Raccomandazioni per la risposta agli eventi imprevisti di sicurezza
Si applica alla raccomandazione dell'elenco di controllo per la sicurezza di Azure Well-Architected Framework:
| SE:12 | Definire e testare procedure di risposta agli eventi imprevisti efficaci che coprono uno spettro di eventi imprevisti, dai problemi localizzati al ripristino di emergenza. Definire chiaramente quale team o individuo esegue una procedura. |
|---|
Questa guida descrive le raccomandazioni per l'implementazione di una risposta agli eventi imprevisti di sicurezza per un carico di lavoro. Se si verifica una compromissione della sicurezza per un sistema, un approccio sistematico alla risposta agli eventi imprevisti consente di ridurre il tempo necessario per identificare, gestire e attenuare gli eventi imprevisti di sicurezza. Questi incidenti possono minacciare la riservatezza, l'integrità e la disponibilità di sistemi e dati software.
La maggior parte delle aziende ha un team operativo di sicurezza centrale (noto anche come Centro operazioni di sicurezza) o SecOps. La responsabilità del team operativo di sicurezza è rilevare, classificare in ordine di priorità e valutare rapidamente potenziali attacchi. Il team monitora anche i dati di telemetria correlati alla sicurezza e analizza le violazioni della sicurezza.
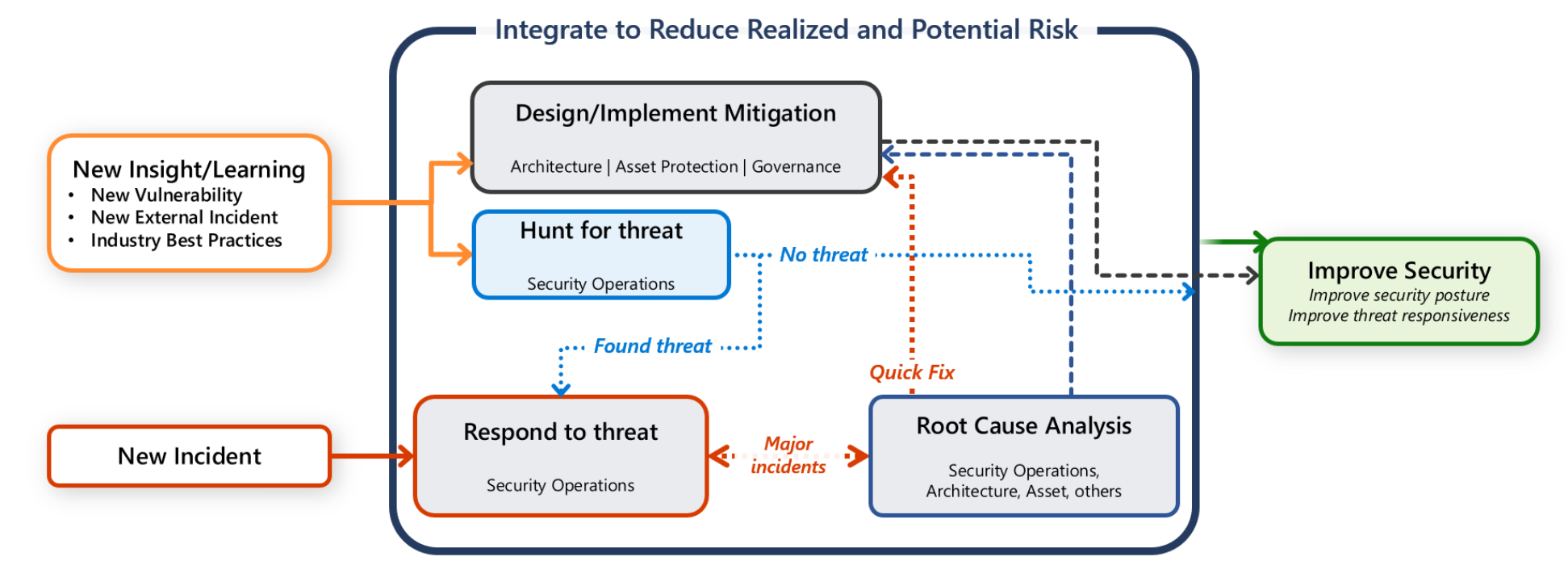
Tuttavia, si ha anche la responsabilità di proteggere il carico di lavoro. È importante che qualsiasi attività di comunicazione, indagine e ricerca sia un lavoro collaborativo tra il team del carico di lavoro e il team SecOps.
