Connettore del pool SQL dedicato di Azure Synapse per Apache Spark
Introduzione
Il connettore del pool SQL dedicato di Azure Synapse per Apache Spark in Azure Synapse Analytics consente il trasferimento efficiente di set di dati di grandi dimensioni tra il runtime di Apache Spark e il pool SQL dedicato. Il connettore viene fornito come libreria predefinita con l'area di lavoro Azure Synapse. Il connettore viene implementato usando il linguaggio Scala. Il connettore supporta Scala e Python. Per usare il connettore con altre opzioni del linguaggio del notebook, usare il comando magic Spark - %%spark.
A livello elevato, il connettore offre le funzionalità seguenti:
- Leggere dal pool SQL dedicato di Azure Synapse:
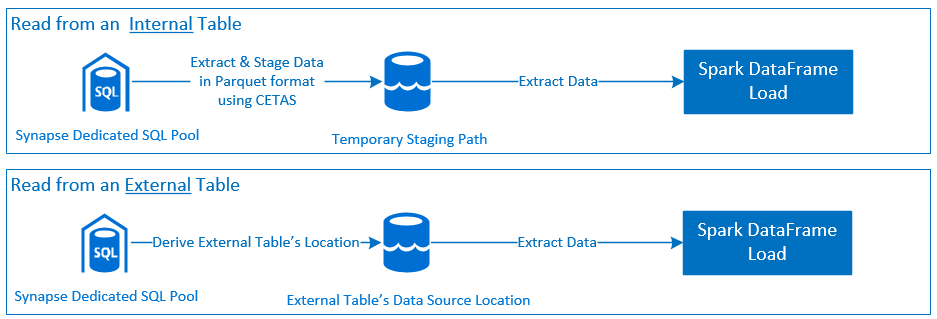
- Leggere set di dati di grandi dimensioni dalle tabelle (interne ed esterne) e dalle viste del pool SQL dedicato di Synapse.
- Supporto completo per il push down del predicato, in cui i filtri sul DataFrame vengono mappati al push down del predicato SQL corrispondente.
- Supporto per l'eliminazione delle colonne.
- Supporto per il push delle query.
- Scrivere in pool SQL dedicato di Azure Synapse:
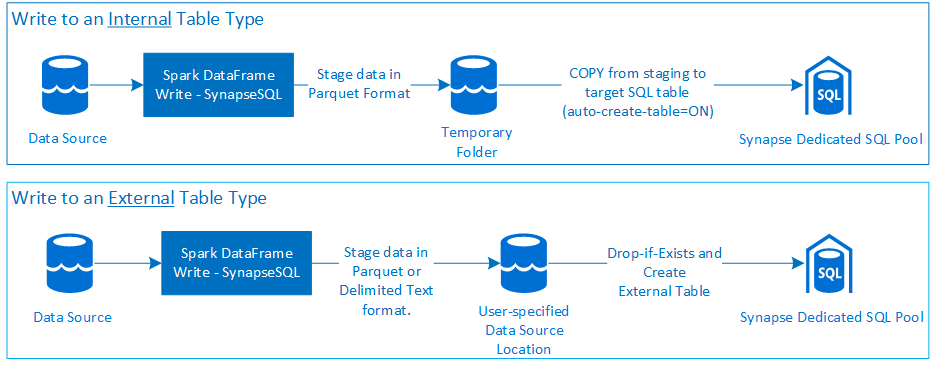
- Inserire dati di volumi di grandi dimensioni in tipi di tabella interni ed esterni.
- Supporta le preferenze della modalità di salvataggio del DataFrame seguenti:
AppendErrorIfExistsIgnoreOverwrite
- La scrittura in tipo tabella esterna supporta il formato di file Parquet e Testo delimitato (ad esempio - CSV).
- Per scrivere dati in tabelle interne, il connettore usa ora l'istruzione COPY anziché l'approccio CETAS/CTAS.
- Miglioramenti per ottimizzare le prestazioni della velocità effettiva di scrittura end-to-end.
- Introduce un handle di callback facoltativo (argomento della funzione Scala) che i client possono usare per ricevere metriche post-scrittura.
- Alcuni esempi includono il numero di record, la durata per completare determinate azioni e il motivo dell'errore.
Approccio di orchestrazione
Lettura
Scrittura
Prerequisiti
I prerequisiti, ad esempio la configurazione delle risorse di Azure necessarie e i passaggi per configurarli, sono descritti in questa sezione.
Risorse di Azure
Esaminare e configurare le risorse di Azure dipendenti seguenti:
- Azure Data Lake Storage - usato come account di archiviazione primario per l'area di lavoro di Azure Synapse.
- Area di lavoro di Azure Synapse - creare notebook, compilare e distribuire flussi di lavoro in ingresso basati su DataFrame.
- Pool SQL dedicato (in precedenza SQL DW) - offre funzionalità di Data Warehousing aziendali.
