Raccogliere le metriche delle applicazioni Apache Spark tramite API
Panoramica
In questa esercitazione si apprenderà come integrare il server Prometheus locale esistente con l'area di lavoro di Azure Synapse per le metriche dell'applicazione Apache Spark quasi in tempo reale usando il connettore Synapse Prometheus.
Questa esercitazione presenta anche le API delle metriche REST di Azure Synapse. È possibile recuperare i dati delle metriche dell'applicazione Apache Spark tramite le API REST per creare un toolkit di monitoraggio e diagnosi personalizzato o eseguire l’integrazione con i sistemi di monitoraggio.
Usare il connettore Prometheus di Azure Synapse per i server Prometheus locali
Il connettore Prometheus di Azure Synapse è un progetto open source. Il connettore Prometheus di Synapse usa un metodo di individuazione dei servizi basato su file per consentire di:
- Eseguire l'autenticazione nell'area di lavoro di Synapse tramite un'entità servizio Microsoft Entra.
- Recuperare l'elenco delle applicazioni Apache Spark nell'area di lavoro.
- Eseguire il pull delle metriche dell'applicazione Apache Spark tramite la configurazione basata su file Prometheus.
1. Prerequisito
È necessario avere un server Prometheus distribuito in una VM Linux.
2. Creare un'entità servizio
Per usare il connettore Prometheus di Azure Synapse nel server Prometheus locale, seguire questa procedura per creare un'entità servizio.
2.1 Creare un'entità servizio:
az ad sp create-for-rbac --name <service_principal_name> --role Contributor --scopes /subscriptions/<subscription_id>
Il risultato dovrebbe avere l'aspetto seguente:
{
"appId": "abcdef...",
"displayName": "<service_principal_name>",
"name": "http://<service_principal_name>",
"password": "abc....",
"tenant": "<tenant_id>"
}
Prendere nota dell'ID app, della password e dell'ID tenant.
2.2 Aggiungere le autorizzazioni corrispondenti all'entità servizio creata nel passaggio precedente.
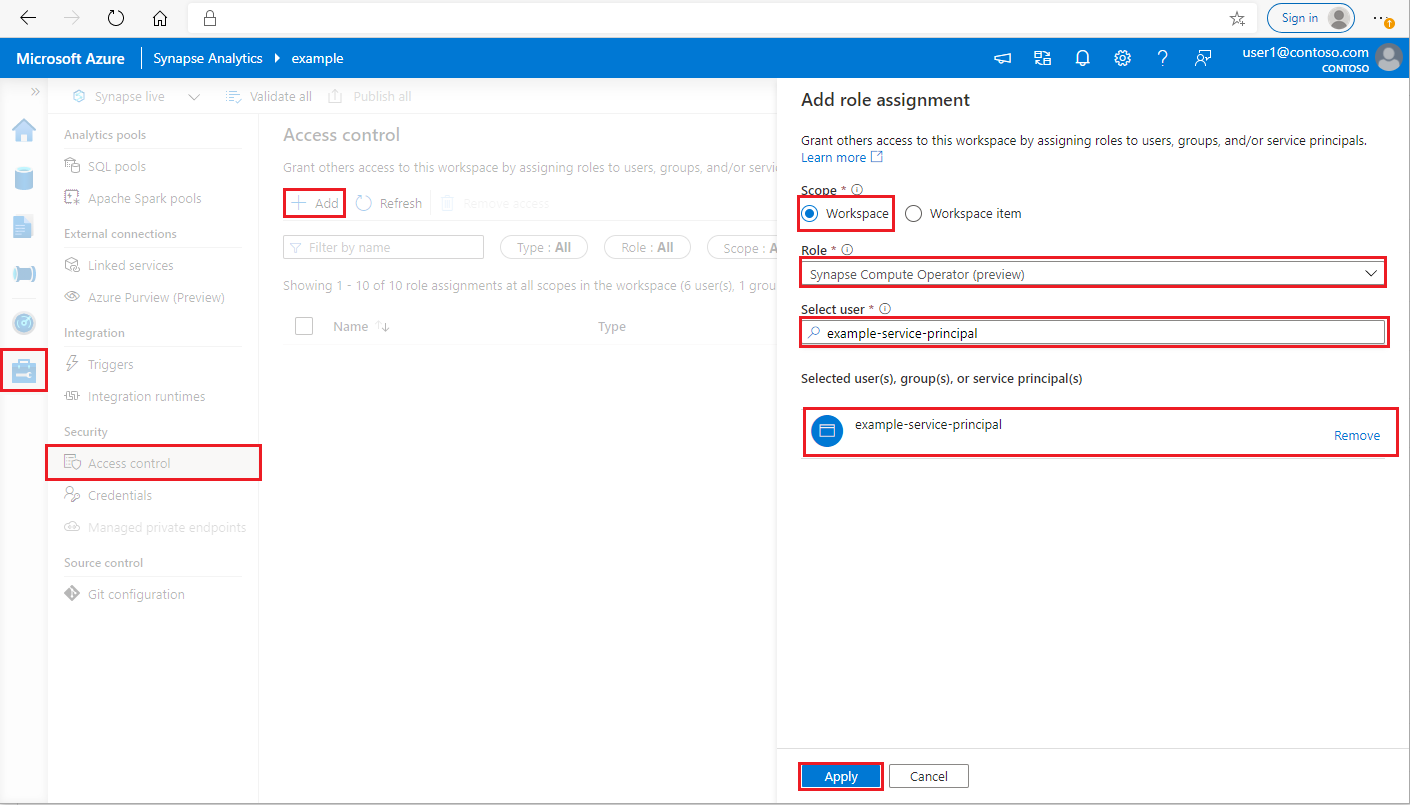
Accedere all'area di lavoro di Azure Synapse Analytics come amministratore di Synapse
Nel riquadro sinistro di Synapse Studio selezionare Gestisci >Controllo di accesso
Fare clic sul pulsante Aggiungi in alto a sinistra per aggiungere un'assegnazione di ruolo
Per Ambito scegliere Area di lavoro
