Test di spostamento a sinistra con unit test
Il test garantisce che il codice venga eseguito come previsto, ma il tempo e il lavoro richiesto per compilare i test richiede tempo da altre attività, ad esempio lo sviluppo di funzionalità. Con questo costo, è importante estrarre il valore massimo dai test. Questo articolo illustra i principi di test di DevOps, concentrandosi sul valore di unit test e su una strategia di test a sinistra di spostamento.
Tester dedicati usati per scrivere la maggior parte dei test e molti sviluppatori di prodotti non hanno imparato a scrivere unit test. La scrittura di test può sembrare troppo difficile o troppo lavoro. Ci può essere scetticismo sul funzionamento di una strategia di unit test, esperienze negative con unit test non scritti correttamente o paura che gli unit test sostituiranno i test funzionali.

Per implementare una strategia di test DevOps, essere pragmatici e concentrati sulla creazione di slancio. Anche se è possibile insistere sugli unit test per il nuovo codice o il codice esistente che può essere sottoposto a refactoring pulito, potrebbe essere utile per una codebase legacy per consentire alcune dipendenze. Se parti significative del codice prodotto usano SQL, consentendo agli unit test di dipendere dal provider di risorse SQL invece di simulare tale livello potrebbe essere un approccio a breve termine allo stato di avanzamento.
Man mano che le organizzazioni DevOps maturano, diventa più facile per la leadership migliorare i processi. Anche se potrebbe esserci qualche resistenza al cambiamento, le organizzazioni Agile valutano le modifiche che pagano chiaramente i dividendi. Dovrebbe essere facile vendere la visione di esecuzioni di test più veloci con un minor numero di errori, perché significa più tempo investire nella generazione di nuovo valore tramite lo sviluppo di funzionalità.
Tassonomia dei test devOps
La definizione di una tassonomia di test è un aspetto importante del processo di test DevOps. Una tassonomia di test DevOps classifica i singoli test in base alle dipendenze e il tempo necessario per l'esecuzione. Gli sviluppatori devono comprendere i tipi corretti di test da usare in scenari diversi e quali test richiedono parti diverse del processo. La maggior parte delle organizzazioni classifica i test in quattro livelli:
- I test L0 e L1 sono unit test o test che dipendono dal codice nell'assembly sottoposto a test e nient'altro. L0 è un'ampia classe di unit test veloci in memoria.
- L2 sono test funzionali che potrebbero richiedere l'assembly più altre dipendenze, ad esempio SQL o il file system.
- I test funzionali L3 vengono eseguiti su distribuzioni di servizi testabili. Questa categoria di test richiede una distribuzione del servizio, ma potrebbe usare gli stub per le dipendenze del servizio chiave.
- I test L4 sono una classe limitata di test di integrazione eseguiti nell'ambiente di produzione. I test L4 richiedono una distribuzione completa del prodotto.
Anche se sarebbe consigliabile che tutti i test vengano eseguiti in qualsiasi momento, non è fattibile. Teams può selezionare la posizione in cui eseguire ogni test nel processo DevOps e usare strategie shift-left o shift-right per spostare diversi tipi di test in precedenza o versioni successive nel processo.
Ad esempio, l'aspettativa potrebbe essere che gli sviluppatori eseguono sempre i test L2 prima del commit, una richiesta pull ha esito negativo automaticamente se l'esecuzione del test L3 ha esito negativo e la distribuzione potrebbe essere bloccata se i test L4 hanno esito negativo. Le regole specifiche possono variare dall'organizzazione all'organizzazione, ma l'applicazione delle aspettative per tutti i team all'interno di un'organizzazione sposta tutti verso gli stessi obiettivi di visione di qualità.
