Architettura del pool SQL dedicato (in precedenza SQL DW) in Azure Synapse Analytics
Azure Synapse Analytics è un servizio di analisi che riunisce funzionalità aziendali di data warehousing e analisi di Big Data. Offre la libertà di eseguire query sui dati in base alle proprie condizioni.
Nota
Per altre informazioni su Azure Synapse Analytics, guardare questo video che illustra i miglioramenti dello spostamento dei dati.
Componenti dell'architettura di Synapse SQL
Pool SQL (in precedenza SQL DW) dedicato usa un'architettura scale-out per distribuire l'elaborazione computazionale dei dati su più nodi. L'unità di scalabilità è un'astrazione della potenza di calcolo nota come unità di data warehouse. Poiché le risorse di calcolo sono separate dall'archiviazione, è possibile ridimensionarle indipendentemente dai dati presenti nel sistema.
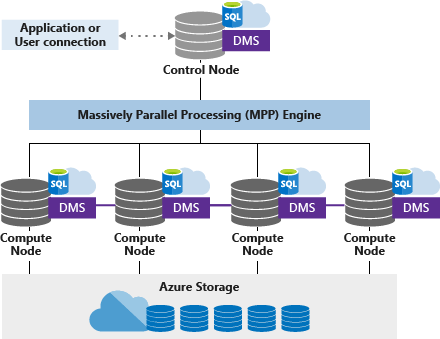
Il pool SQL dedicato (in precedenza SQL DW) usa un'architettura basata su nodi. Le applicazioni si connettono ed emettono comandi T-SQL a un nodo di controllo. Il nodo di controllo ospita il motore delle query distribuite, che ottimizza le query per l'elaborazione parallela e quindi passa le operazioni ai nodi di calcolo per l'elaborazione in parallelo.
I nodi di calcolo archiviano tutti i dati utente in Archiviazione di Azure ed eseguono le query parallele. Data Movement Service (DMS) è un servizio interno a livello di sistema che sposta i dati tra i nodi per eseguire query in parallelo e restituire risultati accurati.
Con le risorse di archiviazione e di calcolo separate, quando si usa il pool Synapse SQL dedicato (in precedenza SQL DW) è possibile:
- Ridimensionare la potenza di calcolo indipendentemente dalle esigenze di archiviazione.
- Aumentare o ridurre la potenza di calcolo all'interno di un pool SQL (in precedenza SQL DW) dedicato senza spostare i dati.
- Sospendere la capacità di calcolo mantenendo intatti i dati e consentendo di pagare solo per l'archiviazione.
- Ripristinare le capacità di calcolo durante l'orario operativo.
Archiviazione di Azure
Il pool SQL dedicato SQL (in precedenza SQL DW) sfrutta Archiviazione di Azure per proteggere i dati utente. Poiché i dati vengono archiviati e gestiti da Archiviazione di Azure, è previsto un addebito separato per l'uso dello spazio di archiviazione. I dati sono partizionati in distribuzioni per ottimizzare le prestazioni del sistema. È possibile scegliere il modello di partizionamento orizzontale da usare per distribuire i dati quando si definisce la tabella. Sono supportati i modelli di partizionamento seguenti:
- Hash
- Round Robin
- Replica
Nodo di controllo
Il nodo di controllo è il componente principale dell'architettura. È il front-end che interagisce con tutte le applicazioni e le connessioni. Il motore di query distribuite viene eseguito nel nodo di controllo al fine di ottimizzare e coordinare le query parallele. Quando si invia una query T-SQL, il nodo di controllo la trasforma in query che verranno eseguite in ogni distruzione in parallelo.
Nodi di calcolo
I nodi di calcolo forniscono la potenza di calcolo. Viene eseguito il mapping delle distribuzioni ai nodi di calcolo per l'elaborazione. Quando si ottengono risorse di calcolo aggiuntive a pagamento, viene eseguito il mapping delle distribuzioni ai nodi di calcolo disponibili. Il numero di nodi di calcolo è compreso tra 1 e 60 e viene determinato in base al livello di servizio associato a Synapse SQL.
Ogni nodo di calcolo ha un ID visibile nelle visualizzazioni di sistema. È possibile individuare l'ID del nodo di calcolo cercando la colonna node_id nelle visualizzazioni di sistema il cui nome inizia con sys.pdw_nodes. Per un elenco delle visualizzazioni di sistema, vedere le visualizzazioni di sistema di Synapse SQL.