- Pool di Spark serverless di Azure Synapse - runtime Spark in cui i processi vengono eseguiti come applicazioni Spark.
Preparare il database
Connettersi al database del pool SQL dedicato di Synapse ed eseguire le istruzioni di installazione seguenti:
Creare un utente di database mappato all'identità utente di Microsoft Entra usata per accedere all'area di lavoro di Azure Synapse.
CREATE USER [username@domain.com] FROM EXTERNAL PROVIDER;Creare uno schema in cui verranno definite le tabelle, in modo che il Connettore possa scrivere e leggere correttamente dalle rispettive tabelle.
CREATE SCHEMA [<schema_name>];
Autenticazione
Autenticazione basata su Microsoft Entra ID
L'autenticazione basata su Microsoft Entra ID è un approccio di autenticazione integrato. L'utente deve accedere correttamente all'area di lavoro di Azure Synapse Analytics.
Autenticazione di base
Un approccio di autenticazione di base richiede all'utente di configurare le opzioni username e password. Fare riferimento alla sezione Opzioni di configurazione per informazioni sui parametri di configurazione pertinenti per la lettura e la scrittura nelle tabelle nel pool SQL dedicato di Azure Synapse.
Autorizzazione
Azure Data Lake Storage Gen2
Esistono due modi per concedere le autorizzazioni di accesso ad Azure Data Lake Storage Gen2 - Account di archiviazione:
- Ruolo controllo degli accessi in base al ruolo - Ruolo Collaboratore ai dati del BLOB di archiviazione
- L'assegnazione di concede all'utente
Storage Blob Data Contributor Rolele autorizzazioni di lettura, scrittura ed eliminazione dai contenitori BLOB Archiviazione di Azure. - Il controllo degli accessi in base al ruolo offre un approccio di controllo grossolano a livello di contenitore.
- L'assegnazione di concede all'utente
- Elenchi di controllo di accesso (ACL)
- L'approccio ACL consente controlli con granularità fine su percorsi e/o file specifici in una determinata cartella.
- I controlli ACL non vengono applicati se l'utente ha già concesso le autorizzazioni usando l'approccio di controllo degli accessi in base al ruolo.
- Esistono due tipi generali di autorizzazioni ACL:
- Autorizzazioni di accesso (applicate a un livello o a un oggetto specifico).
- Autorizzazioni predefinite (applicate automaticamente per tutti gli oggetti figlio al momento della creazione).
- Il tipo di autorizzazioni include:
Executeconsente di attraversare o esplorare le gerarchie di cartelle.Readconsente di leggere.Writeconsente di scrivere.
- È importante configurare gli elenchi di controllo di accesso in modo che il connettore possa scrivere e leggere correttamente dai percorsi di archiviazione.
Nota
Se si desidera eseguire notebook usando le pipeline dell'area di lavoro di Synapse, è necessario concedere anche le autorizzazioni di accesso elencate in precedenza all'identità gestita predefinita dell'area di lavoro di Synapse. Il nome predefinito dell'identità gestita dell'area di lavoro corrisponde al nome dell'area di lavoro.
Per usare l'area di lavoro Synapse con account di archiviazione protetti, è necessario configurare un endpoint privato gestito dal notebook. L'endpoint privato gestito deve essere approvato dalla sezione
Private endpoint connectionsdell'account di archiviazione di ADLS Gen2 nel riquadroNetworking.
Azure Synapse: pool SQL dedicato
Per abilitare l'interazione riuscita con il pool SQL dedicato di Azure Synapse, è necessaria l'autorizzazione seguente, a meno che non si sia un utente configurato anche come Active Directory Admin nell'endpoint SQL dedicato:
Scenario di lettura
Concedere all'utente
db_exporterl’uso della stored procedure di sistemasp_addrolemember.EXEC sp_addrolemember 'db_exporter', [<your_domain_user>@<your_domain_name>.com];
Scenario di scrittura
- Il connettore usa il comando COPY per scrivere dati dalla gestione temporanea alla posizione gestita della tabella interna.
Configurare le autorizzazioni necessarie descritte qui.
Di seguito è riportato un frammento di accesso rapido dello stesso:
--Make sure your user has the permissions to CREATE tables in the [dbo] schema GRANT CREATE TABLE TO [<your_domain_user>@<your_domain_name>.com]; GRANT ALTER ON SCHEMA::<target_database_schema_name> TO [<your_domain_user>@<your_domain_name>.com]; --Make sure your user has ADMINISTER DATABASE BULK OPERATIONS permissions GRANT ADMINISTER DATABASE BULK OPERATIONS TO [<your_domain_user>@<your_domain_name>.com]; --Make sure your user has INSERT permissions on the target table GRANT INSERT ON <your_table> TO [<your_domain_user>@<your_domain_name>.com]
- Il connettore usa il comando COPY per scrivere dati dalla gestione temporanea alla posizione gestita della tabella interna.
