Come configurare il controllo di accesso su oggetti sincronizzati nel pool SQL serverless
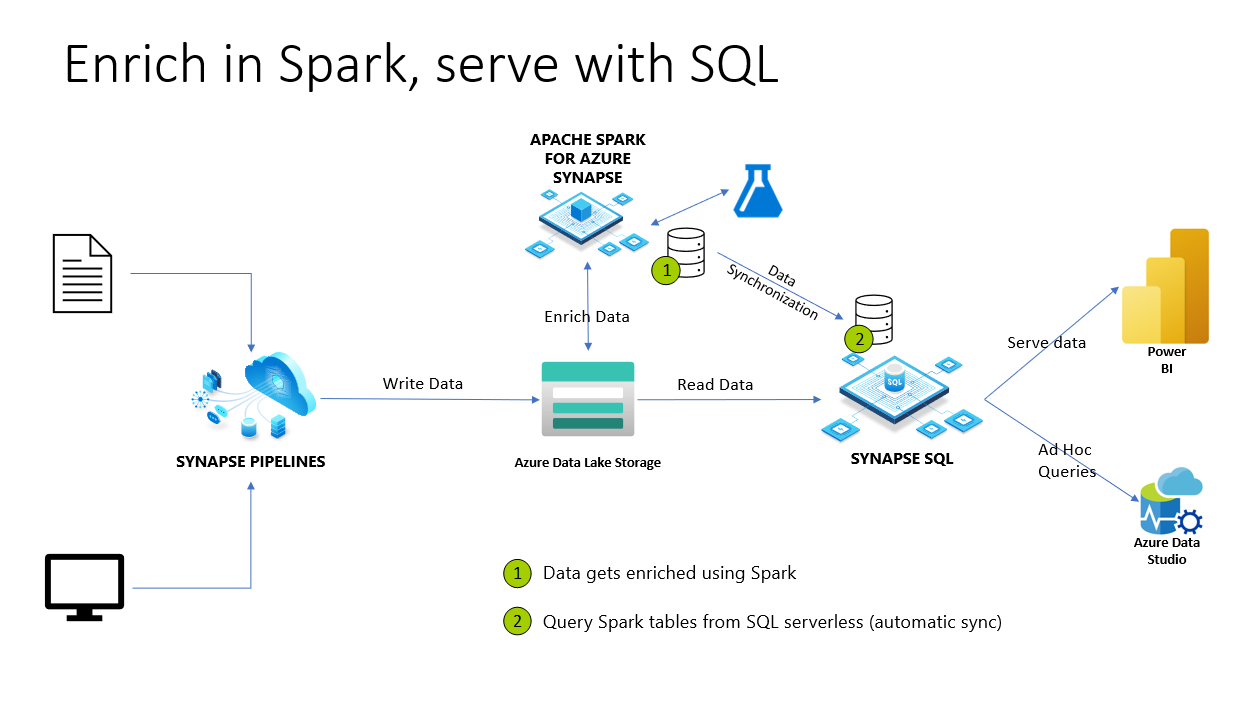
In Azure Synapse Analytics i database e le tabelle Spark vengono condivisi con il pool SQL serverless. I database Lake e le tabelle basate su Parquet e CSV creati con Spark sono automaticamente disponibili nel pool SQL serverless. Questa funzionalità consente di usare il pool SQL serverless per esplorare ed eseguire query sui dati preparati usando i pool di Spark. Nella figura seguente è possibile vedere una panoramica generale dell'architettura per usare questa funzionalità. In primo luogo, le pipeline di Azure Synapse spostano i dati dall'archiviazione locale (o da un'altra archiviazione) ad Azure Data Lake Storage. Spark può ora arricchire i dati e creare database e tabelle che vengono sincronizzati con Synapse SQL serverless. Successivamente, l'utente può eseguire query ad hoc sui dati arricchiti o fornirli, ad esempio, a Power BI.
