Introduzione a Collegamento ad Azure Synapse per il database Azure SQL
Questo articolo è una guida dettagliata per iniziare a usare Collegamento ad Azure Synapse per Database SQL di Azure. Per una panoramica di questa funzionalità, vedere Collegamento ad Azure Synapse per Database SQL di Azure.
Prerequisiti
Per ottenere Collegamento ad Azure Synapse per SQL, vedere Creare una nuova area di lavoro di Azure Synapse. L'esercitazione corrente consiste nel creare un'istanza di Collegamento ad Azure Synapse per SQL in una rete pubblica. Questo articolo presuppone che siano state selezionate le opzioni Disabilita la rete virtuale gestita e Consenti connessioni da tutti gli indirizzi IP quando è stata creata un'area di lavoro di Azure Synapse. Per configurare Collegamento ad Azure Synapse per Database SQL di Azure con la sicurezza di rete, vedere anche Configurare Collegamento ad Azure Synapse per Database SQL di Azure con sicurezza di rete.
Per il provisioning basato su unità di transazione di database (DTU), assicurarsi che il servizio Database SQL di Azure sia almeno di livello Standard con almeno 100 DTU. I livelli Gratuito, Basic o Standard con meno di 100 DTU con provisioning non sono supportati.
Configurare il database SQL di Azure di origine
Accedere al portale di Azure.
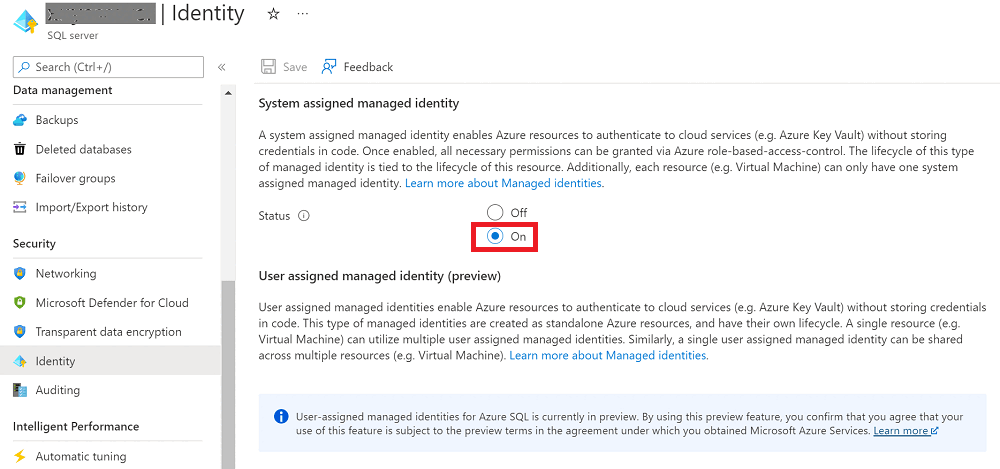
Passare al server logico di Azure SQL, selezionare Identitàe quindi impostare Identità gestita assegnata dal sistema su Attivato.
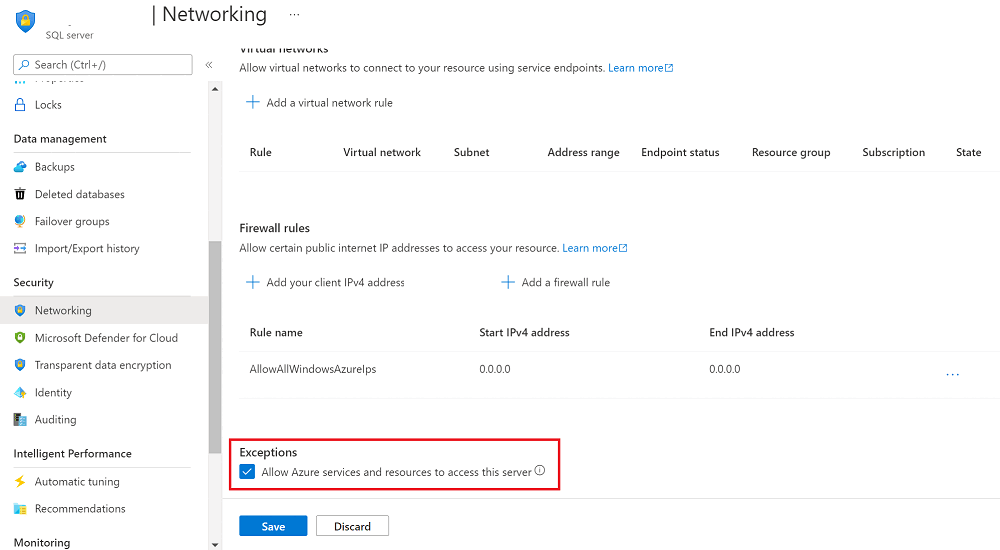
Passare a Rete, quindi selezionare la casella di controllo Consenti alle risorse e ai servizi di Azure di accedere a questo server.
