Raccogliere log e metriche delle applicazioni Apache Spark con l'account di archiviazione di Azure
L'estensione dell'emettitore di diagnostica Apache Spark di Synapse è una libreria che consente all'applicazione Apache Spark di generare i log, i registri eventi e le metriche in una o più destinazioni, tra cui Azure Log Analytics, Archiviazione di Azure e Hub eventi di Azure.
Questa esercitazione illustra come usare l'estensione dell'emettitore di diagnostica Apache Spark di Synapse per generare log, registri eventi e metriche delle applicazioni Apache Spark nell'account di archiviazione di Azure.
Raccogliere log e metriche nell'account di archiviazione
Passaggio 1: Creare un account di archiviazione
Per raccogliere i log di diagnostica e le metriche nell'account di archiviazione, è possibile usare gli account di archiviazione di Azure esistenti. In alternativa, se non si dispone di questo tipo di account, è possibile creare un account di archiviazione BLOB di Azure o creare un account di archiviazione da usare con Azure Data Lake Storage Gen2.
Passaggio 2: creare un file di configurazione di Apache Spark
Creare un diagnostic-emitter-azure-storage-conf.txt e copiare il contenuto seguente nel file. In alternativa, scaricare un file di modello di esempio per la configurazione del pool di Apache Spark.
spark.synapse.diagnostic.emitters MyDestination1
spark.synapse.diagnostic.emitter.MyDestination1.type AzureStorage
spark.synapse.diagnostic.emitter.MyDestination1.categories Log,EventLog,Metrics
spark.synapse.diagnostic.emitter.MyDestination1.uri https://<my-blob-storage>.blob.core.windows.net/<container-name>/<folder-name>
spark.synapse.diagnostic.emitter.MyDestination1.auth AccessKey
spark.synapse.diagnostic.emitter.MyDestination1.secret <storage-access-key>
Inserire i parametri seguenti nel file di configurazione: <my-blob-storage>, <container-name>, <folder-name>, <storage-access-key>.
Per altre descrizioni dei parametri, è possibile fare riferimento alle configurazioni di Archiviazione di Azure
Passaggio 3: caricare il file di configurazione di Apache Spark in Synapse Studio e usarlo nel pool di Spark
- Aprire la pagina delle configurazioni di Apache Spark (Gestisci -> Configurazioni di Apache Spark).
- Fare clic sul pulsante Importa per caricare il file di configurazione di Apache Spark in Synapse Studio.
- Andare al pool di Apache Spark in Synapse Studio (Gestisci -> pool di Apache Spark).
- Fare clic sul pulsante "..." a destra del pool di Apache Spark e selezionare Configurazione di Apache Spark.
- È possibile selezionare il file di configurazione appena caricato nel menu a discesa.
- Fare clic su Applica dopo aver selezionato il file di configurazione.
Passaggio 4: visualizzare i file di log nell'account di archiviazione di Azure
Dopo aver inviato un processo al pool di Apache Spark configurato, dovrebbe essere possibile visualizzare i log e i file delle metriche nell'account di archiviazione di destinazione.
I log verranno inseriti nei percorsi corrispondenti in base alle diverse applicazioni di <workspaceName>.<sparkPoolName>.<livySessionId>.
Tutti i file di log saranno in formato di righe JSON (detto anche JSON delimitato da nuova riga, ndjson), che è utile per l'elaborazione dei dati.
