Prospettiva del Framework Well-Architected su Azure Traffic Manager
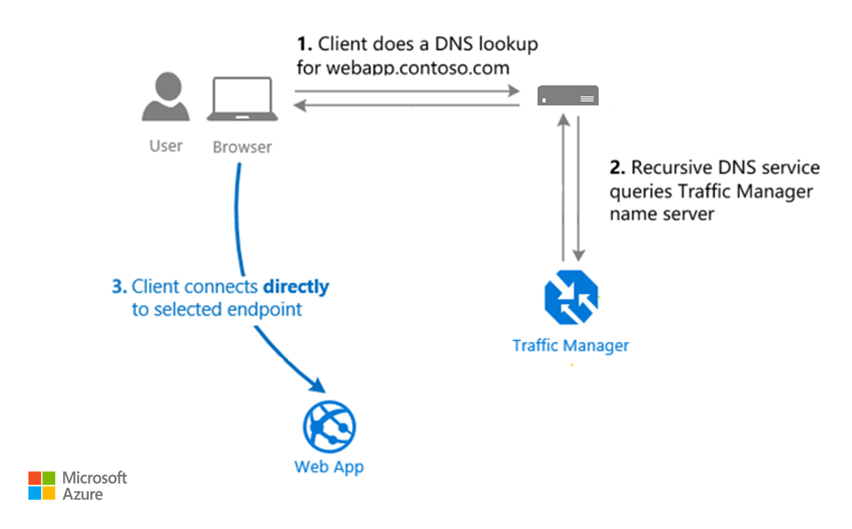
Gestione traffico di Azure è un servizio di bilanciamento del carico globale che può distribuire il traffico tra più aree di Azure, zone all'interno di un'area o data center all'interno di tali zone. Usa il protocollo DNS (Domain Name System) per stabilire un percorso di comunicazione tra un client e gli endpoint del carico di lavoro. Dopo aver stabilito la connessione, i client possono connettersi direttamente all'endpoint senza l'aiuto di Gestione traffico.
Questo articolo presuppone che in qualità di architetto siano state esaminate le opzioni di bilanciamento del carico in Azure e si sia scelto Gestione traffico di Azure per il carico di lavoro, che viene distribuito in più aree in un modello attivo-attivo o attivo-passivo. Le linee guida contenute in questo articolo forniscono raccomandazioni sull'architettura mappate ai principi dei pilastri di Well-Architected Framework.
Importante
Come usare questa guida
Ogni sezione include un elenco di controllo di progettazione che presenta aree di interesse per l'architettura insieme alle strategie di progettazione localizzate nell'ambito della tecnologia.
Sono incluse anche raccomandazioni per le funzionalità tecnologiche che possono aiutare a materializzare tali strategie. Le raccomandazioni non rappresentano un elenco completo di tutte le configurazioni disponibili per Gestione traffico e le relative dipendenze. Vengono invece elencate le raccomandazioni principali mappate alle prospettive di progettazione. Usare le raccomandazioni per creare un modello di verifica o per ottimizzare gli ambienti esistenti.
Architettura di base che illustra le raccomandazioni principali: bilanciamento del carico multi-regionale con Traffic Manager, Azure Firewall e Application Gateway.
ambito della tecnologia
Questa revisione è incentrata sulle decisioni correlate per la risorsa di Azure seguente:
- Gestione traffico
Nota
Per i carichi di lavoro che ospitano applicazioni HTTP, Frontdoor di Azure è una scelta naturale grazie alle relative funzionalità, ad esempio una rete per la distribuzione di contenuti, la terminazione TLS (Transport Layer Security) e un firewall integrato.
Rispetto ad Azure Front Door, Traffic Manager è più semplice da impostare, configurare e gestire. Gestione traffico non ha un endpoint che è possibile controllare direttamente. A differenza di Frontdoor, che gestisce le richieste client, Gestione traffico connette solo i client all'endpoint di un carico di lavoro.
