Ottimizzazione delle prestazioni con viste materializzate usando il pool SQL dedicato in Azure Synapse Analytics
Nel pool SQL dedicato le viste materializzate offrono un metodo a bassa manutenzione per le query analitiche complesse, che consente di ottenere prestazioni veloci senza la necessità di modificare le query. Questo articolo illustra le linee guida generali sull'uso delle viste materializzate.
Confronto tra viste materializzate e viste standard
Il pool SQL supporta le viste standard e le viste materializzate. Entrambe sono tabelle virtuali create con espressioni SELECT e presentate alle query come tabelle logiche. Le viste rivelano la complessità del calcolo dei dati comuni e aggiungono un livello di astrazione alle modifiche dei calcoli, in modo che non sia necessario riscrivere le query.
Una vista standard calcola i dati ogni volta che viene usata. Non sono presenti dati archiviati su disco. Le viste standard vengono in genere usate come strumento per organizzare gli oggetti logici e le query in un database. Per usare una vista standard, una query deve farvi riferimento diretto.
Una vista materializzata precalcola, archivia e gestisce i dati nel pool SQL dedicato esattamente come una tabella. Non è necessario ricalcolare una vista materializzata a ogni utilizzo. Per questo motivo, le query che usano tutti i dati o un subset di dati contenuti in viste materializzate possono ottenere prestazioni più veloci. Ancor meglio, le query possono usare una vista materializzata senza farvi riferimento diretto, pertanto non è necessario modificare il codice dell'applicazione.
La maggior parte dei requisiti di una vista standard è applicabile a una vista materializzata. Per informazioni dettagliate sulla sintassi e sugli altri requisiti delle viste materializzate, vedere CREATE MATERIALIZED VIEW AS SELECT.
| Confronto | Visualizza | Vista materializzata |
|---|---|---|
| Visualizzare la definizione | Archiviata in Azure Data Warehouse. | Archiviata in Azure Data Warehouse. |
| Contenuto della vista | Generato ogni volta che si usa la vista. | Preelaborato e archiviato in Azure Data Warehouse durante la creazione della vista. Aggiornato quando vengono aggiunti dati alle tabelle sottostanti. |
| Aggiornamento dati | Sempre aggiornati | Sempre aggiornati |
| Velocità di recupero dei dati della vista da query complesse | Lente | Veloce |
| Archiviazione aggiuntiva | No | Sì |
| Sintassi | CREATE VIEW | CREATE MATERIALIZED VIEW AS SELECT |
Vantaggi delle viste materializzate
Una vista materializzata progettata in modo corretto offre i vantaggi seguenti:
Il tempo di esecuzione è ridotto per le query complesse con JOIN e funzioni di aggregazione. Più complessa è la query, maggiore è il potenziale di risparmio in fase di esecuzione. Il vantaggio maggiore si ottiene quando il costo di calcolo di una query è elevato e il set di dati risultante è di dimensioni ridotte.
Query Optimizer nel pool SQL dedicato può usare automaticamente le viste materializzate distribuite per migliorare i piani di esecuzione delle query. Questo processo è trasparente per gli utenti, fornendo prestazioni di query più veloci. Inoltre, non è necessario che le query facciano riferimento direttamente alle viste materializzate.
Le viste richiedono poca manutenzione. Una vista materializzata archivia i dati in due posizioni, un indice columnstore cluster per i dati iniziali al momento della creazione della vista e un archivio delta per le modifiche incrementali ai dati. Tutte le modifiche ai dati delle tabelle di base vengono aggiunte automaticamente all'archivio delta in modo sincrono. Un processo in background (motore di tuple) sposta periodicamente i dati dall'archivio delta all'indice columnstore della vista. Grazie a questa progettazione, le query sulle viste materializzate restituiscono gli stessi dati di una query diretta sulle tabelle di base.
I dati in una vista materializzata possono essere distribuiti in modo diverso rispetto alle tabelle di base.
I dati nelle viste materializzate presentano gli stessi vantaggi, in termini di disponibilità elevata e resilienza, dei dati nelle normali tabelle.
Rispetto ad altri provider di data warehouse, le viste materializzate implementate nel pool SQL dedicato offrono anche i vantaggi seguenti:
- Aggiornamento automatico e sincrono dei dati con le modifiche apportate ai dati nelle tabelle di base. Non è richiesta alcuna azione da parte dell'utente.
- Ampio supporto delle funzioni di aggregazione. Vedere CREATE MATERIALIZED VIEW AS SELECT (Transact-SQL).