Linee guida per unit test
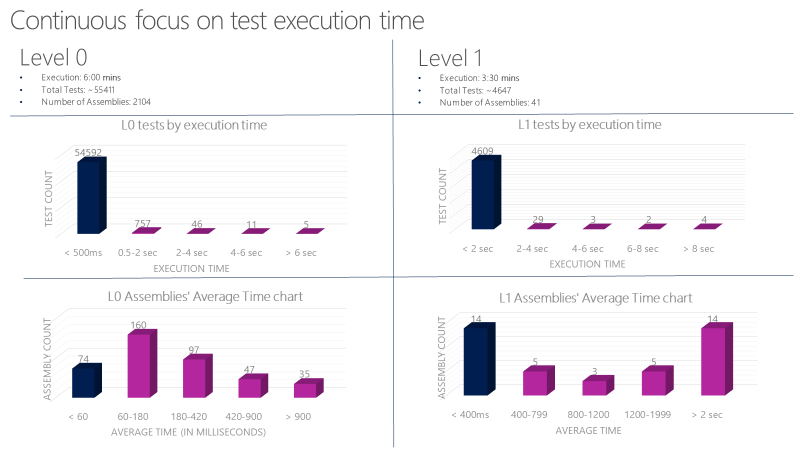
Impostare linee guida rigorose per gli unit test L0 e L1. Questi test devono essere molto veloci e affidabili. Ad esempio, il tempo medio di esecuzione per ogni test L0 in un assembly deve essere inferiore a 60 millisecondi. Il tempo di esecuzione medio per ogni test L1 in un assembly deve essere inferiore a 400 millisecondi. Nessun test a questo livello deve superare 2 secondi.
Un team Microsoft esegue più di 60.000 unit test in parallelo in meno di sei minuti. Il loro obiettivo è ridurre questo tempo a meno di un minuto. Il team tiene traccia del tempo di esecuzione degli unit test con strumenti come il grafico seguente e registra bug sui test che superano il tempo consentito.
Linee guida per i test funzionali
I test funzionali devono essere indipendenti. Il concetto chiave per i test L2 è l'isolamento. I test isolati correttamente possono essere eseguiti in modo affidabile in qualsiasi sequenza, perché hanno il controllo completo sull'ambiente in cui vengono eseguiti. Lo stato deve essere noto all'inizio del test. Se un test ha creato dati e lo ha lasciato nel database, potrebbe danneggiare l'esecuzione di un altro test che si basa su uno stato del database diverso.
I test legacy che richiedono un'identità utente potrebbero aver chiamato provider di autenticazione esterni per ottenere l'identità. Questa pratica presenta diverse sfide. La dipendenza esterna potrebbe non essere affidabile o non disponibile momentaneamente, interrompendo il test. Questa pratica viola anche il principio di isolamento dei test, perché un test potrebbe modificare lo stato di un'identità, ad esempio l'autorizzazione, causando uno stato predefinito imprevisto per altri test. Valutare la possibilità di prevenire questi problemi investendo nel supporto delle identità all'interno del framework di test.
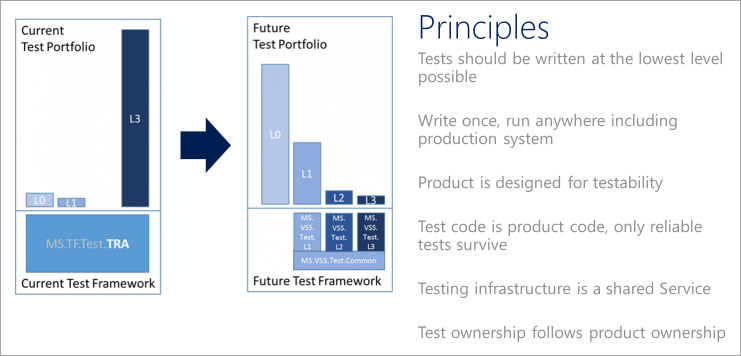
Principi di test devOps
Per facilitare la transizione di un portfolio di test ai processi DevOps moderni, articolato una visione di qualità. I team devono rispettare i principi di test seguenti quando si definisce e implementa una strategia di test DevOps.