Tuttavia, questa semplicità presenta compromessi che possono introdurre complessità in un'architettura. Ad esempio, potrebbe essere necessario implementare misure di sicurezza aggiuntive per bloccare i tipi di attacco OWASP (Open Worldwide Application Security Project). Un Web Application Firewall (WAF) in Azure Front Door o Azure Application Gateway offre questa funzionalità. In alternativa, è possibile aggiungere una cache, che può velocizzare la distribuzione del contenuto, ma aggiunge complessità perché è necessario gestire un archivio dati.
Per ulteriori informazioni, vedere la prospettiva del framework Well-Architected su Azure Front Door.
Affidabilità
Lo scopo del pilastro Affidabilità è fornire funzionalità continue la creazione di resilienza sufficienti e la possibilità di ripristinare rapidamente gli errori.
principi di progettazione dell'affidabilità forniscono una strategia di progettazione di alto livello applicata per singoli componenti, flussi di sistema e sistema nel suo complesso.
Elenco di controllo per la progettazione
Avvia la strategia di progettazione in base all'elenco di controllo di revisione della progettazione per Affidabilità. Determinare la rilevanza per i requisiti aziendali tenendo presente la natura dell'applicazione e la criticità dei relativi componenti. Estendere la strategia per includere altri approcci in base alle esigenze.
Tenere conto dei potenziali errori. "Traffic Manager è progettato per la resilienza." Ma può comunque essere un singolo punto di guasto per il carico di lavoro. Per attenuare questo rischio, definire un percorso secondario a un servizio alternativo che diventa attivo se Gestione traffico non è disponibile. Per evitare problemi di routing, non usare Gestione traffico e il servizio alternativo insieme.
Avere una buona conoscenza della copertura del contratto di servizio. Quando si valuta contratti di servizio di Gestione traffico, comprendere la copertura correlata al percentile pubblicato. Ad esempio, le ricerche DNS potrebbero avere esito negativo più volte. I fallimenti non vengono considerati inattività fino a quando non si verificano errori di ricerca DNS continui per un intero minuto.
Incorporare la ridondanza nell'architettura del carico di lavoro. Se il servizio viene esposto tramite un indirizzo IP pubblico, usare Gestione traffico per implementare la ridondanza tra aree di Azure, locali e altri cloud. Ad esempio, potrebbe essere presente un'applicazione locale con un'istanza secondaria nel cloud. Se il sistema locale ha esito negativo, l'istanza cloud può diventare attiva, che consente di garantire la continuità.
Usare un'architettura di distribuzione affidabile per supportare la ridondanza. Come servizio di bilanciamento del carico, Gestione traffico distribuisce il traffico tra gli endpoint del carico di lavoro in base alla modalità di configurazione del metodo di routing. Questa configurazione viene definita in un profilo di Gestione traffico. Il profilo è un componente fondamentale della strategia di distribuzione. È possibile usare la configurazione del profilo appropriata per implementare un modello attivo-attivo o un modello attivo-passivo con riserva a caldo.
Ogni profilo specifica un singolo metodo di routing del traffico. Alcuni scenari richiedono un routing del traffico più sofisticato. È possibile combinare i profili di Gestione traffico per sfruttare più di un metodo di routing del traffico.
Per ulteriori informazioni, vedere metodi di routing di Gestore del traffico.
Valutare la durata della memorizzazione nella cache delle risposte DNS. L'impostazione TTL (Time-to-Live) per le ricerche DNS in Gestione traffico determina per quanto tempo i resolver DNS downstream memorizzano nella cache le risposte DNS. La durata (TTL) predefinita potrebbe comportare tempi di memorizzazione nella cache più lunghi del necessario, potenzialmente causando temporanei tempi di inattività se un endpoint dovesse fallire. Ridurre il TTL per aumentare la frequenza degli aggiornamenti della cache. Questo metodo può contribuire a ridurre i tempi di inattività, ma aumenta la frequenza delle ricerche DNS.
Evitare di inviare traffico a istanze non integre o compromesse. Esaminare le funzionalità di probe di integrità predefinite in Gestione traffico.