Per Ruolo scegliere Operatore di calcolo Synapse
Per Selezionare l'utente immettere il <service_principal_name> e fare clic sull'entità servizio
Fare clic su Applica (attendere 3 minuti per rendere effettiva l'autorizzazione).
3. Scaricare il connettore Prometheus di Azure Synapse
Usare i comandi per installare il connettore Prometheus di Azure Synapse.
git clone https://github.com/microsoft/azure-synapse-spark-metrics.git
cd ./azure-synapse-spark-metrics/synapse-prometheus-connector/src
python pip install -r requirements.txt
4. Creare un file di configurazione per le aree di lavoro di Azure Synapse
Creare un file config.yaml nella cartella config e compilare i campi seguenti: workspace_name, tenant_id, service_principal_name e service_principal_password. È possibile aggiungere più aree di lavoro nella configurazione yaml.
workspaces:
- workspace_name: <your_workspace_name>
tenant_id: <tenant_id>
service_principal_name: <service_principal_app_id>
service_principal_password: "<service_principal_password>"
5. Aggiornare la configurazione di Prometheus
Aggiungere la sezione config seguente nella scrape_config Prometheus e sostituire il <your_workspace_name> con il nome dell'area di lavoro e il <path_to_synapse_connector> con la cartella clonata synapse-prometheus-connector
- job_name: synapse-prometheus-connector
static_configs:
- labels:
__metrics_path__: /metrics
__scheme__: http
targets:
- localhost:8000
- job_name: synapse-workspace-<your_workspace_name>
bearer_token_file: <path_to_synapse_connector>/output/workspace/<your_workspace_name>/bearer_token
file_sd_configs:
- files:
- <path_to_synapse_connector>/output/workspace/<your_workspace_name>/application_discovery.json
refresh_interval: 10s
metric_relabel_configs:
- source_labels: [ __name__ ]
target_label: __name__
regex: metrics_application_[0-9]+_[0-9]+_(.+)
replacement: spark_$1
- source_labels: [ __name__ ]
target_label: __name__
regex: metrics_(.+)
replacement: spark_$1
6. Avviare il connettore nella VM del server Prometheus
Avviare un server connettore nella VM del server Prometheus come indicato di seguito.
python main.py
Attendere alcuni secondi perché il connettore inizi a funzionare. È anche possibile visualizzare "synapse-prometheus-connector" nella pagina di individuazione del servizio Prometheus.