Spostarsi a sinistra per testare in precedenza
L'esecuzione dei test può richiedere molto tempo. Con la scalabilità dei progetti, i numeri di test e i tipi aumentano notevolmente. Quando i gruppi di test aumentano per il completamento di ore o giorni, possono spingere più lontano fino a quando non vengono eseguiti all'ultimo momento. I vantaggi della qualità del codice dei test non vengono realizzati fino a quando non viene eseguito il commit del codice.
I test a esecuzione prolungata possono anche produrre errori che richiedono molto tempo per l'analisi. Teams può creare una tolleranza per gli errori, soprattutto nelle fasi iniziali degli sprint. Questa tolleranza compromette il valore dei test come informazioni dettagliate sulla qualità della codebase. I test a esecuzione prolungata aggiungono anche imprevedibilità alle aspettative end-of-sprint, perché è necessario pagare una quantità sconosciuta di debito tecnico per ottenere il codice spedibile.
L'obiettivo dello spostamento a sinistra dei test è spostare la qualità a monte eseguendo attività di test in precedenza nella pipeline. Grazie a una combinazione di miglioramenti di test e processi, lo spostamento a sinistra riduce sia il tempo necessario per l'esecuzione dei test che l'impatto degli errori più avanti nel ciclo. Lo spostamento a sinistra garantisce che la maggior parte dei test venga completata prima che una modifica venga unione nel ramo principale.
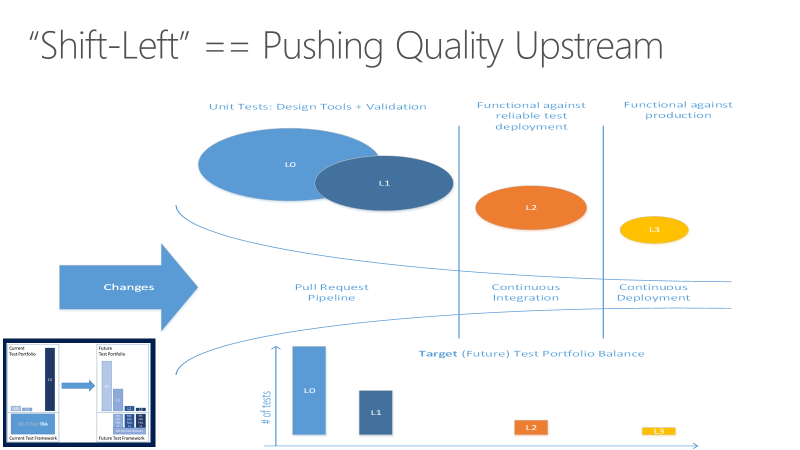
Oltre a spostare determinate responsabilità di test lasciate per migliorare la qualità del codice, i team possono spostare altri aspetti di test a destra o in un secondo momento nel ciclo DevOps, per migliorare il prodotto finale. Per altre informazioni, vedere Shift right to test in production.For more information, see Shift right to test in production.
Scrivere test al livello più basso possibile
Scrivere altri unit test. Favorire i test con le dipendenze esterne più poche e concentrarsi sull'esecuzione della maggior parte dei test nell'ambito della compilazione. Si consideri un sistema di compilazione parallelo in grado di eseguire unit test per un assembly non appena l'assembly e i test associati vengono eseguiti. Non è possibile testare ogni aspetto di un servizio a questo livello, ma il principio consiste nell'usare unit test più leggeri se possono produrre gli stessi risultati dei test funzionali più pesanti.
Obiettivo dell'affidabilità dei test
Un test inaffidabile è dispendioso dall'organizzazione per la manutenzione. Tale test funziona direttamente contro l'obiettivo di efficienza di progettazione rendendo difficile apportare modifiche con fiducia. Gli sviluppatori dovrebbero essere in grado di apportare modifiche ovunque e ottenere rapidamente fiducia che nulla sia stato interrotto. Mantenere una barra alta per l'affidabilità. Scoraggiare l'uso dei test dell'interfaccia utente, perché tendono ad essere inaffidabili.