Per le applicazioni HTTPS e HTTP, implementare il modello di monitoraggio dell'integrità degli endpoint per fornire una pagina dedicata all'interno dell'applicazione. In base a controlli specifici, la pagina restituisce un codice di stato HTTPS appropriato. Oltre alla disponibilità dell'endpoint, il controllo dello stato di salute deve monitorare tutte le dipendenze dell'applicazione.
Per altre applicazioni, Gestione traffico usa tcp (Transmission Control Protocol) per determinare la disponibilità dell'endpoint.
Per ulteriori informazioni, vedere modello di monitoraggio degli endpoint di salute e Comprendere i probe di Gestione Traffico.
Determinare la tolleranza di interruzione. Se un back-end diventa non disponibile, è possibile passare del tempo prima che Gestione traffico riconosca l'errore e arresti il traffico verso l'endpoint non disponibile. C'è un periodo di tempo in cui le richieste client non possono essere gestite. Usare questa tolleranza per configurare le impostazioni della sonda, che determinano con quale rapidità vuoi iniziare le operazioni di continuità aziendale.
Includere gli endpoint come parte dei test di resilienza. Simulare gli endpoint non disponibili per vedere in che modo Gestione traffico gestisce gli errori. Supponi che il tuo carico di lavoro usi un servizio di bilanciamento del carico come Application Gateway in una rete virtuale privata. È possibile usare le regole del gruppo di sicurezza di rete (NSG) in Azure Chaos Studio per simulare gli errori dell'endpoint. È possibile bloccare l'accesso alla subnet in cui risiede il gateway applicativo.
Consigli
| Raccomandazione | Beneficio |
|---|---|
| Distribuire più endpoint nei profili di Gestione traffico e abilitali. Se un endpoint non è abilitato, non viene verificato per i controlli di integrità né incluso nella rotazione del traffico. Posizionare questi endpoint in aree diverse. | Le istanze ridondanti consentono di garantire la disponibilità in caso di errore di un endpoint. |
| Valuta i vari metodi di routing del traffico . Configurare una o una combinazione di metodi per allinearsi alla strategia di distribuzione. Gestione traffico applica il metodo scelto a ogni query DNS e usa il metodo per determinare quale endpoint viene restituito nella risposta DNS. - Il metodo ponderato distribuisce il traffico in base al coefficiente di peso configurato. Questo metodo supporta modelli attivi-attivi. - Il metodo basato sulla priorità configura l'area primaria per ricevere il traffico e inviarlo all'area secondaria come backup. Questo metodo supporta modelli attivi-passivi. - Il metodo geografico instrada il traffico in base all'origine geografica della query DNS. Per coprire tutte le aree, configurare almeno un endpoint con la proprietà All (World). |
Un metodo di routing ottimizzato consente di garantire che il traffico venga distribuito in modo efficiente tra gli endpoint. È possibile supportare gli obiettivi del modello di distribuzione attivo-attivo o attivo-passivo. Un metodo di routing efficiente consente di garantire che le aree secondarie possano gestire il traffico o fungere da backup. Il routing geografico consente agli utenti di indirizzare gli utenti all'endpoint più vicino in base alla propria posizione. Consente di garantire che il traffico venga gestito in modo efficiente e non perso. |
| Impostare l'intervallo TTL DNS durata su un valore basso, preferibilmente inferiore a 60 secondi. Per ottimizzare le prestazioni, regolare la durata del probe di integrità e il TTL del record DNS. | Una durata TTL bassa consente di garantire aggiornamenti della cache del resolver DNS downstream più frequenti e failover più rapido. Riduce inoltre al minimo i tempi di inattività e migliora la velocità di risposta complessiva dell'applicazione. |
| Configurare le sonde di integrità per monitorare l'endpoint. - Non abilitare AlwaysServe, poiché ciò disabilita il monitoraggio degli endpoint e invia richieste all'endpoint, indipendentemente dallo stato di integrità. - Impostare il valore probing interval. Considerare il compromesso tra la velocità di rilevamento degli errori e il numero di richieste all'endpoint. Il numero di richieste può essere sostanziale perché Gestione traffico è un servizio globale che esegue il ping simultaneo da diverse posizioni. - Impostare il valore probe timeout. Considerare quanto tempo attendere prima di dichiarare l'endpoint malfunzionante. Includere i falsi positivi nel conteggio degli errori. |
I probe di integrità assicurano che solo le istanze integre gestiscono le richieste degli utenti. Consentono inoltre di determinare se gli errori non sono transienti e la rapidità con cui devono essere eseguite le operazioni di failover. |
Sicurezza
Lo scopo del pilastro Sicurezza è fornire garanzie di riservatezza, integrità e disponibilità al carico di lavoro.
