempio eShopOnWeb include un oggetto CatalogContext che contiene raccolte per elementi, marchi e tipi:
public class CatalogContext : DbContext
{
public CatalogContext(DbContextOptions<CatalogContext> options) : base(options)
{
}
public DbSet<CatalogItem> CatalogItems { get; set; }
public DbSet<CatalogBrand> CatalogBrands { get; set; }
public DbSet<CatalogType> CatalogTypes { get; set; }
}
DbContext deve avere un costruttore che accetta DbContextOptions e deve passare questo argomento al costruttore DbContext di base. Se l'applicazione contiene una sola classe DbContext, è possibile passare un'istanza di DbContextOptions, ma se ne contiene di più di una, è necessario usare il tipo generico DbContextOptions<T> passando il tipo DbContext come parametro generico.
Configurazione di EF Core
Nell'applicazione ASP.NET Core, in genere EF Core sarà configurato in Program.cs insieme alle altre dipendenze dell'applicazione. EF Core usa un oggetto DbContextOptionsBuilder, che supporta diversi metodi di estensione utili che consentono di semplificarne la configurazione. Per configurare CatalogContext in modo che usi un database di SQL Server con una stringa di connessione definita in Configuration, aggiungere il codice seguente:
builder.Services.AddDbContext<CatalogContext>(
options => options.UseSqlServer(
builder.Configuration.GetConnectionString("DefaultConnection")));
Per usare il database in memoria:
builder.Services.AddDbContext<CatalogContext>(options =>
options.UseInMemoryDatabase());
Dopo aver installato EF Core, aver creato un tipo figlio DbContext e averlo aggiunto ai servizi dell'applicazione, è possibile usare EF Core. È possibile richiedere un'istanza del tipo DbContext in qualsiasi servizio in cui è necessario e iniziare a usare le entità persistenti tramite LINQ come se si trovassero semplicemente in una raccolta. EF Core converte le espressioni LINQ in query SQL per archiviare e recuperare i dati.
È possibile visualizzare le query eseguite da EF Core configurando un logger e verificando che il livello sia impostato almeno su Information, come illustrato nella Figura 8-1.
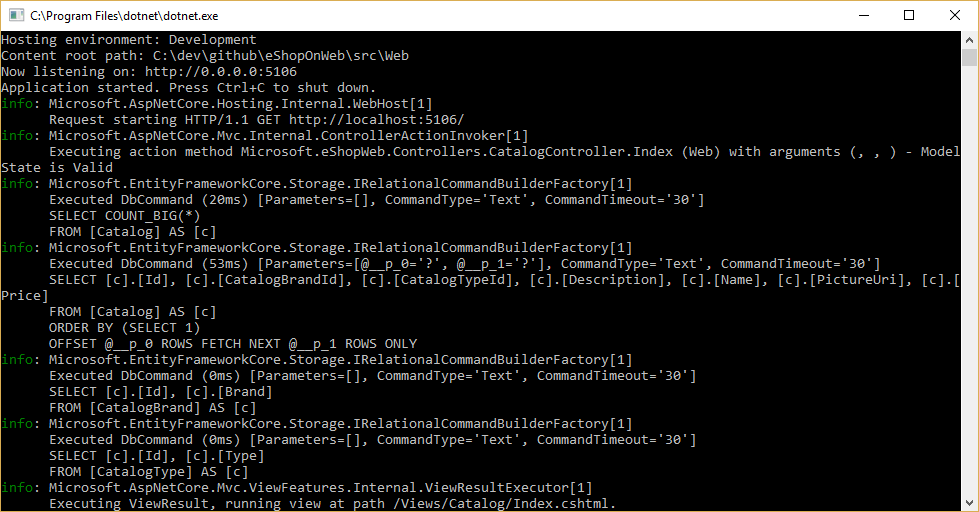
Figura 8-1. Registrazione delle query di EF Core nella console
Recupero e archiviazione dei dati
Per recuperare i dati da EF Core, accedere alla proprietà appropriata e usare LINQ per filtrare il risultato. È anche possibile usare LINQ per eseguire una proiezione e trasformare il risultato da un tipo a un altro. Nell'esempio seguente viene recuperato l'oggetto CatalogBrands. Viene ordinato per nome, filtrato per la proprietà Enabled e proiettato in un tipo SelectListItem:
var brandItems = await _context.CatalogBrands
.Where(b => b.Enabled)
.OrderBy(b => b.Name)
.Select(b => new SelectListItem {
Value = b.Id, Text = b.Name })
.ToListAsync();
Nell'esempio precedente è importante aggiungere la chiamata a ToListAsync per eseguire immediatamente la query. In caso contrario, l'istruzione assegnerà un oggetto IQueryable<SelectListItem> a brandItems, che non sarà eseguito finché non sarà enumerato. Esistono vantaggi e svantaggi nella restituzione di risultati IQueryable dai metodi. La query costruita da EF Core può essere ulteriormente modificata, ma può anche generare errori che si verificano solo in fase di esecuzione, se alla query vengono aggiunte operazioni che EF Core non può convertire. In generale è preferibile passare tutti i filtri al metodo che esegue l'accesso ai dati e restituire una raccolta in memoria, ad esempio List<T>, come risultato.
EF Core tiene traccia delle modifiche apportate alle entità che vengono recuperate dalla persistenza. Per salvare le modifiche a un'entità rilevata, chiamare semplicemente il metodo SaveChangesAsync in DbContext, assicurandosi che sia la stessa istanza di DbContext usata per recuperare l'entità. L'aggiunta e la rimozione delle entità avvengono direttamente nella proprietà DbSet appropriata, con una chiamata a SaveChangesAsync per eseguire i comandi di database. Nell'esempio seguente vengono dimostrate le operazioni di aggiunta, aggiornamento e rimozione delle entità dalla persistenza.