Usando SQL Server Management Studio (SSMS) o Azure Data Studio, connettersi al server logico. Se si vuole che l'area di lavoro di Azure Synapse si connetta al database SQL di Azure usando un'identità gestita, impostare le autorizzazioni di amministratore di Microsoft Entra per il server logico. Per applicare i privilegi nel passaggio 6, usare lo stesso nome amministratore per connettersi al server logico con privilegi amministrativi.
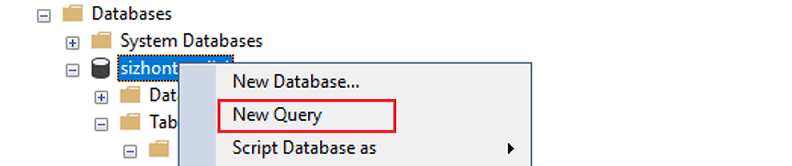
Espandere Databases, fare clic con il pulsante destro del mouse sul database creato, quindi scegliere Nuova query.
Se si vuole che l'area di lavoro di Azure Synapse si connetta al database SQL di Azure di origine usando un'identità gestita, eseguire lo script seguente per fornire l'autorizzazione per l'identità gestita al database di origine.
È possibile ignorare questo passaggio se invece si vuole che l'area di lavoro di Azure Synapse si connetta al database SQL di azure di origine tramite l'autenticazione SQL.
CREATE USER <workspace name> FROM EXTERNAL PROVIDER; ALTER ROLE [db_owner] ADD MEMBER <workspace name>;È possibile creare una tabella con uno schema personalizzato. Il codice seguente rappresenta un esempio di una query
CREATE TABLE. È anche possibile inserire alcune righe in questa tabella per assicurarsi che siano presenti dati da replicare.CREATE TABLE myTestTable1 (c1 int primary key, c2 int, c3 nvarchar(50))


Creare il pool SQL di Azure Synapse di destinazione
Aprire Synapse Studio.
Passare all'hub Gestione, selezionare Pool SQL e quindi selezionare Nuovo.
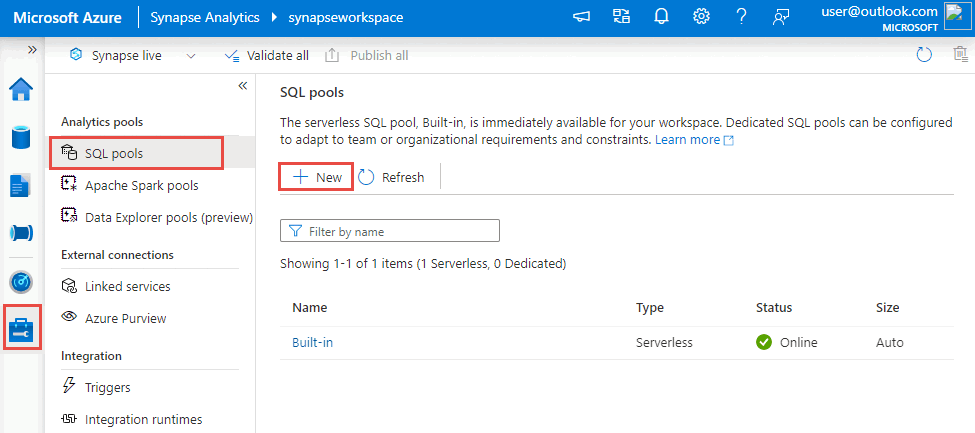
Immettere un nome di pool univoco, usare le impostazioni predefinite e creare il pool dedicato.