I principi di progettazione sicurezza forniscono una strategia di progettazione di alto livello per raggiungere tali obiettivi applicando approcci alla progettazione tecnica di Gestione traffico.
Elenco di controllo per la progettazione
Esaminare le baseline di sicurezza. Per migliorare la postura di sicurezza, esaminare la baseline di sicurezza per Traffic Manager.
Impedire modifiche non autorizzate del routing del traffico. Considerare i profili di Traffic Manager come risorse critiche per il carico di lavoro perché contengono le impostazioni di configurazione per instradare il traffico. Solo le identità autorizzate devono avere accesso a questi profili. Implementare il controllo degli accessi basato sul ruolo (RBAC) sul piano di controllo per limitare attività quali la creazione, l'eliminazione o la modifica delle risorse. Solo le identità autorizzate devono avere l'autorità per abilitare o disabilitare gli endpoint. L'accesso non autorizzato può comportare modifiche alla configurazione e potenzialmente reindirizzare il traffico a implementazioni dannose.
Proteggere le applicazioni dalle minacce nel perimetro di rete. Gestione traffico non offre funzionalità di sicurezza predefinite, ad esempio un WAF. Per proteggere le applicazioni HTTP, è necessario implementare l'ispezione del traffico a livello di endpoint.
Un'architettura tipica può includere Gestione traffico e più endpoint. Per ogni endpoint, un gateway applicativo che gestisce la terminazione del TLS e altre funzioni di sicurezza fornisce protezione. Per un'architettura di riferimento che illustra tale modello, vedere bilanciamento del carico tra più regioni con Traffic Manager, Firewall di Azure e Gateway Applicazione.
Rafforzare le voci DNS. Gestione traffico può essere soggetto ad attacchi che modificano i dati DNS, che possono reindirizzare il traffico a siti dannosi e causare problemi di sicurezza. Una minaccia comune è l'acquisizione di un sottodominio, in cui un record DNS punta a una risorsa di Azure deprovisionata. Per evitare acquisizioni di sottodomini, usare i record alias DNS di Azure e associare il ciclo di vita di un record DNS a una risorsa di Azure.
Per ulteriori informazioni, vedere Impedire voci DNS sospese.
Consigli
| Raccomandazione | Beneficio |
|---|---|
|
Aggiungere i gateway delle applicazioni agli endpoint del carico di lavoro. Per implementare l'ispezione della sicurezza con un firewall per le applicazioni HTTP, aggiungere i gateway delle applicazioni agli endpoint del carico. |
È possibile esaminare il traffico HTTP in ingresso per proteggere l'applicazione da attacchi comuni. |
| Creare un record alias in DNS di Azure per il nome di dominio principale del carico di lavoro per fare riferimento a un profilo di Traffic Manager. | I record alias associano strettamente il ciclo di vita di un record DNS a una risorsa di Azure. Questa configurazione consente di evitare riferimenti incerti se il carico di lavoro viene rimosso. Se il profilo di Gestione traffico viene eliminato, il record alias DNS diventa un set di record vuoto. Non fa più riferimento alla risorsa eliminata. |
Ottimizzazione costi
L'ottimizzazione dei costi è incentrata su rilevare modelli di spesa, dare priorità agli investimenti in aree critiche e ottimizzare in altre per soddisfare il budget dell'organizzazione rispettando i requisiti aziendali.