Usare le API di metriche REST o Prometheus di Azure Synapse per raccogliere i dati delle metriche
1. Authentication
È possibile usare il flusso delle credenziali client per ottenere un token di accesso. Per accedere all'API delle metriche, è necessario ottenere un token di accesso Microsoft Entra per l'entità servizio, che dispone dell'autorizzazione appropriata per accedere alle API.
| Parametro | Richiesto | Descrizione |
|---|---|---|
| tenant_id | Vero | L’ID tenant (applicazione) dell’entità servizio di Azure |
| grant_type | Vero | Specifica il tipo di concessione richiesto. In un flusso di concessione delle credenziali client il valore deve essere client_credentials. |
| client_id | Vero | L’ID applicazione (entità servizio) dell'applicazione registrata nel portale di Azure o nell'interfaccia della riga di comando di Azure. |
| client_secret | Vero | Il segreto generato per l'applicazione (entità servizio) |
| resource | Vero | L'URI della risorsa Synapse deve essere 'https://dev.azuresynapse.net' |
curl -X GET -H 'Content-Type: application/x-www-form-urlencoded' \
-d 'grant_type=client_credentials&client_id=<service_principal_app_id>&resource=<azure_synapse_resource_id>&client_secret=<service_principal_secret>' \
https://login.microsoftonline.com/<tenant_id>/oauth2/token
La risposta ha un aspetto simile al seguente:
{
"token_type": "Bearer",
"expires_in": "599",
"ext_expires_in": "599",
"expires_on": "1575500666",
"not_before": "1575499766",
"resource": "2ff8...f879c1d",
"access_token": "ABC0eXAiOiJKV1Q......un_f1mSgCHlA"
}
2. Elencare le applicazioni in esecuzione nell'area di lavoro di Azure Synapse
Per ottenere l'elenco delle applicazioni Apache Spark per un'area di lavoro di Synapse, è possibile seguire questo documento Monitoraggio - Ottenere l'elenco dei processi Apache Spark.
3. Raccogliere le metriche dell'applicazione Apache Spark con le API REST o Prometheus
Raccogliere le metriche dell'applicazione Apache Spark con l'API Prometheus
Ottenere le metriche più recenti dell'applicazione Apache Spark specificata dall'API Prometheus
GET https://{endpoint}/livyApi/versions/{livyApiVersion}/sparkpools/{sparkPoolName}/sessions/{sessionId}/applications/{sparkApplicationId}/metrics/executors/prometheus?format=html
| Parametro | Richiesto | Descrizione |
|---|---|---|
| endpoint | Vero | Endpoint di sviluppo dell'area di lavoro, ad esempio https://myworkspace.dev.azuresynapse.net. |
| livyApiVersion | Vero | Versione api valida per la richiesta. Attualmente, è 2019-11-01-preview |
| sparkPoolName | Vero | Nome del pool di spark. |
| sessionId | Vero | Identificatore della sessione. |
| sparkApplicationId | Vero | ID applicazione Spark |
Richiesta di esempio:
GET https://myworkspace.dev.azuresynapse.net/livyApi/versions/2019-11-01-preview/sparkpools/mysparkpool/sessions/1/applications/application_1605509647837_0001/metrics/executors/prometheus?format=html
Risposta di esempio:
Codice di stato: la risposta 200 è simile alla seguente:
metrics_executor_rddBlocks{application_id="application_1605509647837_0001", application_name="mynotebook_mysparkpool_1605509570802", executor_id="driver"} 0
metrics_executor_memoryUsed_bytes{application_id="application_1605509647837_0001", application_name="mynotebook_mysparkpool_1605509570802", executor_id="driver"} 74992
metrics_executor_diskUsed_bytes{application_id="application_1605509647837_0001", application_name="mynotebook_mysparkpool_1605509570802", executor_id="driver"} 0
metrics_executor_totalCores{application_id="application_1605509647837_0001", application_name="mynotebook_mysparkpool_1605509570802", executor_id="driver"} 0
metrics_executor_maxTasks{application_id="application_1605509647837_0001", application_name="mynotebook_mysparkpool_1605509570802", executor_id="driver"} 0
metrics_executor_activeTasks{application_id="application_1605509647837_0001", application_name="mynotebook_mysparkpool_1605509570802", executor_id="driver"} 1
metrics_executor_failedTasks_total{application_id="application_1605509647837_0001", application_name="mynotebook_mysparkpool_1605509570802", executor_id="driver"} 0
metrics_executor_completedTasks_total{application_id="application_1605509647837_0001", application_name="mynotebook_mysparkpool_1605509570802", executor_id="driver"} 2
...