Questa guida fornisce suggerimenti per l'utente e il team del carico di lavoro che consentono di rilevare, valutare e analizzare rapidamente gli attacchi.
Definizioni
| Termine | Definizione |
|---|---|
| Avviso | Notifica che contiene informazioni su un evento imprevisto. |
| Fedeltà degli avvisi | Accuratezza dei dati che determinano un avviso. Gli avvisi ad alta fedeltà contengono il contesto di sicurezza necessario per eseguire azioni immediate. Gli avvisi con bassa fedeltà non contengono informazioni o contengono rumore. |
| Falso positivo | Avviso che indica un evento imprevisto che non si è verificato. |
| Incident | Evento che indica l'accesso non autorizzato a un sistema. |
| Risposta agli eventi imprevisti | Un processo che rileva, risponde e riduce i rischi associati a un evento imprevisto. |
| Valutazione | Operazione di risposta agli eventi imprevisti che analizza i problemi di sicurezza e ne assegna la priorità. |
Strategie di progettazione chiave
L'utente e il team eseguono operazioni di risposta agli eventi imprevisti quando è presente un segnale o un avviso per una potenziale compromissione. Gli avvisi ad alta fedeltà contengono un ampio contesto di sicurezza che rende più semplice per gli analisti prendere decisioni. Gli avvisi ad alta fedeltà generano un numero ridotto di falsi positivi. Questa guida presuppone che un sistema di avvisi filtri i segnali a bassa fedeltà e si concentra sugli avvisi ad alta fedeltà che potrebbero indicare un evento imprevisto reale.
Designare i contatti di notifica degli eventi imprevisti
Gli avvisi di sicurezza devono raggiungere le persone appropriate nel team e nell'organizzazione. Stabilire un punto di contatto designato nel team del carico di lavoro per ricevere le notifiche degli eventi imprevisti. Queste notifiche devono includere il maggior numero possibile di informazioni sulla risorsa compromessa e sul sistema. L'avviso deve includere i passaggi successivi, in modo che il team possa accelerare le azioni.
È consigliabile registrare e gestire notifiche e azioni degli eventi imprevisti usando strumenti specializzati che mantengono un audit trail. Usando strumenti standard, è possibile conservare le prove che potrebbero essere necessarie per potenziali indagini legali. Cercare le opportunità di implementare l'automazione in grado di inviare notifiche in base alle responsabilità delle parti responsabili. Mantenere una chiara catena di comunicazioni e report durante un evento imprevisto.
Sfruttare le soluzioni SIEM (Security Information Event Management) e le soluzioni SOAR (Security Orchestration Automated Response) fornite dall'organizzazione. In alternativa, è possibile acquistare strumenti di gestione degli eventi imprevisti e incoraggiare l'organizzazione a standardizzarle per tutti i team del carico di lavoro.
Esaminare con un team di valutazione
Il membro del team che riceve una notifica degli eventi imprevisti è responsabile della configurazione di un processo di valutazione che coinvolge le persone appropriate in base ai dati disponibili. Il team di valutazione, spesso chiamato team bridge, deve concordare la modalità e il processo di comunicazione. Questo evento imprevisto richiede discussioni asincrone o chiamate bridge? In che modo il team deve tenere traccia e comunicare lo stato di avanzamento delle indagini? Dove il team può accedere agli asset degli eventi imprevisti?
La risposta agli eventi imprevisti è un motivo fondamentale per mantenere aggiornata la documentazione, ad esempio il layout architettonico del sistema, le informazioni a livello di componente, la privacy o la classificazione della sicurezza, i proprietari e i punti chiave di contatto. Se le informazioni sono imprecise o obsolete, il team bridge perde tempo prezioso cercando di capire come funziona il sistema, chi è responsabile di ogni area e qual è l'effetto dell'evento.