// create
var newBrand = new CatalogBrand() { Brand = "Acme" };
_context.Add(newBrand);
await _context.SaveChangesAsync();
// read and update
var existingBrand = _context.CatalogBrands.Find(1);
existingBrand.Brand = "Updated Brand";
await _context.SaveChangesAsync();
// read and delete (alternate Find syntax)
var brandToDelete = _context.Find<CatalogBrand>(2);
_context.CatalogBrands.Remove(brandToDelete);
await _context.SaveChangesAsync();
EF Core supporta sia metodi sincroni che asincroni per il recupero e il salvataggio. Nelle applicazioni Web è consigliabile usare il modello asincrono/awaiter con i metodi asincroni. In questo modo i thread del server Web non saranno bloccati in attesa che le operazioni di accesso ai dati siano completate.
Per altre informazioni, vedere Buffering e streaming.
Recupero dei dati correlati
Dopo aver recuperato le entità, EF Core compila tutte le proprietà archiviate direttamente con l'entità appropriata nel database. Le proprietà di navigazione, ad esempio elenchi di entità correlate, non vengono popolate e il loro valore può essere impostato su Null. Questo assicura che EF Core non recuperi più dati del necessario, un requisito particolarmente importante per le applicazioni Web che devono elaborare velocemente le richieste e restituire le risposte in modo efficiente. Per includere le relazioni con un'entità tramite il caricamento eager, specificare la proprietà usando il metodo di estensione Include nella query, come illustrato di seguito:
// .Include requires using Microsoft.EntityFrameworkCore
var brandsWithItems = await _context.CatalogBrands
.Include(b => b.Items)
.ToListAsync();
È possibile includere più relazioni, ma anche relazioni secondarie usando ThenInclude. EF Core eseguirà una singola query per recuperare il set di entità ottenuto. In alternativa è possibile includere proprietà di navigazione di proprietà di navigazione passando una stringa separata da "." al metodo di estensione .Include(), come illustrato di seguito:
.Include("Items.Products")
Oltre a incapsulare la logica di filtro, una specifica può indicare la forma dei dati da restituire, incluse le proprietà da popolare. L'esempio eShopOnWeb include diverse specifiche che illustrano l'incapsulamento di informazioni di caricamento eager nella specifica. Di seguito è visualizzato un esempio d'uso della specifica come parte di una query:
// Includes all expression-based includes
query = specification.Includes.Aggregate(query,
(current, include) => current.Include(include));
// Include any string-based include statements
query = specification.IncludeStrings.Aggregate(query,
(current, include) => current.Include(include));
Il caricamento esplicito è un'altra opzione per caricare i dati correlati. Il caricamento esplicito consente di caricare dati aggiuntivi in un'entità che è già stata recuperata. Poiché questo approccio prevede una richiesta separata al database, non è consigliabile per le applicazioni Web, che devono ridurre al minimo il numero di round trip al database per ogni richiesta.
Il caricamento lazy è una funzionalità che consente di caricare automaticamente i dati correlati ai quali l'applicazione fa riferimento. EF Core ha aggiunto il supporto per il caricamento posticipato nella versione 2.1. Il caricamento posticipato non è abilitato per impostazione predefinita e richiede l'installazione di Microsoft.EntityFrameworkCore.Proxies. Come con il caricamento esplicito, il caricamento posticipato in genere deve essere disabilitato per le applicazioni Web poiché comporta delle query di database aggiuntive eseguite all'interno di ogni richiesta Web. Purtroppo, il sovraccarico generato dal caricamento posticipato spesso non viene rilevato in fase di sviluppo, quando la latenza è poca e spesso i set di dati usati per il test sono piccoli. Tuttavia nell'ambiente di produzione, con più utenti, più dati e latenza maggiore, le richieste di database aggiuntive spesso possono causare una riduzione delle prestazioni delle applicazioni Web che fanno largo uso del caricamento posticipato.
Avoid Lazy Loading Entities in Web Applications (Evitare il caricamento posticipato nelle applicazioni Web)
È consigliabile testare l'applicazione esaminando le effettive query di database che esegue. In determinate circostanze, EF Core può eseguire molte più query o una query più costosa di quanto sia ottimale per l'applicazione. Uno di questi problemi è noto come esplosione cartesiana. Tra i vari modi per ottimizzare il comportamento in fase di esecuzione, il team di EF Core mette a disposizione il metodo AsSplitQuery.
Incapsulamento dei dati
EF Core supporta diverse funzionalità che consentono al modello di incapsulare correttamente il proprio stato. Un problema comune nei modelli di dominio è che espongono le proprietà di navigazione della raccolta come tipi elenco accessibili pubblicamente. Ne consegue che i collaboratori possono modificare il contenuto di questi tipi di raccolta e ignorare importanti regole di business relative alla raccolta stessa, con il rischio di lasciare l'oggetto in uno stato non valido. La soluzione a questo problema è esporre l'accesso in sola lettura alle raccolte correlate e specificare in modo esplicito metodi che definiscono le modalità di modifica di queste raccolte da parte dei client, come nell'esempio seguente:
public class Basket : BaseEntity
{
public string BuyerId { get; set; }
private readonly List<BasketItem> _items = new List<BasketItem>();
public IReadOnlyCollection<BasketItem> Items => _items.AsReadOnly();
public void AddItem(int catalogItemId, decimal unitPrice, int quantity = 1)
{
var existingItem = Items.FirstOrDefault(i => i.CatalogItemId == catalogItemId);
if (existingItem == null)
{
_items.Add(new BasketItem()
{
CatalogItemId = catalogItemId,
Quantity = quantity,
UnitPrice = unitPrice
});
}
else existingItem.Quantity += quantity;
}
}
Questo tipo di entità non espone una proprietà List o ICollection pubblica, ma espone un tipo IReadOnlyCollection che esegue il wrapping del tipo List sottostante. Quando si usa questo criterio è possibile indicare a Entity Framework Core di usare il campo sottostante nel modo seguente:
private void ConfigureBasket(EntityTypeBuilder<Basket> builder)
{
var navigation = builder.Metadata.FindNavigation(nameof(Basket.Items));
navigation.SetPropertyAccessMode(PropertyAccessMode.Field);
}
Un altro approccio per il miglioramento del modello di dominio è l'uso di oggetti valore per i tipi che non dispongono di identità e si distinguono solo per le relative proprietà. L'uso di questi tipi come proprietà delle entità consente di mantenere la logica specifica per l'oggetto valore nella posizione appropriata, evitando duplicazioni di logica tra più entità che usano lo stesso concetto. In Entity Framework Core è possibile rendere persistenti gli oggetti valore nella stessa tabella dell'entità di appartenenza, configurando il tipo come entità di proprietà come illustrato di seguito:
private void ConfigureOrder(EntityTypeBuilder<Order> builder)
{
builder.OwnsOne(o => o.ShipToAddress);
}
In questo esempio la proprietà ShipToAddress è di tipo Address. Address è un oggetto valore con diverse proprietà, quali Street e City. Entity Framework Core esegue il mapping dell'oggetto Order alla relativa tabella con una sola colonna per ogni proprietà Address, facendo precedere al nome di ogni colonna il nome della proprietà. In questo esempio la tabella Order includerebbe colonne come ShipToAddress_Street e ShipToAddress_City. È anche possibile archiviare i tipi di proprietà in tabelle separate, se necessario.