Raccogliere le metriche dell'applicazione Apache Spark con l'API REST
GET https://{endpoint}/livyApi/versions/{livyApiVersion}/sparkpools/{sparkPoolName}/sessions/{sessionId}/applications/{sparkApplicationId}/executors
| Parametro | Richiesto | Descrizione |
|---|---|---|
| endpoint | Vero | Endpoint di sviluppo dell'area di lavoro, ad esempio https://myworkspace.dev.azuresynapse.net. |
| livyApiVersion | Vero | Versione api valida per la richiesta. Attualmente, è 2019-11-01-preview |
| sparkPoolName | Vero | Nome del pool di spark. |
| sessionId | Vero | Identificatore della sessione. |
| sparkApplicationId | Vero | ID applicazione Spark |
Richiesta di esempio
GET https://myworkspace.dev.azuresynapse.net/livyApi/versions/2019-11-01-preview/sparkpools/mysparkpool/sessions/1/applications/application_1605509647837_0001/executors
Esempio di codice di stato della risposta: 200
[
{
"id": "driver",
"hostPort": "f98b8fc2aea84e9095bf2616208eb672007bde57624:45889",
"isActive": true,
"rddBlocks": 0,
"memoryUsed": 75014,
"diskUsed": 0,
"totalCores": 0,
"maxTasks": 0,
"activeTasks": 0,
"failedTasks": 0,
"completedTasks": 0,
"totalTasks": 0,
"totalDuration": 0,
"totalGCTime": 0,
"totalInputBytes": 0,
"totalShuffleRead": 0,
"totalShuffleWrite": 0,
"isBlacklisted": false,
"maxMemory": 15845975654,
"addTime": "2020-11-16T06:55:06.718GMT",
"executorLogs": {
"stdout": "http://f98b8fc2aea84e9095bf2616208eb672007bde57624:8042/node/containerlogs/container_1605509647837_0001_01_000001/trusted-service-user/stdout?start=-4096",
"stderr": "http://f98b8fc2aea84e9095bf2616208eb672007bde57624:8042/node/containerlogs/container_1605509647837_0001_01_000001/trusted-service-user/stderr?start=-4096"
},
"memoryMetrics": {
"usedOnHeapStorageMemory": 75014,
"usedOffHeapStorageMemory": 0,
"totalOnHeapStorageMemory": 15845975654,
"totalOffHeapStorageMemory": 0
},
"blacklistedInStages": []
},
// ...
]
4. Creare strumenti di diagnostica e monitoraggio personalizzati
L'API Prometheus e le API REST forniscono dati avanzati sulle metriche dell'applicazione Apache Spark che esegue informazioni. È possibile raccogliere i dati sulle metriche correlate all'applicazione tramite l'API Prometheus e le API REST. E creare strumenti di diagnostica e monitoraggio personalizzati più adatti alle proprie esigenze.