- Supporto delle raccomandazioni delle viste materializzate specifiche per le query. Vedere EXPLAIN (Transact-SQL).
Scenari comuni
Le viste materializzate vengono in genere usate negli scenari seguenti:
Necessità di migliorare le prestazioni delle query analitiche complesse su dati di grandi dimensioni
Le query analitiche complesse usano in genere più funzioni di aggregazione e join di tabella, che si traducono in operazioni più onerose in termini di calcolo nell'esecuzione della query, ad esempio shuffle e join. Per questo motivo, il completamento di queste query richiede più tempo, in particolare nelle tabelle di grandi dimensioni.
Gli utenti possono creare viste materializzate per i dati restituiti dai normali calcoli delle query. Si elimina così la necessità di ricalcolarli quando sono necessari per le query, riducendo il costo del calcolo e i tempi di risposta.
Necessità di prestazioni più rapide con nessuna o poche modifiche alle query
Le modifiche allo schema e alle query nei data warehouse sono in genere ridotte al minimo necessario per supportare le normali operazioni ETL e la creazione di report. Gli utenti possono usare le viste materializzate per ottimizzare le prestazioni di query, se il costo delle viste può essere compensato dal guadagno in termini di prestazioni di esecuzione delle query.
Rispetto ad altre opzioni di ottimizzazione, ad esempio il ridimensionamento e la gestione delle statistiche, creare e gestire una vista materializzata rappresentano una modifica di produzione molto meno incisiva, che inoltre offre un potenziale di miglioramento delle prestazioni superiore.
- La creazione o la gestione di viste materializzate non influiscono sulle query in esecuzione sulle tabelle di base.
- Query Optimizer può usare automaticamente le viste materializzate distribuite senza un riferimento diretto alla vista in una query. Questa capacità riduce il bisogno di modificare le query nell'ottimizzazione delle prestazioni.
Necessità di una strategia di distribuzione dei dati diversa per velocizzare le prestazioni delle query
Azure Data Warehouse è un sistema distribuito e a elaborazione parallela massiva.
Synapse SQL è un sistema di query distribuito che consente alle aziende di implementare scenari di data warehousing e virtualizzazione dei dati usando esperienze T-SQL standard ben note agli ingegneri dei dati. Espande inoltre le funzionalità di SQL per rispondere ai requisiti di streaming e Machine Learning. I dati in una tabella di data warehouse vengono distribuiti tra 60 nodi usando una delle tre possibili strategie di distribuzione (hash, round robin o replicata).
La distribuzione dei dati si specifica al momento della creazione della tabella e resta invariata finché la tabella non viene eliminata. Poiché la vista materializzata è una tabella virtuale su disco, supporta le distribuzioni dei dati hash e round robin. Gli utenti possono scegliere una distribuzione dei dati diversa rispetto alle tabelle di base, ma ottimale per le prestazioni delle query che usano frequentemente le viste.
Indicazioni per la progettazione
Ecco alcune linee guida generali sull'uso delle viste materializzate per migliorare le prestazioni delle query:
Progettare in base al carico di lavoro
Prima di iniziare a creare viste materializzate, è importante acquisire una conoscenza approfondita del proprio carico di lavoro in termini di modelli di query, importanza, frequenza e dimensioni dei dati risultanti.
Gli utenti possono eseguire l'<istruzione SQL> EXPLAIN WITH_RECOMMENDATIONS per le viste materializzate consigliate da Query Optimizer. Poiché queste raccomandazioni sono specifiche della query, una vista materializzata utile per una singola query potrebbe non essere ottimale per le altre query nello stesso carico di lavoro.
Valutare queste raccomandazioni tenendo a mente le esigenze del carico di lavoro. Le viste materializzate ideali sono quelle che favoriscono le prestazioni del carico di lavoro.
Valutare il compromesso tra query più veloci e costi
Ogni vista materializzata implica un costo di archiviazione dei dati e un costo di gestione. Man mano che i dati nelle tabelle di base cambiano, cambia anche la struttura fisica della vista materializzata e ne aumentano le dimensioni.
Per evitare una riduzione del livello delle prestazioni delle query, ogni vista materializzata viene gestita separatamente dal motore di data warehouse, inclusi lo spostamento di righe dall'archivio delta ai segmenti di indice columnstore e il consolidamento delle modifiche ai dati.
Il carico di lavoro di manutenzione aumenta di pari passo con il numero di viste materializzate e di modifiche alla tabella di base. Gli utenti devono verificare se il costo derivante da tutte le viste materializzate può essere compensato dal miglioramento delle prestazioni delle query.