Documentazione sull'API
Connettore del pool SQL dedicato di Azure Synapse per Apache Spark - Documentazione API.
Opzioni di configurazione
Per eseguire correttamente il bootstrap e orchestrare l'operazione di lettura o scrittura, il connettore prevede determinati parametri di configurazione. La definizione dell'oggetto - com.microsoft.spark.sqlanalytics.utils.Constants fornisce un elenco di costanti standardizzate per ogni chiave di parametro.
Di seguito è riportato l'elenco delle opzioni di configurazione in base allo scenario di utilizzo:
- Lettura con l'autenticazione basata su Microsoft Entra ID
- Le credenziali vengono mappate automaticamente e l'utente non è necessario per fornire opzioni di configurazione specifiche.
- L'argomento nome tabella in tre parti sul metodo
synapsesqlè necessario per leggere dalla rispettiva tabella nel pool SQL dedicato di Azure Synapse.
- Lettura tramite l’autenticazione di base
- Endpoint SQL dedicato di Azure Synapse
Constants.SERVER- Punto finale del pool SQL dedicato di Synapse (FQDN server)Constants.USER- Nome utente SQL.Constants.PASSWORD- Password utente SQL.
- Endpoint di Azure Data Lake Storage (Gen 2) - Cartelle di staging
Constants.DATA_SOURCE- Il percorso di archiviazione impostato nel parametro del percorso dell'origine dati viene usato per la gestione temporanea dei dati.
- Endpoint SQL dedicato di Azure Synapse
- Scrivere usando l'autenticazione basata su Microsoft Entra ID
- Endpoint SQL dedicato di Azure Synapse
- Per impostazione predefinita, il connettore deduce l'endpoint SQL dedicato di Synapse usando il nome del database impostato nel parametro del nome della tabella in tre parti del metodo
synapsesql. - In alternativa, gli utenti possono usare l'opzione
Constants.SERVERper specificare l'endpoint sql. Verificare che il punto finale ospiti il database corrispondente con lo schema corrispondente.
- Per impostazione predefinita, il connettore deduce l'endpoint SQL dedicato di Synapse usando il nome del database impostato nel parametro del nome della tabella in tre parti del metodo
- Endpoint di Azure Data Lake Storage (Gen 2) - Cartelle di staging
- Per tipo di tabella interna:
- Configurare l'opzione
Constants.TEMP_FOLDERoConstants.DATA_SOURCE. - Se l'utente ha scelto di fornire un'opzione
Constants.DATA_SOURCE, la cartella di staging verrà derivata usando il valorelocationdi DataSource. - Se vengono specificati entrambi, verrà usato il valore dell'opzione
Constants.TEMP_FOLDER. - In assenza di un'opzione di cartella di staging, il connettore ne deriva uno in base alla configurazione di runtime -
spark.sqlanalyticsconnector.stagingdir.prefix.
- Configurare l'opzione
- Per il tipo di tabella esterna:
Constants.DATA_SOURCEè una configurazione necessaria.- Il connettore usa il percorso di archiviazione impostato nel parametro location dell'origine dati in combinazione con l'argomento
locational metodosynapsesqle deriva il percorso assoluto per rendere persistenti i dati della tabella esterna. - Se l'argomento
locational metodosynapsesqlnon viene specificato, il connettore deriva il valore della posizione come<base_path>/dbName/schemaName/tableName.
- Per tipo di tabella interna:
- Endpoint SQL dedicato di Azure Synapse
- Scrittura tramite l’autenticazione di base
- Endpoint SQL dedicato di Azure Synapse
Constants.SERVER- - Punto finale del pool SQL dedicato di Synapse (FQDN server).Constants.USER- Nome utente SQL.Constants.PASSWORD- Password utente SQL.Constants.STAGING_STORAGE_ACCOUNT_KEYassociato all'account di archiviazione che ospitaConstants.TEMP_FOLDERS(solo tipi di tabella interni) oConstants.DATA_SOURCE.
- Endpoint di Azure Data Lake Storage (Gen 2) - Cartelle di staging
- Le credenziali di autenticazione di base di SQL non si applicano ai punti finali di archiviazione.
- Assicurarsi quindi di assegnare autorizzazioni di accesso alle risorse di archiviazione pertinenti, come descritto nella sezione Azure Data Lake Storage Gen2.
- Endpoint SQL dedicato di Azure Synapse
Modelli di codice
Questa sezione presenta modelli di codice di riferimento per descrivere come usare e richiamare il connettore del pool SQL dedicato di Azure Synapse per Apache Spark.
Nota
Uso del connettore in Python-
- Il connettore è supportato solo in Python per Spark 3. Per Spark 2.4 (non supportato),è possibile usare l'API del connettore Scala per interagire con il contenuto di un DataFrame in PySpark usando DataFrame.createOrReplaceTempView o DataFrame.createOrReplaceGlobalTempView. Vedere la sezione - Uso di dati materializzati tra le celle.