Scrivere test funzionali che possono essere eseguiti ovunque
I test possono usare punti di integrazione specializzati progettati specificamente per abilitare i test. Una ragione per questa pratica è una mancanza di testbilità nel prodotto stesso. Sfortunatamente, i test come questi spesso dipendono dalle conoscenze interne e usano i dettagli di implementazione che non sono importanti dal punto di vista del test funzionale. Questi test sono limitati agli ambienti con i segreti e la configurazione necessari per eseguire i test, che in genere esclude le distribuzioni di produzione. I test funzionali devono usare solo l'API pubblica del prodotto.
Progettare prodotti per la verificabilità
Le organizzazioni in un processo DevOps maturo prendono una visione completa del significato di offrire un prodotto di qualità a cadenza cloud. Lo spostamento dell'equilibrio fortemente a favore di unit test rispetto ai test funzionali richiede ai team di effettuare scelte di progettazione e implementazione che supportano la testabilità. Esistono idee diverse su ciò che costituisce codice ben progettato e ben implementato per la testabilità, proprio come esistono stili di codifica diversi. Il principio è che la progettazione per la verificabilità deve diventare una parte principale della discussione sulla progettazione e sulla qualità del codice.
Considerare il codice di test come codice prodotto
Dichiarando in modo esplicito che il codice di test è codice prodotto, è chiaro che la qualità del codice di test è importante per la spedizione come quella del codice prodotto. I team devono trattare il codice di test allo stesso modo in cui trattano il codice del prodotto e applicare lo stesso livello di attenzione alla progettazione e all'implementazione di test e framework di test. Questo sforzo è simile alla gestione della configurazione e dell'infrastruttura come codice. Per essere completato, una revisione del codice deve considerare il codice di test e tenerlo nella stessa barra di qualità del codice prodotto.
Usare l'infrastruttura di test condivisa
Abbassare la barra per l'uso dell'infrastruttura di test per generare segnali di qualità attendibili. Visualizzare i test come servizio condiviso per l'intero team. Archiviare il codice di unit test insieme al codice prodotto e compilarlo con il prodotto. Anche i test eseguiti come parte del processo di compilazione devono essere eseguiti con strumenti di sviluppo come Azure DevOps. Se i test possono essere eseguiti in ogni ambiente dallo sviluppo locale all'ambiente di produzione, hanno la stessa affidabilità del codice prodotto.
Rendere i proprietari del codice responsabili dei test
Il codice di test deve trovarsi accanto al codice prodotto in un repository. Per testare il codice in corrispondenza di un limite di componente, eseguire il push della responsabilità per il test alla persona che scrive il codice del componente. Non fare affidamento su altri utenti per testare il componente.
Case study: Sposta a sinistra con unit test
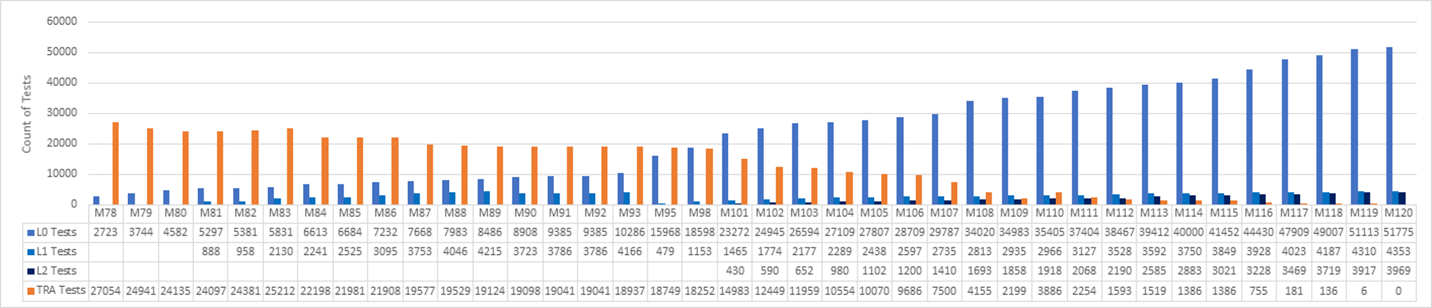
Un team Microsoft ha deciso di sostituire i gruppi di test legacy con unit test moderni, DevOps e un processo di spostamento a sinistra. Il team ha monitorato lo stato di avanzamento tra sprint triweekly, come illustrato nel grafico seguente. Il grafico illustra gli sprint da 78 a 120, che rappresenta 42 sprint su 126 settimane o circa due anni e mezzo di lavoro.
