Connettersi a Esplora dati di Azure con Apache Spark per Azure Synapse Analytics
Questo articolo descrive come accedere a un database di Esplora dati di Azure da Synapse Studio con Apache Spark per Azure Synapse Analytics.
Prerequisiti
- Creare un database e un cluster di Esplora dati di Azure.
- Avere un'area di lavoro di Azure Synapse Analytics o crearne una nuova seguendo i passaggi indicati in Avvio rapido: Creare un'area di lavoro di Azure Synapse.
- Avere un pool di Apache Spark o crearne uno nuovo seguendo i passaggi indicati in Avvio rapido: Creare un pool di Apache Spark usando il portale di Azure.
- Creare un'app Microsoft Entra effettuando il provisioning di un'applicazione Microsoft Entra.
- Consentire all'app Microsoft Entra l'accesso al database seguendo i passaggi indicati in Gestire le autorizzazioni per database di Esplora dati di Azure.
Passare a Synapse Studio
In un'area di lavoro di Azure Synapse selezionare Avvia Synapse Studio. Nella home page di Synapse Studio selezionare Data (Dati) per aprire Data Object Explorer (Esplora oggetti dati).
Connettere un database di Esplora dati di Azure a un'area di lavoro di Azure Synapse
Per la connessione di un database di Esplora dati di Azure a un'area di lavoro si usa un servizio collegato. Con un servizio collegato di Esplora dati di Azure è possibile cercare ed esplorare dati, leggere e scrivere da Apache Spark per Azure Synapse. È anche possibile eseguire i processi di integrazione in una pipeline.
In Data Object Explorer (Esplora oggetti dati) seguire questa procedura per connettere direttamente un cluster di Esplora dati di Azure:
Selezionare l'icona + accanto a Data (Dati).
Selezionare Connect (Connetti) per connettersi a dati esterni.
Selezionare Esplora dati di Azure (Kusto).
Selezionare Continua.
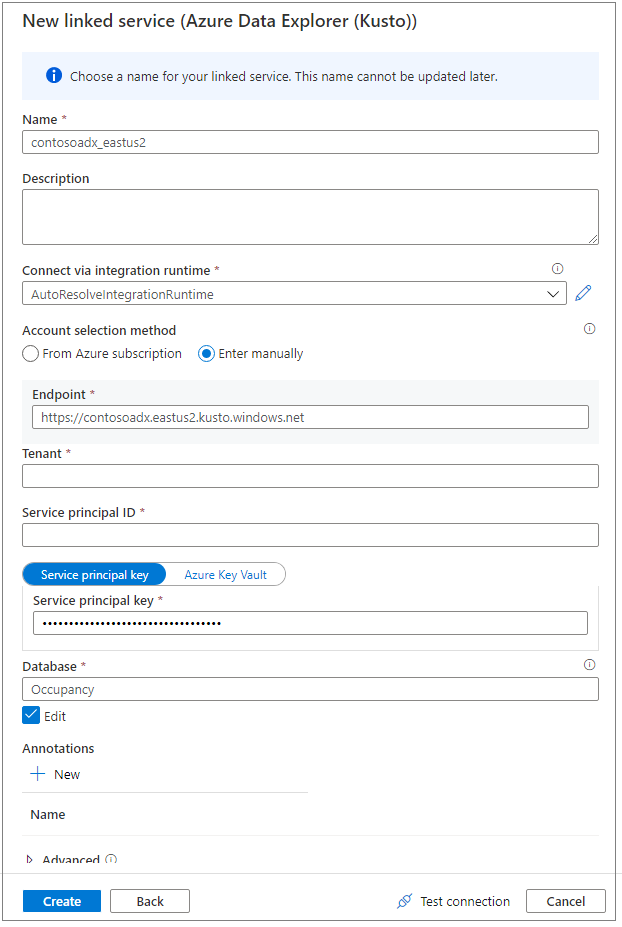
Assegnare un nome descrittivo al servizio collegato. Il nome verrà visualizzato in Data Object Explorer (Esplora oggetti dati) e verrà usato dai runtime di Azure Synapse per connettersi al database.
Selezionare il cluster di Esplora dati di Azure dalla sottoscrizione o immettere l'URI.
Immettere l'ID e la chiave dell'entità servizio. Assicurarsi che questa entità servizio abbia accesso in visualizzazione al database per le operazioni di lettura e accesso in inserimento per l'inserimento dei dati.
Immettere il nome del database di Esplora dati di Azure.
Selezionare Test connessione per assicurarsi che le autorizzazioni siano corrette.
Seleziona Crea.
Nota
(Facoltativo) Test connessione non convalida l'accesso in scrittura. Assicurarsi che l'ID entità servizio abbia accesso in scrittura al database di Esplora dati di Azure.
I cluster e i database di Esplora dati di Azure sono visibili nella scheda Collegati nella sezione Esplora dati di Azure.
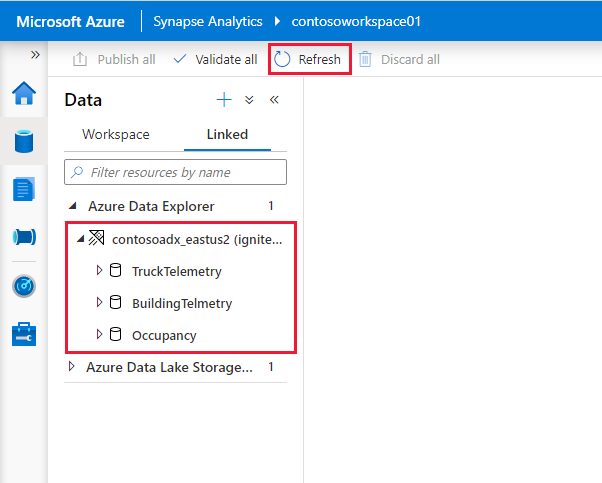
Prima di poter interagire con il servizio collegato da un notebook, è necessario pubblicarlo nell'area di lavoro. Fare clic su Pubblica nella barra degli strumenti, esaminare le modifiche in sospeso e fare clic su OK.
Nota
Nella versione corrente gli oggetti di database vengono popolati in base alle autorizzazioni dell'account Microsoft Entra per i database di Esplora dati di Azure. Quando si eseguono processi di integrazione o notebook di Apache Spark, verranno usate le credenziali indicate nel servizio di collegamento, ad esempio l'entità servizio.
Interagire rapidamente con le azioni generate dal codice
Quando si fa clic con il pulsante destro del mouse su un database o su una tabella, viene visualizzato un elenco di notebook di Spark di esempio. Selezionare un'opzione per la lettura, la scrittura o lo streaming di dati in Esplora dati di Azure.

Ecco un esempio di lettura dei dati. Collegare il notebook al pool di Spark ed eseguire la cella.

Nota
La prima esecuzione dell'avvio della sessione di Spark può richiedere più di tre minuti. Le esecuzioni successive saranno notevolmente più rapide.
Limiti
Il connettore Esplora dati di Azure non è attualmente supportato con le reti virtuali gestite di Azure Synapse.