Progettare il livello di persistenza dell'infrastruttura
Suggerimento
Questo contenuto è un estratto dell'eBook "Microservizi .NET: Architettura per le applicazioni .NET incluse in contenitori", disponibile in .NET Docs o come PDF scaricabile gratuitamente e da poter leggere offline.

I componenti di persistenza dei dati forniscono l'accesso ai dati ospitati nell’ambito dei limiti di un microservizio (vale a dire, il database di un microservizio). Contengono l'implementazione effettiva di componenti come repository e classi di unità di lavoro, ad esempio gli oggetti Entity Framework (EF) DbContext personalizzati. DbContext di Entity Framework implementa sia il criterio Repository che il criterio Unit of Work.
The Repository pattern (Lo schema Repository)\
Il criterio Repository è uno schema progettuale basato su dominio ideato per mantenere problemi di persistenza al di fuori del modello di dominio del sistema. Una o più astrazioni di persistenza, ovvero interfacce, sono definite nel modello di dominio e tali astrazioni presentano implementazioni sotto forma di adapter specifici per la persistenza definiti altrove nell'applicazione.
Le implementazioni del repository sono classi che incapsulano la logica necessaria per accedere alle origini dati. Centralizzano la funzionalità di accesso ai dati comuni, migliorando la manutenibilità e il disaccoppiamento dell'infrastruttura o della tecnologia usata per accedere ai database dal livello del modello di dominio. Se si usa un Object-Relational Mapper (ORM) come Entity Framework, il codice da implementare viene semplificato grazie a LINQ e alla tipizzazione forte. In questo modo è possibile concentrarsi sulla logica di persistenza dei dati anziché sulle attività di plumbing per l'accesso ai dati.
Lo schema Repository è una modalità di utilizzo di un'origine dati ben documentata. Nel libro Patterns of Enterprise Application Architecture, Martin Fowler descrive un repository come segue:
Un repository esegue le attività di intermediario tra i livelli del modello di dominio e il mapping dei dati, agendo in modo analogo a un set di oggetti di dominio in memoria. Gli oggetti client compilare query in modo dichiarativo e le inviano ai repository per le risposte. Concettualmente, un repository incapsula un set di oggetti archiviati nel database e le operazioni che possono essere eseguite sugli oggetti stessi, offrendo un modo che più si avvicina al livello di persistenza. I repository, inoltre, supportano lo scopo di separare chiaramente e in una sola direzione la dipendenza tra il dominio di lavoro e l'allocazione o il mapping dei dati.
Definire un repository per ogni aggregazione
Per ogni aggregazione o radice di aggregazione è necessario creare una classe di repository. È possibile sfruttare i generics C# per ridurre il numero totale di classi concrete da gestire (come illustrato più avanti in questo capitolo). In un microservizio che si basa su schemi progettuali basati su dominio (DDD, Domain-Driven Design), l'unico canale che è necessario usare per aggiornare il database deve essere il repository, Questo perché presentano una relazione uno-a-uno con la radice di aggregazione, che controlla le invarianti di aggregazione e la coerenza delle transazioni. È possibile eseguire query sul database tramite altri canali (seguendo un approccio CQRS), perché le query non modificano lo stato del database. Tuttavia, l'area transazionale, ovvero gli aggiornamenti, deve sempre essere controllata dai repository e dalle radici di aggregazione.
In pratica, un repository consente di popolare i dati in memoria che provengono dal database sotto forma di entità di dominio. Quando le entità sono in memoria, è possibile modificarle e quindi salvarle in modo permanente nel database tramite le transazioni.
Come notato in precedenza, se si usa lo schema architetturale CQS/CQRS, le query iniziali verranno eseguite da query secondarie all'esterno del modello di dominio, eseguite da semplici istruzioni SQL con Dapper. Questo approccio è molto più flessibile dei repository perché è possibile eseguire query e join di tutte le tabelle necessarie, e tali query non sono limitate da regole dalle aggregazioni. Tali dati verranno inviati al livello di presentazione o all'app client.
Se l'utente apporta modifiche, i dati da aggiornare proverranno dal livello di presentazione o dall'app client al livello di applicazione (ad esempio, un servizio Web API). Quando si riceve un comando in un gestore dei comandi, usare i repository per ottenere i dati da aggiornare dal database. È possibile aggiornarli in memoria con i dati passati con i comandi e quindi aggiungere o aggiornare i dati (entità di dominio) nel database tramite una transazione.