Per altre informazioni, leggere l'articolo sul supporto delle entità di proprietà in EF Core.
Connessioni resilienti
In alcuni casi è possibile che le risorse esterne, ad esempio i database SQL, non siano disponibili. In caso di indisponibilità temporanea, le applicazioni possono usare la logica di ripetizione per evitare che sia generata un'eccezione. Questa tecnica è comunemente nota come resilienza della connessione. È possibile implementare i tentativi con backoff esponenziale , vale a dire una tecnica che tenta di ripetere un'operazione con un tempo di attesa che aumenta esponenzialmente, fino a quando non viene raggiunto il numero massimo di tentativi. Questa tecnica si basa sul presupposto che le risorse cloud potrebbero essere non disponibili in modo intermittente per brevi periodi, generando l'errore di alcune richieste.
Per il database SQL di Azure, Entity Framework Core fornisce già la logica per i tentativi e la resilienza della connessione di database interna. È tuttavia necessario abilitare la strategia di esecuzione di Entity Framework per ogni connessione DbContext per ottenere connessioni di EF Core resilienti.
Ad esempio, il codice seguente a livello della connessione di EF Core consente connessioni SQL resilienti per le quali vengono effettuati ulteriori tentativi in caso di mancata connessione.
builder.Services.AddDbContext<OrderingContext>(options =>
{
options.UseSqlServer(builder.Configuration["ConnectionString"],
sqlServerOptionsAction: sqlOptions =>
{
sqlOptions.EnableRetryOnFailure(
maxRetryCount: 5,
maxRetryDelay: TimeSpan.FromSeconds(30),
errorNumbersToAdd: null);
}
);
});
Strategie di esecuzione e transazioni esplicite usando BeginTransaction e più oggetti DbContext
Quando nelle connessioni di EF Core sono abilitati i tentativi, ogni operazione che viene eseguita con EF Core diventa un'unica operazione con possibilità di ritentare. Per ogni query e per ogni chiamata a SaveChangesAsync verranno eseguiti altri tentativi come una sola unità nel caso in cui si verifichi un errore temporaneo.
Se tuttavia il codice avvia una transazione tramite BeginTransaction, viene definito un gruppo di operazioni personalizzato che deve essere considerato come un'unità. Se si verifica un errore, verrà eseguito il rollback di tutto ciò che si trova all'interno della transazione. Se si prova a eseguire la transazione quando si usa una strategia di esecuzione (criteri di ripetizione) di EF e si includono numerosi oggetti SaveChangesAsync da più oggetti DbContext, verrà restituita un'eccezione simile alla seguente.
System.InvalidOperationException: la strategia di esecuzione configurata SqlServerRetryingExecutionStrategy non supporta le transazioni avviate dall'utente. Usare la strategia di esecuzione restituita da DbContext.Database.CreateExecutionStrategy() per eseguire tutte le operazioni nella transazione come un'unità con possibilità di ritentare.
La soluzione prevede di richiamare manualmente la strategia di esecuzione di EF con un delegato che rappresenta tutte le operazioni che devono essere eseguite. Se si verifica un errore temporaneo, la strategia di esecuzione chiamerà nuovamente il delegato. Nel codice seguente viene illustrato come implementare questo approccio:
// Use of an EF Core resiliency strategy when using multiple DbContexts
// within an explicit transaction
// See:
// https://learn.microsoft.com/ef/core/miscellaneous/connection-resiliency
var strategy = _catalogContext.Database.CreateExecutionStrategy();
await strategy.ExecuteAsync(async () =>
{
// Achieving atomicity between original Catalog database operation and the
// IntegrationEventLog thanks to a local transaction
using (var transaction = _catalogContext.Database.BeginTransaction())
{
_catalogContext.CatalogItems.Update(catalogItem);
await _catalogContext.SaveChangesAsync();
// Save to EventLog only if product price changed
if (raiseProductPriceChangedEvent)
{
await _integrationEventLogService.SaveEventAsync(priceChangedEvent);
transaction.Commit();
}
}
});
Il primo oggetto DbContext è _catalogContext e il secondo si trova all'interno dell'oggetto _integrationEventLogService. Alla fine, l'azione Commit viene eseguita su più oggetti DbContext tramite una strategia di esecuzione di EF.
Riferimenti a Entity Framework Core
- Documentazione di Entity Frameworkhttps://learn.microsoft.com/ef/
- Entity Framework Core: dati correlatihttps://learn.microsoft.com/ef/core/querying/related-data
- Avoid Lazy Loading Entities in ASP.NET Applicationshttps://ardalis.com/avoid-lazy-loading-entities-in-asp-net-applications (Evitare il caricamento lazy di entità in applicazioni ASPNET)
EF Core o micro ORM?