- L'handle di callback non è disponibile in Python.
Leggere dal pool SQL dedicato di Azure Synapse
Richiesta di lettura - firma del metodo synapsesql
Leggere da una tabella usando l'autenticazione basata su Microsoft Entra ID
//Use case is to read data from an internal table in Synapse Dedicated SQL Pool DB
//Azure Active Directory based authentication approach is preferred here.
import org.apache.spark.sql.DataFrame
import com.microsoft.spark.sqlanalytics.utils.Constants
import org.apache.spark.sql.SqlAnalyticsConnector._
//Read from existing internal table
val dfToReadFromTable:DataFrame = spark.read.
//If `Constants.SERVER` is not provided, the `<database_name>` from the three-part table name argument
//to `synapsesql` method is used to infer the Synapse Dedicated SQL End Point.
option(Constants.SERVER, "<sql-server-name>.sql.azuresynapse.net").
//Defaults to storage path defined in the runtime configurations
option(Constants.TEMP_FOLDER, "abfss://<container_name>@<storage_account_name>.dfs.core.windows.net/<some_base_path_for_temporary_staging_folders>").
//Three-part table name from where data will be read.
synapsesql("<database_name>.<schema_name>.<table_name>").
//Column-pruning i.e., query select column values.
select("<some_column_1>", "<some_column_5>", "<some_column_n>").
//Push-down filter criteria that gets translated to SQL Push-down Predicates.
filter(col("Title").startsWith("E")).
//Fetch a sample of 10 records
limit(10)
//Show contents of the dataframe
dfToReadFromTable.show()
Leggere da una query usando l'autenticazione basata su Microsoft Entra ID
Nota
Restrizioni durante la lettura dalla query:
- Non è possibile specificare contemporaneamente il nome e la query della tabella.
- Sono consentite solo determinate query. Gli SQL DDL e DML non sono consentiti.
- Le opzioni di selezione e filtro nel DataFrame non vengono spostate nel pool dedicato SQL quando viene specificata una query.
- La lettura da una query è disponibile solo in Spark 3.
//Use case is to read data from an internal table in Synapse Dedicated SQL Pool DB
//Azure Active Directory based authentication approach is preferred here.
import org.apache.spark.sql.DataFrame
import com.microsoft.spark.sqlanalytics.utils.Constants
import org.apache.spark.sql.SqlAnalyticsConnector._
// Read from a query
// Query can be provided either as an argument to synapsesql or as a Constant - Constants.QUERY
val dfToReadFromQueryAsOption:DataFrame = spark.read.
// Name of the SQL Dedicated Pool or database where to run the query
// Database can be specified as a Spark Config - spark.sqlanalyticsconnector.dw.database or as a Constant - Constants.DATABASE
option(Constants.DATABASE, "<database_name>").
//If `Constants.SERVER` is not provided, the `<database_name>` from the three-part table name argument
//to `synapsesql` method is used to infer the Synapse Dedicated SQL End Point.
option(Constants.SERVER, "<sql-server-name>.sql.azuresynapse.net").
//Defaults to storage path defined in the runtime configurations
option(Constants.TEMP_FOLDER, "abfss://<container_name>@<storage_account_name>.dfs.core.windows.net/<some_base_path_for_temporary_staging_folders>")
//query from which data will be read
.option(Constants.QUERY, "select <column_name>, count(*) as cnt from <schema_name>.<table_name> group by <column_name>")
synapsesql()
val dfToReadFromQueryAsArgument:DataFrame = spark.read.
// Name of the SQL Dedicated Pool or database where to run the query
// Database can be specified as a Spark Config - spark.sqlanalyticsconnector.dw.database or as a Constant - Constants.DATABASE
option(Constants.DATABASE, "<database_name>")
//If `Constants.SERVER` is not provided, the `<database_name>` from the three-part table name argument
//to `synapsesql` method is used to infer the Synapse Dedicated SQL End Point.
option(Constants.SERVER, "<sql-server-name>.sql.azuresynapse.net").
//Defaults to storage path defined in the runtime configurations
option(Constants.TEMP_FOLDER, "abfss://<container_name>@<storage_account_name>.dfs.core.windows.net/<some_base_path_for_temporary_staging_folders>")
//query from which data will be read
.synapsesql("select <column_name>, count(*) as counts from <schema_name>.<table_name> group by <column_name>")
//Show contents of the dataframe
dfToReadFromQueryAsOption.show()
dfToReadFromQueryAsArgument.show()
Leggere da una tabella usando l'autenticazione di base
//Use case is to read data from an internal table in Synapse Dedicated SQL Pool DB
//Azure Active Directory based authentication approach is preferred here.
import org.apache.spark.sql.DataFrame
import com.microsoft.spark.sqlanalytics.utils.Constants
import org.apache.spark.sql.SqlAnalyticsConnector._
//Read from existing internal table
val dfToReadFromTable:DataFrame = spark.read.