È importante sottolineare di nuovo che è consigliabile definire un solo repository per ogni radice di aggregazione, come illustrato nella figura 7-17. Per raggiungere l'obiettivo della radice dell'aggregazione per mantenere la coerenza delle transazioni tra tutti gli oggetti all'interno dell'aggregazione, è consigliabile non creare mai un repository per ogni tabella nel database.
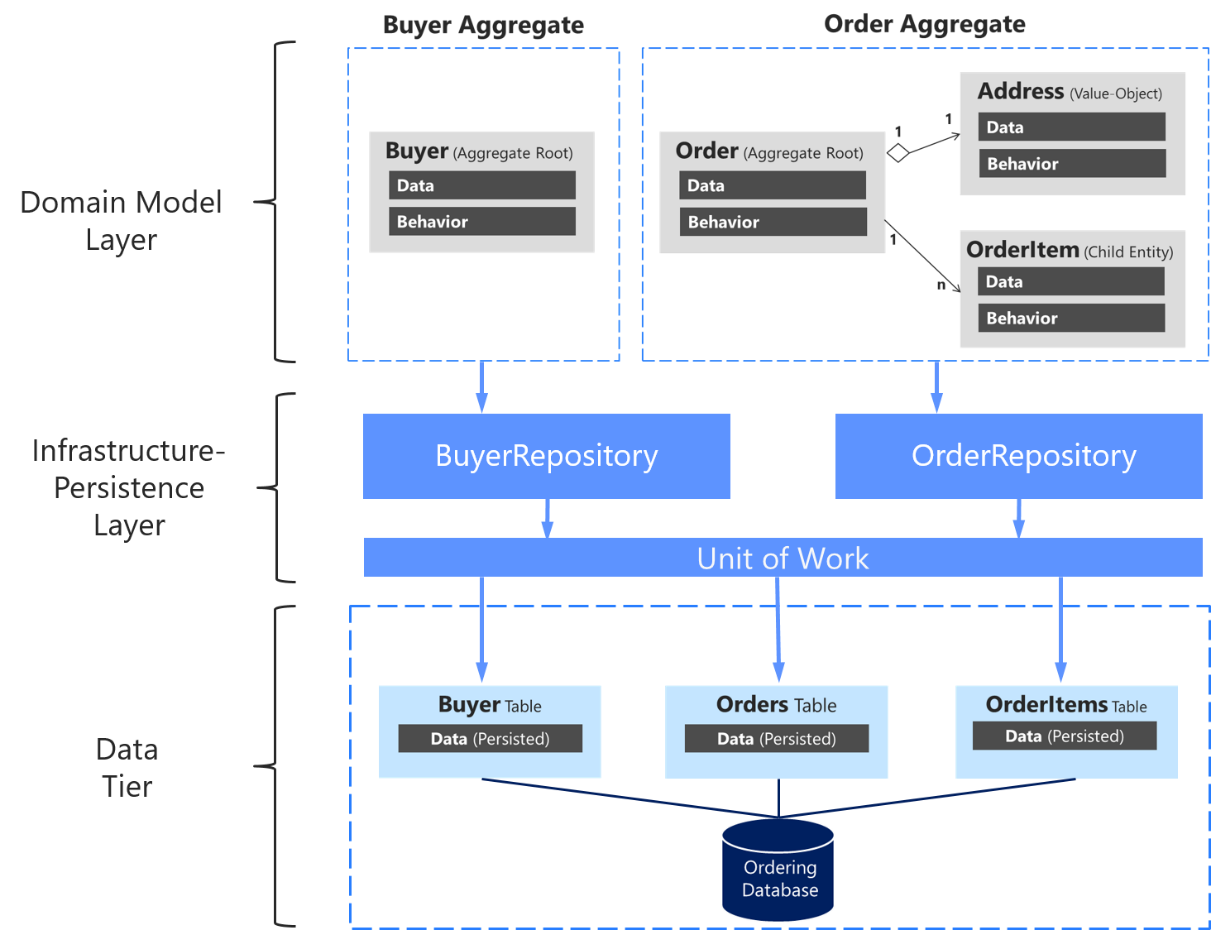
Figura 7-17. Relazione tra repository, aggregazioni e tabelle del database
Il diagramma di cui sopra mostra le relazioni tra i livelli di infrastruttura e di dominio: l'aggregazione Buyer dipende da IBuyerRepository e l'aggregazione Order dipende dalle interfacce IOrderRepository. Tali interfacce vengono implementate nel livello di infrastruttura dai repository corrispondenti che dipendono da UnitOfWork, implementato anch'esso qui, che accede alle tabelle nel livello Dati.