È possibile eseguire questa query per l'elenco di viste materializzate in un database:
SELECT V.name as materialized_view, V.object_id
FROM sys.views V
JOIN sys.indexes I ON V.object_id= I.object_id AND I.index_id < 2;
Opzioni per ridurre il numero di viste materializzate:
Identificare i set di dati comuni usati spesso dalle query complesse nel carico di lavoro. Creare viste materializzate in cui archiviare questi set di dati, in modo che l'utilità di ottimizzazione possa usarli come blocchi predefiniti durante la creazione dei piani di esecuzione.
Eliminare le viste materializzate che hanno un utilizzo ridotto o che non sono più necessarie. Una vista materializzata disabilitata non richiede manutenzione, ma comporta comunque un costo di archiviazione.
Combinare le viste materializzate create sulla stessa tabella di base o su tabelle simili, anche se i dati non sono sovrapponibili. La combinazione di viste materializzate può produrre una vista di dimensioni maggiori rispetto alla somma delle viste separate, tuttavia il costo di gestione dovrebbe diminuire. Ad esempio:
-- Query 1 would benefit from having a materialized view created with this SELECT statement
SELECT A, SUM(B)
FROM T
GROUP BY A
-- Query 2 would benefit from having a materialized view created with this SELECT statement
SELECT C, SUM(D)
FROM T
GROUP BY C
-- You could create a single materialized view of this form
SELECT A, C, SUM(B), SUM(D)
FROM T
GROUP BY A, C
Non tutte le ottimizzazioni delle prestazioni richiedono una modifica delle query
L'utilità di ottimizzazione del data warehouse può usare automaticamente le viste materializzate distribuite per migliorare l'esecuzione delle query. Questo supporto viene applicato in modo trasparente alle query che non fanno riferimento alle viste e alle query che usano aggregazioni non supportate nella creazione di viste materializzate. Non è necessario apportare alcuna modifica alle query. È possibile controllare il piano di esecuzione stimato di una query per verificare se viene usata una vista materializzata.
- Per altre informazioni sul recupero del piano di esecuzione effettivo, vedere Monitorare il carico di lavoro del pool SQL dedicato di Azure Synapse Analytics tramite DMV.
- È possibile recuperare un piano di esecuzione stimato tramite SQL Server Management Studio (SSMS) o SET SHOWPLAN_XML.
Monitorare le viste materializzate
Una vista materializzata viene archiviata nel data warehouse come se si trattasse una tabella con indice columnstore cluster (CCI). La lettura dei dati da una vista materializzata include l'analisi dell'indice e l'applicazione di modifiche dall'archivio delta. Quando il numero di righe nell'archivio delta è troppo elevato, la risoluzione di una query da una vista materializzata può richiedere più tempo rispetto a una query diretta sulle tabelle di base.
Per evitare la riduzione del livello delle prestazioni delle query, è consigliabile eseguire DBCC PDW_SHOWMATERIALIZEDVIEWOVERHEAD per monitorare il rapporto di overhead della vista (total_rows/base_view_row). Se il valore di overhead_ratio è troppo elevato, provare a ricompilare la vista materializzata in modo che tutte le righe nell'archivio delta vengano spostate nell'indice columnstore.
Vista materializzata e memorizzazione nella cache del set di risultati
Queste due funzionalità si introducono nel pool SQL dedicato pressappoco nello stesso momento per ottimizzare le prestazioni delle query. La memorizzazione nella cache del set di risultati si usa per ottenere una concorrenza elevata e tempi di risposta rapidi dalle query ripetitive sui dati statici.
Per usare il risultato memorizzato nella cache, la forma della query di richiesta della cache deve corrispondere alla query che ha generato la cache. Inoltre, il risultato memorizzato nella cache deve essere applicabile all'intera query.
Le viste materializzate consentono di apportare modifiche ai dati nelle tabelle di base. I dati nelle viste materializzate possono essere applicati a una parte di una query. Questo supporto consente l'uso delle stesse viste materializzate da parte di query diverse che condividono alcuni calcoli, allo scopo di ottenere prestazioni più veloci.
Esempio
In questo esempio viene usata una query di tipo TPCDS che trova i clienti che spendono più denaro tramite il catalogo che nei negozi. Identifica inoltre i clienti preferiti e il paese/area geografica di origine. La query prevede la selezione dei primi 100 record risultanti dall'esecuzione di un'istruzione UNION su tre istruzioni sub-SELECT che includono operazioni SUM() e GROUP BY.