Accesso amministratore completo (sysadmin)
Dopo la sincronizzazione di questi database e tabelle da Spark al pool SQL serverless, queste tabelle esterne nel pool SQL serverless possono essere usate per accedere agli stessi dati. Tuttavia, gli oggetti nel pool SQL serverless sono di sola lettura per mantenere la coerenza con gli oggetti dei pool Spark. Questa limitazione fa sì che solo gli utenti con il ruolo Amministratore Synapse SQL o SAmministratore Synapse possano accedere a questi oggetti nel pool SQL serverless. Se un utente non amministratore tenta di eseguire una query sul database o sulla tabella sincronizzata, riceverà un errore simile al seguente: External table '<table>' is not accessible because content of directory cannot be listed. nonostante abbiano accesso ai dati negli account di archiviazione sottostanti.
Poiché i database sincronizzati nel pool SQL serverless sono di sola lettura, non possono essere modificati. Se si tenta di creare un utente o di concedere altre autorizzazioni, tali operazioni avranno esito negativo. Per leggere i database sincronizzati, è necessario disporre delle autorizzazioni con privilegi a livello di server, ad esempio sysadmin. Questa limitazione è presente anche nelle tabelle esterne del pool SQL serverless quando si usa Collegamento ad Azure Synapse per Dataverse e le tabelle dei database lake.
Accesso non amministratore ai database sincronizzati
Un utente che deve leggere i dati e creare report in genere non dispone dell'accesso amministratore completo (sysadmin). Questo utente è in genere un analista di dati che deve solo leggere e analizzare i dati usando le tabelle esistenti. Non deve creare nuovi oggetti.
Un utente con autorizzazioni minime deve essere in grado di:
- Connettersi a un database replicato da Spark
- Selezionare i dati tramite tabelle esterne e accedere ai dati ADLS sottostanti.
Dopo aver eseguito lo script di codice riportato di seguito, gli utenti non amministratori disporranno delle autorizzazioni a livello di server per connettersi a qualsiasi database. Gli utenti potranno inoltre visualizzare i dati di tutti gli oggetti a livello di schema, come tabelle o viste. La sicurezza dell'accesso ai dati può essere gestita a livello di archiviazione.
-- Creating Azure AD login (same can be achieved for Azure AD app)
CREATE LOGIN [login@contoso.com] FROM EXTERNAL PROVIDER;
go;
GRANT CONNECT ANY DATABASE to [login@contoso.com];
GRANT SELECT ALL USER SECURABLES to [login@contoso.com];
GO;
Nota
Queste istruzioni devono essere eseguite nel database master, perché sono tutte autorizzazioni a livello di server.
Dopo aver creato un account di accesso e aver concesso le autorizzazioni, gli utenti possono eseguire query sulle tabelle esterne sincronizzate. Questa mitigazione può essere applicata anche ai gruppi di sicurezza di Microsoft Entra.
È possibile gestire una maggiore sicurezza sugli oggetti tramite schemi specifici e bloccare l'accesso a uno schema specifico. La soluzione alternativa richiede una DDL aggiuntiva. Per questo scenario, è possibile creare nuovi database, schemi e viste serverless che punteranno ai dati delle tabelle Spark in ADLS.
L'accesso ai dati nell'account di archiviazione può essere gestito tramite ACL o i normali ruoli proprietario/lettore/collaboratore dei dati dei BLOB di archiviazione per utenti/gruppi di Microsoft Entra. Per le entità servizio (app Microsoft Entra), assicurarsi di usare la configurazione ACL.
Nota
- Se si vuole impedire l'uso di OPENROWSET sui dati, è possibile usare
DENY ADMINISTER BULK OPERATIONS to [login@contoso.com];Per altre informazioni, vedere DENY - Autorizzazioni per server. - Se si vuole impedire l'uso di schemi specifici, è possibile usare
DENY SELECT ON SCHEMA::[schema_name] TO [login@contoso.com];Per altre informazioni, vedere DENY - autorizzazioni per schemi.
Passaggi successivi
Per altre informazioni, vedere Autenticazione SQL.