EF Core è un'ottima soluzione per la gestione della persistenza. In pratica incapsula i dettagli del database dagli sviluppatori dell'applicazione. Non è tuttavia l'unica possibilità. Esiste un'alternativa open source molto diffusa denominata Dapper. Si tratta di un micro ORM. Un micro ORM è uno strumento semplice e meno completo per il mapping di oggetti in strutture di dati. Nel caso di Dapper, è stato progettato per focalizzarsi sulle prestazioni, anziché sul completo incapsulamento delle query sottostanti usate per recuperare e aggiornare i dati. Poiché non estrae le istruzioni SQL dallo sviluppatore, Dapper è un prodotto CTM (close to the meta) e consente agli sviluppatori di scrivere le query esatte da usare per una determinata operazione di accesso ai dati.
EF Core offre due importanti funzionalità che lo distinguono da Dapper ma che al tempo stesso gravano sulle prestazioni. La prima è la conversione di espressioni LINK in SQL. Queste conversioni vengono memorizzate nella cache. Ciononostante, la prima volta che vengono eseguite si verifica un sovraccarico delle prestazioni. La seconda funzionalità importante è il rilevamento delle modifiche nelle entità. In questo modo è possibile generare istruzioni di aggiornamento in modo efficiente. Questo comportamento può essere disattivato per query specifiche tramite l'estensione AsNoTracking. EF Core genera anche query SQL che sono generalmente molto efficienti e in ogni caso perfettamente accettabili dal punto di vista delle prestazioni. Se è tuttavia necessario eseguire un controllo dettagliato sulla query specifica, è anche possibile passare un'istruzione SQL personalizzata (o eseguire una stored procedure) tramite EF Core. In questo caso, le prestazioni offerte da Dapper sono di poco più elevate rispetto a EF Core. Dati di benchmark aggiornati sulle prestazioni di una serie di metodi di accesso ai dati sono disponibili sul sito di Dapper.
Per conoscere le diversità in termini di sintassi tra Dapper ed EF Core, considerare queste due versioni dello stesso metodo per recuperare un elenco di elementi:
// EF Core
private readonly CatalogContext _context;
public async Task<IEnumerable<CatalogType>> GetCatalogTypes()
{
return await _context.CatalogTypes.ToListAsync();
}
// Dapper
private readonly SqlConnection _conn;
public async Task<IEnumerable<CatalogType>> GetCatalogTypesWithDapper()
{
return await _conn.QueryAsync<CatalogType>("SELECT * FROM CatalogType");
}
Per compilare oggetti grafici più complessi con Dapper, è necessario scrivere le query associate. Non è invece possibile aggiungere un oggetto Include come EF Core prevede. Questa funzionalità è supportata mediante diverse sintassi, tra cui una funzione denominata Multi Mapping, che consente di eseguire il mapping di singole righe su più oggetti con mapping. Ad esempio, data una classe Post con una proprietà Owner di tipo User, l'istruzione SQL seguente restituirà tutti i dati necessari:
select * from #Posts p
left join #Users u on u.Id = p.OwnerId
Order by p.Id
Ogni riga restituita include i dati sia di User sia di Post. Poiché i dati di User sono collegati ai dati di Post tramite la proprietà Owner, è necessario usare la funzione seguente:
(post, user) => { post.Owner = user; return post; }
Il listato di codice completo per restituire una raccolta di oggetti Post con la proprietà Owner popolata e i dati di User associati sarà il seguente:
var sql = @"select * from #Posts p
left join #Users u on u.Id = p.OwnerId
Order by p.Id";
var data = connection.Query<Post, User, Post>(sql,
(post, user) => { post.Owner = user; return post;});
Poiché Dapper offre una capacità di incapsulamento ridotta, è necessario che gli sviluppatori sappiano come archiviare i dati, eseguire una query sui dati in modo efficiente e scrivere altro codice per recuperare i dati. Quando viene modificato il modello, anziché creare semplicemente una nuova migrazione (un'altra funzionalità di EF Core) e/o aggiornare le informazioni di mapping in un unico punto di un oggetto DbContext, è necessario aggiornare tutte le query interessate. Queste query non offrono garanzie in fase di compilazione, pertanto possono interrompersi durante l'esecuzione in risposta alle modifiche al modello o al database, compromettendo il rilevamento rapido degli errori. A fronte di questi compromessi, Dapper offre prestazioni molto elevate.
Per la maggior parte delle applicazioni e per molte parti di quasi tutte le applicazioni, le prestazioni di EF Core risultano accettabili. Di conseguenza, i vantaggi offerti agli sviluppatori dal punto della produttività superano il relativo sovraccarico delle prestazioni. Per le query che usano la memorizzazione nella cache, la query effettiva può essere eseguita in brevissimo tempo. In questi casi le differenze in termini di prestazioni di query si riducono e diventano discutibili.
SQL o NoSQL
I database relazionali, ad esempio SQL Server, hanno tradizionalmente dominato il mercato in termini di archiviazione dei dati persistenti, ma non sono l'unica soluzione disponibile. I database NoSQL come MongoDB offrono un approccio diverso per l'archiviazione degli oggetti. Anziché eseguire il mapping di oggetti in tabelle e righe, è possibile serializzare l'intero oggetto grafico e memorizzare il risultato. I vantaggi di questo approccio sono, almeno inizialmente, le prestazioni e la semplicità. È più semplice archiviare un singolo oggetto serializzato con una chiave, rispetto a decomporre l'oggetto in molte tabelle con relazioni e aggiornare le righe che potrebbero essere state modificate dall'ultima volta in cui l'oggetto è stato recuperato dal database. Analogamente, il recupero e la deserializzazione di un singolo oggetto da un archivio basato su chiavi è in genere molto più veloce e più semplice rispetto all'uso di join complessi o più query di database necessari per comporre completamente lo stesso oggetto da un database relazionale. La mancanza di blocchi, transazioni o di uno schema fisso rende i database NoSQL anche particolarmente adatti ai fini della scalabilità su molti computer e dunque al supporto di set di dati di grandi dimensioni.