Configurazioni disponibili
| Impostazione | Descrizione |
|---|---|
spark.synapse.diagnostic.emitters |
Obbligatorio. Nomi di destinazione delimitati da virgole degli emettitori di diagnostica. Ad esempio, MyDest1,MyDest2 |
spark.synapse.diagnostic.emitter.<destination>.type |
Obbligatorio. Tipo di destinazione predefinito. Per abilitare la destinazione di archiviazione di Azure, è necessario includere AzureStorage in questo campo. |
spark.synapse.diagnostic.emitter.<destination>.categories |
Facoltativo. Categorie di log selezionate separate da virgole. I valori disponibili includono DriverLog, ExecutorLog, EventLog e Metrics. Se non è impostato, il valore predefinito è tutte le categorie. |
spark.synapse.diagnostic.emitter.<destination>.auth |
Obbligatorio. AccessKey per l'uso dell'autorizzazione della chiave di accesso dell'account di archiviazione. SAS per l'autorizzazione delle firme di accesso condiviso. |
spark.synapse.diagnostic.emitter.<destination>.uri |
Obbligatorio. L'URI della cartella del contenitore BLOB di destinazione. Deve corrispondere al criterio https://<my-blob-storage>.blob.core.windows.net/<container-name>/<folder-name>. |
spark.synapse.diagnostic.emitter.<destination>.secret |
Facoltativo. Il contenuto di (AccessKey o SAS) segreto. |
spark.synapse.diagnostic.emitter.<destination>.secret.keyVault |
Obbligatorio se .secret non viene specificato. Nome dell’insieme di credenziali delle chiavi di Azure in cui è archiviato il (AccessKey o SAS) segreto. |
spark.synapse.diagnostic.emitter.<destination>.secret.keyVault.secretName |
Obbligatorio se si specifica .secret.keyVault. Il nome segreto dell'insieme di credenziali delle chiavi di Azure in cui è archiviato il (AccessKey o SAS) segreto. |
spark.synapse.diagnostic.emitter.<destination>.secret.keyVault.linkedService |
Facoltativo. Il nome del Servizio collegato di Azure Key Vault. Se abilitata nella pipeline di Synapse, è necessario ottenere il segreto da Azure Key Vault. (assicurarsi che l'identità del servizio gestito disponga dell'autorizzazione di lettura per Azure Key Vault). |
spark.synapse.diagnostic.emitter.<destination>.filter.eventName.match |
Facoltativo. I nomi degli eventi spark delimitati da virgole; è possibile specificare gli eventi da raccogliere. Ad esempio: SparkListenerApplicationStart,SparkListenerApplicationEnd |
spark.synapse.diagnostic.emitter.<destination>.filter.loggerName.match |
Facoltativo. I nomi dei logger log4j delimitati da virgole; è possibile specificare i log da raccogliere. Ad esempio: org.apache.spark.SparkContext,org.example.Logger |
spark.synapse.diagnostic.emitter.<destination>.filter.metricName.match |
Facoltativo. I suffissi del nome della metrica Spark delimitati da virgole; è possibile specificare le metriche da raccogliere. Ad esempio: jvm.heap.used |
Esempio di dati di log
Di seguito è riportato un record di log di esempio in formato JSON:
{
"timestamp": "2021-01-02T12:34:56.789Z",
"category": "Log|EventLog|Metrics",
"workspaceName": "<my-workspace-name>",
"sparkPool": "<spark-pool-name>",
"livyId": "<livy-session-id>",
"applicationId": "<application-id>",
"applicationName": "<application-name>",
"executorId": "<driver-or-executor-id>",
"properties": {
// The message properties of logs, events and metrics.
"timestamp": "2021-01-02T12:34:56.789Z",
"message": "Registering signal handler for TERM",
"logger_name": "org.apache.spark.util.SignalUtils",
"level": "INFO",
"thread_name": "main"
// ...
}
}
Area di lavoro di Synapse con protezione dall'esfiltrazione dati abilitata
Le aree di lavoro di Azure Synapse Analytics supportano l'abilitazione della protezione dell'esfiltrazione dei dati per le aree di lavoro. Con la protezione dall'esfiltrazione, non è possibile inviare i log e le metriche direttamente agli endpoint di destinazione. In questo scenario è possibile creare endpoint privati gestiti corrispondenti per endpoint di destinazione differenti, oppure creare regole del firewall IP.
Andare a Synapse Studio> Gestisci >Endpoint privati gestiti, fare clic sul pulsante Nuovo, selezionare Archiviazione BLOB di Azure o Azure Data Lake Storage Gen2 e Continua.
