Gestire gli errori parziali
Suggerimento
Questo contenuto è un estratto dell'eBook "Microservizi .NET: Architettura per le applicazioni .NET incluse in contenitori", disponibile in .NET Docs o come PDF scaricabile gratuitamente e da poter leggere offline.

Nei sistemi distribuiti, come le applicazioni basate su microservizi, esiste sempre un rischio di errori parziali. Ad esempio, può verificarsi un errore in un singolo microservizio/contenitore oppure questo potrebbe non essere disponibile per rispondere per un breve periodo di tempo oppure può verificarsi un arresto anomalo di una macchina virtuale o di un server. Poiché i client e i servizi sono processi separati, un servizio potrebbe non riuscire a rispondere tempestivamente a una richiesta del client. Il servizio potrebbe essere sovraccarico e rispondere molto lentamente alle richieste oppure potrebbe semplicemente non essere accessibile per un breve periodo di tempo a causa di problemi di rete.
Si consideri ad esempio la pagina dei dettagli dell'ordine dell'applicazione di esempio eShopOnContainers. Se il microservizio degli ordini non risponde quando l'utente tenta di inviare un ordine, un'implementazione non corretta del processo client (l'applicazione Web MVC), se ad esempio il codice client usasse RPC sincrone senza timeout, bloccherebbe i thread a tempo indefinito in attesa di una risposta. Oltre a creare un'esperienza utente non corretta, ogni attesa senza risposta usa o blocca un thread e i thread sono estremamente preziosi nelle applicazioni a scalabilità elevata. Se molti thread sono bloccati, il runtime dell'applicazione alla fine li esaurirà. In questo caso l'applicazione potrebbe non rispondere a livello globale anziché solo parzialmente, come illustrato nella figura 8-1.
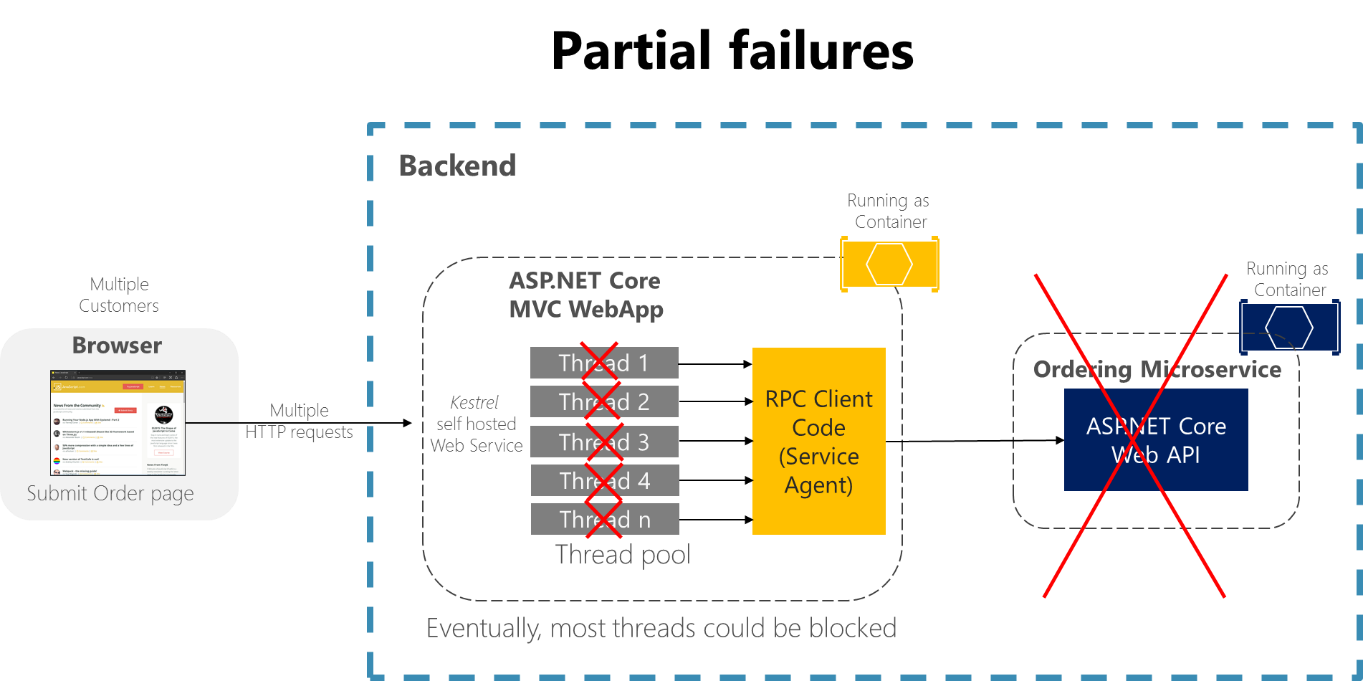
Figura 8-1. Errori parziali dovuti a dipendenze che influiscono sulla disponibilità dei thread del servizio
In applicazioni basate su microservizi di grandi dimensioni, ogni errore parziale può risultare amplificato, in particolare se la maggior parte dell'interazione tra i microservizi interni è basata su chiamate HTTP sincrone (scenario definito come antipattern). Si pensi a un sistema che riceve milioni di chiamate in ingresso al giorno. Se il sistema presenta una progettazione insufficiente basata su lunghe catene di chiamate HTTP sincrone, le chiamate in ingresso potrebbero generare molti milioni di chiamate in uscita (si supponga un rapporto 1:4), a dozzine di microservizi interni come dipendenze sincrone. Questa situazione è illustrata nella figura 8-2, in particolare la dipendenza n. 3, che avvia una catena, chiamando la dipendenza n. 4, che chiama quindi #5.