Di contro, nei comunemente detti database NoSQL non mancano gli svantaggi. Nei database relazionali viene applicata la normalizzazione per garantire coerenza ed evitare la duplicazione dei dati. Questo approccio riduce le dimensioni totali del database e assicura che gli aggiornamenti ai dati condivisi siano immediatamente disponibili in tutto il database. In un database relazionale è possibile che una tabella Address faccia riferimento a una tabella Country usando l'ID, in modo che se il nome di un paese/area geografica è stato modificato, i record relativi agli indirizzi possano usare l'aggiornamento senza dover essere a loro volta aggiornati. In un database NoSQL, la tabella Address e la relativa tabella Country associata potrebbero essere invece serializzate come parte di molti oggetti archiviati. Per poter aggiornare il nome del paese o dell'area geografica è necessario aggiornare tutti questi oggetti anziché una sola riga. I database relazionali possono anche garantire l'integrità relazionale tramite l'applicazione di regole, come le chiavi esterne. I database NoSQL non offrono solitamente vincoli di questo genere sui dati.
Un altro aspetto complesso che i database NoSQL devono gestire è il controllo delle versioni. Quando le proprietà di un oggetto vengono modificate, non è possibile eseguire la deserializzazione degli oggetti dalle versioni precedenti in cui sono archiviati. Di conseguenza, è necessario aggiornare tutti gli oggetti esistenti con una versione (precedente) serializzata dell'oggetto per rispettare il nuovo schema. Questo approccio concettualmente non è diverso da quanto accade in un database relazionale dove, in seguito a modifiche allo schema, è talvolta necessario aggiornare script e mapping. Spesso però il numero delle modifiche da apportare in un database NoSQL è molto più elevato, in quanto è necessaria una maggiore duplicazione dei dati.
Nei database NoSQL è possibile archiviare più versioni di oggetti, requisito che non è solitamente supportato dai database relazionali a schema fisso. In questo caso però il codice dell'applicazione deve tenere conto dell'esistenza delle versioni precedenti degli oggetti, aumentando così la complessità.
In genere nei database NoSQL non vengono applicate le ACID, vale a dire che sono vantaggiosi rispetto ai database relazionali in termini sia di prestazioni che di scalabilità. Sono database ideali per set di dati e oggetti di dimensioni molto grandi, che non sono particolarmente adatti per essere archiviati in strutture tabella normalizzate. Non esiste un motivo per cui un'applicazione non possa usare sia i database relazionali sia i database NoSQL a seconda dell'utilità.
Azure Cosmos DB
Azure Cosmos DB è un servizio di database NoSQL completamente gestito che offre l'archiviazione di dati privi di schema basata sul cloud. Azure Cosmos DB garantisce prestazioni rapide e prevedibili, disponibilità elevata, scalabilità elastica e distribuzione globale. Nonostante sia un database NoSQL, gli sviluppatori possono applicare le note funzionalità avanzate di query SQL su dati JSON. Tutte le risorse in Azure Cosmos DB vengono archiviate come documenti JSON. Le risorse sono gestite come elementi, vale a dire documenti che contengono metadati, e come feed, ovvero raccolte di elementi. La figura 8-2 illustra la relazione tra le diverse risorse di Azure Cosmos DB.
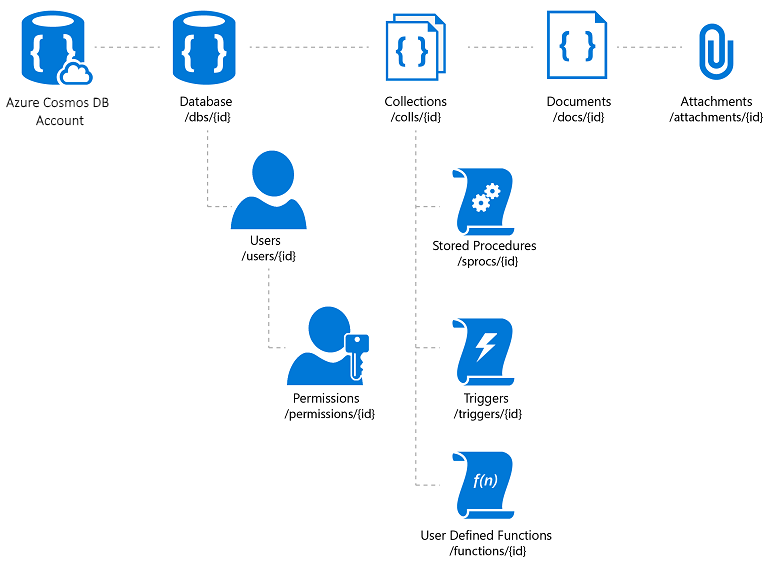
Figura 8-2. Organizzazione delle risorse di Azure Cosmos DB.
Il linguaggio di query di Azure Cosmos DB è un'interfaccia semplice ma potente per l'esecuzione di query su documenti JSON. Il linguaggio supporta un sottoinsieme della grammatica SQL ANSI e aggiunge un'integrazione profonda di oggetti JavaScript, matrici, costruzione di oggetti e chiamata di funzioni.
Riferimenti - Azure Cosmos DB
- Introduzione ad Azure Cosmos DB https://learn.microsoft.com/azure/cosmos-db/introduction
Altre opzioni di persistenza
Oltre alle opzioni di archiviazione con database relazionali e NoSQL, le applicazioni ASP.NET Core possono usare Archiviazione di Azure per archiviare una varietà di formati di dati e file in una modalità scalabile e basata sul cloud. L'archiviazione di Azure è altamente scalabile. È quindi possibile iniziare archiviando piccole quantità di dati per poi aumentare l'archiviazione a centinaia di terabyte, se richiesto dall'applicazione. L'archiviazione di Azure supporta quattro tipi di dati:
Archiviazione BLOB per l'archiviazione di testo non strutturato o dati binari, detta anche archiviazione di oggetti.