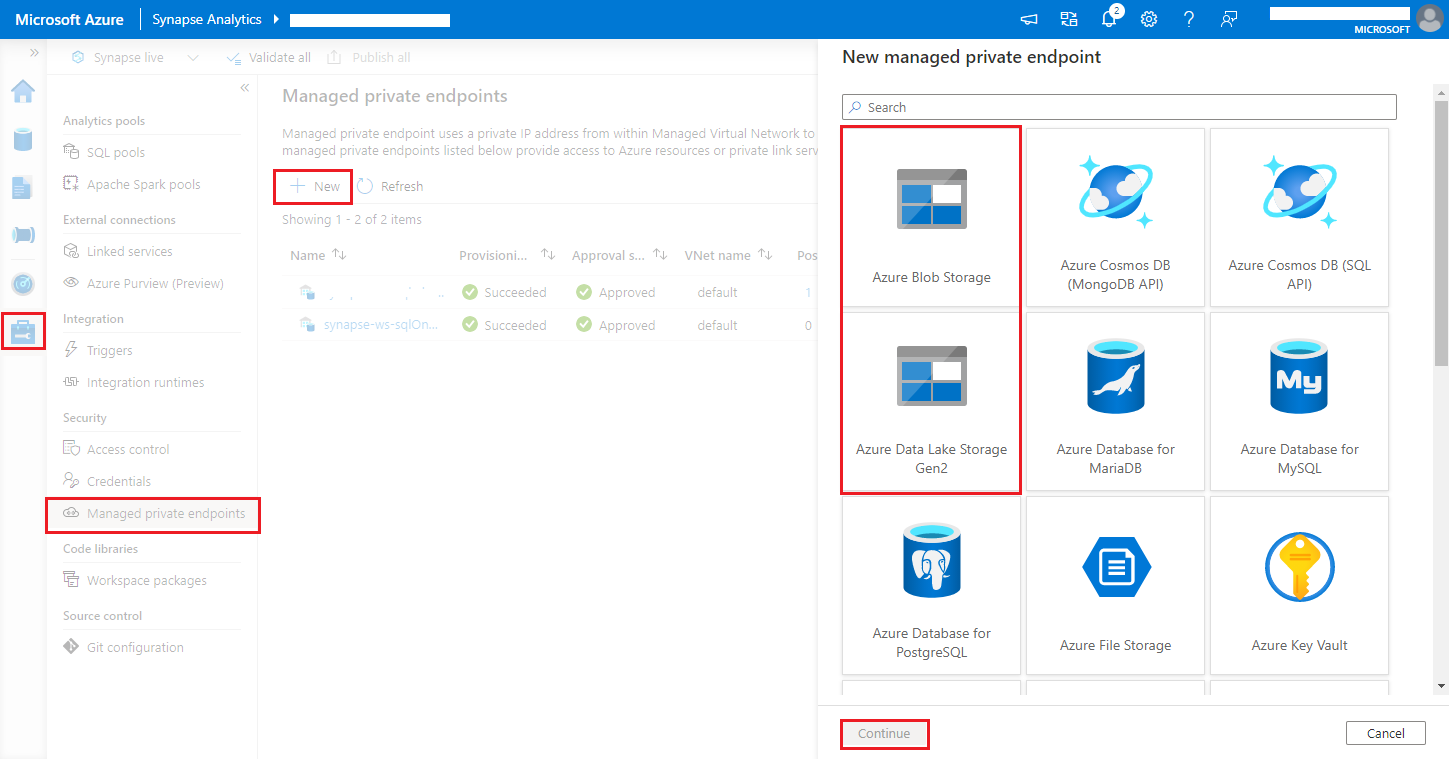
Nota
Siamo in grado di supportare dati per Archiviazione BLOB di Azure e Azure Data Lake Storage Gen2. Tuttavia, non è stato possibile analizzare il formato abfss://. Gli endpoint di Azure Data Lake Storage Gen2 devono essere formattati come URL BLOB:
https://<my-blob-storage>.blob.core.windows.net/<container-name>/<folder-name>Scegliere l'account di archiviazione di Azure nel nome dell'account di archiviazione e fare clic sul pulsante Crea.