Applicare una radice di aggregazione per ogni repository
Può essere utile per implementare la progettazione del repository in modo che venga applicata la regola che solo le radici di aggregazione devono contenere repository. È possibile creare un tipo di repository generico o di base che limita il tipo di entità usate per assicurarsi di avere l'interfaccia dei marcatori IAggregateRoot.
Di conseguenza, ogni classe di repository implementata a livello infrastruttura implementa il proprio contratto o interfaccia, come illustrato nel codice seguente:
namespace Microsoft.eShopOnContainers.Services.Ordering.Infrastructure.Repositories
{
public class OrderRepository : IOrderRepository
{
// ...
}
}
Ogni interfaccia specifica del repository implementa l'interfaccia IRepository generica:
public interface IOrderRepository : IRepository<Order>
{
Order Add(Order order);
// ...
}
Tuttavia, un modo migliore perché il codice applichi la convenzione secondo cui ogni repository è correlato a un singolo aggregato consiste nell'implementare un tipo di repository generico. In questo modo è evidente che si sta usando un repository per un aggregato specifico. A tale scopo, è possibile implementare un'interfaccia di base IRepository generica, come illustrato nel codice seguente:
public interface IRepository<T> where T : IAggregateRoot
{
//....
}
Lo schema Repository rende più semplice testare la logica dell'applicazione
Lo schema Repository consente di testare facilmente l'applicazione con gli unit test. Tenere presente che gli unit test testano solo il codice, non l'infrastruttura, in modo che le astrazioni dei repository consentono di raggiungere più facilmente tale obiettivo.
Come indicato in una sezione precedente, è consigliabile definire e inserire le interfacce di repository nel livello del modello di dominio in modo tale che il livello dell'applicazione, come un microservizio API Web, non dipenda direttamente dal livello infrastruttura in cui sono state implementate le classi di repository effettive. In questo modo e grazie all'uso dell'inserimento di dipendenze nei controller dell'API Web, è possibile implementare repository fittizi che restituiscono dati falsi anziché i dati del database. Questo approccio disaccoppiato consente di creare ed eseguire unit test concentrati sulla logica dell'applicazione senza richiedere la connettività al database.
Le connessioni ai database possono non riuscire e, cosa ancora più importante, l'esecuzione di centinaia di test in un database è sconsigliata per due motivi. In primo luogo, può richiedere molto tempo a causa dell'elevato numero di test. In secondo luogo, i record del database possono cambiare e influire sui risultati dei test, soprattutto se i test sono in esecuzione in parallelo, in modo tale che possono non essere coerenti. Gli unit test in genere possono essere eseguiti in parallelo; i test di integrazione potrebbero non supportare l'esecuzione parallela a seconda dell'implementazione. I test sui database non sono unit test, ma test di integrazione. È consigliabile avere molti unit test che vengono eseguiti rapidamente ma pochi test di integrazione sui database.
In termini di separazione delle problematiche per gli unit test, la logica opera sulle entità di dominio in memoria. Si presuppone che la classe di repository abbia usato queste ultime. Una volta che la logica modifica le entità di dominio, si presuppone che la classe di repository le archivi in modo corretto. Il punto importante consiste nel creare unit test su un modello di dominio e la relativa logica di dominio. Le radici di aggregazione sono i limiti principali della coerenza in DDD.
I repository implementati in eShopOnContainers si basano sull'implementazione di DbContext di Entity Framework Core dei criteri Repository e Unit of Work che usano il rilevamento delle modifiche, in modo che questa funzionalità non venga duplicata.
Differenza tra lo schema Repository e lo schema legacy Data Access class (DAL class)
Un tipico oggetto DAL esegue direttamente operazioni di persistenza e accesso ai dati in relazione all'archiviazione, spesso a livello di una singola tabella e riga. Le semplici operazioni CRUD implementate con un set di classi DAL spesso non supportano le transazioni (anche se non sempre). La maggior parte degli approcci relativi alle classi DAL presenta un uso minimo delle astrazioni, con conseguente accoppiamento stretto tra l’applicazione o le classi BLL (Business Logic Layer) che chiamano gli oggetti DAL.