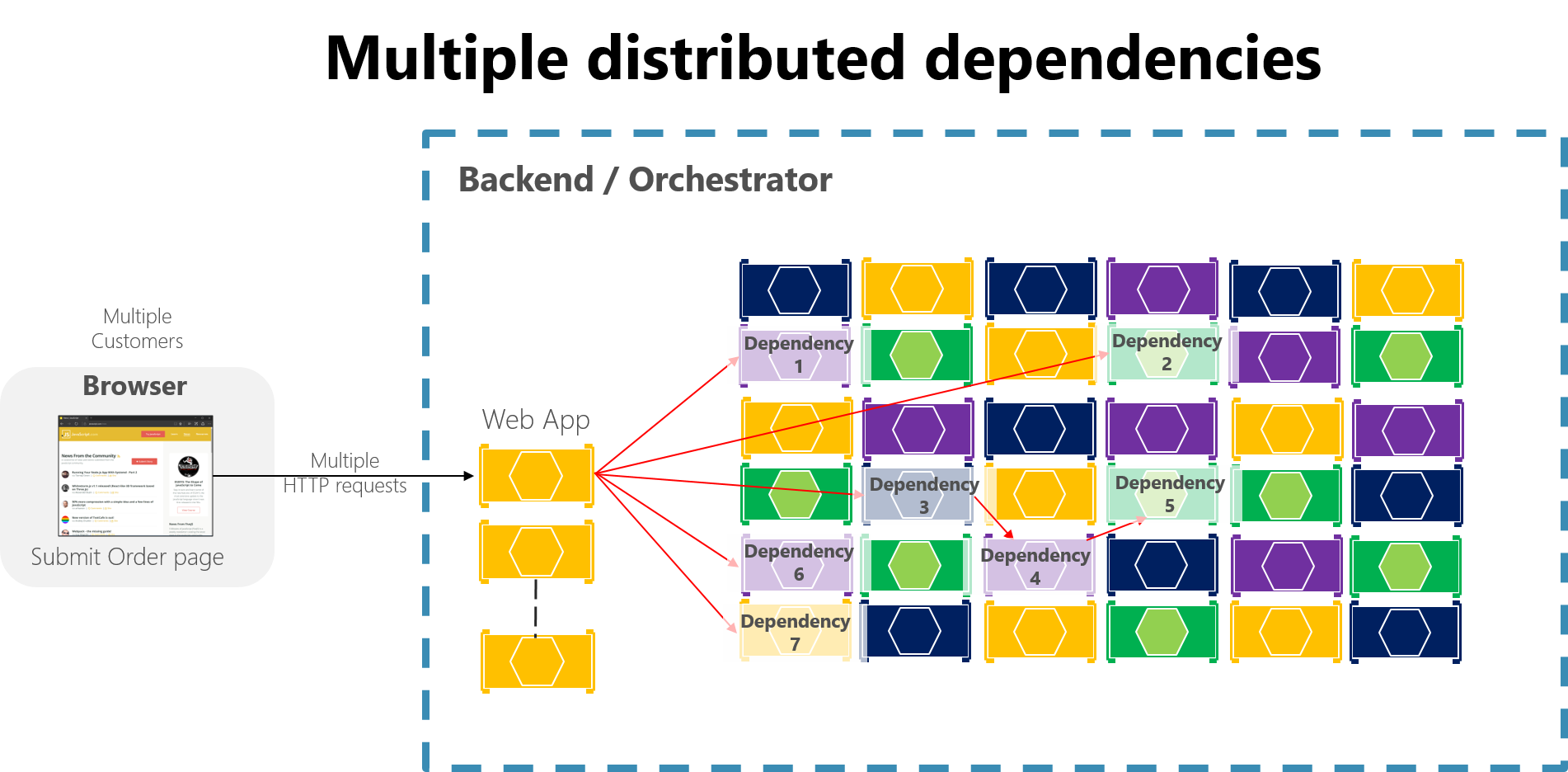
Figura 8-2. L'impatto di una progettazione non corretta che prevede lunghe catene di richieste HTTP
L'errore intermittente è garantito in un sistema distribuito basato sul cloud, anche se ogni dipendenza presenta una disponibilità eccellente. Questo è un aspetto da prendere in considerazione.