Per ulteriori indagini, coinvolgere le persone appropriate. È possibile includere un responsabile eventi imprevisti, un responsabile della sicurezza o lead incentrati sul carico di lavoro. Per mantenere attiva la valutazione, escludere le persone che non rientrano nell'ambito del problema. A volte team separati esaminano l'evento imprevisto. Potrebbe esserci un team che esamina inizialmente il problema e cerca di attenuare l'evento imprevisto e un altro team specializzato che potrebbe eseguire analisi forensi per un'indagine approfondita per verificare problemi di ampia entità. È possibile mettere in quarantena l'ambiente del carico di lavoro per consentire al team forense di eseguire le indagini. In alcuni casi, lo stesso team potrebbe gestire l'intera indagine.
Nella fase iniziale, il team di valutazione è responsabile della determinazione del potenziale vettore e del suo effetto sulla riservatezza, l'integrità e la disponibilità (detta anche CIA) del sistema.
All'interno delle categorie della CIA, assegnare un livello di gravità iniziale che indica la profondità del danno e l'urgenza della correzione. Questo livello dovrebbe cambiare nel corso del tempo man mano che vengono individuate altre informazioni nei livelli di valutazione.
Nella fase di individuazione è importante determinare un corso immediato di azioni e piani di comunicazione. Sono state apportate modifiche allo stato di esecuzione del sistema? Come può essere contenuto l'attacco per fermare ulteriori sfruttamento? Il team deve inviare comunicazioni interne o esterne, ad esempio una divulgazione responsabile? Prendere in considerazione il rilevamento e il tempo di risposta. È possibile che l'utente sia legalmente obbligato a segnalare alcuni tipi di violazioni a un'autorità di regolamentazione entro un periodo di tempo specifico, spesso ore o giorni.
Se si decide di arrestare il sistema, i passaggi successivi portano al processo di ripristino di emergenza del carico di lavoro.
Se non si arresta il sistema, determinare come correggere l'evento imprevisto senza influire sulle funzionalità del sistema.
Ripristino da un evento imprevisto
Considerare un evento imprevisto di sicurezza come un'emergenza. Se la correzione richiede un ripristino completo, usare meccanismi di ripristino di emergenza appropriati dal punto di vista della sicurezza. Il processo di ripristino deve impedire la ricorrenza. In caso contrario, il ripristino da un backup danneggiato reintroduce il problema. La ridistribuzione di un sistema con la stessa vulnerabilità comporta lo stesso evento imprevisto. Convalidare i passaggi e i processi di failover e failback.
Se il sistema rimane funzionante, valutare l'effetto sulle parti in esecuzione del sistema. Continuare a monitorare il sistema per assicurarsi che altri obiettivi di affidabilità e prestazioni vengano soddisfatti o riaggiusti implementando processi di riduzione delle prestazioni appropriati. Non compromettere la privacy a causa della mitigazione.
La diagnosi è un processo interattivo fino a quando non viene identificato il vettore e una potenziale correzione e fallback. Dopo la diagnosi, il team lavora sulla correzione, che identifica e applica la correzione richiesta entro un periodo accettabile.
Le metriche di ripristino misurano il tempo necessario per risolvere un problema. In caso di arresto, potrebbe esserci un'urgenza per quanto riguarda i tempi di correzione. Per stabilizzare il sistema, è necessario tempo per applicare correzioni, patch e test e distribuire gli aggiornamenti. Determinare le strategie di contenimento per prevenire ulteriori danni e la diffusione dell'incidente. Sviluppare procedure di eliminazione per rimuovere completamente la minaccia dall'ambiente.
Compromesso: esiste un compromesso tra obiettivi di affidabilità e tempi di correzione. Durante un evento imprevisto, è probabile che non siano soddisfatti altri requisiti funzionali o non funzionali. Ad esempio, potrebbe essere necessario disabilitare parti del sistema durante l'analisi dell'evento imprevisto oppure potrebbe anche essere necessario portare offline l'intero sistema finché non si determina l'ambito dell'evento imprevisto. I decision maker aziendali devono decidere in modo esplicito quali obiettivi sono accettabili durante l'evento imprevisto. Specificare chiaramente la persona responsabile di tale decisione.
Imparare da un evento imprevisto
Un evento imprevisto rileva lacune o punti vulnerabili in una progettazione o un'implementazione. Si tratta di un'opportunità di miglioramento guidata da lezioni su aspetti di progettazione tecnica, automazione, processi di sviluppo del prodotto che includono test e l'efficacia del processo di risposta agli eventi imprevisti. Mantenere i record dettagliati degli eventi imprevisti, incluse le azioni eseguite, le sequenze temporali e i risultati.