Archiviazione tabelle per set di dati strutturati, accessibile tramite chiavi di riga.
Archiviazione code per messaggistica affidabile basata su coda.
Archiviazione file per l'accesso a file condivisi tra macchine virtuali di Azure e applicazioni locali.
Riferimenti ad archiviazione di Azure
- Introduzione ad Archiviazione di Azure https://learn.microsoft.com/azure/storage/common/storage-introduction
Memorizzazione nella cache
Nelle applicazioni Web è necessario che ogni richiesta Web sia completata nel minor tempo possibile. Un modo per raggiungere questo obiettivo è limitare il numero di chiamate esterne che il server deve effettuare per completare la richiesta. La memorizzazione nella cache comporta l'archiviazione di una copia di dati nel server, vale a dire un altro archivio dati che può essere sottoposto a query più facilmente rispetto all'origine dei dati. Le applicazioni Web, soprattutto le applicazioni Web tradizionali non SPA, devono compilare l'intera interfaccia utente con ogni richiesta. Con questo approccio, spesso molte delle stesse query sul database vengono eseguite ripetutamente tra una richiesta utente e quella successiva. Nella maggior parte dei casi i dati raramente cambiano. Non c'è quindi motivo di richiederli costantemente dal database. ASP.NET Core supporta la memorizzazione nella cache delle risposte, per le pagine intere, e la memorizzazione nella cache dei dati, che consente un comportamento di memorizzazione nella cache più granulare.
Quando si implementa la memorizzazione nella cache, è importante considerare i concetti in modo separato. Non implementare la logica della memorizzazione nella cache nella logica di accesso ai dati o nell'interfaccia utente. Incapsulare invece la memorizzazione nella cache nelle classi e usare la configurazione per gestirne il comportamento. Questo approccio segue i principi di aperto/chiuso (OCP) e di singola responsabilità (SRP) e renderà più facile gestire l'uso della memorizzazione nella cache nell'applicazione man mano che cresce.
Memorizzazione nella cache delle risposte di ASP.NET Core
ASP.NET Core supporta due livelli di memorizzazione nella cache delle risposte. Il primo livello non memorizza tutto nella cache nel server, ma aggiunge le intestazioni HTTP che indicano ai client e ai server proxy di memorizzare le risposte nella cache. Questa funzionalità si implementa aggiungendo l'attributo ResponseCache ai singoli controller o azioni:
[ResponseCache(Duration = 60)]
public IActionResult Contact()
{
ViewData["Message"] = "Your contact page.";
return View();
}
L'esempio precedente comporterà l'aggiunta della seguente intestazione alla risposta, indicando ai client di memorizzare nella cache il risultato fino a 60 secondi.
Cache-Control: public,max-age=60
Per aggiungere la memorizzazione nella cache in memoria sul lato server per l'applicazione, è necessario fare riferimento al pacchetto NuGet Microsoft.AspNetCore.ResponseCaching e quindi aggiungere il middleware di memorizzazione nella cache delle risposte. Questo middleware viene configurato con servizi e middleware durante l'avvio dell'app:
builder.Services.AddResponseCaching();
// other code omitted, including building the app
app.UseResponseCaching();
Il middleware di memorizzazione nella cache delle risposte memorizzerà autenticamente le risposte sulla base di una serie di condizioni personalizzabili. Per impostazione predefinita, vengono memorizzate nella cache solo risposte con codice di stato 200 (OK) tramite i metodi GET o HEAD. È anche necessario che le richieste abbiano una risposta con intestazione pubblica Cache-Control e non includano le intestazioni Authorization o Set-Cookie. Vedere l'elenco completo delle condizioni di memorizzazione nella cache usato dal middleware di memorizzazione nella cache delle risposte.
Memorizzazione dei dati nella cache
Anziché memorizzare nella cache tutte le risposte Web oppure oltre ad abilitare tale funzionalità, è possibile memorizzare nella cache i risultati delle singole query sui dati. A questo scopo è possibile usare la memorizzazione nella cache in memoria nel server Web oppure una cache distribuita. In questa sezione sarà illustrato come implementare la memorizzazione nella cache in memoria.
Aggiungere il supporto per la memorizzazione nella cache in memoria (o distribuita) con il codice seguente:
builder.Services.AddMemoryCache();
builder.Services.AddMvc();
Assicurarsi di aggiungere anche il pacchetto NuGet Microsoft.Extensions.Caching.Memory.
Dopo aver aggiunto il servizio, si inviano richieste IMemoryCache tramite l'inserimento di dipendenze ogni volta che è necessario accedere alla cache. In questo esempio CachedCatalogService usa lo schema progettuale Proxy (o Decorator), offrendo un'implementazione alternativa di ICatalogService che controlla l'accesso (o aggiunge un comportamento) all'implementazione di CatalogService sottostante.