//If `Constants.SERVER` is not provided, the `<database_name>` from the three-part table name argument
//to `synapsesql` method is used to infer the Synapse Dedicated SQL End Point.
option(Constants.SERVER, "<sql-server-name>.sql.azuresynapse.net").
//Set database user name
option(Constants.USER, "<user_name>").
//Set user's password to the database
option(Constants.PASSWORD, "<user_password>").
//Set name of the data source definition that is defined with database scoped credentials.
//Data extracted from the table will be staged to the storage path defined on the data source's location setting.
option(Constants.DATA_SOURCE, "<data_source_name>").
//Three-part table name from where data will be read.
synapsesql("<database_name>.<schema_name>.<table_name>").
//Column-pruning i.e., query select column values.
select("<some_column_1>", "<some_column_5>", "<some_column_n>").
//Push-down filter criteria that gets translated to SQL Push-down Predicates.
filter(col("Title").startsWith("E")).
//Fetch a sample of 10 records
limit(10)
//Show contents of the dataframe
dfToReadFromTable.show()
Leggere da una query usando l'autenticazione di base
//Use case is to read data from an internal table in Synapse Dedicated SQL Pool DB
//Azure Active Directory based authentication approach is preferred here.
import org.apache.spark.sql.DataFrame
import com.microsoft.spark.sqlanalytics.utils.Constants
import org.apache.spark.sql.SqlAnalyticsConnector._
// Name of the SQL Dedicated Pool or database where to run the query
// Database can be specified as a Spark Config or as a Constant - Constants.DATABASE
spark.conf.set("spark.sqlanalyticsconnector.dw.database", "<database_name>")
// Read from a query
// Query can be provided either as an argument to synapsesql or as a Constant - Constants.QUERY
val dfToReadFromQueryAsOption:DataFrame = spark.read.
//Name of the SQL Dedicated Pool or database where to run the query
//Database can be specified as a Spark Config - spark.sqlanalyticsconnector.dw.database or as a Constant - Constants.DATABASE
option(Constants.DATABASE, "<database_name>").
//If `Constants.SERVER` is not provided, the `<database_name>` from the three-part table name argument
//to `synapsesql` method is used to infer the Synapse Dedicated SQL End Point.
option(Constants.SERVER, "<sql-server-name>.sql.azuresynapse.net").
//Set database user name
option(Constants.USER, "<user_name>").
//Set user's password to the database
option(Constants.PASSWORD, "<user_password>").
//Set name of the data source definition that is defined with database scoped credentials.
//Data extracted from the SQL query will be staged to the storage path defined on the data source's location setting.
option(Constants.DATA_SOURCE, "<data_source_name>").
//Query where data will be read.
option(Constants.QUERY, "select <column_name>, count(*) as counts from <schema_name>.<table_name> group by <column_name>" ).
synapsesql()
val dfToReadFromQueryAsArgument:DataFrame = spark.read.
//Name of the SQL Dedicated Pool or database where to run the query
//Database can be specified as a Spark Config - spark.sqlanalyticsconnector.dw.database or as a Constant - Constants.DATABASE
option(Constants.DATABASE, "<database_name>").
//If `Constants.SERVER` is not provided, the `<database_name>` from the three-part table name argument
//to `synapsesql` method is used to infer the Synapse Dedicated SQL End Point.
option(Constants.SERVER, "<sql-server-name>.sql.azuresynapse.net").
//Set database user name
option(Constants.USER, "<user_name>").
//Set user's password to the database
option(Constants.PASSWORD, "<user_password>").
//Set name of the data source definition that is defined with database scoped credentials.
//Data extracted from the SQL query will be staged to the storage path defined on the data source's location setting.
option(Constants.DATA_SOURCE, "<data_source_name>").
//Query where data will be read.
synapsesql("select <column_name>, count(*) as counts from <schema_name>.<table_name> group by <column_name>")
//Show contents of the dataframe
dfToReadFromQueryAsOption.show()
dfToReadFromQueryAsArgument.show()
Scrivere in pool SQL dedicato di Azure Synapse
Richiesta di scrittura - firma del metodo synapsesql
synapsesql(tableName:String,
tableType:String = Constants.INTERNAL,
location:Option[String] = None,
callBackHandle=Option[(Map[String, Any], Option[Throwable])=>Unit]):Unit
Scrivere usando l'autenticazione basata su Microsoft Entra ID
Di seguito è riportato un modello di codice completo che descrive come usare il connettore per scenari di scrittura:
//Add required imports
import org.apache.spark.sql.DataFrame
import org.apache.spark.sql.SaveMode
import com.microsoft.spark.sqlanalytics.utils.Constants
import org.apache.spark.sql.SqlAnalyticsConnector._
//Define read options for example, if reading from CSV source, configure header and delimiter options.
val pathToInputSource="abfss://<storage_container_name>@<storage_account_name>.dfs.core.windows.net/<some_folder>/<some_dataset>.csv"
//Define read configuration for the input CSV
val dfReadOptions:Map[String, String] = Map("header" -> "true", "delimiter" -> ",")
//Initialize DataFrame that reads CSV data from a given source
val readDF:DataFrame=spark.
read.
options(dfReadOptions).
csv(pathToInputSource).
limit(1000) //Reads first 1000 rows from the source CSV input.