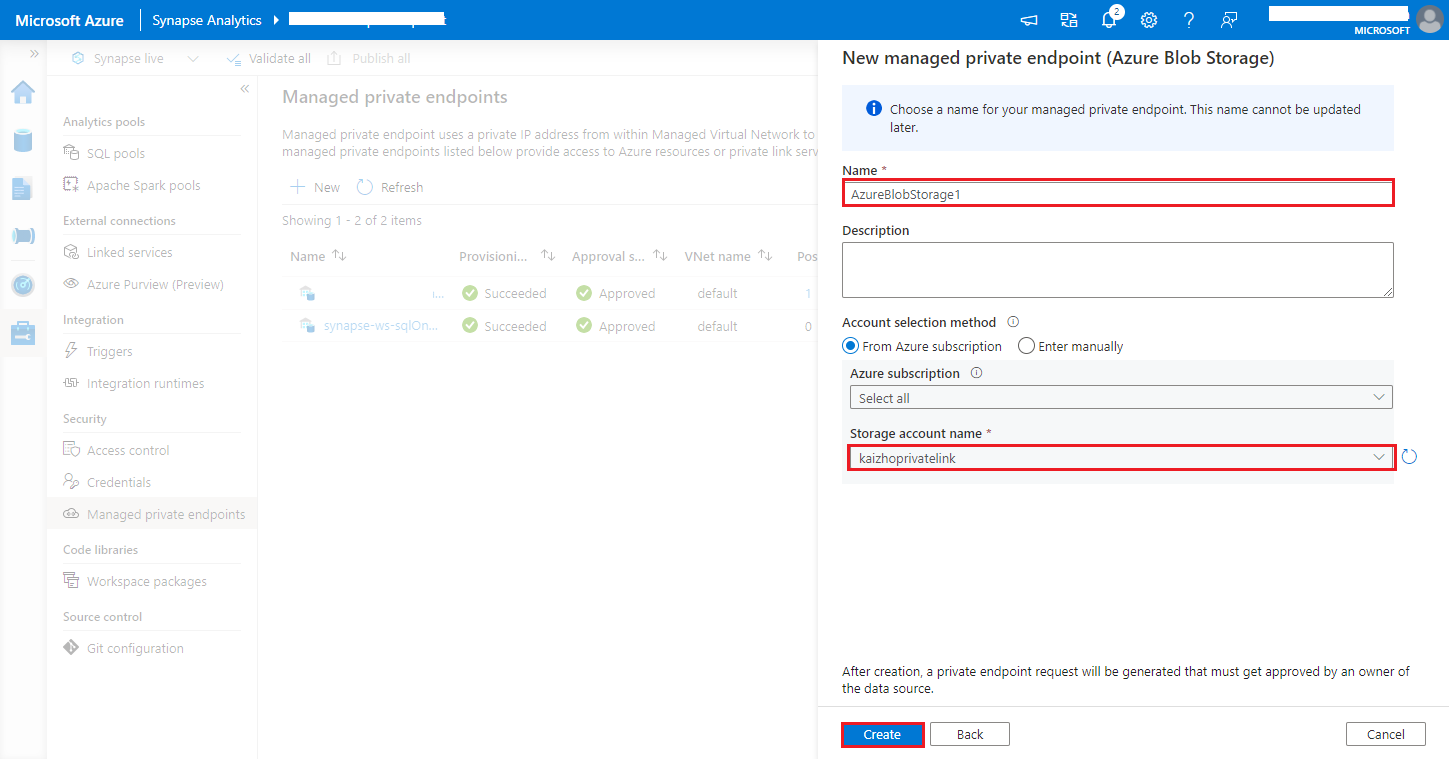
Attendere alcuni minuti per effettuare il provisioning di endpoint privati.
Andare all'account di archiviazione nel portale di Azure, nella pagina Networking> Connessioni endpoint private, selezionare la connessione di cui è stato effettuato il provisioning e Approva.