Quando si usa il repository, i dettagli di implementazione della persistenza vengono incapsulati allontanandoli dal modello di dominio. L'uso di un'astrazione offre facilità di estensione del comportamento tramite criteri come Decorator o Proxy. Ad esempio, i problemi trasversali come la memorizzazione nella cache, la registrazione e la gestione degli errori, possono essere applicati usando questi criteri anziché hardcoded nel codice di accesso ai dati stesso. È inoltre semplice supportare più adapter di repository che possono essere usati in ambienti diversi, da quelli di sviluppo locale agli ambienti di gestione temporanea condivisi alla produzione.
Implementazione Unit of Work
Per unità di lavoro si intende una singola transazione che coinvolge più operazioni di inserimento, aggiornamento o eliminazione. In altre parole, per un'azione utente specifica, ad esempio la registrazione in un sito Web, tutte le operazioni di inserimento, aggiornamento ed eliminazione vengono gestite in un'unica transazione. Questa procedura è più efficiente rispetto alla gestione di più operazioni relative al database in maniera più frammentata.
Queste varie operazioni di persistenza vengono eseguite in un secondo momento in un'unica azione quando indicato dal codice a livello dell'applicazione. La decisione sull'applicazione delle modifiche in memoria all'archiviazione effettiva dei database si basa in genere sullo schema Unit of Work. In Entity Framework, il criterio Unit of Work viene implementato da un DbContext e viene eseguito quando viene effettuata una chiamata a SaveChanges.
In molti casi, questo schema o il modo di applicare le operazioni nell'archivio può migliorare le prestazioni dell'applicazione riducendo il rischio di incoerenze. Inoltre, riduce il blocco delle transazioni nelle tabelle del database, perché il commit di tutte le operazioni previste viene eseguito come parte di un'unica transazione. Questo approccio è molto più efficiente rispetto all'esecuzione di molte operazioni isolate sul database. Pertanto, l'ORM selezionato è in grado di ottimizzare l'esecuzione nel database raggruppando le varie azioni di aggiornamento all'interno della stessa transazione, anziché eseguire più transazioni separate di dimensioni inferiori.
Il criterio Unit of Work può essere implementato con o senza usare il criterio Repository.
I repository non devono essere obbligatori
I repository personalizzati sono utili per i motivi citati in precedenza e rappresentano l'approccio usato per il microservizio degli ordini in eShopOnContainers. Tuttavia, non è uno schema essenziale da implementare in una progettazione DDD o persino nello sviluppo generale in .NET.
Ad esempio, Jimmy Bogard, quando ha fornito un feedback diretto per questa guida, ha affermato quanto segue:
Questo probabilmente sarà il feedback più importante. Non sono proprio un fan dei repository, soprattutto perché nascondono i dettagli importanti del meccanismo di persistenza sottostante. Questo è anche il motivo per cui usare MediatR per i comandi. È possibile sfruttare tutte le potenzialità del livello di persistenza e spostare tutto il comportamento del dominio nelle radici di aggregazione. In genere non si vogliono simulare i repository ma avere un test di integrazione con il componente reale. Usare CQRS comporta che i repository non sono più necessari.
I repository possono essere utili ma non sono fondamentali per la progettazione DDD come lo sono il criterio Aggregate e il criterio di dominio avanzato. Pertanto, usare lo schema Repository se si ritiene opportuno.
Risorse aggiuntive
Schema Repository
Edward Hieatt and Rob Mee. Repository pattern (Schema Repository).\
https://martinfowler.com/eaaCatalog/repository.htmlThe Repository pattern (Lo schema Repository)\
https://learn.microsoft.com/previous-versions/msp-n-p/ff649690(v=pandp.10)Eric Evans. Domain-Driven Design: Tackling Complexity in the Heart of Software (Progettazione basata su domini: gestire le complessità nel software). (Libro; include una discussione sullo schema repository)
https://www.amazon.com/Domain-Driven-Design-Tackling-Complexity-Software/dp/0321125215/
Schema Unit of Work
Martin Fowler. Unit of Work pattern (Schema Unit of Work).\
https://martinfowler.com/eaaCatalog/unitOfWork.htmlImplementazione dei modelli con repository e unità di lavoro in un'applicazione MVC ASP.NET
https://learn.microsoft.com/aspnet/mvc/overview/older-versions/getting-started-with-ef-5-using-mvc-4/implementing-the-repository-and-unit-of-work-patterns-in-an-asp-net-mvc-application