//Setup and trigger the read DataFrame for write to Synapse Dedicated SQL Pool.
//Fully qualified SQL Server DNS name can be obtained using one of the following methods:
// 1. Synapse Workspace - Manage Pane - SQL Pools - <Properties view of the corresponding Dedicated SQL Pool>
// 2. From Azure Portal, follow the bread-crumbs for <Portal_Home> -> <Resource_Group> -> <Dedicated SQL Pool> and then go to Connection Strings/JDBC tab.
//If `Constants.SERVER` is not provided, the value will be inferred by using the `database_name` in the three-part table name argument to the `synapsesql` method.
//Like-wise, if `Constants.TEMP_FOLDER` is not provided, the connector will use the runtime staging directory config (see section on Configuration Options for details).
val writeOptionsWithAADAuth:Map[String, String] = Map(Constants.SERVER -> "<dedicated-pool-sql-server-name>.sql.azuresynapse.net",
Constants.TEMP_FOLDER -> "abfss://<storage_container_name>@<storage_account_name>.dfs.core.windows.net/<some_temp_folder>")
//Setup optional callback/feedback function that can receive post write metrics of the job performed.
var errorDuringWrite:Option[Throwable] = None
val callBackFunctionToReceivePostWriteMetrics: (Map[String, Any], Option[Throwable]) => Unit =
(feedback: Map[String, Any], errorState: Option[Throwable]) => {
println(s"Feedback map - ${feedback.map{case(key, value) => s"$key -> $value"}.mkString("{",",\n","}")}")
errorDuringWrite = errorState
}
//Configure and submit the request to write to Synapse Dedicated SQL Pool (note - default SaveMode is set to ErrorIfExists)
//Sample below is using AAD-based authentication approach; See further examples to leverage SQL Basic auth.
readDF.
write.
//Configure required configurations.
options(writeOptionsWithAADAuth).
//Choose a save mode that is apt for your use case.
mode(SaveMode.Overwrite).
synapsesql(tableName = "<database_name>.<schema_name>.<table_name>",
//For external table type value is Constants.EXTERNAL
tableType = Constants.INTERNAL,
//Optional parameter that is used to specify external table's base folder; defaults to `database_name/schema_name/table_name`
location = None,
//Optional parameter to receive a callback.
callBackHandle = Some(callBackFunctionToReceivePostWriteMetrics))
//If write request has failed, raise an error and fail the Cell's execution.
if(errorDuringWrite.isDefined) throw errorDuringWrite.get
Scrittura tramite l’autenticazione di base
Il frammento di codice seguente sostituisce la definizione di scrittura descritta nella sezione Scrivere usando l'autenticazione basata su Microsoft Entra ID per inviare una richiesta di scrittura usando l'approccio di autenticazione di base di SQL:
//Define write options to use SQL basic authentication
val writeOptionsWithBasicAuth:Map[String, String] = Map(Constants.SERVER -> "<dedicated-pool-sql-server-name>.sql.azuresynapse.net",
//Set database user name
Constants.USER -> "<user_name>",
//Set database user's password
Constants.PASSWORD -> "<user_password>",
//Required only when writing to an external table. For write to internal table, this can be used instead of TEMP_FOLDER option.
Constants.DATA_SOURCE -> "<Name of the datasource as defined in the target database>"
//To be used only when writing to internal tables. Storage path will be used for data staging.
Constants.TEMP_FOLDER -> "abfss://<storage_container_name>@<storage_account_name>.dfs.core.windows.net/<some_temp_folder>")
//Configure and submit the request to write to Synapse Dedicated SQL Pool.
readDF.
write.
options(writeOptionsWithBasicAuth).
//Choose a save mode that is apt for your use case.
mode(SaveMode.Overwrite).
synapsesql(tableName = "<database_name>.<schema_name>.<table_name>",
//For external table type value is Constants.EXTERNAL
tableType = Constants.INTERNAL,
//Not required for writing to an internal table
location = None,
//Optional parameter.