Data Movement Service
Data Movement Service (DMS) è la tecnologia di trasporto dei dati che coordina lo spostamento dei dati da un nodo di calcolo all'altro. Alcune query richiedono lo spostamento dei dati per garantire che le query parallele restituiscano risultati accurati. Quando lo spostamento dei dati è necessario, DMS assicura che i dati corretti vengano spostati nel percorso corretto.
Distribuzioni
La distribuzione è l'unità di base dell'archiviazione e dell'elaborazione di query parallele eseguite su dati distribuiti. Quando Synapse SQL esegue una query, il processo viene suddiviso in 60 query di dimensioni più piccole che vengono eseguite in parallelo.
Ognuna delle 60 query viene eseguita in una distribuzione dei dati. Ogni nodo di calcolo gestisce una o più delle 60 distribuzioni. Un pool SQL dedicato (in precedenza SWL DW) con il numero massimo di risorse di calcolo ha un'unica distribuzione per ogni nodo di calcolo. Un pool SQL dedicato (in precedenza SQL DW) con il numero minimo di risorse di calcolo ha tutte le distribuzioni in un unico nodo di calcolo.
Nota
Per consigli sulla migliore strategia di distribuzione delle tabelle da usare in base ai carichi di lavoro, vedere Azure Synapse SQL Distribution Advisor.
Tabelle con distribuzione hash
Una tabella con distribuzione hash offre le prestazioni di query più elevate per join e aggregazioni in tabelle di grandi dimensioni.
Per partizionare i dati in una tabella con distribuzione hash, viene usata una funzione hash per assegnare in modo deterministico ogni riga a un'unica distribuzione. Nella definizione della tabella una delle colonne è definita come colonna di distribuzione. La funzione hash usa i valori della colonna di distribuzione per assegnare ogni riga a una distribuzione.
Il diagramma seguente illustra come una tabella completa (nonstributed) venga archiviata come tabella con distribuzione hash.

- Ogni riga appartiene a una sola distribuzione.
- Un algoritmo hash deterministico assegna ogni riga a una sola distribuzione.
- Il numero di righe di tabella per distribuzione varia come mostrano le diverse dimensioni delle tabelle.
Ai fini delle prestazioni, per la selezione di una colonna di distribuzione è necessario considerare alcuni aspetti, ad esempio la specificità, la differenza dei dati e i tipi di query eseguite nel sistema.
Tabelle con distribuzione round robin
La tabella round robin è la tabella più semplice da creare e offre ottime prestazioni quando viene usata come tabella di staging per i caricamenti.
Una tabella con distribuzione round robin distribuisce i dati in modo uniforme all'interno della tabella senza alcuna ottimizzazione aggiuntiva. Viene innanzitutto selezionata casualmente una distribuzione, quindi i buffer di righe vengono assegnati in sequenza alle distribuzioni. Sebbene il caricamento dei dati in una tabella round robin risulti rapido, è spesso possibile ottenere prestazioni di query migliori con le tabelle con distribuzione hash. Per i join nelle tabelle round robin è necessaria una ridistribuzione dei dati, che richiede più tempo.
Tabelle replicate
Una tabella replicata offre le migliori prestazioni di query per le tabelle di piccole dimensioni.
Una tabella replicata memorizza nella cache una copia completa della tabella in ogni nodo di calcolo. Di conseguenza, la replica di una tabella elimina la necessità di trasferire i dati tra i nodi di calcolo prima di un join o un'aggregazione. Le tabelle replicate sono particolarmente adatte all'uso con tabelle di piccole dimensioni. È necessario più spazio di archiviazione e si verifica un sovraccarico aggiuntivo durante la scrittura dei dati, che impedisce l'uso di tabelle di grandi dimensioni.
Il diagramma seguente mostra una tabella replicata memorizzata nella cache durante la prima distribuzione in ogni nodo di calcolo.

Contenuto correlato
Dopo aver appreso alcune informazioni su Azure Synapse, vedere come creare rapidamente un pool SQL dedicato (in precedenza SQL DW) e caricare dati di esempio. Se non si ha ancora una conoscenza di Azure, è possibile trovare i concetti fondamentali di Azure utili quando si riscontrano nuove terminologie. In alternativa, vedere alcune delle altre risorse disponibili per Azure Synapse.