WITH year_total AS (
SELECT c_customer_id customer_id
,c_first_name customer_first_name
,c_last_name customer_last_name
,c_preferred_cust_flag customer_preferred_cust_flag
,c_birth_country customer_birth_country
,c_login customer_login
,c_email_address customer_email_address
,d_year dyear
,sum(isnull(ss_ext_list_price-ss_ext_wholesale_cost-ss_ext_discount_amt+ss_ext_sales_price, 0)/2) year_total
,'s' sale_type
FROM customer
,store_sales
,date_dim
WHERE c_customer_sk = ss_customer_sk
AND ss_sold_date_sk = d_date_sk
GROUP BY c_customer_id
,c_first_name
,c_last_name
,c_preferred_cust_flag
,c_birth_country
,c_login
,c_email_address
,d_year
UNION ALL
SELECT c_customer_id customer_id
,c_first_name customer_first_name
,c_last_name customer_last_name
,c_preferred_cust_flag customer_preferred_cust_flag
,c_birth_country customer_birth_country
,c_login customer_login
,c_email_address customer_email_address
,d_year dyear
,sum(isnull(cs_ext_list_price-cs_ext_wholesale_cost-cs_ext_discount_amt+cs_ext_sales_price, 0)/2) year_total
,'c' sale_type
FROM customer
,catalog_sales
,date_dim
WHERE c_customer_sk = cs_bill_customer_sk
AND cs_sold_date_sk = d_date_sk
GROUP BY c_customer_id
,c_first_name
,c_last_name
,c_preferred_cust_flag
,c_birth_country
,c_login
,c_email_address
,d_year
UNION ALL
SELECT c_customer_id customer_id
,c_first_name customer_first_name
,c_last_name customer_last_name
,c_preferred_cust_flag customer_preferred_cust_flag
,c_birth_country customer_birth_country
,c_login customer_login
,c_email_address customer_email_address
,d_year dyear
,sum(isnull(ws_ext_list_price-ws_ext_wholesale_cost-ws_ext_discount_amt+ws_ext_sales_price, 0)/2) year_total
,'w' sale_type
FROM customer
,web_sales
,date_dim
WHERE c_customer_sk = ws_bill_customer_sk
AND ws_sold_date_sk = d_date_sk
GROUP BY c_customer_id
,c_first_name
,c_last_name
,c_preferred_cust_flag
,c_birth_country
,c_login
,c_email_address
,d_year
)
SELECT TOP 100
t_s_secyear.customer_id
,t_s_secyear.customer_first_name
,t_s_secyear.customer_last_name
,t_s_secyear.customer_birth_country
FROM year_total t_s_firstyear
,year_total t_s_secyear
,year_total t_c_firstyear
,year_total t_c_secyear
,year_total t_w_firstyear
,year_total t_w_secyear
WHERE t_s_secyear.customer_id = t_s_firstyear.customer_id
AND t_s_firstyear.customer_id = t_c_secyear.customer_id
AND t_s_firstyear.customer_id = t_c_firstyear.customer_id
AND t_s_firstyear.customer_id = t_w_firstyear.customer_id
AND t_s_firstyear.customer_id = t_w_secyear.customer_id
AND t_s_firstyear.sale_type = 's'
AND t_c_firstyear.sale_type = 'c'
AND t_w_firstyear.sale_type = 'w'
AND t_s_secyear.sale_type = 's'
AND t_c_secyear.sale_type = 'c'
AND t_w_secyear.sale_type = 'w'
AND t_s_firstyear.dyear+0 = 1999
AND t_s_secyear.dyear+0 = 1999+1
AND t_c_firstyear.dyear+0 = 1999
AND t_c_secyear.dyear+0 = 1999+1
AND t_w_firstyear.dyear+0 = 1999
AND t_w_secyear.dyear+0 = 1999+1
AND t_s_firstyear.year_total > 0
AND t_c_firstyear.year_total > 0
AND t_w_firstyear.year_total > 0
AND CASE WHEN t_c_firstyear.year_total > 0 THEN t_c_secyear.year_total / t_c_firstyear.year_total ELSE NULL END
> CASE WHEN t_s_firstyear.year_total > 0 THEN t_s_secyear.year_total / t_s_firstyear.year_total ELSE NULL END
AND CASE WHEN t_c_firstyear.year_total > 0 THEN t_c_secyear.year_total / t_c_firstyear.year_total ELSE NULL END
> CASE WHEN t_w_firstyear.year_total > 0 THEN t_w_secyear.year_total / t_w_firstyear.year_total ELSE NULL END
ORDER BY t_s_secyear.customer_id
,t_s_secyear.customer_first_name
,t_s_secyear.customer_last_name
,t_s_secyear.customer_birth_country
OPTION ( LABEL = 'Query04-af359846-253-3');
Controllare il piano di esecuzione stimato della query. Sono presenti 18 operazioni di shuffle e 17 join, la cui esecuzione richiede più tempo.