callBackHandle = Some(callBackFunctionToReceivePostWriteMetrics))
In un approccio di autenticazione di base, per leggere i dati da un percorso di archiviazione di origine sono necessarie altre opzioni di configurazione. Il frammento di codice seguente fornisce un esempio per leggere da un'origine dati di Azure Data Lake Storage Gen2 usando le credenziali dell'entità servizio:
//Specify options that Spark runtime must support when interfacing and consuming source data
val storageAccountName="<storageAccountName>"
val storageContainerName="<storageContainerName>"
val subscriptionId="<AzureSubscriptionID>"
val spnClientId="<ServicePrincipalClientID>"
val spnSecretKeyUsedAsAuthCred="<spn_secret_key_value>"
val dfReadOptions:Map[String, String]=Map("header"->"true",
"delimiter"->",",
"fs.defaultFS" -> s"abfss://$storageContainerName@$storageAccountName.dfs.core.windows.net",
s"fs.azure.account.auth.type.$storageAccountName.dfs.core.windows.net" -> "OAuth",
s"fs.azure.account.oauth.provider.type.$storageAccountName.dfs.core.windows.net" ->
"org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider",
"fs.azure.account.oauth2.client.id" -> s"$spnClientId",
"fs.azure.account.oauth2.client.secret" -> s"$spnSecretKeyUsedAsAuthCred",
"fs.azure.account.oauth2.client.endpoint" -> s"https://login.microsoftonline.com/$subscriptionId/oauth2/token",
"fs.AbstractFileSystem.abfss.impl" -> "org.apache.hadoop.fs.azurebfs.Abfs",
"fs.abfss.impl" -> "org.apache.hadoop.fs.azurebfs.SecureAzureBlobFileSystem")
//Initialize the Storage Path string, where source data is maintained/kept.
val pathToInputSource=s"abfss://$storageContainerName@$storageAccountName.dfs.core.windows.net/<base_path_for_source_data>/<specific_file (or) collection_of_files>"
//Define data frame to interface with the data source
val df:DataFrame = spark.
read.
options(dfReadOptions).
csv(pathToInputSource).
limit(100)
Modalità di salvataggio del DataFrame supportate
Quando si scrivono dati di origine in una tabella di destinazione nel pool SQL dedicato di Azure Synapse, sono supportate le modalità di salvataggio seguenti:
- ErrorIfExists (modalità di salvataggio predefinita)
- Se la tabella di destinazione è presente, la scrittura viene interrotta con un'eccezione restituita al destinatario. In caso contrario, viene creata una nuova tabella con i dati delle cartelle di staging.
- Ignora
- Se la tabella di destinazione esiste, la scrittura ignorerà la richiesta di scrittura senza restituire un errore. In caso contrario, viene creata una nuova tabella con i dati delle cartelle di staging.
- Overwrite
- Se la tabella di destinazione esiste, i dati esistenti nella destinazione vengono sostituiti con i dati delle cartelle di staging. In caso contrario, viene creata una nuova tabella con i dati delle cartelle di staging.
- Accoda
- Se la tabella di destinazione esiste, i nuovi dati vengono accodati. In caso contrario, viene creata una nuova tabella con i dati delle cartelle di staging.
Handle di callback della richiesta di scrittura
La nuova API del percorso di scrittura ha introdotto una funzionalità sperimentale per fornire al client una mappa dei valori chiave-> delle metriche post-scrittura. Le chiavi per le metriche vengono definite nella nuova definizione Oggetto - Constants.FeedbackConstants. Le metriche possono essere recuperate come stringa JSON passando l'handle di callback (Scala Function). Di seguito è riportata la firma della funzione:
//Function signature is expected to have two arguments - a `scala.collection.immutable.Map[String, Any]` and an Option[Throwable]
//Post-write if there's a reference of this handle passed to the `synapsesql` signature, it will be invoked by the closing process.
//These arguments will have valid objects in either Success or Failure case. In case of Failure the second argument will be a `Some(Throwable)`.
(Map[String, Any], Option[Throwable]) => Unit
Di seguito sono riportate alcune metriche rilevanti (presentate nel caso camel):
WriteFailureCauseDataStagingSparkJobDurationInMillisecondsNumberOfRecordsStagedForSQLCommitSQLStatementExecutionDurationInMillisecondsrows_processed
Di seguito è riportata una stringa JSON di esempio con metriche post-scrittura:
{
SparkApplicationId -> <spark_yarn_application_id>,
SQLStatementExecutionDurationInMilliseconds -> 10113,
WriteRequestReceivedAtEPOCH -> 1647523790633,
WriteRequestProcessedAtEPOCH -> 1647523808379,
StagingDataFileSystemCheckDurationInMilliseconds -> 60,
command -> "COPY INTO [schema_name].[table_name] ...",
NumberOfRecordsStagedForSQLCommit -> 100,
DataStagingSparkJobEndedAtEPOCH -> 1647523797245,
SchemaInferenceAssertionCompletedAtEPOCH -> 1647523790920,
DataStagingSparkJobDurationInMilliseconds -> 5252,
rows_processed -> 100,
SaveModeApplied -> TRUNCATE_COPY,
DurationInMillisecondsToValidateFileFormat -> 75,
status -> Completed,
SparkApplicationName -> <spark_application_name>,
ThreePartFullyQualifiedTargetTableName -> <database_name>.<schema_name>.<table_name>,
request_id -> <query_id_as_retrieved_from_synapse_dedicated_sql_db_query_reference>,
StagingFolderConfigurationCheckDurationInMilliseconds -> 2,
JDBCConfigurationsSetupAtEPOCH -> 193,
StagingFolderConfigurationCheckCompletedAtEPOCH -> 1647523791012,
FileFormatValidationsCompletedAtEPOCHTime -> 1647523790995,
SchemaInferenceCheckDurationInMilliseconds -> 91,
SaveModeRequested -> Overwrite,
DataStagingSparkJobStartedAtEPOCH -> 1647523791993,
DurationInMillisecondsTakenToGenerateWriteSQLStatements -> 4
}
Altri esempi di codice
Uso di dati materializzati tra celle
È possibile usare createOrReplaceTempView del DataFrame di Spark per accedere ai dati recuperati in un'altra cella, registrando una visualizzazione temporanea.