Se non si progettano e implementano tecniche in grado di garantire la tolleranza di errore, anche brevi periodi di inattività possono risultare amplificati. Ad esempio, 50 dipendenze ognuna con una disponibilità del 99,99% genererebbero diverse ore di inattività al mese a causa dell'effetto domino. Quando si verifica un errore nella dipendenza di un microservizio durante la gestione di un volume elevato di richieste, l'errore può saturare velocemente tutti i thread delle richieste disponibili in ogni servizio e determinare un arresto anomalo dell'intera applicazione.
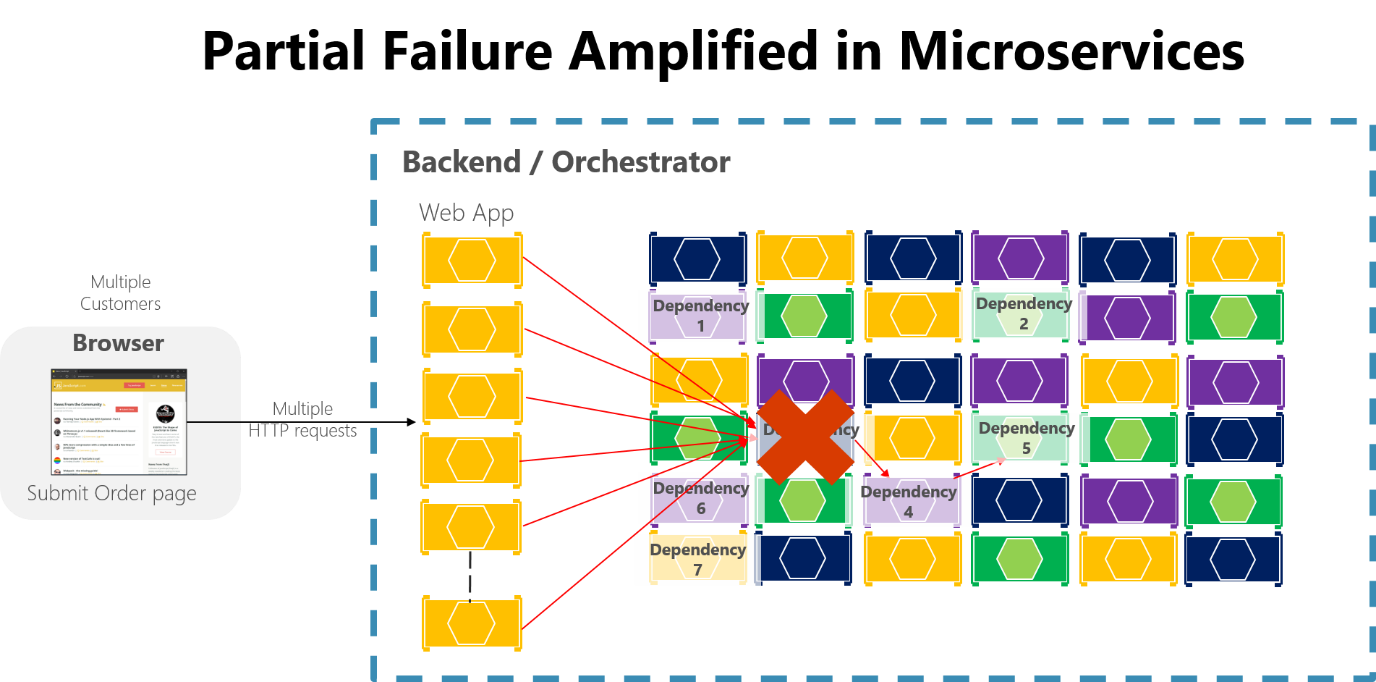
Figura 8-3. Errore parziale amplificato da microservizi con lunghe catene di chiamate HTTP sincrone
Per ridurre al minimo l'impatto del problema, nella sezione L'integrazione di microservizi asincroni impone l'autonomia del microservizio viene consigliato l'uso della comunicazione asincrona tra i microservizi interni.
È anche essenziale progettare i microservizi e le applicazioni client per la gestione degli errori parziali, ovvero creare microservizi e applicazioni client resilienti.