I principi di progettazione Ottimizzazione costi forniscono una strategia di progettazione di alto livello per raggiungere tali obiettivi e fare compromessi in base alle esigenze nella progettazione tecnica relativa a Gestione traffico e al relativo ambiente.
Elenco di controllo per la progettazione
Inizia la tua strategia di design basata sull'elenco di controllo della revisione del design per l'ottimizzazione dei costi per gli investimenti. Ottimizzare la progettazione in modo che il carico di lavoro sia allineato al budget allocato per il carico di lavoro. La progettazione deve usare le funzionalità di Azure appropriate, monitorare gli investimenti e trovare opportunità per ottimizzare nel tempo.
Valutare il costo delle funzionalità. La funzionalità dashboard visualizzazione traffico mostra la posizione da cui i client si connettono e la latenza associata. Queste informazioni consentono di ottimizzare le prestazioni e perfezionare la progettazione, contribuendo all'eccellenza operativa e all'efficienza del sistema. Tuttavia, comporta costi aggiuntivi. Per altre informazioni, vedere Visualizzazione traffico.
Considerare anche il costo associato alle sonde di controllo. Gestione traffico effettua il ping degli endpoint definiti da diverse posizioni per verificarne la disponibilità. È possibile scegliere ping lenti e ping veloci. I ping veloci rilevano gli errori più velocemente, ma comportano costi più elevati. Aggiungono anche un carico maggiore sul carico di lavoro perché i controlli di integrità sono più frequenti.
Valuta il costo della tua strategia di routing. Ad esempio, se la maggior parte dei client accede all'endpoint da un'area a latenza elevata, è possibile creare un altro endpoint più vicino a tali utenti e modificare il metodo di routing in Gestione traffico. Questa procedura riduce la latenza in modo da poter elaborare più richieste con meno capacità, con conseguente risparmio sui costi.
Consigli
Eccellenza operativa
L'eccellenza operativa si concentra principalmente sulle procedure per lo sviluppo, l'osservabilità e la gestione delle release.
I principi di progettazione 'eccellenza operativa forniscono una strategia di progettazione di alto livello per raggiungere tali obiettivi per i requisiti operativi del carico di lavoro.
Elenco di controllo per la progettazione
Raccogliere e analizzare i dati operativi come parte del monitoraggio del carico di lavoro. Acquisire i log e le metriche di Gestione traffico pertinenti. Usare questi dati per risolvere i problemi, comprendere i comportamenti del traffico e ottimizzare la logica di routing.
Visualizzare i dati del traffico per i profili. Questi dati consentono di individuare aree di miglioramento, ad esempio l'espansione della presenza di Azure in aree a latenza elevata. Evidenzia anche i modelli di traffico in aree diverse per determinare dove aumentare o ridurre gli investimenti.
Implementare le operazioni di ripristino di emergenza. L'implementazione del ripristino di emergenza può essere progettata per reindirizzare il traffico di rete/Web dal sito principale a un sito di backup. Questo metodo di ripristino di emergenza può essere implementato usando DNS di Azure e Azure Traffic Manager (DNS). In caso di emergenza, se l'endpoint primario diventa danneggiato, Gestione traffico reindirizza il traffico a un endpoint secondario integro. Per impostazione predefinita, Gestione traffico assegna la priorità all'endpoint primario, ma può anche essere configurato con endpoint di failover aggiuntivi o servizi di bilanciamento del carico per distribuire il carico del traffico. Per altre informazioni, vedere Configurare il ripristino di emergenza e il rilevamento delle interruzioni.
Evitare operazioni di failback automatico. Quando si esegue un failback, non usare il failback automatico, che torna immediatamente all'endpoint originale nel primario quando è disponibile. Disabilitare invece l'endpoint originale e usare l'endpoint secondario fino a quando non si vuole passare. Questo approccio offre tempo per la stabilizzazione. Il failback immediato può creare carichi e ritardi aggiuntivi.
Per altre informazioni, vedere architettura di riferimento del bilanciamento del carico multiregione.