È necessario creare uno schema se quello previsto non è disponibile nel database SQL di Azure Synapse di destinazione. Se lo schema è proprietario del database (dbo), è possibile ignorare questo passaggio.

Creare la connessione Collegamento ad Azure Synapse
Nel riquadro sinistro del portale di Azure selezionare Integrazione.
Nel riquadro Integrazione selezionare il segno più (+) e quindi selezionare Connessione di collegamento.
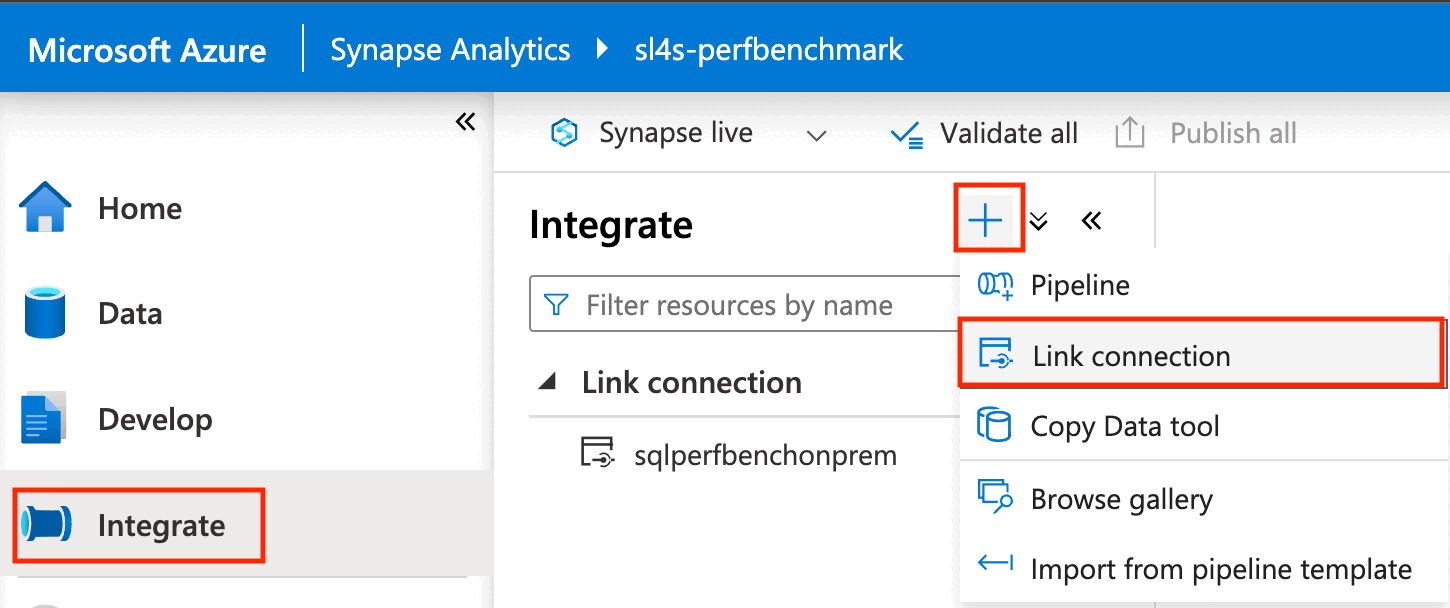
In Servizio collegato di origine selezionare Nuovo.