public class CachedCatalogService : ICatalogService
{
private readonly IMemoryCache _cache;
private readonly CatalogService _catalogService;
private static readonly string _brandsKey = "brands";
private static readonly string _typesKey = "types";
private static readonly TimeSpan _defaultCacheDuration = TimeSpan.FromSeconds(30);
public CachedCatalogService(
IMemoryCache cache,
CatalogService catalogService)
{
_cache = cache;
_catalogService = catalogService;
}
public async Task<IEnumerable<SelectListItem>> GetBrands()
{
return await _cache.GetOrCreateAsync(_brandsKey, async entry =>
{
entry.SlidingExpiration = _defaultCacheDuration;
return await _catalogService.GetBrands();
});
}
public async Task<Catalog> GetCatalogItems(int pageIndex, int itemsPage, int? brandID, int? typeId)
{
string cacheKey = $"items-{pageIndex}-{itemsPage}-{brandID}-{typeId}";
return await _cache.GetOrCreateAsync(cacheKey, async entry =>
{
entry.SlidingExpiration = _defaultCacheDuration;
return await _catalogService.GetCatalogItems(pageIndex, itemsPage, brandID, typeId);
});
}
public async Task<IEnumerable<SelectListItem>> GetTypes()
{
return await _cache.GetOrCreateAsync(_typesKey, async entry =>
{
entry.SlidingExpiration = _defaultCacheDuration;
return await _catalogService.GetTypes();
});
}
}
Per configurare l'applicazione in modo che usi la versione del servizio memorizzata nella cache, ma consentire comunque al servizio di ottenere l'istanza di CatalogService necessaria nel relativo costruttore, aggiungere le righe di codice seguenti in Program.cs:
builder.Services.AddMemoryCache();
builder.Services.AddScoped<ICatalogService, CachedCatalogService>();
builder.Services.AddScoped<CatalogService>();
Con questo codice, le chiamate al database per recuperare i dati del catalogo verranno eseguite una sola volta al minuto anziché a ogni richiesta. In base al traffico del sito, questa configurazione può avere un impatto significativo sul numero di query eseguite sul database e sul tempo medio di caricamento della home page che attualmente dipende da tutte e tre le query esposte da questo servizio.
Quando viene implementata la memorizzazione nella cache si verifica un problema correlato ai dati non aggiornati , vale a dire i dati che sono stati modificati nell'origine, ma di cui nella cache è rimasta una versione non aggiornata. Un modo semplice per risolvere questo problema è usare durate della cache ridotte. Infatti, per un'applicazione occupata il vantaggio aggiuntivo di estendere la durata di memorizzazione nella cache dei dati è limitato. Si consideri ad esempio una pagina che esegue un'unica query al database, richiedendola 10 volte al secondo. Se questa pagina rimane memorizzata nella cache per un minuto, il numero di query al database ogni minuto diminuirà da 600 a 1, pari a una riduzione del 99,8%. Se invece la durata della cache fosse di un'ora, la riduzione complessiva sarebbe del 99,997%, ma in questo caso la probabilità e la potenziale durata dei dati non aggiornati aumenterebbero considerevolmente.
Un altro approccio consiste nel rimuovere in modo proattivo le voci della cache quando vengono aggiornati i dati in esse contenuti. È possibile rimuovere ogni singola voce se si conosce la relativa chiave:
_cache.Remove(cacheKey);
Se l'applicazione espone la funzionalità per l'aggiornamento delle voci memorizzate nella cache, è possibile rimuovere le voci della cache corrispondenti nel codice che esegue gli aggiornamenti. In alcuni casi potrebbero esistere numerose voci diverse che dipendono da un set di dati specifico. In questo caso può essere utile creare dipendenze tra le voci della cache, usando un oggetto CancellationChangeToken, che consente di annullare la validità di più voci della cache in una sola volta, annullando il token.
// configure CancellationToken and add entry to cache
var cts = new CancellationTokenSource();
_cache.Set("cts", cts);
_cache.Set(cacheKey, itemToCache, new CancellationChangeToken(cts.Token));
// elsewhere, expire the cache by cancelling the token\
_cache.Get<CancellationTokenSource>("cts").Cancel();
La memorizzazione nella cache può migliorare notevolmente le prestazioni delle pagine Web che richiedono più volte gli stessi valori dal database. Assicurarsi di misurare le prestazioni di accesso ai dati e delle pagine prima di applicare la memorizzazione nella cache e applicarla solo dove si ritiene sia necessario un miglioramento. La memorizzazione nella cache consuma le risorse di memoria del server Web e aumenta la complessità dell'applicazione, pertanto è importante non eseguire anzitempo l'ottimizzazione con questa tecnica.
Recupero dei dati per le app BlazorWebAssembly
Se si creano app che usano Blazor Server, è possibile usare Entity Framework e le altre tecnologie di accesso diretto ai dati illustrate finora in questo capitolo. Tuttavia, quando si creano app BlazorWebAssembly, come per altri framework per applicazioni a pagina singola è necessaria una strategia di accesso ai dati diversa. In genere queste applicazioni accedono ai dati e interagiscono con il server tramite endpoint di API Web.
Se i dati o le operazioni eseguite sono sensibili, assicurarsi di esaminare la sezione sulla sicurezza nel capitolo precedente e proteggere le API dagli accessi non autorizzati.
Un esempio di BlazorWebAssembly app è disponibile nell'applicazione di riferimento eShopOnWeb, nel progetto BlazorAdmin. Questo progetto è ospitato all'interno del progetto Web eShopOnWeb e consente agli utenti del gruppo Administrators di gestire gli articoli nel negozio. La figura 8-3 contiene screenshot dell'applicazione.