È consigliabile condurre revisioni post-evento imprevisto strutturate, ad esempio analisi della causa radice e analisi retrospettive. Tenere traccia e classificare in ordine di priorità il risultato di tali revisioni e prendere in considerazione l'uso di quanto appreso nelle progettazioni future del carico di lavoro.
I piani di miglioramento devono includere aggiornamenti alle esercitazioni e ai test di sicurezza, ad esempio le esercitazioni sulla continuità aziendale e sul ripristino di emergenza (BCDR). Usare la compromissione della sicurezza come scenario per eseguire un'esercitazione BCDR. Le esercitazioni possono convalidare il funzionamento dei processi documentati. Non dovrebbero essere presenti più playbook di risposta agli eventi imprevisti. Usare una singola origine che è possibile regolare in base alle dimensioni dell'evento imprevisto e alla diffusione o localizzazione dell'effetto. Le esercitazioni si basano su situazioni ipotetiche. Eseguire esercitazioni in un ambiente a basso rischio e includere la fase di apprendimento nelle esercitazioni.
Condurre revisioni post-evento imprevisto o postmortem per identificare i punti deboli nel processo di risposta e nelle aree per il miglioramento. In base alle lezioni apprese dall'evento imprevisto, aggiornare il piano di risposta agli eventi imprevisti (IRP) e i controlli di sicurezza.
Definire un piano di comunicazione
Implementare un piano di comunicazione per notificare agli utenti un'interruzione e informare gli stakeholder interni sulla correzione e sui miglioramenti. Altri utenti dell'organizzazione devono ricevere una notifica delle modifiche apportate alla baseline di sicurezza del carico di lavoro per evitare eventi imprevisti futuri.
Generare report sugli eventi imprevisti per l'uso interno e, se necessario, per la conformità alle normative o per scopi legali. Inoltre, adottare un report in formato standard (un modello di documento con sezioni definite) usato dal team SOC per tutti gli eventi imprevisti. Assicurarsi che a ogni evento imprevisto sia associato un report prima di chiudere l'indagine.
Facilitazione di Azure
Microsoft Sentinel è una soluzione SIEM e SOAR. È un'unica soluzione per il rilevamento degli avvisi, la visibilità delle minacce, la ricerca proattiva e la gestione delle minacce. Per altre informazioni, vedere Che cos'è Microsoft Sentinel?
Assicurarsi che il portale di registrazione di Azure includa le informazioni di contatto dell'amministratore in modo che le operazioni di sicurezza possano ricevere notifiche direttamente tramite un processo interno. Per altre informazioni, vedere Aggiornare le impostazioni di notifica.
Per altre informazioni sulla definizione di un punto di contatto designato che riceve le notifiche degli eventi imprevisti di Azure da Microsoft Defender per il cloud, vedere Configurare le notifiche di posta elettronica per gli avvisi di sicurezza.
Allineamento dell'organizzazione
Cloud Adoption Framework per Azure fornisce indicazioni sulla pianificazione della risposta agli eventi imprevisti e sulle operazioni di sicurezza. Per altre informazioni, vedere Operazioni di sicurezza.
Collegamenti correlati
- Creare automaticamente eventi imprevisti dagli avvisi di sicurezza Microsoft
- Eseguire la ricerca di minacce end-to-end usando la funzionalità di ricerca
- Configurare le notifiche tramite posta elettronica per gli avvisi di sicurezza
- Panoramica della risposta agli eventi imprevisti
- Idoneità agli eventi imprevisti di Microsoft Azure
- Esplorare e analizzare gli incidenti in Microsoft Sentinel
- Controllo di sicurezza: risposta agli eventi imprevisti
- Soluzioni SOAR in Microsoft Sentinel
- Formazione: Introduzione all'idoneità agli eventi imprevisti di Azure
- Aggiornare le impostazioni di notifica portale di Azure
- Che cos'è un SOC?
- Che cos'è Microsoft Sentinel?
Elenco di controllo relativo alla sicurezza
Fare riferimento al set completo di raccomandazioni.