Creare ora una vista materializzata per ognuna delle tre istruzioni sub-SELECT.
CREATE materialized view nbViewSS WITH (DISTRIBUTION=HASH(customer_id)) AS
SELECT c_customer_id customer_id
,c_first_name customer_first_name
,c_last_name customer_last_name
,c_preferred_cust_flag customer_preferred_cust_flag
,c_birth_country customer_birth_country
,c_login customer_login
,c_email_address customer_email_address
,d_year dyear
,sum(isnull(ss_ext_list_price-ss_ext_wholesale_cost-ss_ext_discount_amt+ss_ext_sales_price, 0)/2) year_total
, count_big(*) AS cb
FROM dbo.customer
,dbo.store_sales
,dbo.date_dim
WHERE c_customer_sk = ss_customer_sk
AND ss_sold_date_sk = d_date_sk
GROUP BY c_customer_id
,c_first_name
,c_last_name
,c_preferred_cust_flag
,c_birth_country
,c_login
,c_email_address
,d_year
GO
CREATE materialized view nbViewCS WITH (DISTRIBUTION=HASH(customer_id)) AS
SELECT c_customer_id customer_id
,c_first_name customer_first_name
,c_last_name customer_last_name
,c_preferred_cust_flag customer_preferred_cust_flag
,c_birth_country customer_birth_country
,c_login customer_login
,c_email_address customer_email_address
,d_year dyear
,sum(isnull(cs_ext_list_price-cs_ext_wholesale_cost-cs_ext_discount_amt+cs_ext_sales_price, 0)/2) year_total
, count_big(*) as cb
FROM dbo.customer
,dbo.catalog_sales
,dbo.date_dim
WHERE c_customer_sk = cs_bill_customer_sk
AND cs_sold_date_sk = d_date_sk
GROUP BY c_customer_id
,c_first_name
,c_last_name
,c_preferred_cust_flag
,c_birth_country
,c_login
,c_email_address
,d_year
GO
CREATE materialized view nbViewWS WITH (DISTRIBUTION=HASH(customer_id)) AS
SELECT c_customer_id customer_id
,c_first_name customer_first_name
,c_last_name customer_last_name
,c_preferred_cust_flag customer_preferred_cust_flag
,c_birth_country customer_birth_country
,c_login customer_login
,c_email_address customer_email_address
,d_year dyear
,sum(isnull(ws_ext_list_price-ws_ext_wholesale_cost-ws_ext_discount_amt+ws_ext_sales_price, 0)/2) year_total
, count_big(*) AS cb
FROM dbo.customer
,dbo.web_sales
,dbo.date_dim
WHERE c_customer_sk = ws_bill_customer_sk
AND ws_sold_date_sk = d_date_sk
GROUP BY c_customer_id
,c_first_name
,c_last_name
,c_preferred_cust_flag
,c_birth_country
,c_login
,c_email_address
,d_year
Controllare di nuovo il piano di esecuzione della query originale. A questo punto, il numero di operazioni di join passa da 17 a 5 e non ci sono più shuffle. Selezionare l'icona dell'operazione di filtro nel piano. L'elenco di output mostra che i dati vengono letti dalle viste materializzate anziché dalle tabelle di base.
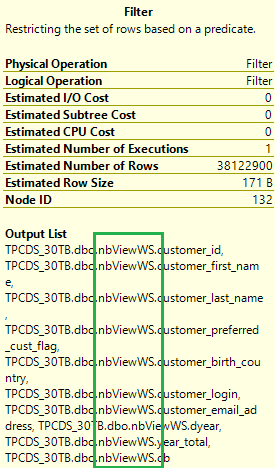
Con le viste materializzate, la stessa query viene eseguita molto più velocemente senza alcuna modifica del codice.
Passaggi successivi
Per altri suggerimenti sullo sviluppo, vedere Synapse SQL pool development overview (Panoramica sullo sviluppo per il pool Synapse SQL).