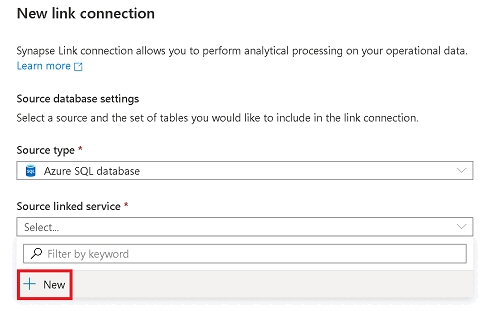
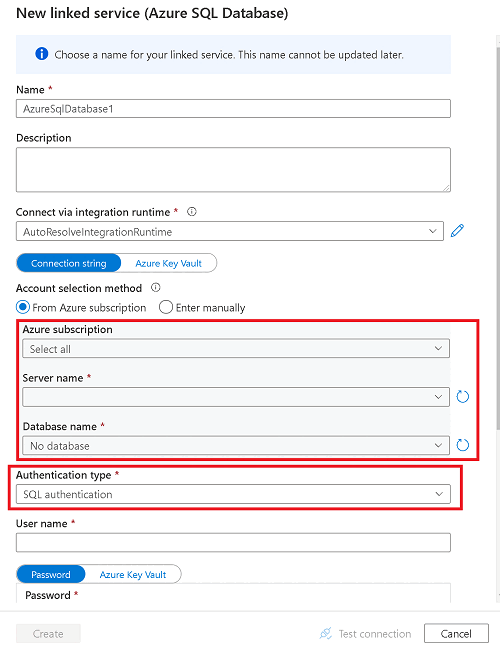
Immettere le informazioni relative al database SQL di Azure di origine.
- Selezionare la sottoscrizione, il server e il database corrispondenti al database SQL di Azure.
- Effettuare una delle operazioni seguenti:
- Per connettere l'area di lavoro di Azure Synapse al database di origine usando l'identità gestita dell'area di lavoro, impostare Tipo di autenticazione su Identità gestita.
- Per usare invece l'autenticazione SQL, se si conosce il nome utente e la password da usare, selezionare Autenticazione SQL.
Nota
È supportato solo il servizio collegato nella versione legacy.
Selezionare Connessione di test per assicurarsi che le regole del firewall siano configurate correttamente e che l'area di lavoro possa connettersi al database SQL di Azure di origine.
Seleziona Crea.
Nota
Il servizio collegato creato qui non è dedicato a Collegamento ad Azure Synapse per SQL. Può essere usato da qualsiasi utente dell'area di lavoro che ha le autorizzazioni appropriate. Dedicare il tempo necessario alla comprensione dell'ambito degli utenti che potrebbero avere accesso a questo servizio collegato e alle relative credenziali. Per altre informazioni sulle autorizzazioni nelle aree di lavoro di Azure Synapse, vedere Panoramica del controllo di accesso dell'area di lavoro di Azure Synapse - Azure Synapse Analytics.
Selezionare una o più tabelle di origine da replicare nell'area di lavoro di Azure Synapse e quindi selezionare Continua.
Nota
Una tabella di origine specificata può essere abilitata in una sola connessione di collegamento alla volta.
Selezionare un database e un pool SQL di Azure Synapse di destinazione.
Specificare un nome per la connessione a Collegamento ad Azure Synapse e selezionare il numero di core per l'ambiente di calcolo della connessione di collegamento. Questi core verranno usati per lo spostamento dei dati dall'origine alla destinazione.
Nota
- Il numero di core selezionati qui viene allocato al servizio di inserimento per l'elaborazione di modifiche e caricamento dei dati. Non influiscono sulla configurazione del database SQL di Azure di origine o sulla configurazione del pool SQL dedicato di destinazione.
- È consigliabile iniziare in piccolo e aumentare il numero di core in base alle esigenze.
Seleziona OK.
Con la nuova connessione Collegamento ad Azure Synapse aperta, è possibile aggiornare il nome della tabella di destinazione, il tipo di distribuzione e il tipo di struttura.
Nota
- È consigliabile usare la tabella heap per il tipo di struttura quando i dati contengono varchar(max), nvarchar(max)e varbinary(max).
- Assicurarsi che lo schema nel pool SQL dedicato di Azure Synapse sia già stato creato prima di avviare la connessione di collegamento. Collegamento ad Azure Synapse per SQL creerà automaticamente le tabelle nello schema nel pool SQL dedicato di Azure Synapse.
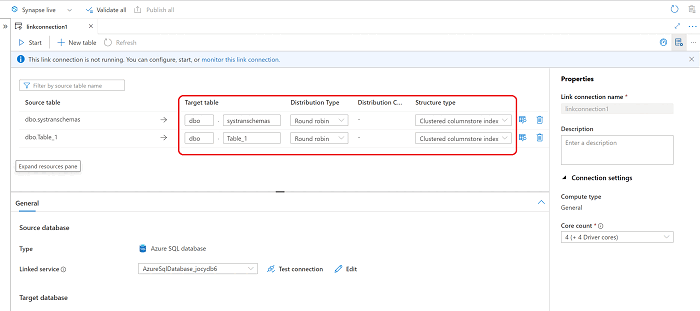
Nell'elenco a discesa Azione sulla tabella di destinazione esistente scegliere l'opzione più appropriata per lo scenario, se la tabella esiste già nella destinazione.