- Cella in cui vengono recuperati i dati (ad esempio con preferenza lingua notebook come
Scala)
//Necessary imports
import org.apache.spark.sql.DataFrame
import org.apache.spark.sql.SaveMode
import com.microsoft.spark.sqlanalytics.utils.Constants
import org.apache.spark.sql.SqlAnalyticsConnector._
//Configure options and read from Synapse Dedicated SQL Pool.
val readDF = spark.read.
//Set Synapse Dedicated SQL End Point name.
option(Constants.SERVER, "<synapse-dedicated-sql-end-point>.sql.azuresynapse.net").
//Set database user name.
option(Constants.USER, "<user_name>").
//Set database user's password.
option(Constants.PASSWORD, "<user_password>").
//Set name of the data source definition that is defined with database scoped credentials.
option(Constants.DATA_SOURCE,"<data_source_name>").
//Set the three-part table name from which the read must be performed.
synapsesql("<database_name>.<schema_name>.<table_name>").
//Optional - specify number of records the DataFrame would read.
limit(10)
//Register the temporary view (scope - current active Spark Session)
readDF.createOrReplaceTempView("<temporary_view_name>")
- Modificare ora la preferenza per la lingua nel notebook in
PySpark (Python)e recuperare i dati dalla vista registrata<temporary_view_name>
spark.sql("select * from <temporary_view_name>").show()
Gestione delle risposte
La chiamata di synapsesql ha due possibili stati finali: Operazione riuscita o Stato non riuscito. Questa sezione descrive come gestire la risposta della richiesta per ogni scenario.
Risposta alla richiesta di lettura
Al termine, il frammento di risposta di lettura viene visualizzato nell'output della cella. L'errore nella cella corrente annulla anche le esecuzioni successive delle celle. Le informazioni dettagliate sugli errori sono disponibili nei registri applicazioni Spark.
Risposta alla richiesta di scrittura
Per impostazione predefinita, viene stampata una risposta di scrittura nell'output della cella. In caso di errore, la cella corrente viene contrassegnata come non riuscita e le successive esecuzioni di celle verranno interrotte. L'altro approccio consiste nel passare l'opzione handle di callback al metodo synapsesql. L'handle di callback fornirà l'accesso a livello di codice alla risposta di scrittura.
Altre considerazioni
- Durante la lettura dalle tabelle del pool SQL dedicato di Azure Synapse:
- Valutare la possibilità di applicare i filtri necessari al DataFrame per sfruttare la funzionalità di eliminazione delle colonne del connettore.
- Lo scenario di lettura non supporta la clausola
TOP(n-rows), durante il framing delle istruzioni di querySELECT. La scelta di limitare i dati consiste nell'usare la clausola limite(.) del DataFrame.- Fare riferimento all'esempio - sezione Uso di dati materializzati tra le celle.
- Durante la scrittura nelle tabelle del pool SQL dedicato di Azure Synapse:
- Per i tipi di tabella interni:
- Le tabelle vengono create con la distribuzione dei dati ROUND_ROBIN.
- I tipi di colonna vengono dedotti dal DataFrame che leggerebbe i dati dall'origine. Le colonne stringa vengono mappate a
NVARCHAR(4000).
- Per i tipi di tabella esterni:
- Il parallelismo iniziale del DataFrame determina l'organizzazione dei dati per la tabella esterna.
- I tipi di colonna vengono dedotti dal DataFrame che leggerebbe i dati dall'origine.
- È possibile ottenere una migliore distribuzione dei dati tra executor ottimizzando il parametro
spark.sql.files.maxPartitionByteserepartitiondel DataFrame. - Quando si scrivono set di dati di grandi dimensioni, è importante tenere conto dell'impatto dell'impostazione del livello di prestazioni DWU che limita le dimensioni delle transazioni.
- Per i tipi di tabella interni:
- Monitorare le tendenze di utilizzo di Azure Data Lake Storage Gen2 per individuare i comportamenti di limitazione che possono influire sulle prestazioni di lettura e scrittura.