Il team ha iniziato a 27K test legacy nello sprint 78 e ha raggiunto zero test legacy a S120. Un set di unit test L0 e L1 ha sostituito la maggior parte dei test funzionali precedenti. I nuovi test L2 hanno sostituito alcuni dei test e molti dei vecchi test sono stati eliminati.
In un percorso software che richiede più di due anni per completare, c'è molto da imparare dal processo stesso. Nel complesso, lo sforzo di ripetere completamente il sistema di test nel corso di due anni è stato un enorme investimento. Non tutti i team di funzionalità hanno eseguito il lavoro contemporaneamente. Molti team dell'organizzazione hanno investito tempo in ogni sprint e in alcuni sprint è stata la maggior parte delle operazioni eseguite dal team. Anche se è difficile misurare il costo del turno, era un requisito non negoziabile per gli obiettivi di qualità e prestazioni del team.
Attività iniziali
All'inizio, il team ha lasciato i vecchi test funzionali, chiamati test TRA, da soli. Il team voleva che gli sviluppatori acquistano l'idea di scrivere unit test, in particolare per le nuove funzionalità. L'obiettivo è stato quello di rendere più semplice possibile la creazione di test L0 e L1. Il team ha bisogno di sviluppare prima tale capacità e di costruire slancio.
Il grafico precedente mostra il numero di unit test che iniziano ad aumentare in anticipo, perché il team ha visto il vantaggio della creazione di unit test. Gli unit test sono stati più facili da gestire, più veloci da eseguire e hanno avuto meno errori. È stato facile ottenere supporto per l'esecuzione di tutti gli unit test nel flusso di richiesta pull.
Il team non si è concentrato sulla scrittura di nuovi test L2 fino allo sprint 101. Nel frattempo, il conteggio dei test TRA è sceso da 27.000 a 14.000 da Sprint 78 a Sprint 101. I nuovi unit test hanno sostituito alcuni dei test TRA, ma molti sono stati semplicemente eliminati, in base all'analisi del team della loro utilità.
I test TRA sono passati da 2100 a 3800 nello sprint 110 perché sono stati individuati altri test nell'albero di origine e aggiunti al grafico. Si è scoperto che i test erano sempre stati in esecuzione, ma non venivano rilevati correttamente. Questa non era una crisi, ma era importante essere onesti e rivalutare in base alle esigenze.
Ottenere più velocemente
Una volta che il team ha avuto un segnale di integrazione continua (CI) che era estremamente veloce e affidabile, è diventato un indicatore attendibile per la qualità del prodotto. Lo screenshot seguente mostra la richiesta pull e la pipeline CI in azione e il tempo necessario per eseguire varie fasi.