- Elimina e ricrea la tabella: la tabella di destinazione esistente verrà eliminata e ricreata.
- Errore nella tabella non vuota: se la tabella di destinazione contiene dati, la connessione di collegamento per la tabella specificata avrà esito negativo.
- Unisci con dati esistenti: i dati verranno uniti nella tabella esistente.
Nota
Per unire più origini nella stessa destinazione con "Unisci con dati esistenti", assicurarsi che le origini contengano dati diversi per evitare conflitti e risultati imprevisti.
Specificare se abilitare la coerenza delle transazioni tra le tabelle.
- Quando questa opzione è abilitata, una transazione che si estende su più tabelle nel database di origine viene sempre replicata nel database di destinazione in un'unica transazione. In questo modo, tuttavia, si crea un sovraccarico sulla velocità effettiva complessiva della replica.
- Quando l'opzione è disabilitata, ogni tabella replica le modifiche nel proprio limite di transazione nella destinazione in connessioni parallele, migliorando così la velocità effettiva complessiva della replica.
Nota
Quando si vuole abilitare la coerenza delle transazioni tra tabelle, assicurarsi anche che i livelli di isolamento delle transazioni nel pool SQL dedicato di Synapse siano READ COMMITTED SNAPSHOT ISOLATION.
Selezionare Pubblica tutto per salvare la nuova connessione del collegamento al servizio.

Avviare la connessione di Collegamento ad Azure Synapse
Selezionare Avvia e attendere alcuni minuti per la replica dei dati.
Nota
Una connessione di collegamento inizierà da un caricamento iniziale completo dal database di origine, seguito da feed di modifiche incrementali tramite la funzionalità feed di modifiche di Database SQL di Azure. Per altre informazioni, vedere Feed di modifiche di Collegamento ad Azure Synapse per SQL.
Monitorare lo stato della connessione di Collegamento ad Azure Synapse
È possibile monitorare lo stato della connessione di Collegamento ad Azure Synapse, vedere quali tabelle vengono inizialmente copiate (snapshot) e vedere quali tabelle sono in modalità di replica continua (replica).
Passare all'hub Monitoraggio e quindi selezionare Connessioni di collegamento.
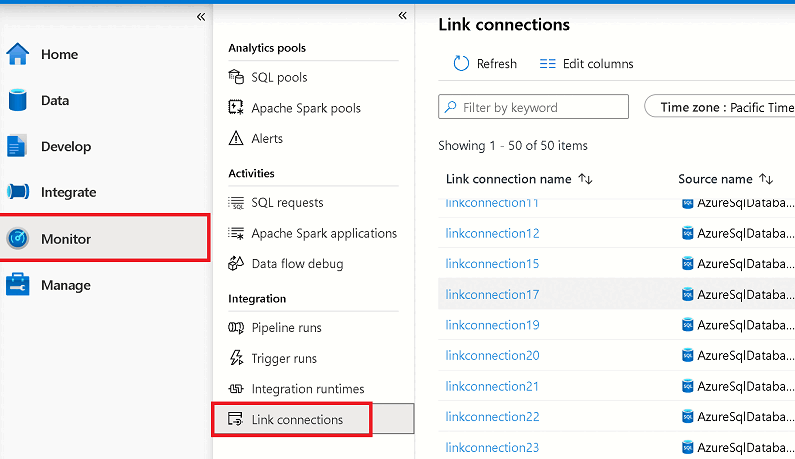
Aprire la connessione di Collegamento ad Azure Synapse avviata e visualizzare lo stato di ogni tabella.
Selezionare Aggiorna nella visualizzazione di monitoraggio per la connessione per osservare eventuali aggiornamenti dello stato.