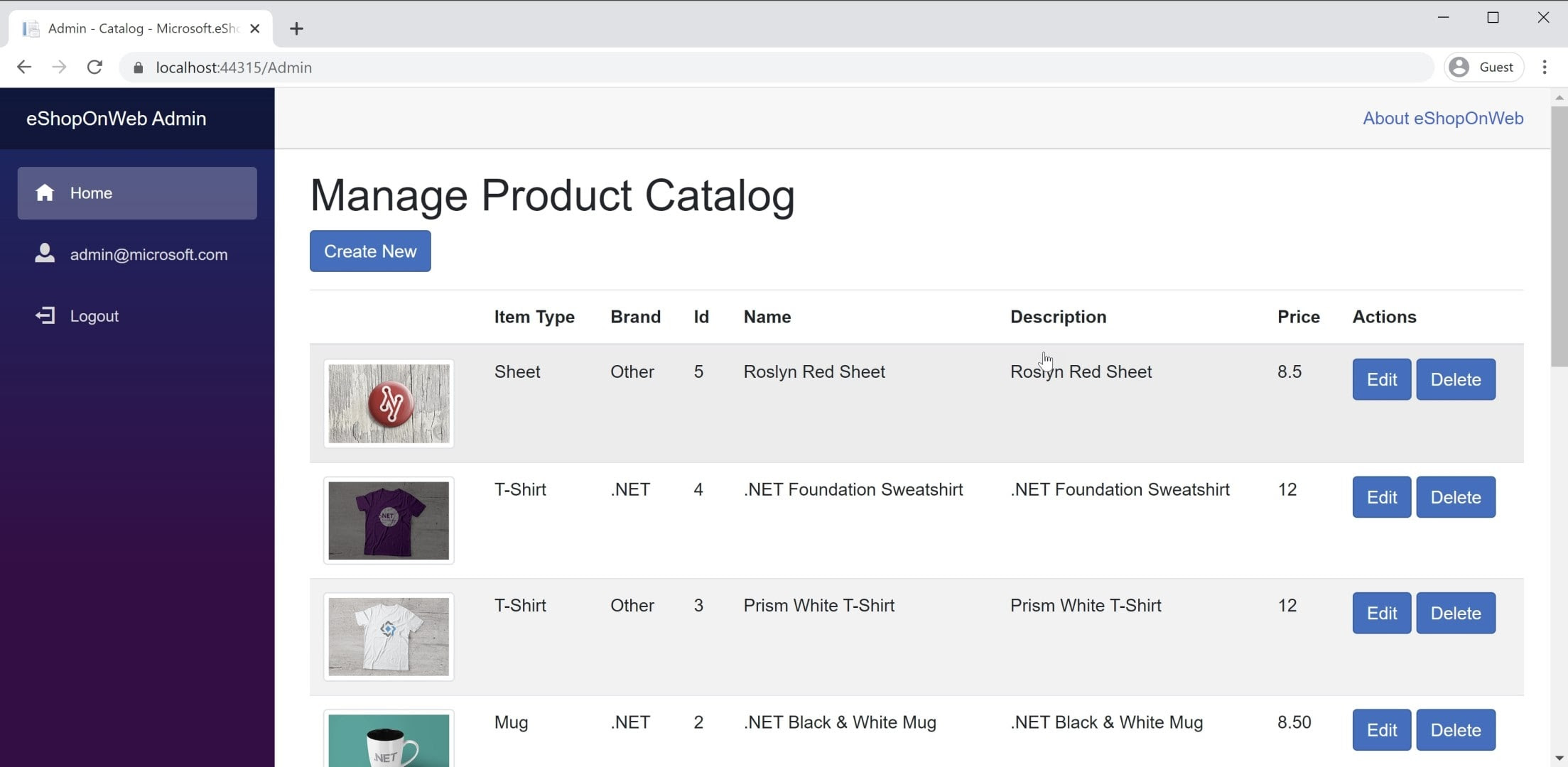
Figura 8-3. Screenshot del catalogo eShopOnWeb Admin.
Quando si recuperano dati dalle API Web all'interno di un'app BlazorWebAssembly è sufficiente usare un'istanza di HttpClient, come in qualsiasi applicazione .NET. I passaggi di base sono la creazione della richiesta da inviare (se necessario, in genere per le richieste POST o PUT), l'attesa della richiesta stessa, la verifica del codice di stato e la deserializzazione della risposta. Se si prevede di effettuare molte richieste a un determinato set di API, è consigliabile incapsulare le API e configurare l'indirizzo di base HttpClient in modo centralizzato. In questo modo, se è necessario modificare una qualunque di queste impostazioni tra gli ambienti, è possibile apportare le modifiche in un'unica posizione. È consigliabile aggiungere il supporto per questo servizio in Program.Main:
builder.Services.AddScoped(sp => new HttpClient
{
BaseAddress = new Uri(builder.HostEnvironment.BaseAddress)
});
Se è necessario accedere ai servizi in modo sicuro, è necessario accedere a un token sicuro e configurare HttpClient in modo da passare questo token come intestazione di autenticazione insieme a ogni richiesta:
_httpClient.DefaultRequestHeaders.Authorization =
new AuthenticationHeaderValue("Bearer", token);
Questa attività può essere eseguita da qualsiasi componente in cui sia stato inserito HttpClient, purché HttpClient non sia stato aggiunto ai servizi dell'applicazione con una durata Transient. Ogni riferimento a HttpClient nell'applicazione fa riferimento alla stessa istanza, quindi le modifiche che vi vengono apportate in un componente si propagano all'intera applicazione. Un buon punto per eseguire questa verifica dell'autenticazione, seguita dalla specifica del token, è all'interno di un componente condiviso come la struttura di spostamento principale del sito. Altre informazioni su questo approccio sono disponibili nel progetto BlazorAdmin, nell'applicazione di riferimento eShopOnWeb.
Uno dei vantaggi offerti da BlazorWebAssembly rispetto alle applicazioni a pagina singola JavaScript tradizionali è che non è necessario mantenere sincronizzate le copie degli oggetti di trasferimento dati (DTO). Il progetto BlazorWebAssembly e il progetto di API Web possono condividere gli stessi DTO in un progetto condiviso comune. Questo approccio elimina alcune delle complicazioni associate allo sviluppo di applicazioni a pagina singola.
Per ottenere rapidamente i dati da un endpoint API, è possibile usare il metodo helper predefinito GetFromJsonAsync. Esistono metodi simili per POST, PUT e così via. L'esempio seguente mostra come ottenere un oggetto CatalogItem da un endpoint API usando un HttpClient configurato in un'app BlazorWebAssembly:
var item = await _httpClient.GetFromJsonAsync<CatalogItem>($"catalog-items/{id}");
Dopo aver ottenuto i dati necessari, in genere si terrà traccia delle modifiche in locale. Per apportare aggiornamenti all'archivio dati di back-end, si chiameranno API Web aggiuntive.
Riferimenti - Dati Blazor
- Chiamare un'API Web da ASP.NET Core Blazorhttps://learn.microsoft.com/aspnet/core/blazor/call-web-api