Testare le impostazioni di configurazione. Le configurazioni errate possono influire su tutti gli aspetti del carico di lavoro, in particolare sull'affidabilità. Testare le configurazioni con più client in diverse posizioni. Per altre informazioni, vedere Verificare le impostazioni di Gestione del traffico.
Consigli
| Raccomandazione | Beneficio |
|---|---|
|
Abilitare i log di Diagnostica per un profilo di Traffic Manager. Usare strumenti per ripetere i log e analizzare i dati del controllo dello stato di salute. |
I log di diagnostica forniscono informazioni dettagliate sul comportamento del profilo di Gestione traffico. Ad esempio, è possibile identificare i motivi per i singoli timeout del probe rispetto a un endpoint. |
| Attiva il dashboard della visualizzazione del traffico . Ottenere informazioni dettagliate sulla posizione da cui i client si connettono e sulla latenza associata. | Queste informazioni consentono di ottimizzare le prestazioni e i costi perché è possibile perfezionare la progettazione. |
| Approfitta della API REST Heat Map , che fornisce dati sulle posizioni dei client e sulla latenza. | Questo approccio offre flessibilità, ad esempio l'impostazione di un periodo di tempo specifico. È possibile aggiungere dati a strumenti o dashboard personalizzati. È anche possibile usare questa API per l'integrazione con strumenti esterni. |
| Disabilitare gli endpoint per le attività operative. Ad esempio, è possibile disabilitare il failback dopo un failover per eseguire operazioni di manutenzione o test. | La disabilitazione dell'endpoint dal servizio di bilanciamento del carico è utile per le attività operative perché non è possibile arrestare il traffico in tempo reale. Durante la manutenzione, le istanze non ricevono traffico se si disabilita l'endpoint. Questo approccio impedisce il failback automatico. |
Efficienza delle prestazioni
L'efficienza delle prestazioni riguarda mantenere l'esperienza utente anche quando si verifica un aumento del carico gestendo la capacità. La strategia include il ridimensionamento delle risorse, l'identificazione e l'ottimizzazione dei potenziali colli di bottiglia e l'ottimizzazione delle prestazioni massime.
I principi di progettazione efficienza delle prestazioni forniscono una strategia di progettazione di alto livello per raggiungere tali obiettivi di capacità rispetto all'utilizzo previsto.
Elenco di controllo per la progettazione
Avvia la strategia di progettazione in base all'elenco di controllo della revisione della progettazione per l'efficienza operativa. Definire una linea di base basata su indicatori di prestazioni chiave per Gestione traffico.
Misurare l'impatto sulle prestazioni della configurazione. Traffic Manager non interferisce con la connessione diretta tra il client e l'endpoint. L'impatto principale sulle prestazioni è la ricerca DNS iniziale. L'impostazione TTL influisce sulla frequenza con cui si verifica questa ricerca. Un TTL inferiore indica risoluzioni DNS più frequenti, che possono influire leggermente sulle prestazioni. Se si imposta il valore TTL su zero, ogni richiesta richiede una ricerca DNS, che aggiunge un piccolo ritardo prima di accedere all'endpoint.
Poiché Gestione del traffico opera a livello di DNS, non supporta l'affinità di sessione. Gestione traffico potrebbe indirizzare gli utenti a endpoint diversi per ogni chiamata. Se è necessaria l'affinità di sessione, è necessario rendere persistente lo stato in un archivio dati separato.
Per ulteriori informazioni, vedere Considerazioni sulle prestazioni per Traffic Manager.
Modificare il comportamento del routing del traffico per ottimizzare le prestazioni. Un singolo profilo può avere più endpoint, ma è possibile applicare un solo metodo di routing alla volta.
Per scenari più complessi, è consigliabile creare una gerarchia di profili per combinare metodi di routing diversi. Ad esempio, è possibile classificare in ordine di priorità le aree e quindi usare il routing basato sulle prestazioni all'interno delle aree.