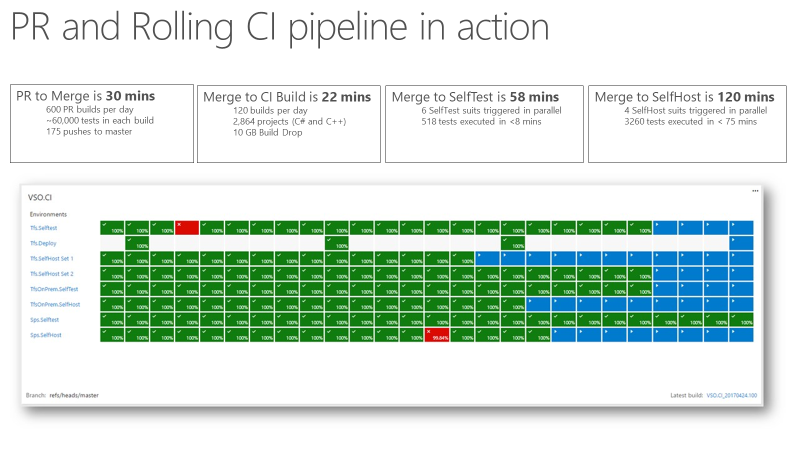
L'esecuzione di 60.000 unit test richiede circa 30 minuti, tra cui l'esecuzione di 60.000 unit test. Dall'unione del codice alla compilazione CI sono circa 22 minuti. Il primo segnale di qualità di CI, SelfTest, arriva dopo circa un'ora. Quindi, la maggior parte del prodotto viene testata con la modifica proposta. Entro due ore da Merge a SelfHost, l'intero prodotto viene testato e la modifica è pronta per essere inserita nell'ambiente di produzione.
Uso delle metriche
Il team tiene traccia di una scorecard come nell'esempio seguente. A livello generale, la scorecard tiene traccia di due tipi di metriche: Integrità o debito e velocità.
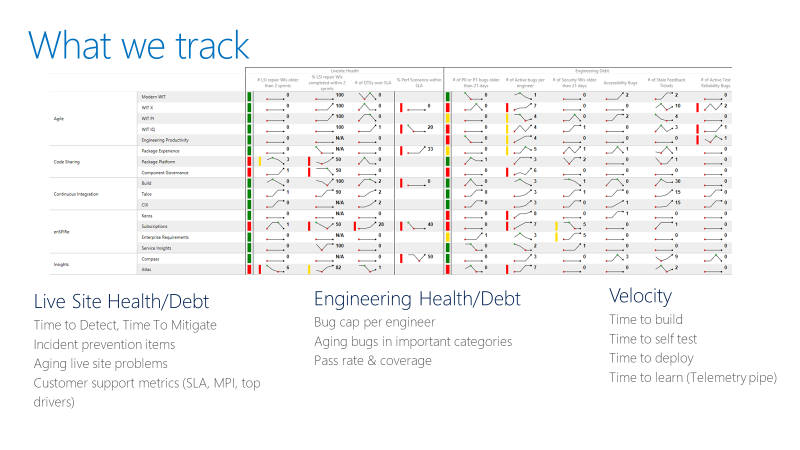
Per le metriche di integrità del sito live, il team tiene traccia del tempo necessario per rilevare, ridurre il tempo necessario e il numero di elementi di riparazione che un team sta trasportando. Un elemento di ripristino è il lavoro che il team identifica in una retrospettiva del sito live per evitare che eventi imprevisti simili vengano ricorrenti. La scorecard tiene traccia anche se i team stanno chiudendo gli elementi di riparazione entro un intervallo di tempo ragionevole.
Per le metriche di integrità di progettazione, il team tiene traccia dei bug attivi per ogni sviluppatore. Se un team ha più di cinque bug per sviluppatore, il team deve classificare in ordine di priorità la correzione di tali bug prima dello sviluppo di nuove funzionalità. Il team tiene traccia anche dei bug invecchiati in categorie speciali come la sicurezza.
Le metriche della velocità di progettazione misurano la velocità in parti diverse della pipeline di integrazione continua e recapito continuo (CI/CD). L'obiettivo generale è quello di aumentare la velocità della pipeline DevOps: a partire da un'idea, ottenere il codice nell'ambiente di produzione e ricevere i dati dai clienti.