Eseguire query sui dati replicati
Attendere qualche minuto e quindi verificare che il database di destinazione contenga la tabella e i dati previsti. È anche possibile esplorare le tabelle replicate nel pool SQL dedicato di Azure Synapse di destinazione.
Nell'hub Dati aprire il database di destinazione in Area di lavoro.
In Tabelle fare clic con il pulsante destro del mouse su una delle tabelle di destinazione.
Scegliere Nuovo script SQL e quindi selezionare Prime 100 righe.
Eseguire questa query per visualizzare i dati replicati nel pool SQL dedicato di Azure Synapse di destinazione.
È anche possibile eseguire query sul database di destinazione usando SSMS o altri strumenti. Usare l'endpoint SQL dedicato per l'area di lavoro come nome del server. Questo nome è in genere
<workspacename>.sql.azuresynapse.net. AggiungereDatabase=databasename@poolnamecome parametro aggiuntivo della stringa di connessione durante la connessione tramite SSMS o altri strumenti.
Aggiungere o rimuovere una tabella in una connessione di Collegamento ad Azure Synapse esistente
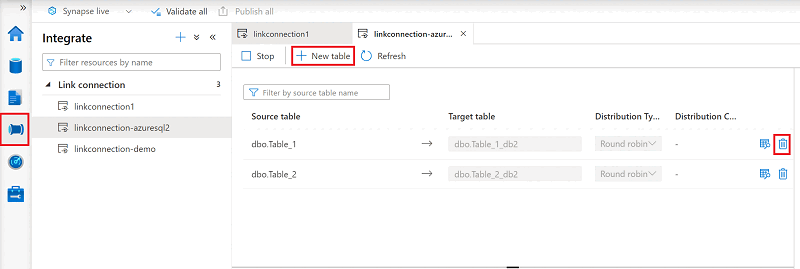
Per aggiungere o rimuovere tabelle in Synapse Studio, seguire questa procedura:
Aprire l'hub Integrazione.
Selezionare la connessione di collegamento da modificare e quindi aprirla.
Effettuare una delle operazioni riportate di seguito:
- Per aggiungere una tabella, selezionare Nuova tabella.
- Per rimuovere una tabella, selezionare l'icona del cestino accanto alla tabella.
Nota
È possibile aggiungere o rimuovere direttamente tabelle quando è in esecuzione una connessione di collegamento.

Arrestare la connessione di Collegamento ad Azure Synapse
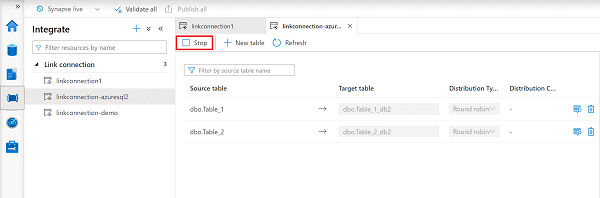
Per arrestare la connessione di Collegamento ad Azure Synapse in Synapse Studio, seguire questa procedura:
Nell'area di lavoro di Azure Synapse aprire l'hub Integrazione.
Selezionare la connessione di collegamento da modificare e quindi aprirla.
Selezionare Arresta per arrestare la connessione di collegamento. La replica dei dati verrà interrotta.
Nota
- Se si riavvia una connessione di collegamento dopo l'arresto, verrà eseguito un caricamento iniziale completo dal database di origine e quindi seguiranno i feed di modifiche incrementali.
- Se si sceglie "Unisci con dati esistenti" come azione sulla tabella di destinazione esistente, quando si arresta e si riavvia la connessione di collegamento, le eliminazioni di record nell'origine durante tale periodo non verranno eliminate nella destinazione. In tal caso, per garantire la coerenza dei dati, è consigliabile usare sospendi/riprendi anziché arrestare/avviare o pulire le tabelle di destinazione prima di riavviare la connessione di collegamento.
Contenuto correlato
- Ottenere o impostare un'identità gestita per un server logico o un'istanza gestita di Database SQL di Azure
- Domande frequenti su Collegamento ad Azure Synapse per SQL
- Configurare Collegamento ad Azure Synapse per Azure Cosmos DB
- Configurare Collegamento ad Azure Synapse per Dataverse
- Introduzione a Collegamento ad Azure Synapse per SQL Server 2022