Consigli
| Raccomandazione | Beneficio |
|---|---|
| Usare il metodo di routing delle prestazioni quando si dispone di endpoint in posizioni geografiche diverse. | Questo metodo assegna priorità all'invio del traffico all'endpoint con la latenza più bassa. Questo metodo consente di garantire un servizio rapido per gli utenti. |
| Usare strumenti specializzati per ottimizzare le prestazioni. Misurare le prestazioni delle ricerche DNS . Per analizzare le prestazioni del traffico, usare il dashboard di visualizzazione del traffico o l'API REST della mappa termica . | Gli strumenti di misurazione della latenza DNS eseguono una ricerca DNS completa e forniscono dati sulle prestazioni. È possibile usare questi dati per impostare la durata TTL e ottimizzare le prestazioni. |
| Combinare i metodi di traffico con profili annidati per ottenere prestazioni ottimali, in base ai requisiti del carico di lavoro. | Un metodo di routing ottimizzato consente di garantire che il traffico venga indirizzato agli endpoint più reattivi e più vicini. Questo approccio consente di migliorare le prestazioni dell'applicazione e l'esperienza utente. |
| Usare la funzionalità di misurazione utente reale per visualizzare le misurazioni della latenza di rete nelle aree di Azure. Questa funzionalità è disponibile senza costi aggiuntivi. | È possibile prendere decisioni di routing guidate dai dati per indirizzare le query all'area di Azure che offre la latenza più bassa. |
| Impostare l'intervallo TTL DNS su un valore superiore. | I client possono memorizzare nella cache i risultati per un periodo di tempo più lungo, riducendo la necessità di risolvere il DNS ogni volta. |
Criteri di Azure
Azure offre un set completo di criteri predefiniti correlati a Gestione traffico e alle relative dipendenze. È possibile controllare alcune delle raccomandazioni precedenti tramite Criteri di Azure. Ad esempio, è possibile verificare se:
- I log delle risorse sono abilitati per tenere traccia delle attività.
- I log per i profili di Gestione traffico vengono inviati a Hub eventi di Azure.
Per una governance completa, vedere le definizioni predefinite di Criteri di Azure per i servizi di rete di Azure.
Raccomandazioni di Azure Advisor
azure Advisor è un consulente cloud personalizzato che consente di seguire le procedure consigliate per ottimizzare le distribuzioni di Azure. Ecco alcuni consigli che consentono di migliorare l'affidabilità, la sicurezza, l'efficacia dei costi, le prestazioni e l'eccellenza operativa delle istanze dell'applicazione Web.
Compromessi
Potrebbe essere necessario fare compromessi di progettazione se si usano gli approcci negli elenchi di controllo dei pilastri. Ecco alcuni esempi di vantaggi e svantaggi.
affidabilità ed efficienza delle prestazioni 
Impostazione TTL per le ricerche DNS. L'impostazione TTL predefinita può comportare tempi di memorizzazione nella cache più lunghi. Tempi di memorizzazione nella cache lunghi possono causare tempi di inattività se un endpoint non riesce, perché l'applicazione continua a tentare una connessione all'endpoint guasto per tutta la durata del TTL.
Ridurre il valore TTL per attenuare questo problema. Un TTL inferiore porta ad aggiornamenti più frequenti e a un failover più rapido, ma incrementa la frequenza delle interrogazioni DNS. Questo approccio può influire sulle prestazioni e aumentare il carico sui server DNS.
Affidabilità e Ottimizzazione dei Costi
- Sonde di salute. Traffic Manager usa sonde di integrità per eseguire il ping degli endpoint da diverse posizioni per controllarne la disponibilità. È possibile scegliere ping lenti o ping veloci. I ping veloci rilevano gli errori più velocemente, ma aggiungono costi. I ping lenti richiedono più tempo per rilevare gli errori, ma costano meno. Bilanciare i costi associati con la velocità di rilevamento e ripristino degli errori.
Passaggio successivo
Si considerino le risorse seguenti che illustrano le raccomandazioni in questo articolo.
Usare l'architettura di riferimento seguente come esempio di come applicare le linee guida di questo articolo a un carico di lavoro:
Usare la documentazione del prodotto seguente per migliorare le competenze di implementazione: